







 超级会员免费看
超级会员免费看
 本文详细介绍了使用Hadoop MapReduce实现词频统计的全过程,包括设计思路、实现步骤、清洗标点符号、调整切片数量、设置分区等关键环节。通过创建Maven项目MRWordCount,配置Mapper、Reducer,以及上传到虚拟机运行,展示了如何统计HDFS文件中的单词个数,并优化程序以处理标点符号和调整切片及Reduce任务数量。
本文详细介绍了使用Hadoop MapReduce实现词频统计的全过程,包括设计思路、实现步骤、清洗标点符号、调整切片数量、设置分区等关键环节。通过创建Maven项目MRWordCount,配置Mapper、Reducer,以及上传到虚拟机运行,展示了如何统计HDFS文件中的单词个数,并优化程序以处理标点符号和调整切片及Reduce任务数量。
文章目录
- 一、词频统计设计思路
- 二、词频统计实现步骤
-
- 1、创建Maven项目MRWordCount
- 2、在项目根目录创建words.txt文件
- 3、启动HDFS服务,上传文件到HDFS
- 4、修改pom.xml文件,添加hadoop依赖
- 5、在resources目录下创建log4j.properties文件
- 6、创建WordCountMapper类
- 7、创建WordCountDriver类
- 8、在虚拟机上启动yarn服务
- 9、启动WordCountDriver,看看结果
- 10、修改WordCountMapper
- 11、修改WordCountDriver
- 12、启动WordCountDriver,查看运行结果
- 13、创建WordCountReducer
- 14、修改WordCountDriver,设置WordCountReducer
- 15、启动WordCountDriver,查看结果
- 16、将MRWordCount打jar包上传到虚拟机上运行
- 17、改善程序,用户可指定输入路径和输出路径
- 18、清洗标点符号
- 19、切片数量问题
- 20、采用多个Reduce做合并
- 21、将三个类合成一个类完成词频统计
- 22、合并分区导致的多个结果文件
- 23、统计一个或多个文件里总共有多少个不同单词
- 三、项目MRWordCount下载
词频统计是MapReduce的入门案例,类似于学习程序设计的“Hello World”案例。
一、词频统计设计思路
1、映射阶段(Map)
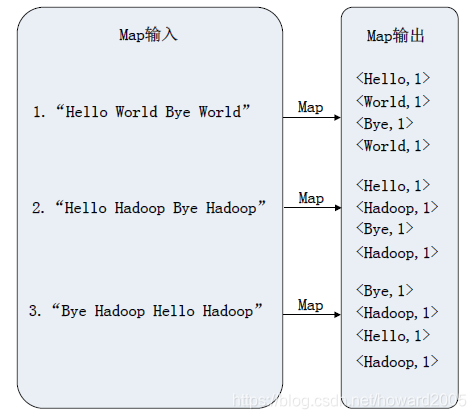
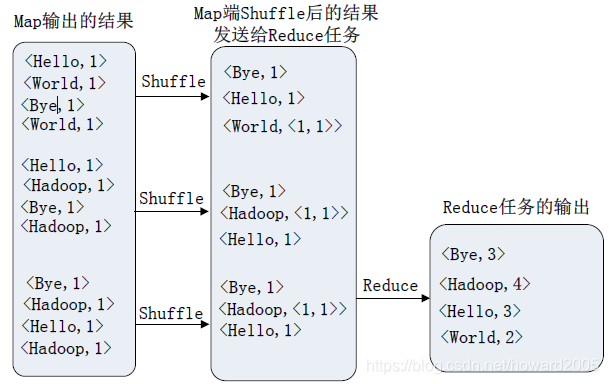
2、归并阶段(Reduce)
(1)不用合并器(Combiner)
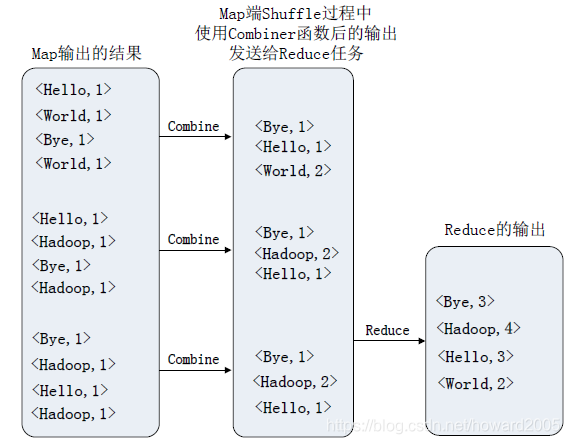
(2)采用合并器(Combiner)

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











