




一、什么是Transformer?
核心定义
Transformer是一种基于自注意力机制的神经网络架构,专门设计用于处理序列数据,但完全摒弃了传统的循环和卷积结构。它于2017年由Google在论文《Attention Is All You Need》中首次提出。
历史地位:序列建模的范式转移
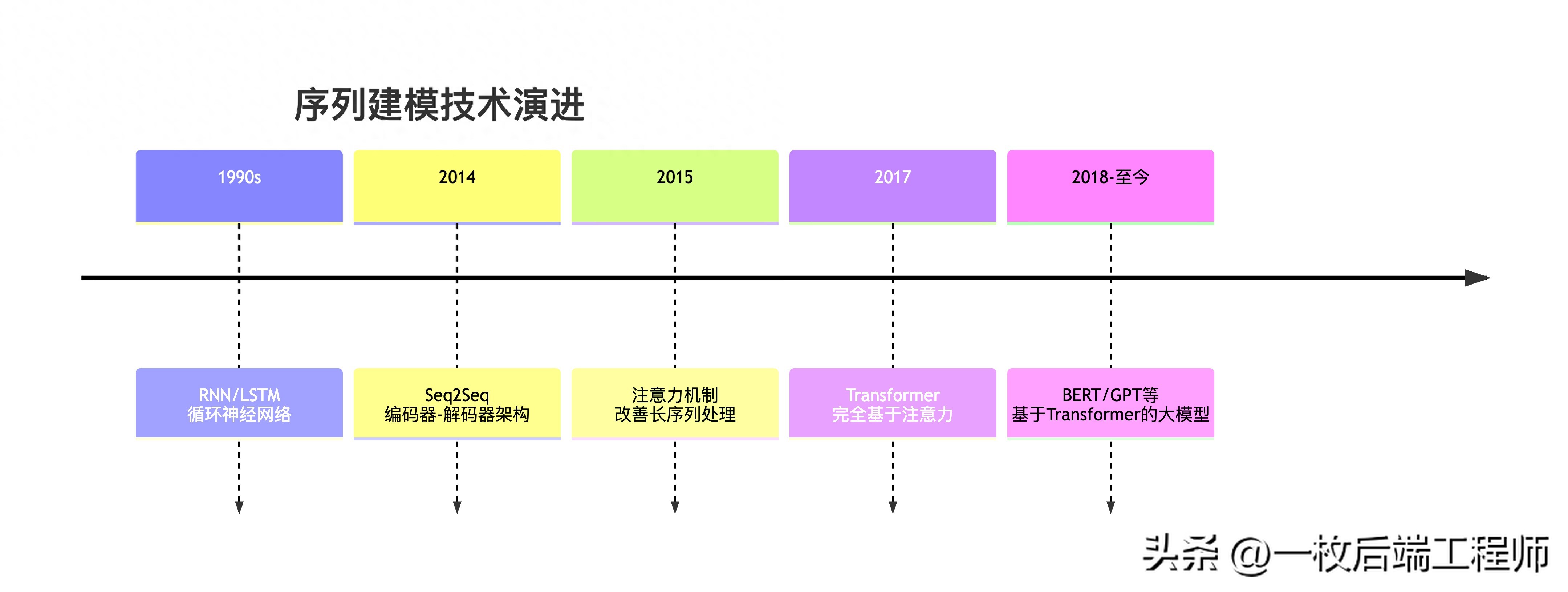
核心价值主张
传统RNN的顺序处理瓶颈:
输入: [词1] → [词2] → [词3] → ... → [词n]
↓ ↓ ↓ ↓
隐藏: [h1] → [h2] → [h3] → ... → [hn]
问题:必须按顺序处理,无法并行;长距离依赖容易丢失。
Transformer的并行处理革命:
所有词一次性输入 → 自注意力机制 → 所有词同时输出
完全并行,任意词直接交互
生动比喻:从接力赛到圆桌会议
- RNN/LSTM:像接力赛跑
-
- 每个选手(词)必须等待前一个选手传递接力棒(隐藏状态)
- 信息在传递过程中会衰减或丢失
- 只能单向顺序进行
- Transformer:像圆桌会议
-
- 所有参会者(词)同时发言和倾听
- 每个人都能直接与任何其他人交流
- 自由、并行、全方位的沟通
二、Transformer架构的编码器和解码器
整体架构俯瞰

编码器:深度理解专家团队
编码器由N个(原文N=6)完全相同的层堆叠而成,每层包含两个核心子层:
编码器层详细结构

比喻:编码器就像一群文本理解专家组成的流水线:
- 每个专家都对文本进行一轮深度分析
- 每轮分析都在前一轮的基础上深化理解
- 最终产出包含全文精髓的"理解向量"
解码器:序列生成艺术家
解码器同样由N个相同层堆叠,但结构更复杂,包含三个核心子层:
解码器层详细结构
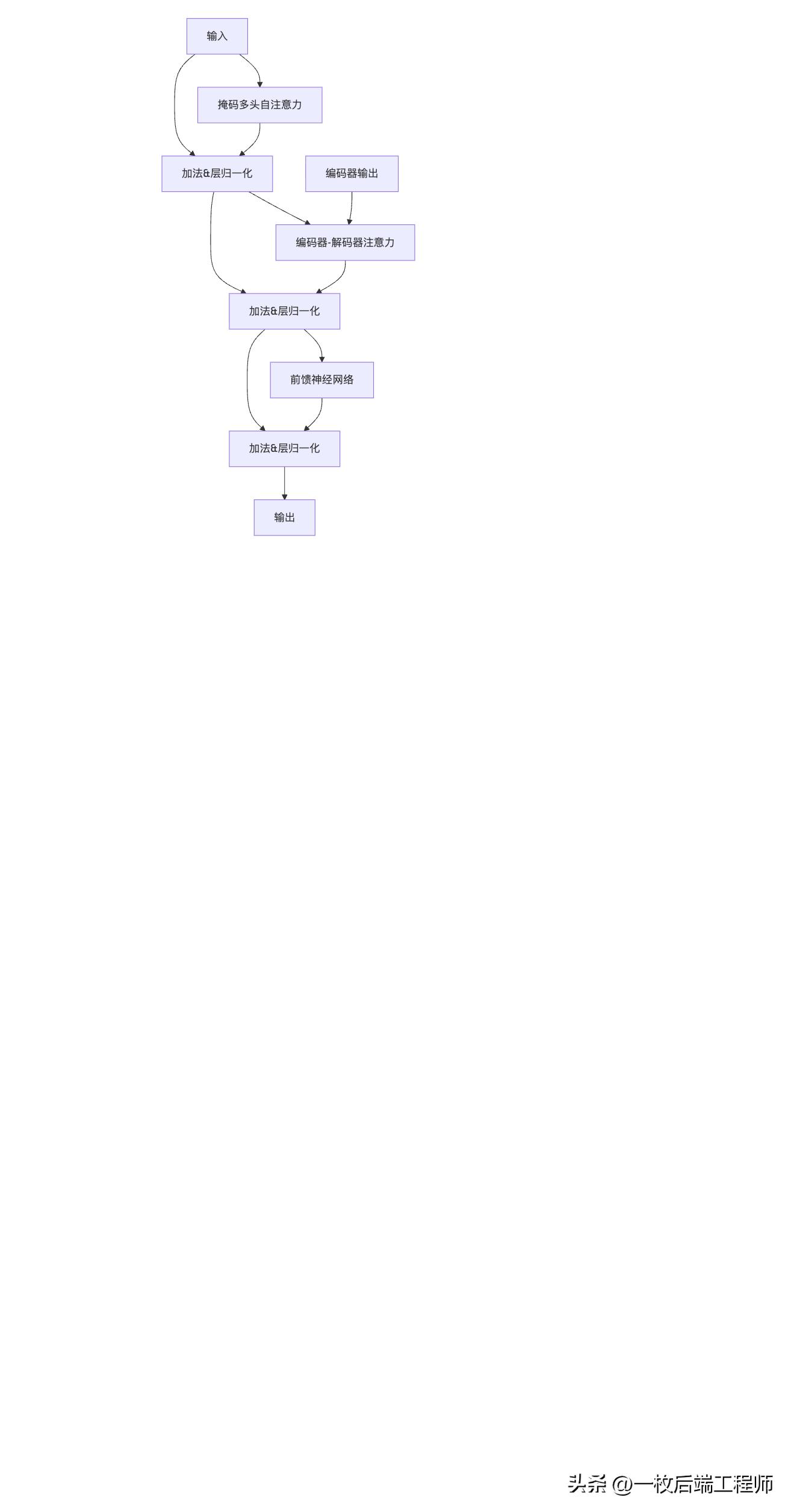
三个关键设计:
- 掩码自注意力:防止"偷看未来"
- text
- 生成第3个词时,只能看: [, 词1, 词2] 不能看: [词3, 词4, ...] (尚未生成)
- 编码器-解码器注意力:连接理解与生成
- Query来自解码器("我要生成什么?")
- Key和Value来自编码器("原文说了什么?")
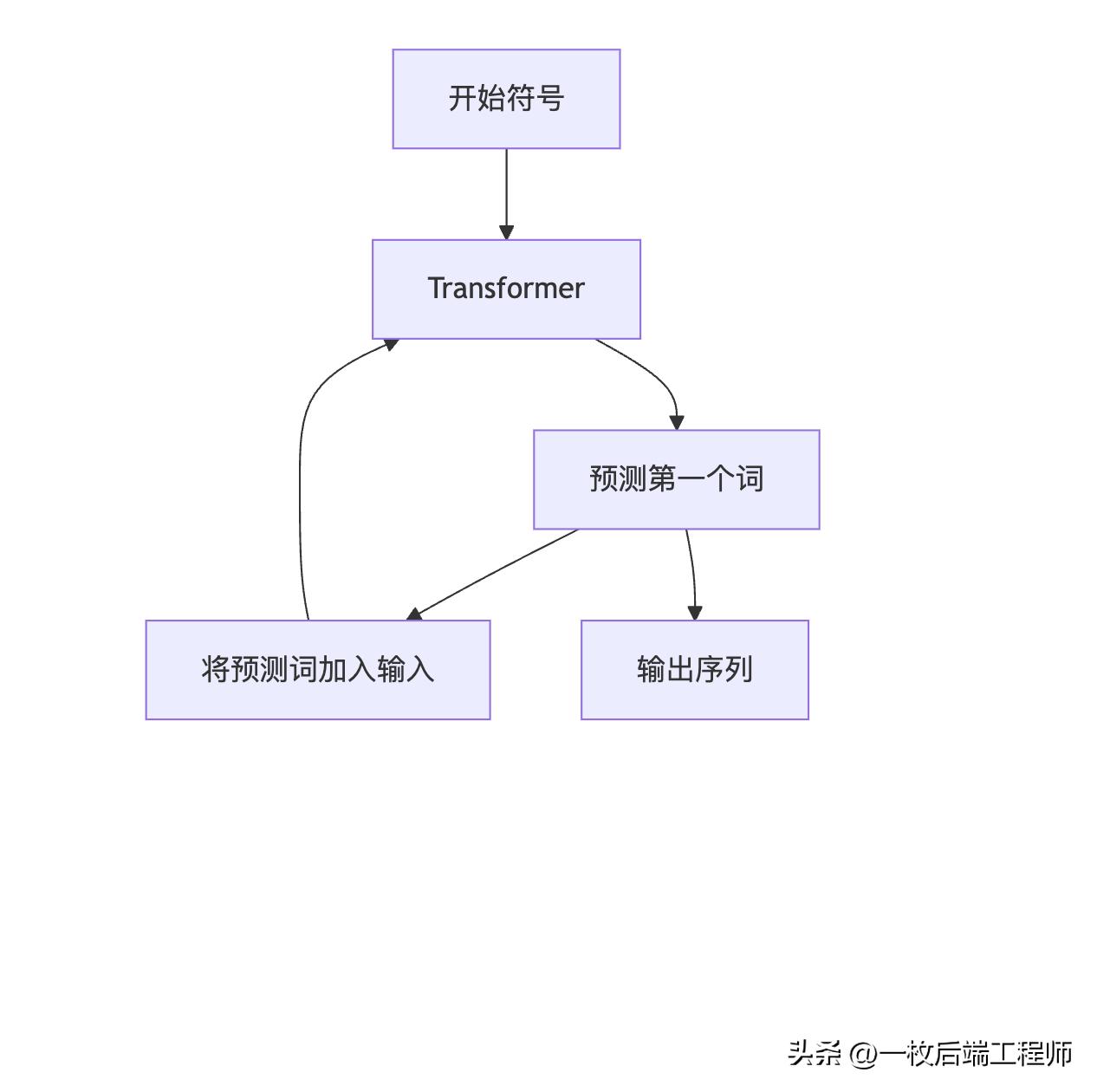
- 自回归生成:逐词生成输出
- text
- 输入: → 模型 → 输出: 词1 输入: 词1 → 模型 → 输出: 词2 输入: 词1 词2 → 模型 → 输出: 词3
三、Transformer的最大特点:自注意力机制
自注意力的核心思想
传统注意力:让解码器关注编码器的不同部分
自注意力:让序列中的每个元素关注序列中的所有元素
三步流程详解
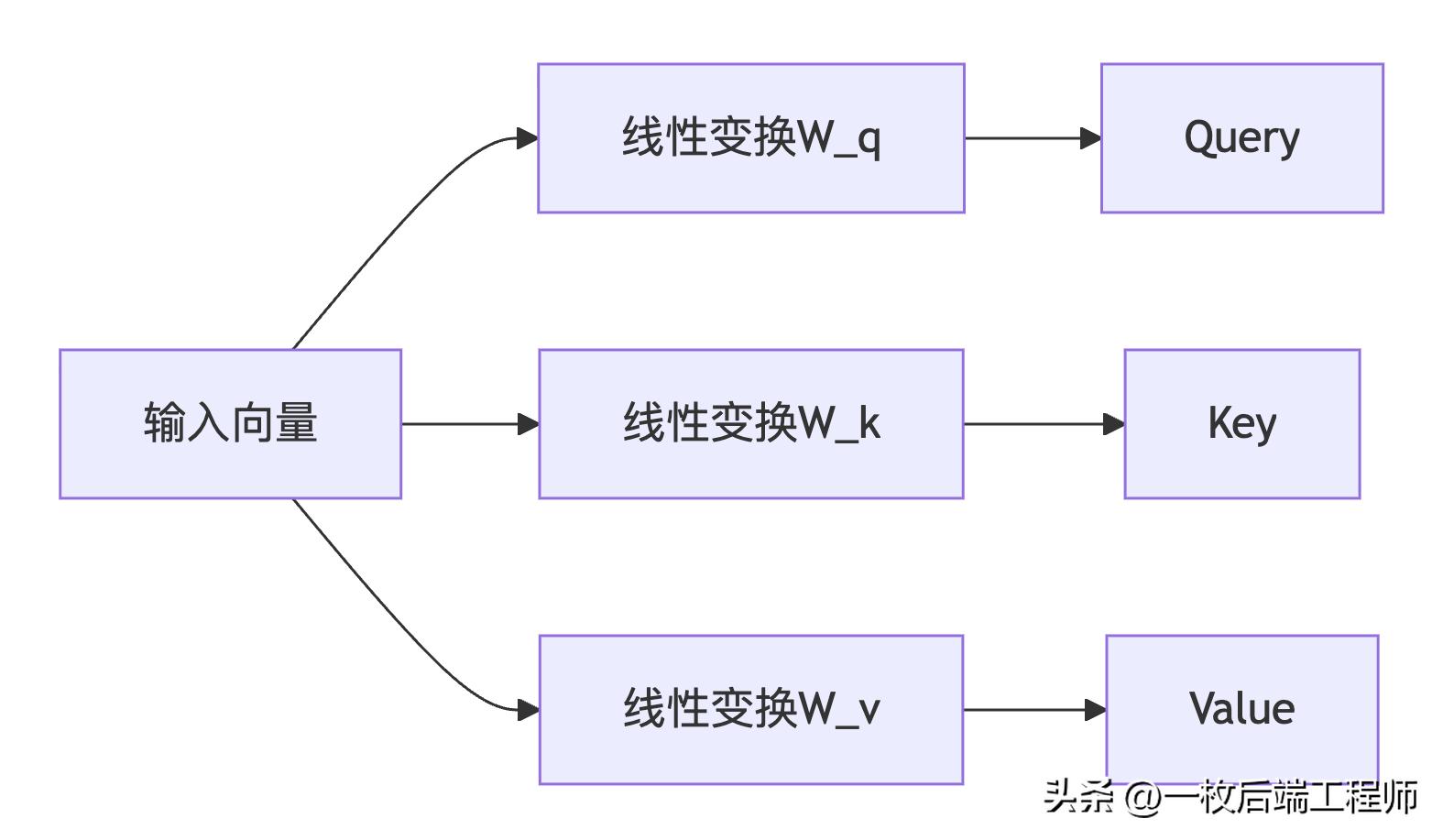
步骤1:创建Q、K、V向量
每个词生成三个向量:
- Query:表示"我要找什么?"
- Key:表示"我是谁?"
- Value:表示"我的实际内容"
步骤2:计算注意力分数
用每个Query与所有Key计算相似度:
注意力分数 = Softmax(Q × K^T / √d_k)
文本示意图:
句子:"猫 吃了 鱼 因为 它 饿了"
计算词"它"的注意力:
Query("它") vs Keys 分数 Softmax权重
Key("猫") 8.0 0.6
Key("吃了") 1.0 0.05
Key("鱼") 2.0 0.1
Key("因为") 1.5 0.08
Key("它") 0.5 0.02
Key("饿了") 4.0 0.15
步骤3:加权合成输出
用权重对Values加权求和:
输出("它") = 0.6×Value("猫") + 0.1×Value("鱼") + 0.15×Value("饿了") + ...
现在"它"的表示中包含了大量"猫"的信息!
多头注意力:多专家委员会
单一注意力可能只关注一种关系,多头让模型同时关注多种模式:
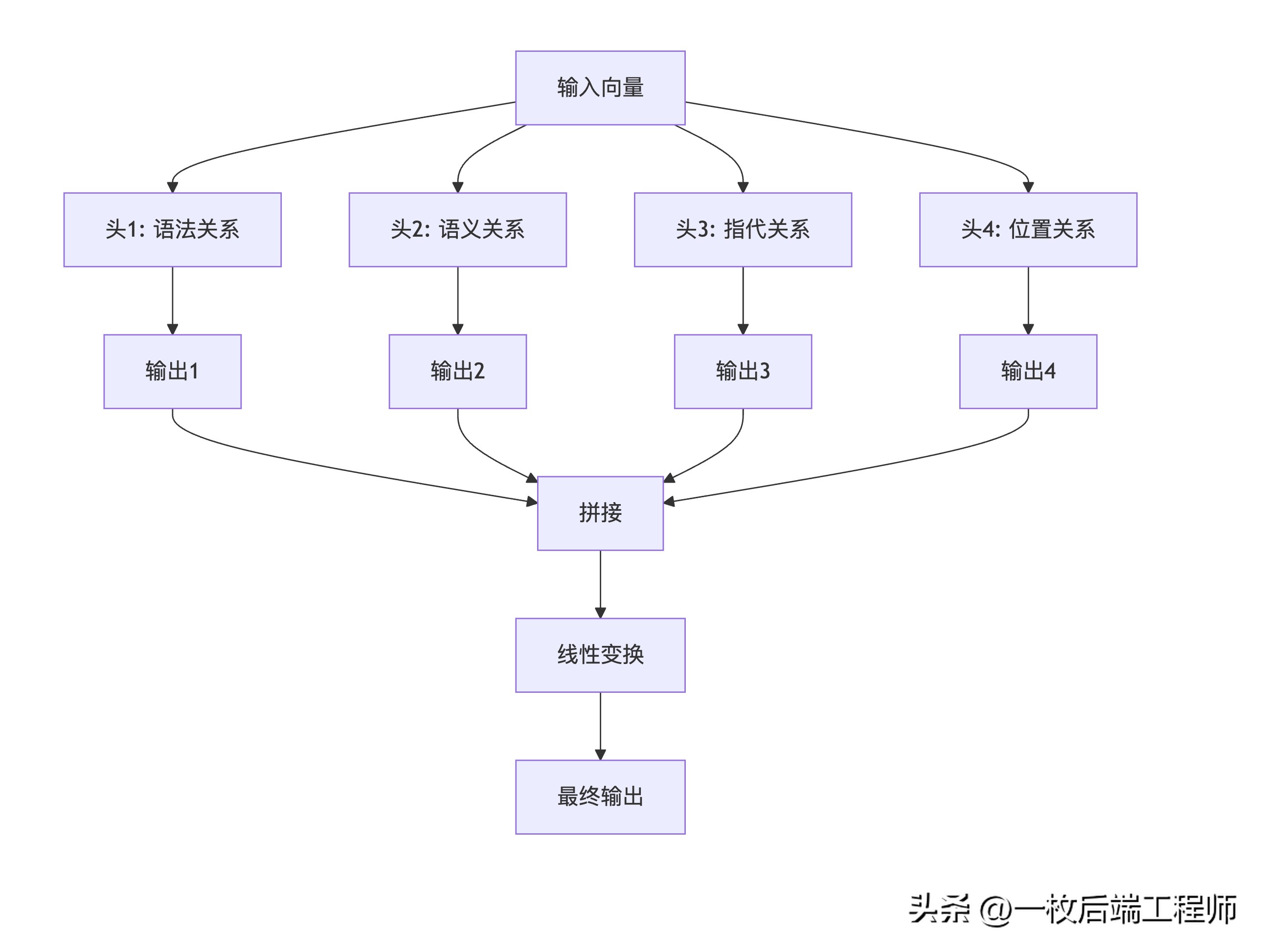
比喻:就像专家委员会分析案件:
- 语法专家:分析句子结构
- 语义专家:理解含义逻辑
- 指代专家:理清指代关系
- 语境专家:把握上下文氛围
每个专家从不同角度分析,最终综合决策。
四、Transformer架构逻辑
完整数据流图

关键组件详解
1. 位置编码:弥补无顺序缺陷
由于Transformer没有循环结构,需要显式注入位置信息:
正弦位置编码:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
比喻:给每个词发一个座位号,让模型知道词序。
2. 残差连接:训练稳定器
每个子层都有残差连接:
输出 = LayerNorm(子层输出 + 子层输入)
作用:缓解梯度消失,支持深层网络训练。
3. 层归一化:训练加速器
对每个样本独立归一化,稳定训练过程。
4. 前馈网络:特征变换器
每个位置独立通过相同的全连接网络:
FFN(x) = max(0, xW1 + b1)W2 + b2
训练vs推理流程对比
训练阶段:并行处理
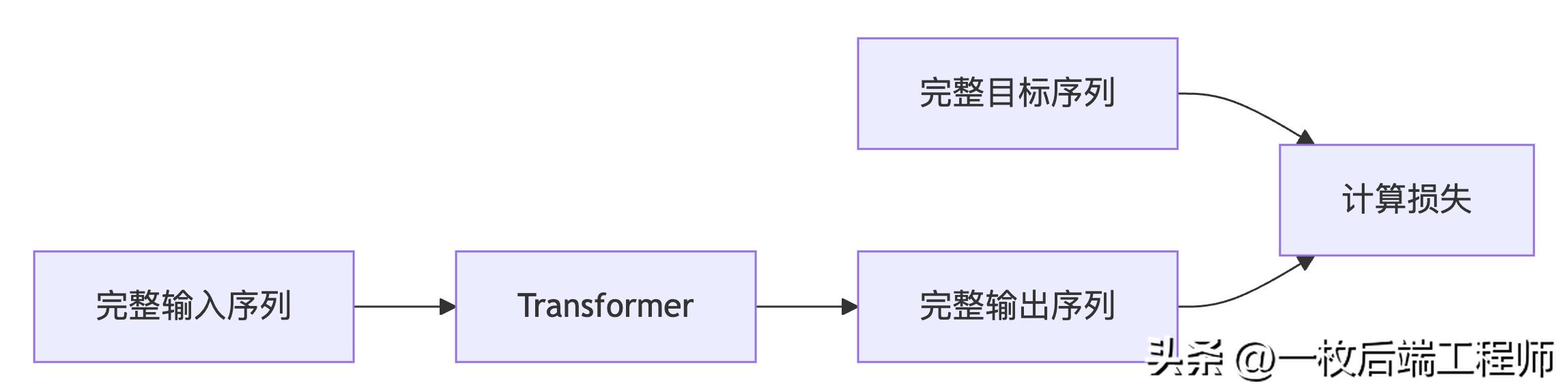
推理阶段:自回归生成
Transformer的设计哲学
1.并行化优先
- 所有位置同时处理
- 充分利用GPU并行能力
- 训练速度比RNN快数个量级
2.长距离依赖直接连接
- 任意两个词直接交互
- 不受序列长度限制
- 完美解决长序列遗忘问题
3.可扩展性架构
- 堆叠更多层获得更强能力
- 增大模型尺寸提升性能
- 成为大模型的理想基础
为什么Transformer如此成功?
- 计算效率:完全并行,训练速度快
- 建模能力:直接捕获长距离依赖
- 可扩展性:模型规模几乎无上限
- 通用性:适用于各种序列任务
- 可解释性:注意力权重提供洞察
总结:架构革命的启示
Transformer的成功证明了一个深刻见解:有时候,放弃传统的归纳偏置(如局部性、顺序性),让模型完全从数据中学习,反而能获得更强大的能力。
正如论文标题《Attention Is All You Need》所宣告的,这个简洁而强大的架构不仅改变了自然语言处理,正在重塑整个人工智能领域。从BERT到GPT,从视觉Transformer到多模态模型,Transformer已经成为现代AI不可或缺的基础构件。


















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











