




一、什么是Transformer自注意力机制?
核心定义
自注意力机制是Transformer架构的核心组件,它允许序列中的每个元素直接与所有其他元素进行交互和关联,从而动态计算每个位置在理解当前元素时应该关注序列中的哪些部分。
与传统注意力的区别
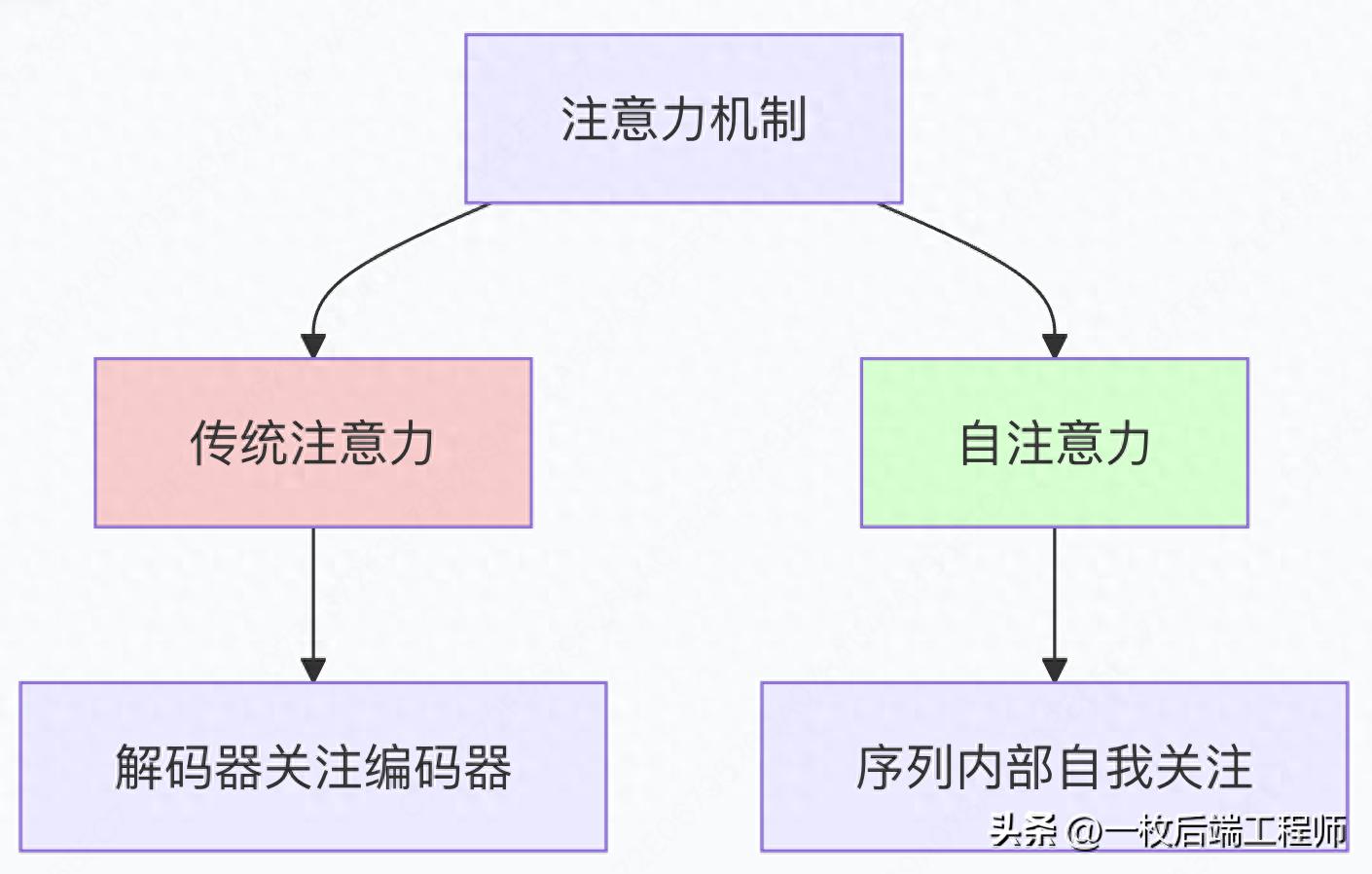
传统注意力(编码器-解码器注意力):
- 解码器查询 ↔ 编码器键值对
- 用于连接两个不同序列
自注意力(Self-Attention):
- 序列内部自我查询
- 每个元素既是查询者也是被查询者
生动比喻:侦探破案会议
想象一个侦探在分析案件陈述:
"银行劫匪开车逃离了现场,因为他害怕被抓住。"
传统方法(类似RNN):
- 按顺序分析每个词
- 读到"他"时,可能已经淡忘了前面"劫匪"的细节
自注意力方法:
- 把所有证词同时摊开在桌上
- 专门分析"他"时,直接查看所有其他词
- 发现"他"与"劫匪"关联度最高
- 立即明白指代关系
二、自注意力机制为什么重要?
革命性的价值主张
1.彻底解决长距离依赖问题

实际例子:
句子:"虽然昨天天气很差,还下着大雨,而且路上很堵,但我们还是决定按照原计划,开车去那个位于城市另一端的新开张的餐厅吃饭。" 传统RNN:读到"餐厅"时,可能已经忘了"天气"的信息 自注意力:"餐厅"可以直接关联到"天气"、"大雨"、"堵车"等所有相关信息
2.完美的计算并行性
RNN的计算模式:
时间步1 → 时间步2 → 时间步3 → ... → 时间步n
↓ ↓ ↓ ↓
计算1 计算2 计算3 ... 计算n
(必须顺序执行)
自注意力的计算模式:
所有时间步
↓
同时计算
↓
同时输出
3.前所未有的可解释性
自注意力权重矩阵就像模型的"思考过程记录":
# 假设的注意力权重矩阵 # 我 喜欢 吃 苹果 因为 它 很 甜 # 我 0.8 0.1 0.05 0.02 0.01 0.01 0.01 0.0 # 喜欢 0.1 0.6 0.2 0.05 0.03 0.01 0.01 0.0 # 吃 0.05 0.1 0.5 0.3 0.03 0.01 0.01 0.0 # 苹果 0.02 0.05 0.2 0.4 0.2 0.1 0.02 0.01 # 因为 0.01 0.02 0.05 0.1 0.6 0.1 0.1 0.02 # 它 0.0 0.0 0.0 0.6 0.1 0.2 0.05 0.05 # 很 0.0 0.0 0.0 0.1 0.1 0.1 0.5 0.2 # 甜 0.0 0.0 0.0 0.05 0.05 0.05 0.2 0.65
从矩阵中可以看到:
- "它"主要关注"苹果"(权重0.6)
- "甜"主要关注"很"和"苹果"
三、自注意力机制解决了什么问题或痛点?
痛点1:RNN的"记忆衰减"问题

RNN的信息流:
问题:信息从词1传递到词n时,就像"传话游戏",原始信息严重失真。
自注意力解决方案:
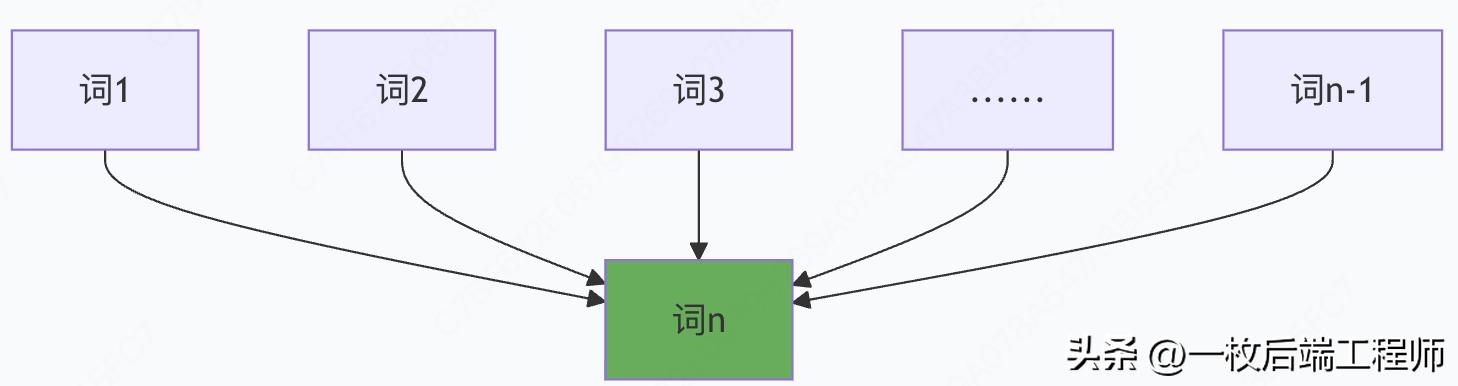
每个词都可以直接访问所有其他词,无信息衰减。
痛点2:CNN的"局部视野"局限
CNN的感受野:
层1: [词1, 词2, 词3] [词4, 词5, 词6] ... 层2: [特征1, 特征2, 特征3] ... 层3: [更全局特征] ...
需要多层堆叠才能获得全局视野,且感受野受架构限制。
自注意力的全局视野:
单层即可看到: [所有词的所有关系]
痛点3:计算效率的"顺序瓶颈"
RNN训练时间:与序列长度呈线性关系,且无法并行
训练时间 ≈ O(n × batch_size)
自注意力训练时间:理论上与序列长度平方相关,但完全并行
训练时间 ≈ O(1) # 得益于并行化,实际常数时间
痛点4:复杂模式的"表示能力不足"
传统方法难以处理的现象:
- 长距离指代:
"那个穿着红色外套,戴着墨镜,手里拿着公文包,刚刚从出租车上下来的男人" → "他" - 多义词理解:
"苹果很好吃" vs "苹果发布了新手机" - 复杂语法结构:
"The horse raced past the barn fell."
自注意力的优势:通过直接连接和动态权重,自然处理所有这些复杂情况。
四、深入理解K、V、Q三要素
K、V、Q的核心角色
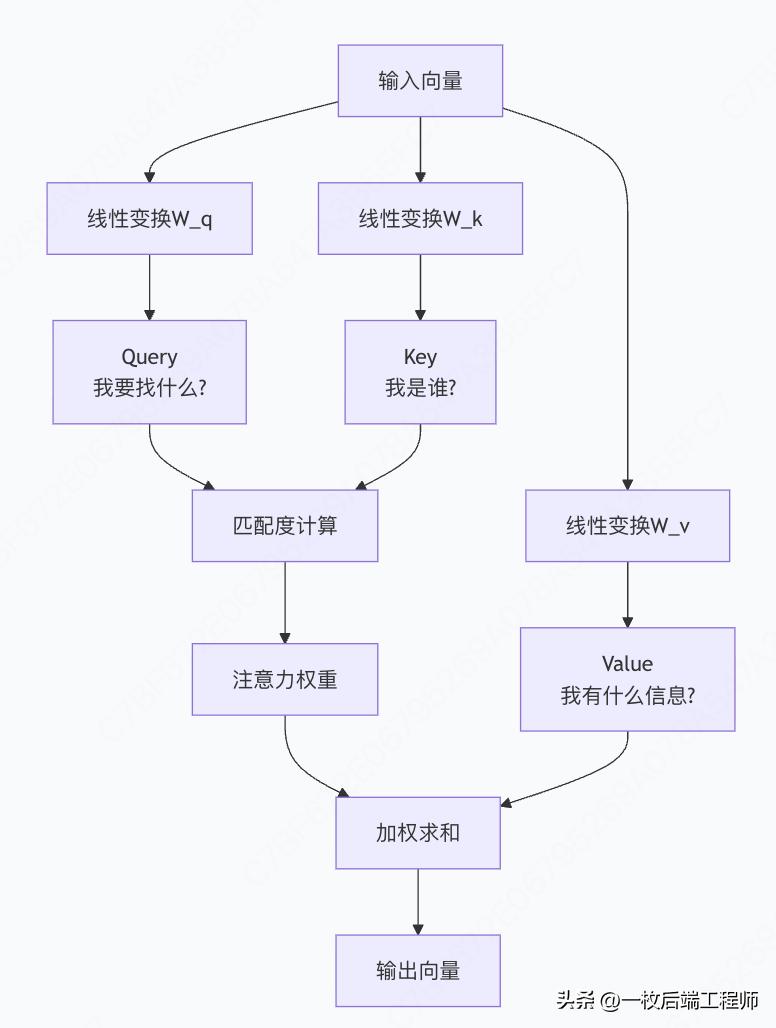
生动比喻:图书馆检索系统
想象你在图书馆研究"人工智能":
Query:你的研究问题
- "我要找关于人工智能伦理的书籍"
- 这是你主动提出的查询
Key:书籍的索引标签
- 每本书都有索引号:《AI基础》(关键词:机器学习)、
《伦理问题》(关键词:人工智能, 伦理)、《技术原理》(关键词:深度学习) - 这些是书籍的身份标识
Value:书籍的实际内容
- 《伦理问题》这本书的完整文本内容
- 这是你真正想获取的价值信息
检索过程:
- 匹配:用你的Query("人工智能伦理")与所有书的Key进行匹配
- 评分:《伦理问题》匹配度最高(因为它有"人工智能"和"伦理"关键词)
- 获取:重点阅读《伦理问题》的内容(Value)
数学公式详解
步骤1:生成Q、K、V
对于每个词向量 x_i: Q_i = x_i × W_Q # 查询向量 K_i = x_i × W_K # 键向量 V_i = x_i × W_V # 值向量
步骤2:计算注意力分数
注意力分数 = softmax( Q × K^T / √d_k )
为什么要除以√d_k?
- 防止点积结果过大导致softmax梯度消失
- 维度d_k越大,点积结果倾向于越大,需要缩放
步骤3:加权合成输出
输出 = 注意力权重 × V
实际计算示例
假设句子:"猫 吃了 鱼 因为 它 饿了"
计算"它"的自注意力:
# 伪代码示例
query_它 = 嵌入("它") × W_Q
keys = [嵌入("猫")×W_K, 嵌入("吃了")×W_K, ..., 嵌入("饿了")×W_K]
values = [嵌入("猫")×W_V, 嵌入("吃了")×W_V, ..., 嵌入("饿了")×W_V]
# 计算相似度
scores = []
for key in keys:
score = dot_product(query_它, key) / √d_k
scores.append(score)
# 归一化权重
weights = softmax(scores) # 比如: [0.6, 0.05, 0.1, 0.05, 0.05, 0.15]
# 加权求和
output_它 = 0.6×values[0] + 0.05×values[1] + 0.1×values[2] + ... + 0.15×values[5]
现在,"它"的输出向量中包含了60%的"猫"的信息!
多头注意力:多专家委员会
单一注意力可能只关注一种关系模式,多头注意力让模型同时学习多种关注模式:
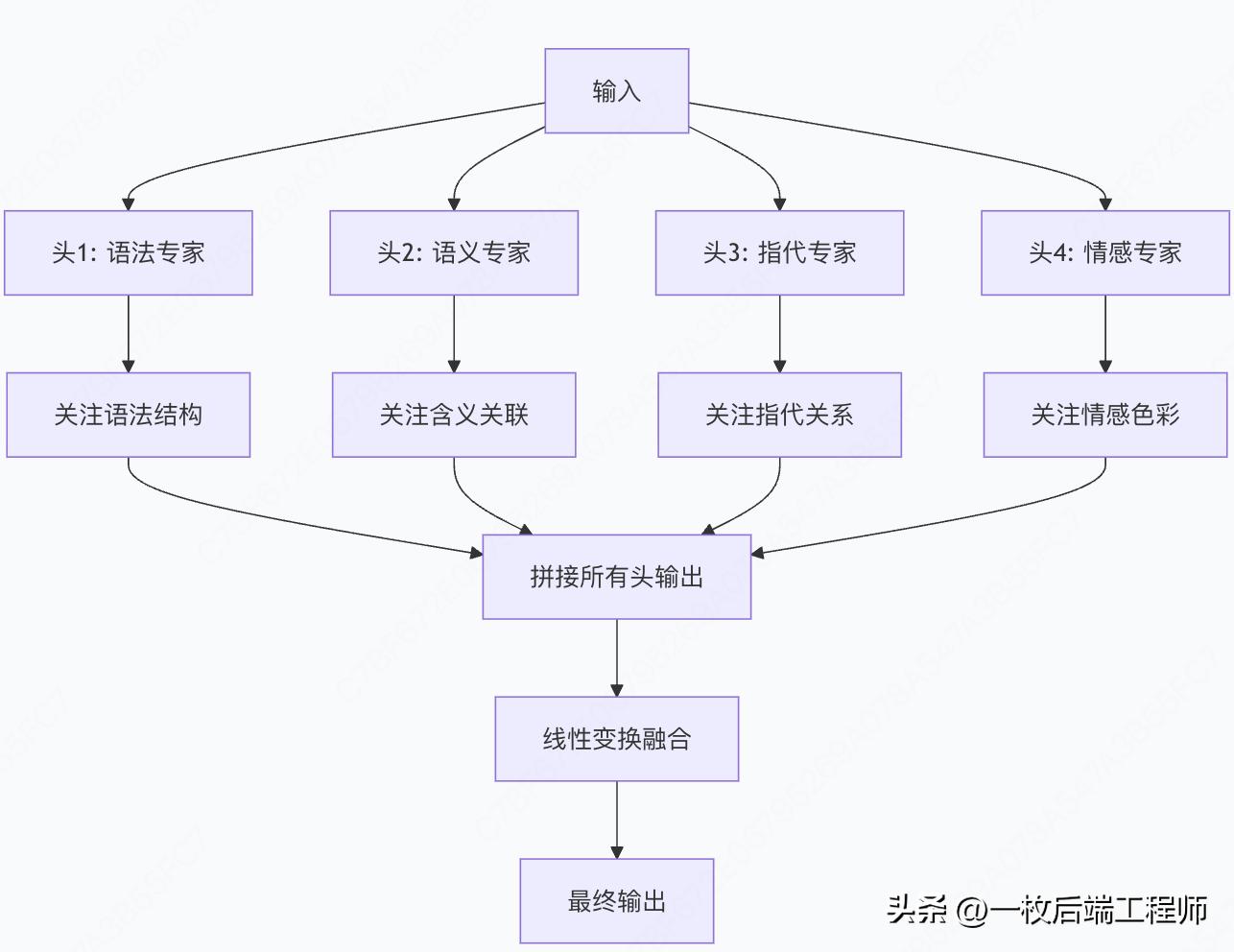
每个头都有自己的W_Q、W_K、W_V矩阵,学习不同的关注模式。
总结:自注意力的革命性意义
自注意力机制之所以如此重要,是因为它从根本上重新思考了序列建模的方式:
从"渐进理解"到"全局洞察"
- 传统方法:像按顺序拼拼图,只能基于相邻碎片推理
- 自注意力:像把拼图全部摊开,一眼看到完整画面和所有关系
从"硬件限制"到"算法创新"
- 不再受限于序列处理的顺序瓶颈
- 充分利用现代硬件的并行计算能力
- 让模型规模可以几乎无限扩展
从"黑箱模型"到"可解释决策"
- 注意力权重提供了模型"思考过程"的窗口
- 可以直观理解模型为何做出特定决策
- 为可信AI和模型调试提供基础
自注意力机制不仅是技术突破,更是思维范式的转变——它证明有时候,放弃传统的归纳偏置,让数据自己说话,反而能获得更强大的能力。这正是Transformer架构能够在众多领域取得突破性进展的根本原因。


















 5877
5877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











