




1. 人工智能发展历程概述
1.1 从机器学习到深度学习
人工智能的发展经历了从传统机器学习到深度学习的革命性转变:
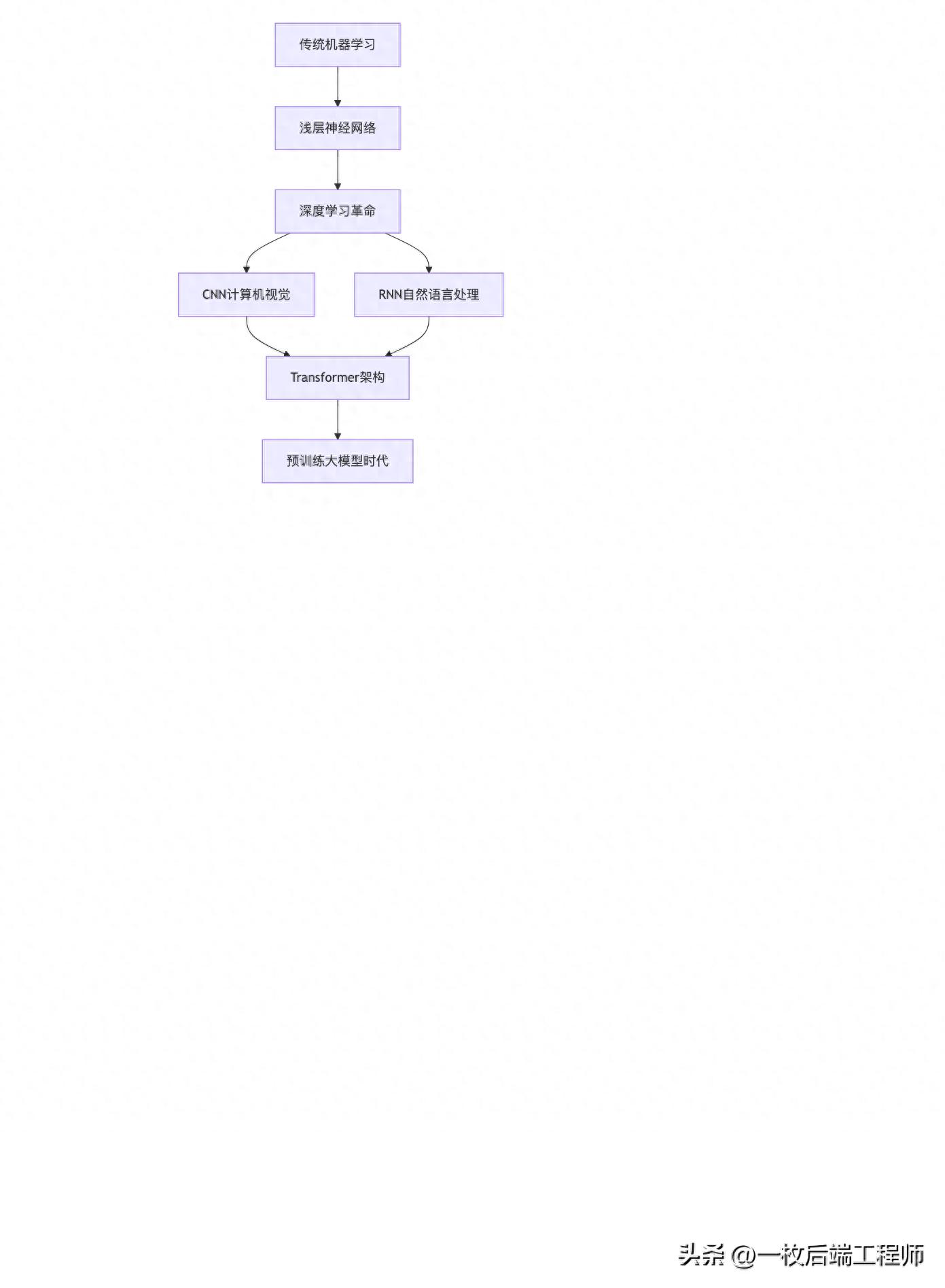
关键发展阶段:
- 1950s-1980s:符号主义AI,基于规则的专家系统
- 1990s-2000s:统计机器学习(SVM、决策树、随机森林)
- 2012年:AlexNet开启深度学习革命
- 2017年:Transformer架构诞生
- 2018年至今:预训练大模型时代
1.2 关键算法演进
|
时期 |
核心技术 |
主要应用 |
局限性 |
|
2000年前 |
贝叶斯网络、SVM |
分类、回归 |
特征工程依赖性强 |
|
2006-2011 |
自编码器、RBM |
降维、推荐系统 |
训练难度大 |
|
2012-2016 |
CNN、RNN、LSTM |
图像识别、语音识别 |
任务特异性强 |
|
2017至今 |
Transformer、注意力机制 |
多模态任务 |
计算资源需求大 |
2. 神经网络基础架构演进
2.1 卷积神经网络(CNN)
核心思想:局部连接、权重共享、池化操作
import tensorflow as tf
from tensorflow.keras import layers
# 经典的CNN架构示例
def build_cnn_model():
model = tf.keras.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
return model
# 代表性CNN模型发展
cnn_evolution = {
"LeNet-5 (1998)": "首个成功CNN,手写数字识别",
"AlexNet (2012)": "ReLU、Dropout、GPU训练",
"VGG (2014)": "深层网络结构",
"ResNet (2015)": "残差连接解决梯度消失",
"EfficientNet (2019)": "复合模型缩放"
}
2.2 循环神经网络(RNN)与LSTM
RNN核心结构:
ht = tanh(Wxh * Xt + Whh * ht-1 + bh) yt = Why * ht + by
LSTM改进:引入门控机制(输入门、遗忘门、输出门)
class LSTMCell(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
self.units = units
def build(self, input_shape):
# 输入门、遗忘门、输出门、候选细胞状态
self.w_i = self.add_weight(shape=(input_shape[-1], self.units))
self.w_f = self.add_weight(shape=(input_shape[-1], self.units))
self.w_o = self.add_weight(shape=(input_shape[-1], self.units))
self.w_c = self.add_weight(shape=(input_shape[-1], self.units))
def call(self, inputs, states):
h_prev, c_prev = states
# 门控计算
i = tf.sigmoid(tf.matmul(inputs, self.w_i))
f = tf.sigmoid(tf.matmul(inputs, self.w_f))
o = tf.sigmoid(tf.matmul(inputs, self.w_o))
# 候选细胞状态
c_hat = tf.tanh(tf.matmul(inputs, self.w_c))
# 更新细胞状态
c = f * c_prev + i * c_hat
# 更新隐藏状态
h = o * tf.tanh(c)
return h, (h, c)
3. 深度学习框架发展
3.1 TensorFlow生态系统
import tensorflow as tf
# TensorFlow 2.x 的eager execution模式
# 构建模型示例
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译和训练
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 分布式训练策略
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
# 在策略范围内构建模型
distributed_model = create_model()
TensorFlow核心组件:
- Keras:高级API,快速原型开发
- tf.data:高效数据流水线
- TFX:生产级机器学习流水线
- TensorBoard:可视化工具
4. Transformer架构革命
4.1 核心架构解析
原始论文:Attention Is All You Need
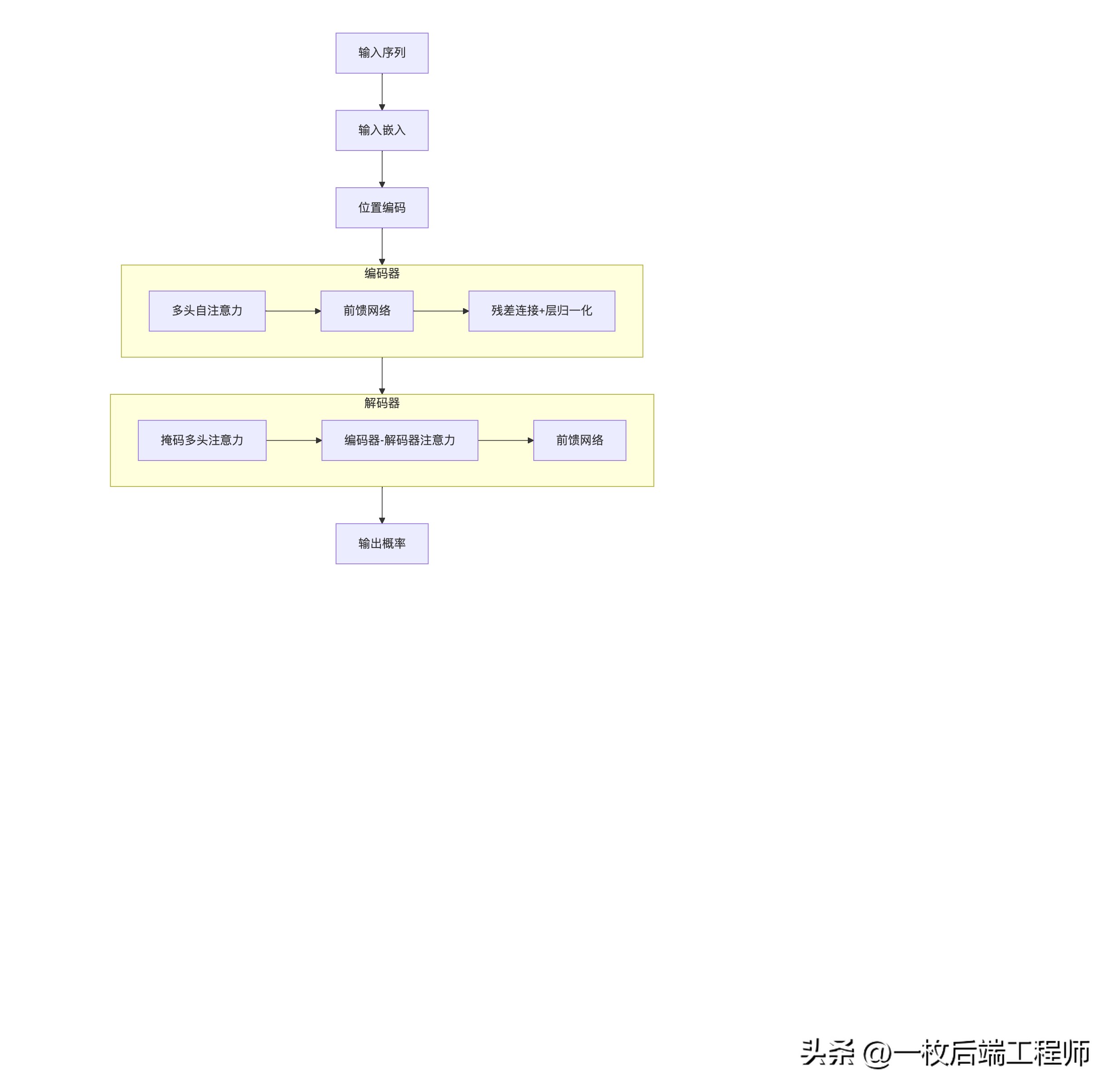
4.2 自注意力机制数学表达
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, q, k, v, mask=None):
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
attn_probs = torch.softmax(attn_scores, dim=-1)
output = torch.matmul(attn_probs, v)
return output
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 线性变换并分头
q = self.w_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
k = self.w_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
v = self.w_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 自注意力计算
attn_output = self.scaled_dot_product_attention(q, k, v, mask)
# 合并多头输出
attn_output = attn_output.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model
)
return self.w_o(attn_output)
5. 预训练语言模型革命
5.1 BERT:双向编码器表示
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
# BERT的核心预训练任务
class BertPretraining(nn.Module):
def __init__(self, config):
super().__init__()
self.bert = BertModel(config)
self.mlm_head = MaskedLMPredictionHead(config)
self.nsp_head = NextSentencePredictionHead(config)
def forward(self, input_ids, token_type_ids, attention_mask):
sequence_output, pooled_output = self.bert(
input_ids, token_type_ids, attention_mask
)
# 掩码语言模型任务
mlm_scores = self.mlm_head(sequence_output)
# 下一句预测任务
nsp_scores = self.nsp_head(pooled_output)
return mlm_scores, nsp_scores
# BERT的输入表示
"""
[CLS] sentence1 [SEP] sentence2 [SEP]
| | | | |
嵌入 = 词嵌入 + 段嵌入 + 位置嵌入
"""
5.2 GPT系列:自回归语言模型
GPT发展历程:
|
模型 |
参数量 |
关键创新 |
发布时间 |
|
GPT |
1.17亿 |
Transformer解码器 |
2018.06 |
|
GPT-2 |
15亿 |
零样本学习、更大规模 |
2019.02 |
|
GPT-3 |
1750亿 |
上下文学习、思维链 |
2020.05 |
|
GPT-4 |
未公开 |
多模态、强化学习优化 |
2023.03 |
# GPT风格的自回归生成
class GPTGeneration:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
def generate_text(self, prompt, max_length=100, temperature=0.8):
input_ids = self.tokenizer.encode(prompt, return_tensors="pt")
for _ in range(max_length):
outputs = self.model(input_ids)
next_token_logits = outputs.logits[:, -1, :]
# 温度采样
next_token_logits = next_token_logits / temperature
next_token_probs = torch.softmax(next_token_logits, dim=-1)
next_token_id = torch.multinomial(next_token_probs, num_samples=1)
input_ids = torch.cat([input_ids, next_token_id], dim=1)
if next_token_id.item() == self.tokenizer.eos_token_id:
break
return self.tokenizer.decode(input_ids[0], skip_special_tokens=True)
6. 现代大模型生态系统
6.1 主流大模型对比
|
模型 |
开发机构 |
参数量 |
主要特点 |
开源情况 |
|
ChatGPT |
OpenAI |
1750亿+ |
对话优化、指令遵循 |
闭源 |
|
DeepSeek |
深度求索 |
670亿 |
高质量中文、开源 |
开源 |
|
Qwen |
阿里巴巴 |
720亿 |
多语言、代码能力 |
开源 |
|
LLaMA |
Meta |
70-650亿 |
高效架构、研究友好 |
开源 |
|
Claude |
Anthropic |
未公开 |
宪法AI、安全性 |
闭源 |
6.2 大模型训练技术栈
# 典型的大模型训练配置
training_config:
hardware:
gpu: "8x A100 80GB"
interconnect: "NVLink + InfiniBand"
data_pipeline:
preprocessing: "tokenization, filtering"
dataset_size: "1TB+ 文本数据"
data_parallelism: "sharded data loading"
model_parallelism:
tensor_parallel: 8
pipeline_parallel: 4
sequence_parallel: true
optimization:
precision: "bfloat16"
optimizer: "AdamW"
learning_rate: "1e-4 with cosine decay"
gradient_clipping: 1.0
checkpointing:
frequency: "every 1000 steps"
strategy: "async checkpointing"
7. 大模型训练全流程
7.1 预训练阶段
# 简化的预训练代码框架
class Pretrainer:
def __init__(self, model_config, training_config):
self.model = initialize_model(model_config)
self.optimizer = configure_optimizer(self.model, training_config)
self.dataloader = create_pretraining_dataloader(training_config)
def pretrain_epoch(self):
self.model.train()
total_loss = 0
for batch in self.dataloader:
inputs, labels = batch
# 前向传播
outputs = self.model(inputs)
loss = self.compute_loss(outputs, labels)
# 反向传播
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 1.0)
self.optimizer.step()
total_loss += loss.item()
return total_loss / len(self.dataloader)
def compute_loss(self, outputs, labels):
# 语言建模损失
logits = outputs.logits
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = torch.nn.CrossEntropyLoss()
return loss_fct(shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1))
7.2 指令微调与对齐
# 指令微调实现
class InstructionTuning:
def __init__(self, base_model, tokenizer):
self.model = base_model
self.tokenizer = tokenizer
def format_instruction_data(self, instruction, input_text, output_text):
"""格式化指令数据"""
prompt = f"### Instruction:\n{instruction}\n\n"
if input_text:
prompt += f"### Input:\n{input_text}\n\n"
prompt += f"### Response:\n{output_text}"
return self.tokenizer(prompt, truncation=True, padding=True)
def sft_training(self, dataset, epochs=3):
"""监督微调训练"""
optimizer = torch.optim.AdamW(self.model.parameters(), lr=2e-5)
for epoch in range(epochs):
for batch in dataset:
inputs = batch["input_ids"]
attention_mask = batch["attention_mask"]
labels = batch["labels"]
outputs = self.model(
input_ids=inputs,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
8. 大模型推理与服务
8.1 推理优化技术
# 使用vLLM进行高效推理
from vLLM import LLM, SamplingParams
class ModelServer:
def __init__(self, model_path):
# 初始化模型,启用PagedAttention
self.llm = LLM(
model=model_path,
tensor_parallel_size=4,
gpu_memory_utilization=0.9,
max_model_len=8192
)
def generate(self, prompts, **kwargs):
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512,
stop_token_ids=[self.llm.get_tokenizer().eos_token_id]
)
outputs = self.llm.generate(prompts, sampling_params)
return [output.outputs[0].text for output in outputs]
# 量化推理示例
def load_quantized_model(model_path):
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=quantization_config,
device_map="auto"
)
return model
8.2 聊天系统架构
class ChatSystem:
def __init__(self, model, tokenizer, system_prompt=None):
self.model = model
self.tokenizer = tokenizer
self.system_prompt = system_prompt or "你是一个有帮助的AI助手。"
self.conversation_history = []
def format_chat_template(self, messages):
"""格式化聊天模板"""
formatted = []
for msg in messages:
if msg["role"] == "system":
formatted.append(f"<|system|>\n{msg['content']}</s>")
elif msg["role"] == "user":
formatted.append(f"<|user|>\n{msg['content']}</s>")
elif msg["role"] == "assistant":
formatted.append(f"<|assistant|>\n{msg['content']}</s>")
return "".join(formatted) + "<|assistant|>\n"
def chat(self, user_input, max_tokens=500, temperature=0.7):
"""处理用户输入并生成回复"""
# 更新对话历史
self.conversation_history.append({"role": "user", "content": user_input})
# 构建完整对话上下文
full_conversation = [{"role": "system", "content": self.system_prompt}]
full_conversation.extend(self.conversation_history)
# 格式化输入
formatted_input = self.format_chat_template(full_conversation)
input_ids = self.tokenizer.encode(formatted_input, return_tensors="pt")
# 生成回复
with torch.no_grad():
outputs = self.model.generate(
input_ids,
max_new_tokens=max_tokens,
temperature=temperature,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id,
eos_token_id=self.tokenizer.eos_token_id
)
# 提取新生成的回复
response_ids = outputs[0][len(input_ids[0]):]
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# 更新对话历史
self.conversation_history.append({"role": "assistant", "content": response})
return response
9. 未来发展趋势与挑战
9.1 技术发展方向
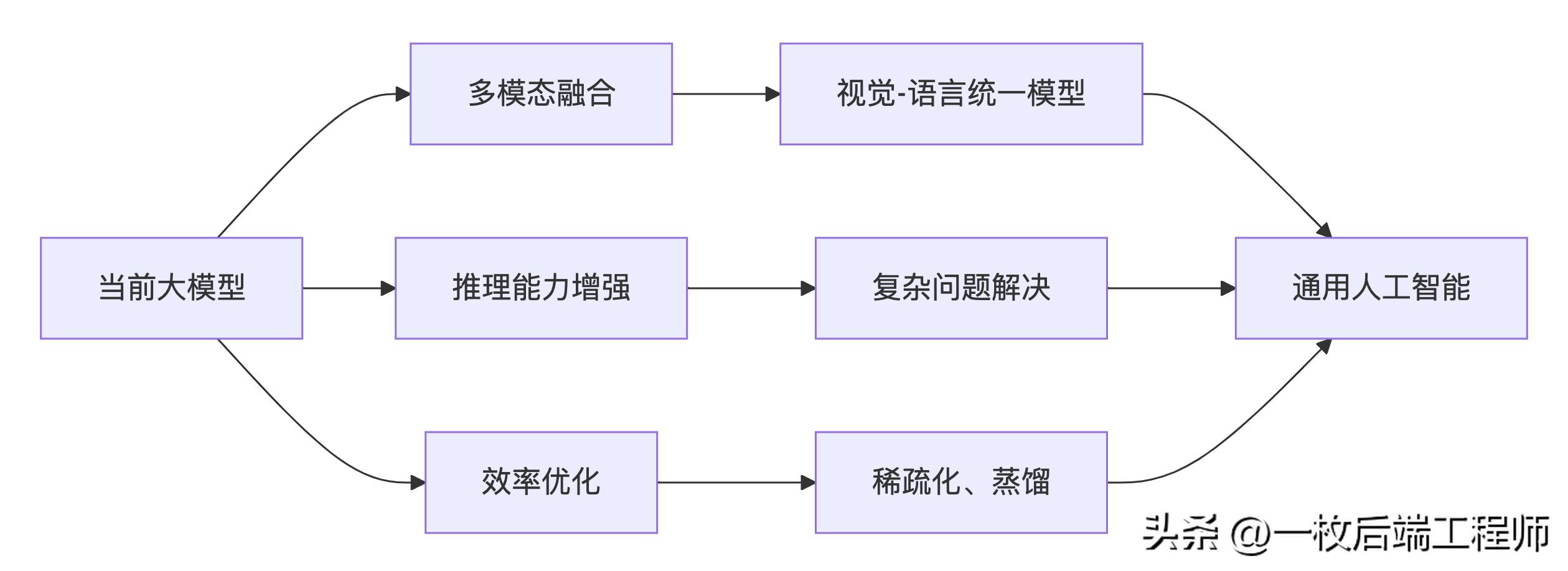
9.2 主要挑战与解决方案
|
挑战类别 |
具体问题 |
现有解决方案 |
|
计算资源 |
训练成本高 |
模型蒸馏、量化、MoE架构 |
|
推理能力 |
逻辑推理弱 |
思维链、程序辅助推理 |
|
安全性 |
幻觉、偏见 |
强化学习对齐、红队测试 |
|
知识更新 |
知识截止 |
RAG、持续学习 |
|
部署成本 |
推理延迟 |
模型压缩、专用硬件 |
总结
AI大模型技术的发展经历了从传统的机器学习到深度学习,再到基于Transformer的预训练大模型的演进过程。这一演进不仅带来了技术能力的质的飞跃,也彻底改变了人机交互的方式。
关键技术里程碑:
- 理论基础:注意力机制解决了长距离依赖问题
- 架构突破:Transformer成为大模型的基础构建块
- 规模化效应:模型参数量与数据规模的指数增长
- 对齐技术:RLHF等技术使模型更好地理解人类意图
当前,大模型技术仍在快速发展中,未来的重点将集中在多模态能力、推理能力提升、效率优化和安全性保障等方向。开源社区与商业公司的共同努力,正在推动这一技术向更加普惠和可用的方向发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











