





一、什么是LangChain和LangGraph?
LangChain:大模型应用的"乐高积木"
LangChain是一个用于构建大语言模型应用的开发框架,它提供了标准化的接口、组件和工具链,让开发者能够快速搭建基于LLM的应用程序。
生动比喻:乐高积木套装
- 传统LLM开发:像手工雕刻
-
- 每个项目从头开始
- 需要处理各种底层细节
- 重复劳动,效率低下
- LangChain:像乐高积木
-
- 提供标准化组件(积木块)
- 快速组合成复杂应用
- 可复用、可扩展
LangGraph:复杂工作流的"交通控制系统"
LangGraph是建立在LangChain之上的库,专门用于构建有状态、多步骤的复杂工作流,特别擅长处理循环、条件和并行执行。
生动比喻:城市交通控制系统
- 简单链式调用:像单行道
-
- 只能单向顺序执行
- 没有分支,没有回头路
- LangGraph:像智能交通系统
-
- 管理多条路径和交叉口
- 处理拥堵和意外情况
- 动态调整路线
技术定位对比
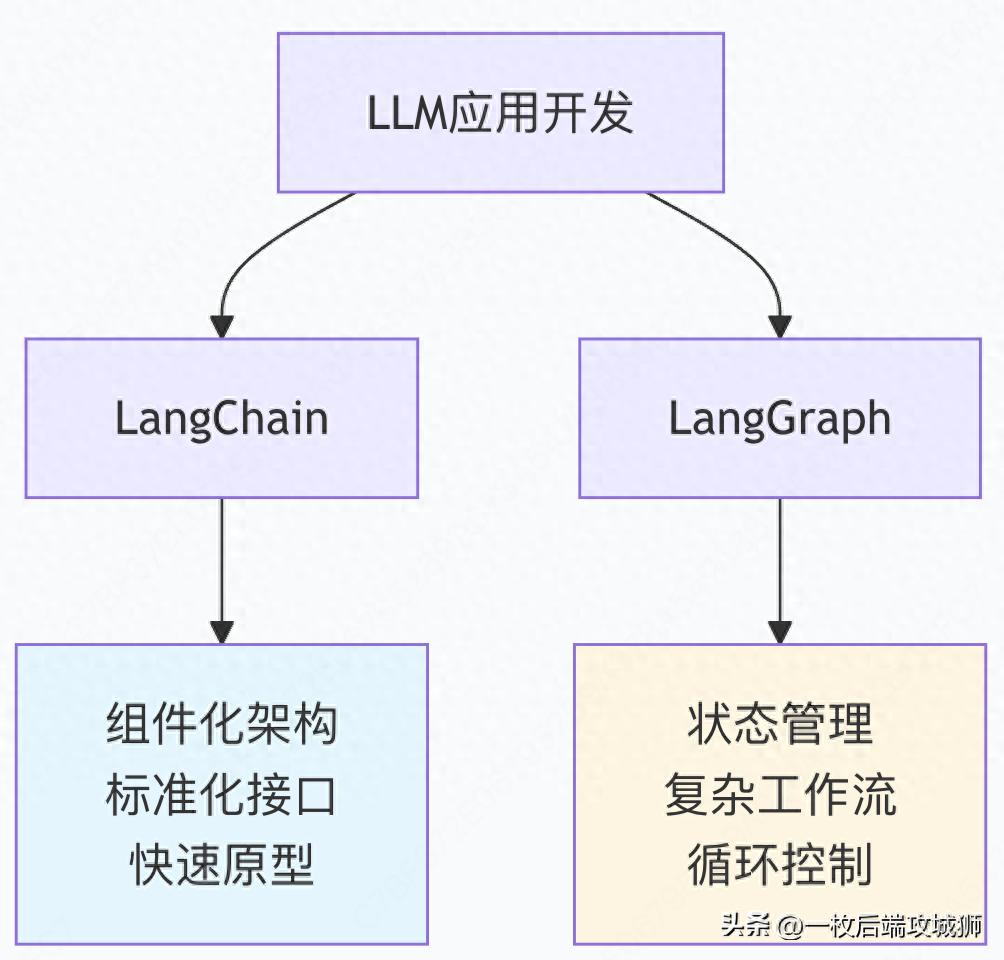
二、LangChain和LangGraph的区别是什么?
1. 核心架构差异
LangChain:组件化架构
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
# LangChain的核心组件化思想
class LangChainArchitecture:
"""LangChain的组件化架构"""
def __init__(self):
self.components = {
"Models": ["LLMs", "Chat Models", "Embeddings"],
"Prompts": ["Prompt Templates", "Output Parsers"],
"Chains": ["Simple Sequential", "Custom Chains"],
"Indexes": ["Document Loaders", "Text Splitters", "Vector Stores"],
"Memory": ["Conversation Memory", "Entity Memory"],
"Agents": ["Tools", "Toolkits", "Agent Executors"]
}
def demonstrate_chain_construction(self):
"""演示LangChain链式构建"""
# 1. 定义提示模板
prompt = PromptTemplate(
input_variables=["product"],
template="为{product}写一个营销标语:"
)
# 2. 初始化LLM
llm = OpenAI(temperature=0.7)
# 3. 创建链
chain = LLMChain(llm=llm, prompt=prompt)
# 4. 执行链
result = chain.run("智能手表")
return result
# 使用示例
langchain_demo = LangChainArchitecture()
print("LangChain组件:", langchain_demo.components)
marketing_slogan = langchain_demo.demonstrate_chain_construction()
print(f"生成的标语: {marketing_slogan}")
LangGraph:图基工作流
from typing import Dict, Any, List
from langgraph.graph import StateGraph, END
from langchain.schema import BaseMessage, HumanMessage
# LangGraph的状态定义
class GraphState(Dict):
"""LangGraph的状态容器"""
messages: List[BaseMessage]
current_step: str
needs_human_input: bool = False
class LangGraphArchitecture:
"""LangGraph的图基架构"""
def __init__(self):
self.graph_elements = {
"Nodes": "执行具体任务的函数",
"Edges": "节点间的连接和条件路由",
"State": "在节点间传递的共享数据",
"Checkpoint": "状态快照,支持回滚"
}
def create_conversation_graph(self):
"""创建对话图"""
# 初始化图
workflow = StateGraph(GraphState)
# 定义节点
workflow.add_node("receive_input", self.receive_input_node)
workflow.add_node("analyze_intent", self.analyze_intent_node)
workflow.add_node("generate_response", self.generate_response_node)
workflow.add_node("request_clarification", self.request_clarification_node)
# 定义边和条件路由
workflow.set_entry_point("receive_input")
workflow.add_edge("receive_input", "analyze_intent")
workflow.add_conditional_edges(
"analyze_intent",
self.should_clarify,
{
"clarify": "request_clarification",
"continue": "generate_response"
}
)
workflow.add_edge("request_clarification", "receive_input") # 循环
workflow.add_edge("generate_response", END)
return workflow.compile()
def receive_input_node(self, state: GraphState) -> GraphState:
"""接收输入节点"""
print("接收用户输入...")
return state
def analyze_intent_node(self, state: GraphState) -> GraphState:
"""分析意图节点"""
print("分析用户意图...")
# 模拟意图分析
state["intent_clear"] = len(state["messages"][-1].content) > 10
return state
def should_clarify(self, state: GraphState) -> str:
"""条件路由:是否需要澄清"""
return "clarify" if not state.get("intent_clear", False) else "continue"
def request_clarification_node(self, state: GraphState) -> GraphState:
"""请求澄清节点"""
print("请求用户澄清...")
state["needs_human_input"] = True
return state
def generate_response_node(self, state: GraphState) -> GraphState:
"""生成响应节点"""
print("生成最终响应...")
return state
# 使用示例
langgraph_demo = LangGraphArchitecture()
conversation_graph = langgraph_demo.create_conversation_graph()
print("LangGraph图结构已创建")
2. 状态管理对比
LangChain:无状态执行
class LangChainStateless:
"""LangChain的无状态执行模式"""
def sequential_processing(self, user_input):
"""顺序处理 - 无状态"""
steps = [
self.preprocess_input,
self.extract_entities,
self.generate_response,
self.format_output
]
result = user_input
for step in steps:
result = step(result)
print(f"步骤完成: {step.__name__}, 结果: {result}")
return result
def preprocess_input(self, text):
return text.strip().lower()
def extract_entities(self, text):
return f"提取的实体: {text.split()[:2]}"
def generate_response(self, entities):
return f"基于{entities}生成的回答"
def format_output(self, response):
return f"格式化: {response.upper()}"
# 测试无状态执行
stateless = LangChainStateless()
result = stateless.sequential_processing(" Hello World Test ")
print(f"最终结果: {result}")
LangGraph:有状态工作流
from typing import TypedDict, Annotated
import operator
class StatefulWorkflowState(TypedDict):
"""有状态工作流的状态定义"""
original_input: str
processed_input: str
extracted_entities: list
generated_response: str
conversation_history: Annotated[list, operator.add] # 累加操作
current_step: str
error_count: int
class LangGraphStateful:
"""LangGraph的有状态工作流"""
def create_stateful_workflow(self):
"""创建有状态工作流"""
workflow = StateGraph(StatefulWorkflowState)
# 添加节点
workflow.add_node("preprocess", self.preprocess_with_state)
workflow.add_node("extract", self.extract_with_state)
workflow.add_node("generate", self.generate_with_state)
workflow.add_node("handle_error", self.handle_error)
# 设置路由
workflow.set_entry_point("preprocess")
workflow.add_edge("preprocess", "extract")
workflow.add_edge("extract", "generate")
workflow.add_conditional_edges(
"generate",
self.check_quality,
{"acceptable": END, "poor": "handle_error"}
)
workflow.add_edge("handle_error", "extract") # 重试
return workflow.compile()
def preprocess_with_state(self, state: StatefulWorkflowState):
"""带状态的预处理"""
state["processed_input"] = state["original_input"].strip().lower()
state["current_step"] = "preprocess"
state["conversation_history"].append("预处理完成")
return state
def extract_with_state(self, state: StatefulWorkflowState):
"""带状态的实体提取"""
entities = state["processed_input"].split()[:2]
state["extracted_entities"] = entities
state["current_step"] = "extract"
state["conversation_history"].append(f"提取实体: {entities}")
return state
def generate_with_state(self, state: StatefulWorkflowState):
"""带状态的响应生成"""
response = f"基于{state['extracted_entities']}的响应"
state["generated_response"] = response
state["current_step"] = "generate"
state["conversation_history"].append(f"生成响应: {response}")
return state
def check_quality(self, state: StatefulWorkflowState):
"""检查响应质量"""
# 模拟质量检查
quality_acceptable = len(state["generated_response"]) > 10
return "acceptable" if quality_acceptable else "poor"
def handle_error(self, state: StatefulWorkflowState):
"""错误处理"""
state["error_count"] = state.get("error_count", 0) + 1
state["conversation_history"].append(f"错误处理,计数: {state['error_count']}")
return state
# 测试有状态工作流
stateful = LangGraphStateful()
workflow = stateful.create_stateful_workflow()
initial_state = {
"original_input": " Hello World Test ",
"processed_input": "",
"extracted_entities": [],
"generated_response": "",
"conversation_history": [],
"current_step": "",
"error_count": 0
}
result = workflow.invoke(initial_state)
print("最终状态:", result)
3. 工作流模式对比
LangChain:顺序链式执行
from langchain.chains import SimpleSequentialChain, TransformChain
from langchain.schema import BaseOutputParser
class LangChainWorkflow:
"""LangChain的顺序工作流"""
def create_sequential_chain(self):
"""创建顺序链"""
# 转换链1:文本清理
def clean_text(inputs):
return {"cleaned_text": inputs["text"].strip()}
clean_chain = TransformChain(
input_variables=["text"],
output_variables=["cleaned_text"],
transform=clean_text
)
# 转换链2:文本分析
def analyze_text(inputs):
words = inputs["cleaned_text"].split()
return {
"word_count": len(words),
"first_words": words[:3]
}
analyze_chain = TransformChain(
input_variables=["cleaned_text"],
output_variables=["word_count", "first_words"],
transform=analyze_text
)
# 组合成顺序链
sequential_chain = SimpleSequentialChain(
chains=[clean_chain, analyze_chain],
verbose=True
)
return sequential_chain
def demonstrate_linear_flow(self):
"""演示线性流程"""
chain = self.create_sequential_chain()
result = chain.run(" This is a test sentence for demonstration ")
return result
# 测试顺序链
workflow_demo = LangChainWorkflow()
result = workflow_demo.demonstrate_linear_flow()
print(f"顺序链结果: {result}")
LangGraph:图基条件执行
from langgraph.graph import StateGraph, END
from typing import Literal
class LangGraphWorkflow:
"""LangGraph的图基工作流"""
def create_conditional_workflow(self):
"""创建条件工作流"""
class WorkflowState(TypedDict):
input_text: str
text_length: int
complexity: str
processing_path: list
final_result: str
workflow = StateGraph(WorkflowState)
# 添加节点
workflow.add_node("analyze_length", self.analyze_length)
workflow.add_node("simple_process", self.simple_process)
workflow.add_node("complex_process", self.complex_process)
workflow.add_node("assemble_result", self.assemble_result)
# 设置复杂路由
workflow.set_entry_point("analyze_length")
workflow.add_conditional_edges(
"analyze_length",
self.determine_complexity,
{
"simple": "simple_process",
"complex": "complex_process"
}
)
workflow.add_edge("simple_process", "assemble_result")
workflow.add_edge("complex_process", "assemble_result")
workflow.add_edge("assemble_result", END)
return workflow.compile()
def analyze_length(self, state: WorkflowState):
"""分析文本长度"""
state["text_length"] = len(state["input_text"])
state["processing_path"].append("analyze_length")
return state
def determine_complexity(self, state: WorkflowState) -> Literal["simple", "complex"]:
"""确定处理复杂度"""
if state["text_length"] < 50:
state["complexity"] = "simple"
return "simple"
else:
state["complexity"] = "complex"
return "complex"
def simple_process(self, state: WorkflowState):
"""简单处理"""
state["processing_path"].append("simple_process")
state["final_result"] = f"简单处理: {state['input_text'][:20]}..."
return state
def complex_process(self, state: WorkflowState):
"""复杂处理"""
state["processing_path"].append("complex_process")
words = state["input_text"].split()
state["final_result"] = f"复杂处理: {len(words)}个单词,前5个: {words[:5]}"
return state
def assemble_result(self, state: WorkflowState):
"""组装结果"""
state["processing_path"].append("assemble_result")
state["final_result"] += f" | 处理路径: {' -> '.join(state['processing_path'])}"
return state
# 测试条件工作流
graph_workflow = LangGraphWorkflow()
workflow = graph_workflow.create_conditional_workflow()
# 测试短文本
short_result = workflow.invoke({
"input_text": "Hello world",
"processing_path": [],
"final_result": ""
})
print(f"短文本结果: {short_result['final_result']}")
# 测试长文本
long_result = workflow.invoke({
"input_text": "This is a much longer text that requires more complex processing due to its length and complexity",
"processing_path": [],
"final_result": ""
})
print(f"长文本结果: {long_result['final_result']}")
4. 复杂任务处理对比
LangChain:代理模式处理复杂任务
from langchain.agents import AgentType, initialize_agent, Tool
from langchain.utilities import SerpAPIWrapper
from langchain.llms import OpenAI
class LangChainAgentApproach:
"""LangChain的代理方法处理复杂任务"""
def setup_agent(self):
"""设置代理"""
# 定义工具
search = SerpAPIWrapper()
tools = [
Tool(
name="Search",
func=search.run,
description="用于搜索最新信息"
),
Tool(
name="Calculator",
func=lambda x: str(eval(x)),
description="用于数学计算"
)
]
# 初始化代理
llm = OpenAI(temperature=0)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
return agent
def handle_complex_query(self, query):
"""处理复杂查询"""
agent = self.setup_agent()
try:
result = agent.run(query)
return result
except Exception as e:
return f"代理执行错误: {str(e)}"
# 注意:实际使用时需要配置SerpAPI密钥
agent_demo = LangChainAgentApproach()
# result = agent_demo.handle_complex_query("今天北京的天气怎么样?然后计算25的平方根")
# print(f"代理结果: {result}")
LangGraph:图工作流处理复杂任务
class LangGraphComplexWorkflow:
"""LangGraph处理复杂任务"""
def create_research_workflow(self):
"""创建研究型工作流"""
class ResearchState(TypedDict):
research_topic: str
search_queries: list
search_results: dict
analysis: str
report: str
current_step: str
needs_human_review: bool
workflow = StateGraph(ResearchState)
# 定义所有节点
workflow.add_node("plan_research", self.plan_research)
workflow.add_node("execute_searches", self.execute_searches)
workflow.add_node("analyze_results", self.analyze_results)
workflow.add_node("generate_report", self.generate_report)
workflow.add_node("human_review", self.human_review)
workflow.add_node("refine_report", self.refine_report)
# 复杂路由逻辑
workflow.set_entry_point("plan_research")
workflow.add_edge("plan_research", "execute_searches")
workflow.add_edge("execute_searches", "analyze_results")
workflow.add_conditional_edges(
"analyze_results",
self.need_human_review,
{"review": "human_review", "continue": "generate_report"}
)
workflow.add_edge("human_review", "refine_report")
workflow.add_edge("refine_report", "generate_report")
workflow.add_edge("generate_report", END)
return workflow.compile()
def plan_research(self, state: ResearchState):
"""规划研究"""
topic = state["research_topic"]
state["search_queries"] = [
f"{topic} 最新发展",
f"{topic} 关键技术",
f"{topic} 应用场景"
]
state["current_step"] = "plan_research"
return state
def execute_searches(self, state: ResearchState):
"""执行搜索"""
# 模拟搜索执行
state["search_results"] = {
query: f"关于'{query}'的模拟搜索结果..."
for query in state["search_queries"]
}
state["current_step"] = "execute_searches"
return state
def analyze_results(self, state: ResearchState):
"""分析结果"""
results = state["search_results"]
state["analysis"] = f"分析了{len(results)}个搜索结果,发现关键信息..."
state["current_step"] = "analyze_results"
return state
def need_human_review(self, state: ResearchState) -> Literal["review", "continue"]:
"""判断是否需要人工审核"""
# 基于分析复杂度决定
complexity = len(state["analysis"]) > 200
return "review" if complexity else "continue"
def human_review(self, state: ResearchState):
"""人工审核"""
state["needs_human_review"] = True
state["current_step"] = "human_review"
return state
def refine_report(self, state: ResearchState):
"""精炼报告"""
state["analysis"] += " [经过人工审核精炼]"
state["current_step"] = "refine_report"
return state
def generate_report(self, state: ResearchState):
"""生成最终报告"""
state["report"] = f"""
研究报告:{state['research_topic']}
分析结果:{state['analysis']}
基于搜索:{list(state['search_results'].keys())}
""".strip()
state["current_step"] = "generate_report"
return state
# 测试复杂工作流
complex_workflow = LangGraphComplexWorkflow()
research_flow = complex_workflow.create_research_workflow()
research_result = research_flow.invoke({
"research_topic": "人工智能在医疗诊断中的应用",
"search_queries": [],
"search_results": {},
"analysis": "",
"report": "",
"current_step": "",
"needs_human_review": False
})
print("研究工作报告:")
print(research_result["report"])
5. 错误处理和恢复对比
LangChain:异常捕获模式
class LangChainErrorHandling:
"""LangChain的错误处理模式"""
def create_robust_chain(self):
"""创建带错误处理的链"""
def safe_processing(inputs):
try:
text = inputs["text"]
if len(text) < 5:
raise ValueError("文本太短")
return {"processed": text.upper()}
except Exception as e:
return {
"processed": f"错误处理: {str(e)}",
"error": True
}
robust_chain = TransformChain(
input_variables=["text"],
output_variables=["processed", "error"],
transform=safe_processing
)
return robust_chain
def demonstrate_error_handling(self):
"""演示错误处理"""
chain = self.create_robust_chain()
# 正常情况
normal_result = chain({"text": "Hello World"})
print(f"正常结果: {normal_result}")
# 错误情况
error_result = chain({"text": "Hi"})
print(f"错误处理结果: {error_result}")
error_demo = LangChainErrorHandling()
error_demo.demonstrate_error_handling()
LangGraph:状态恢复模式
class LangGraphErrorRecovery:
"""LangGraph的错误恢复模式"""
def create_fault_tolerant_workflow(self):
"""创建容错工作流"""
class RecoveryState(TypedDict):
input_data: str
processing_stage: str
attempt_count: int
max_attempts: int
final_result: str
last_error: str
workflow = StateGraph(RecoveryState)
workflow.add_node("process_data", self.process_data)
workflow.add_node("handle_error", self.handle_error)
workflow.add_node("finalize", self.finalize)
workflow.set_entry_point("process_data")
workflow.add_conditional_edges(
"process_data",
self.check_success,
{
"success": "finalize",
"retry": "handle_error",
"fail": "finalize"
}
)
workflow.add_conditional_edges(
"handle_error",
self.can_retry,
{
"retry": "process_data",
"fail": "finalize"
}
)
workflow.add_edge("finalize", END)
return workflow.compile()
def process_data(self, state: RecoveryState):
"""处理数据(可能失败)"""
state["attempt_count"] = state.get("attempt_count", 0) + 1
state["processing_stage"] = f"尝试第{state['attempt_count']}次"
# 模拟随机失败
import random
if random.random() < 0.6: # 60%失败率
raise Exception("模拟处理失败")
state["final_result"] = "处理成功!"
return state
def check_success(self, state: RecoveryState) -> Literal["success", "retry", "fail"]:
"""检查处理结果"""
if state.get("final_result"):
return "success"
elif state["attempt_count"] < state.get("max_attempts", 3):
return "retry"
else:
return "fail"
def handle_error(self, state: RecoveryState):
"""错误处理"""
state["last_error"] = "处理失败,准备重试"
state["processing_stage"] = "错误处理中"
return state
def can_retry(self, state: RecoveryState) -> Literal["retry", "fail"]:
"""判断是否可以重试"""
return "retry" if state["attempt_count"] < state.get("max_attempts", 3) else "fail"
def finalize(self, state: RecoveryState):
"""最终处理"""
if not state.get("final_result"):
state["final_result"] = f"最终失败,尝试了{state['attempt_count']}次"
state["processing_stage"] = "完成"
return state
# 测试容错工作流
recovery_demo = LangGraphErrorRecovery()
recovery_flow = recovery_demo.create_fault_tolerant_workflow()
result = recovery_flow.invoke({
"input_data": "测试数据",
"processing_stage": "",
"attempt_count": 0,
"max_attempts": 3,
"final_result": "",
"last_error": ""
})
print(f"容错处理结果: {result['final_result']}")
print(f"处理阶段: {result['processing_stage']}")
三、完整对比总结
技术特性对比表格
|
特性维度 |
LangChain |
LangGraph |
|
架构模式 |
组件化链式架构 |
图基工作流架构 |
|
状态管理 |
无状态或简单状态 |
强大的有状态管理 |
|
执行模式 |
顺序线性执行 |
条件分支、循环、并行 |
|
复杂任务 |
通过代理模式处理 |
原生支持复杂工作流 |
|
错误处理 |
异常捕获和回退 |
状态恢复和重试机制 |
|
学习曲线 |
相对平缓 |
较陡峭,需要理解图概念 |
|
适用场景 |
快速原型、简单应用 |
复杂业务逻辑、长时间运行任务 |
选择指南决策树
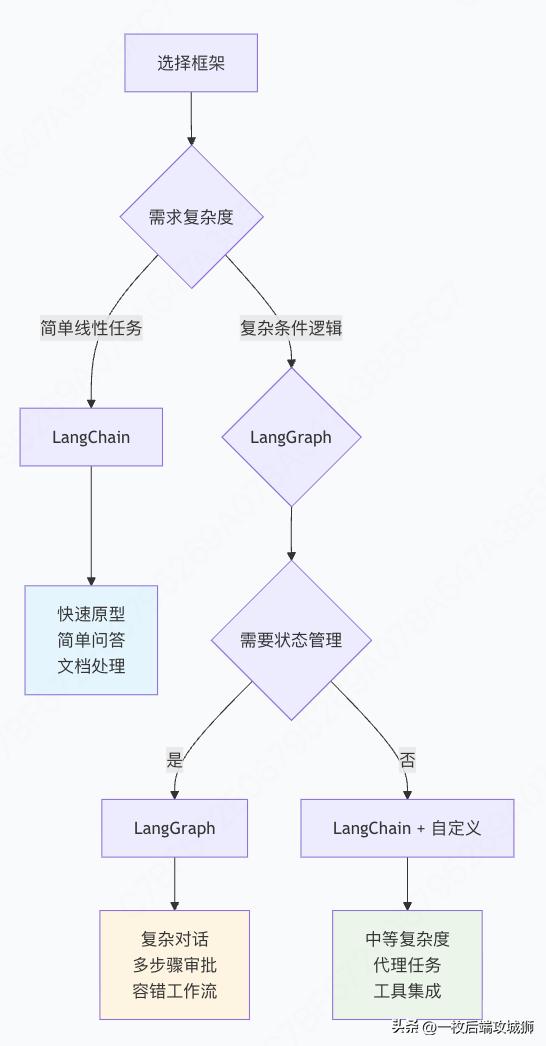
实际项目推荐
场景1:客服聊天机器人
# 推荐:LangChain
def create_customer_service_bot():
"""使用LangChain创建客服机器人"""
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
chain = ConversationChain(
llm=OpenAI(temperature=0.5),
memory=memory,
verbose=True
)
return chain
# 简单、高效,适合大多数客服场景
场景2:复杂业务流程自动化
# 推荐:LangGraph
def create_business_approval_workflow():
"""使用LangGraph创建审批工作流"""
workflow = StateGraph(ApprovalState)
workflow.add_node("submit_request", submit_request)
workflow.add_node("manager_review", manager_review)
workflow.add_node("director_approval", director_approval)
workflow.add_node("finance_check", finance_check)
workflow.add_node("finalize", finalize_approval)
# 复杂条件路由
workflow.add_conditional_edges(
"manager_review",
determine_approval_path,
{"approve": "finalize", "escalate": "director_approval", "reject": END}
)
return workflow.compile()
# 处理多条件、多审批人的复杂流程
场景3:混合使用模式
def create_hybrid_solution():
"""LangChain + LangGraph 混合解决方案"""
# 使用LangChain处理标准化组件
from langchain.chains import LLMChain
from langgraph.graph import StateGraph
class HybridState(TypedDict):
user_input: str
langchain_result: str
workflow_status: str
def langchain_processing(state: HybridState):
"""使用LangChain处理文本"""
# 在这里集成LangChain链
prompt = PromptTemplate(...)
chain = LLMChain(...)
state["langchain_result"] = chain.run(state["user_input"])
return state
# 使用LangGraph管理复杂工作流
workflow = StateGraph(HybridState)
workflow.add_node("langchain_processing", langchain_processing)
# ... 添加更多节点和边
return workflow.compile()
总结:互补的技术双星
LangChain和LangGraph不是竞争关系,而是互补的技术栈,共同构成了大模型应用开发的完整解决方案:
核心价值总结
- LangChain:标准化与效率
- 提供标准化组件,降低开发门槛
- 快速原型开发,验证想法
- 丰富的生态系统和工具集成
- LangGraph:复杂性与控制
- 处理复杂业务逻辑和状态管理
- 提供细粒度控制和错误恢复
- 支持长时间运行的复杂工作流
演进关系

最佳实践建议
- 从LangChain开始:新项目建议从LangChain起步,快速验证核心逻辑
- 按需引入LangGraph:当业务逻辑变得复杂,需要状态管理、条件分支时引入
- 混合使用:在复杂系统中,可以同时使用两者,各取所长
- 团队技能匹配:考虑团队的技术背景和学习成本
正如LangChain创始人Harrison Chase所言:"LangGraph是为了解决LangChain处理复杂工作流时的局限性而生的。" 这两个框架共同为开发者提供了从简单到复杂、从原型到生产的完整工具链。
选择不是二选一,而是根据你的具体需求找到最适合的技术组合。在AI应用开发的道路上,它们是你不可或缺的得力助手。


















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











