




上一篇文章我们已经部署了环境,接下来我们就要开始进行模型训练了
自定义训练
需要准备:训练集图片、验证集图片以及图片中所有目标的标注
一、训练集准备
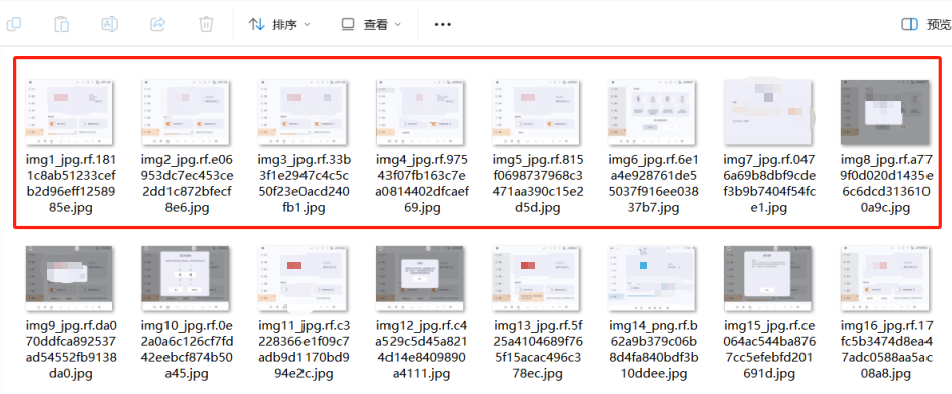
1.原始图片
在本地PC端创建一个文件夹存放原始图片
我这里截图了一些打算测试的座舱域车机页面图
2.图片标注以及生成训练集
【如何通过原始图片生成训练集图片以及训练集标签呢?】
使用 roboflow 标注工具
https://app.roboflow.com/ces-vtecm/my-first-project-j7iyp/4

Roboflow是一款自动化训练数据工具,它提供了一种独特的标记方式,让开发者更轻松地为图像中的物体设定标签,以便YOLOv5能够更有效地识别。
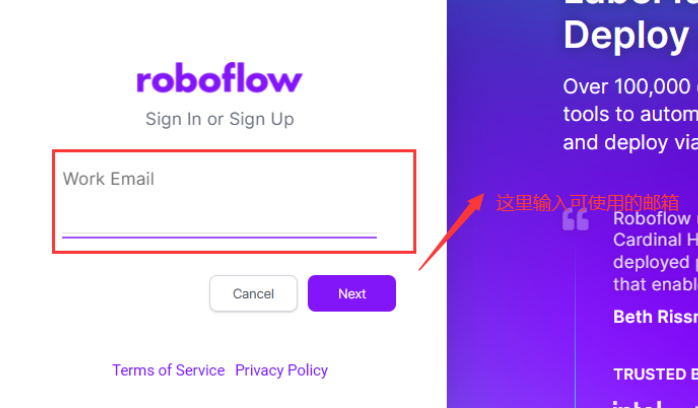
图片标注步骤
①使用邮箱登陆

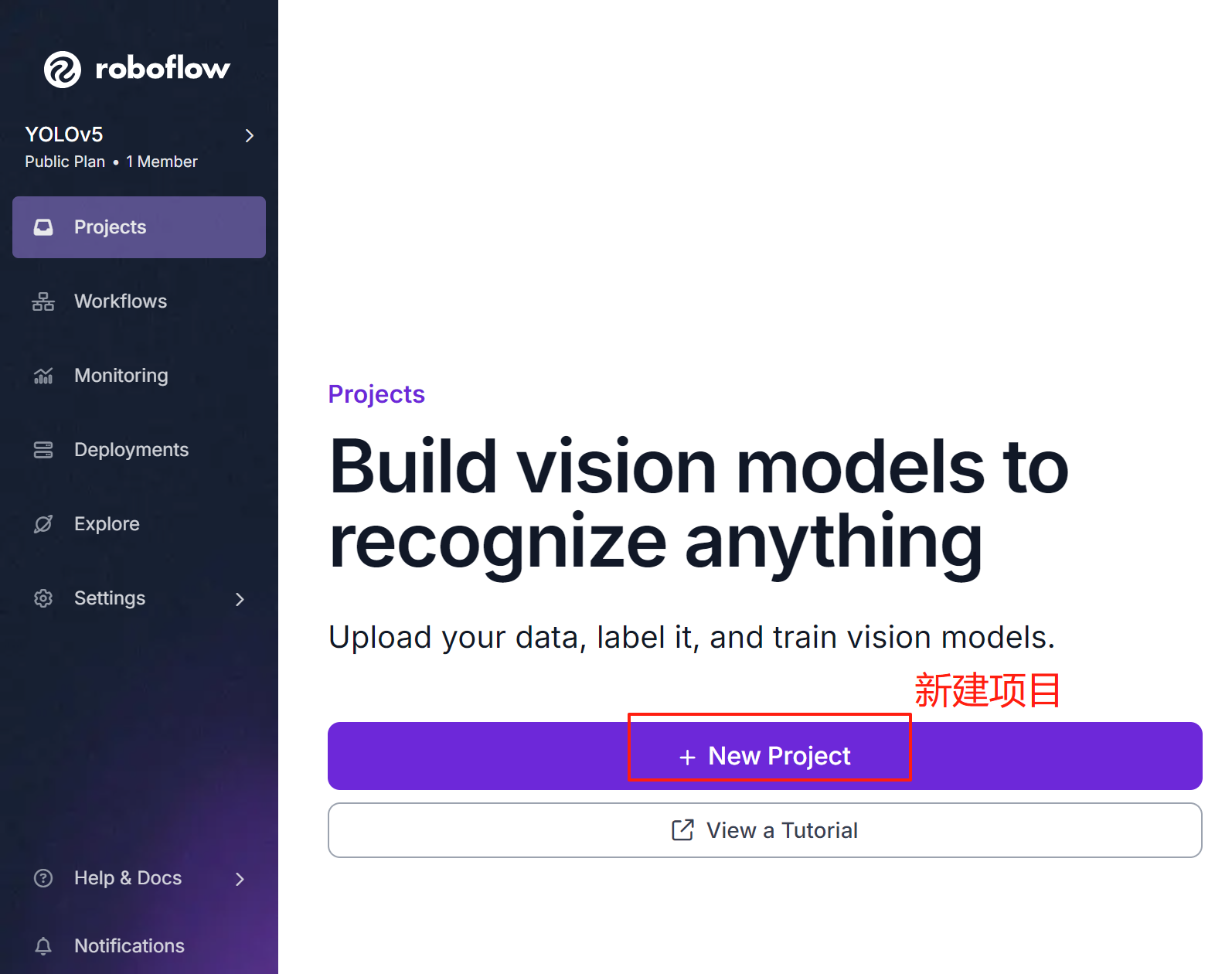
②创建项目
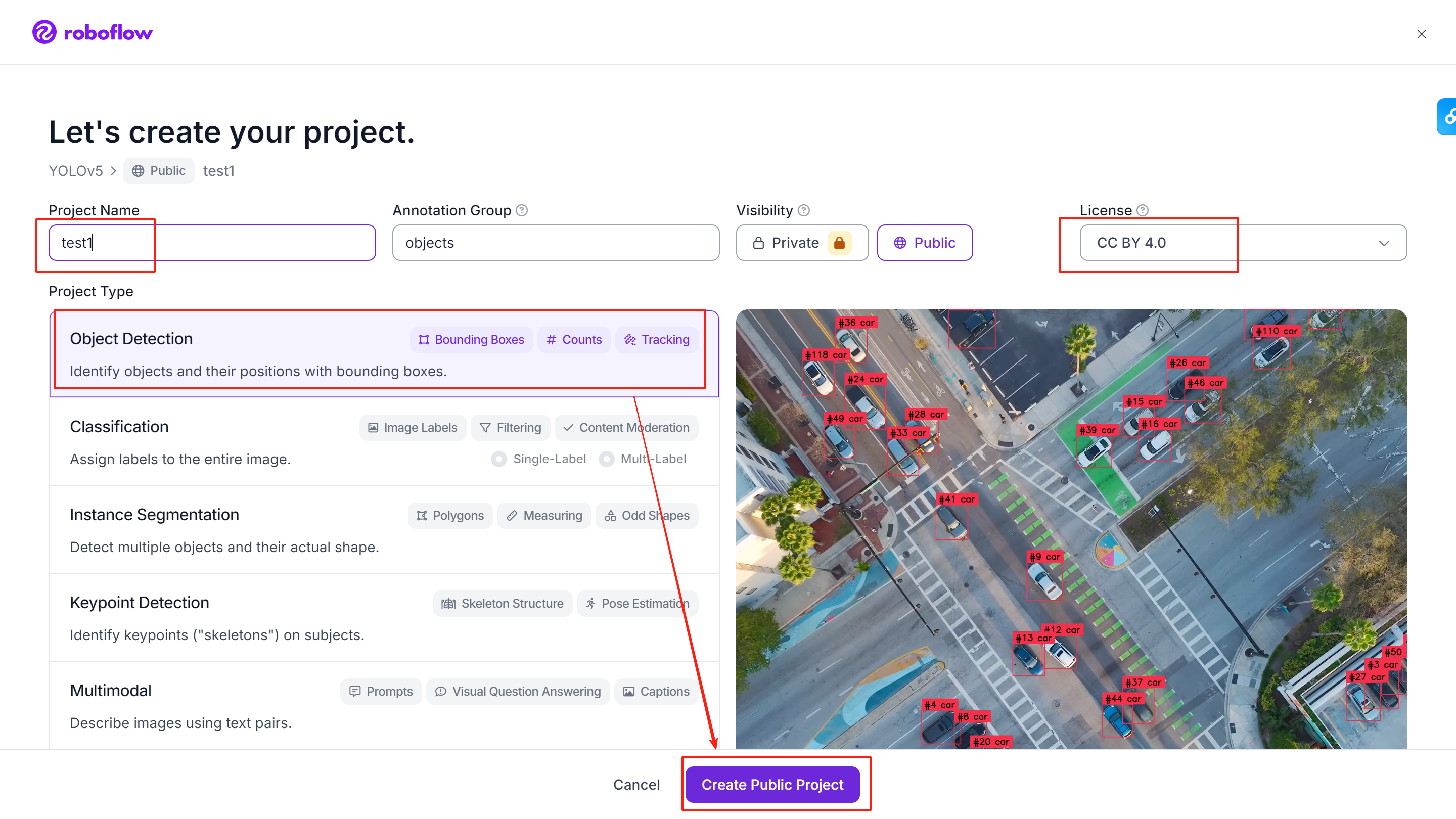
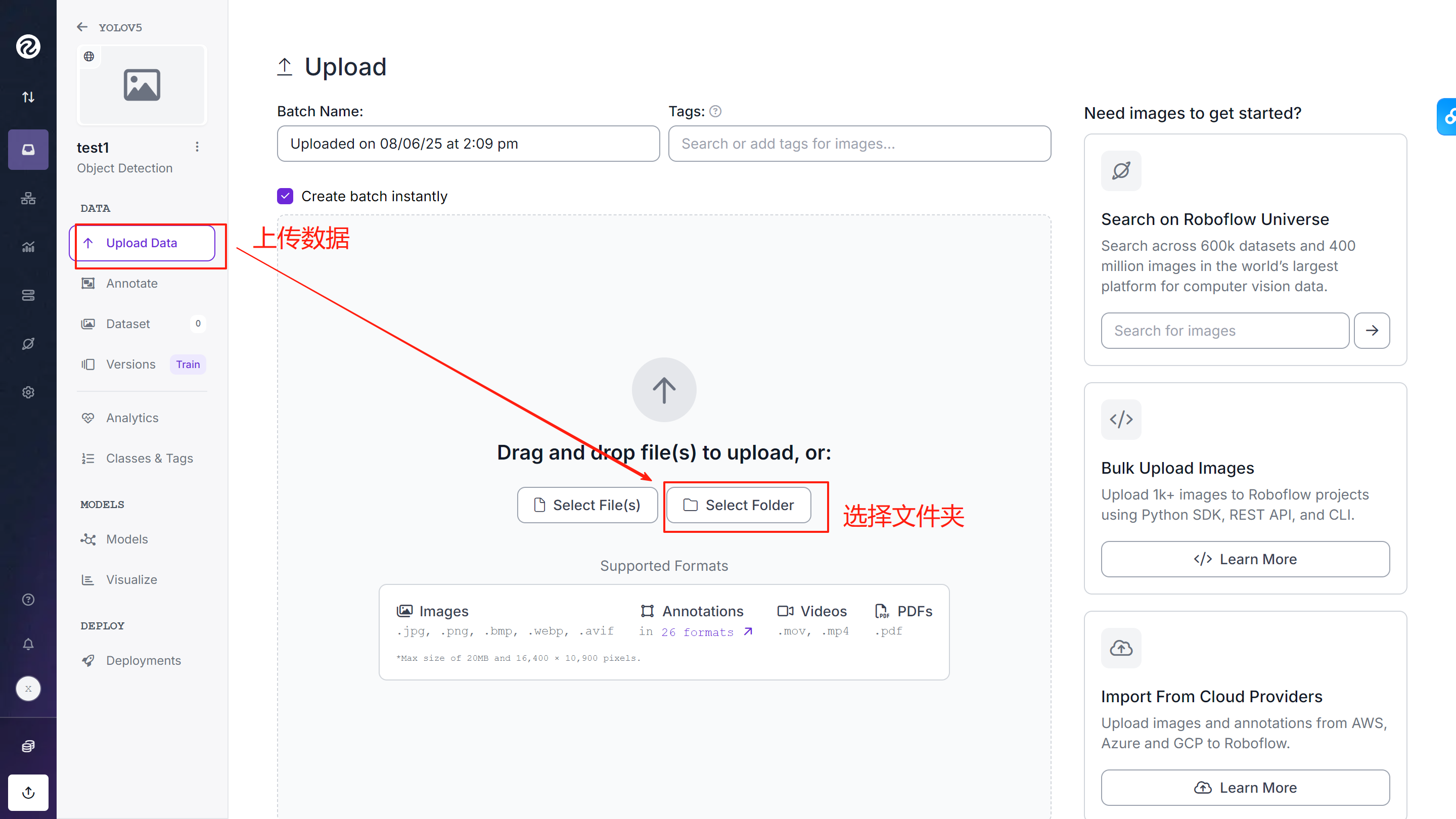
③上传原始图片
直接上传整个文件夹
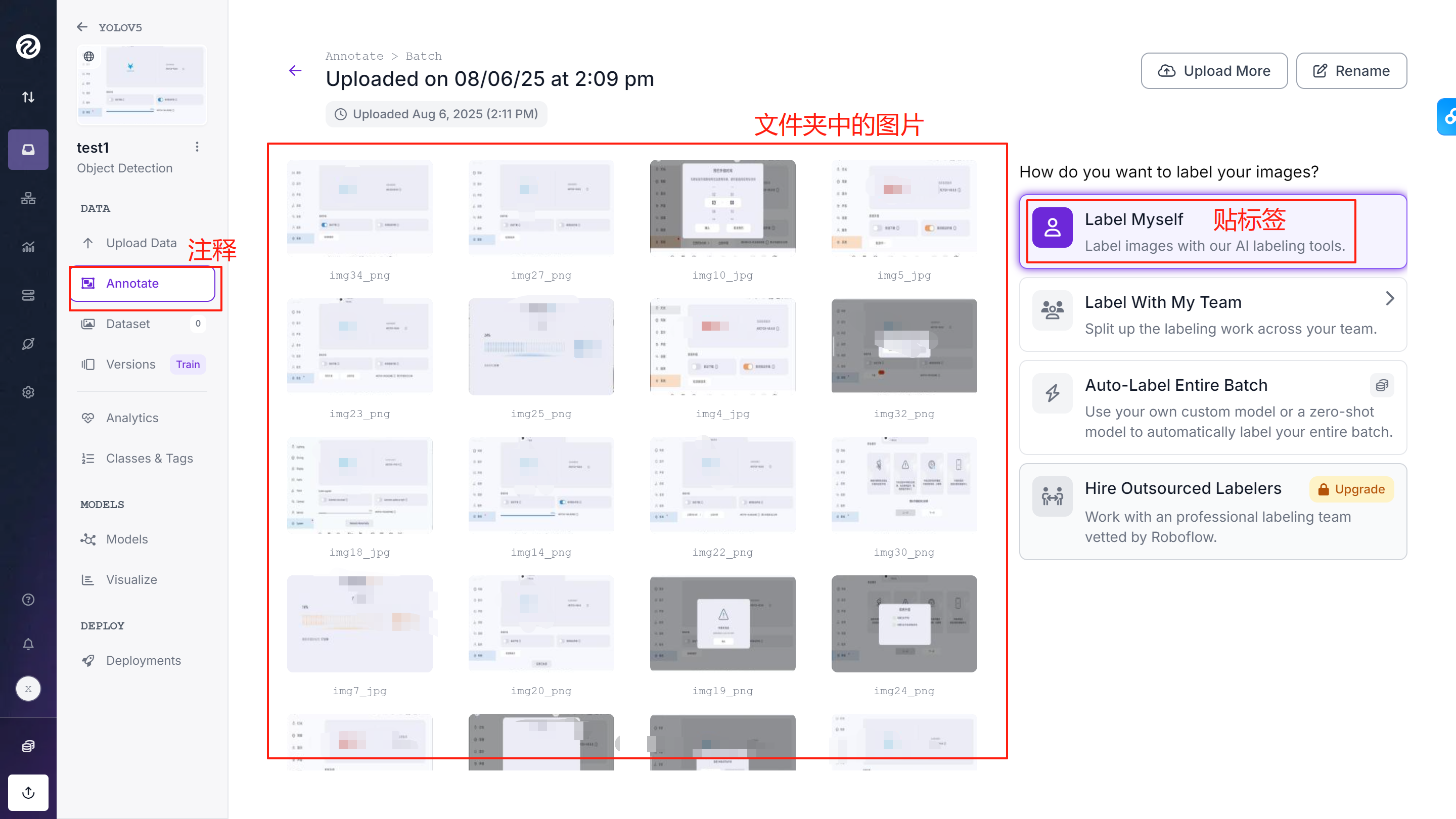
④选择图片添加标签
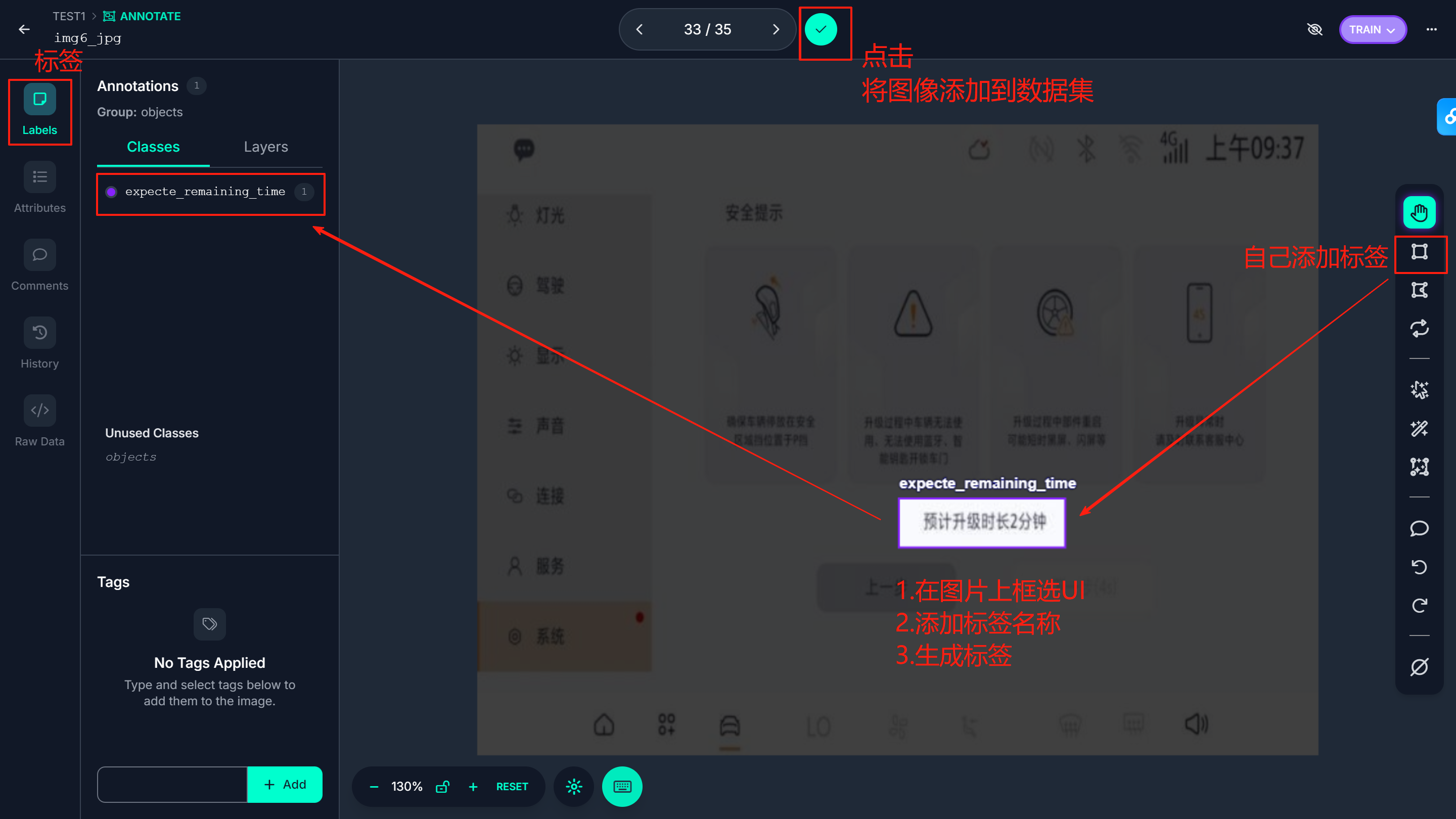
⑤添加标签
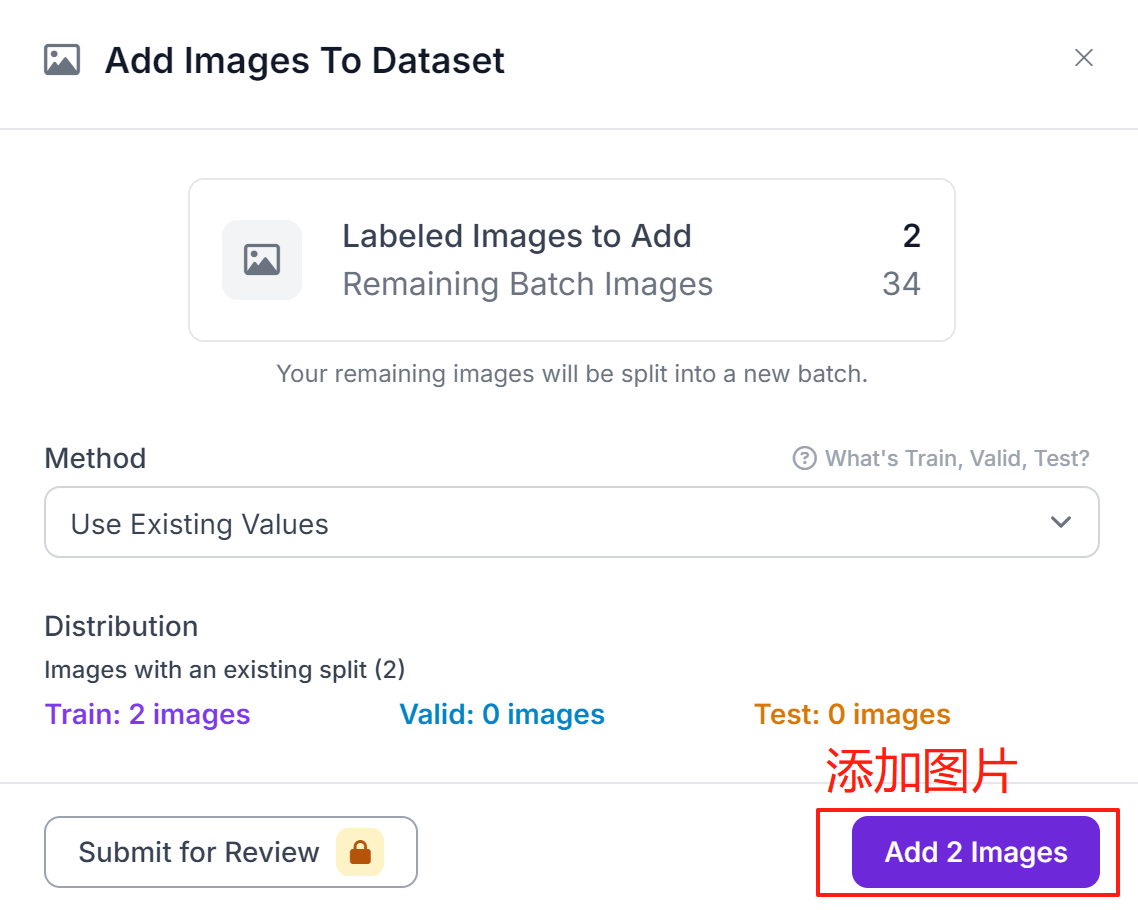
⑥添加数据集
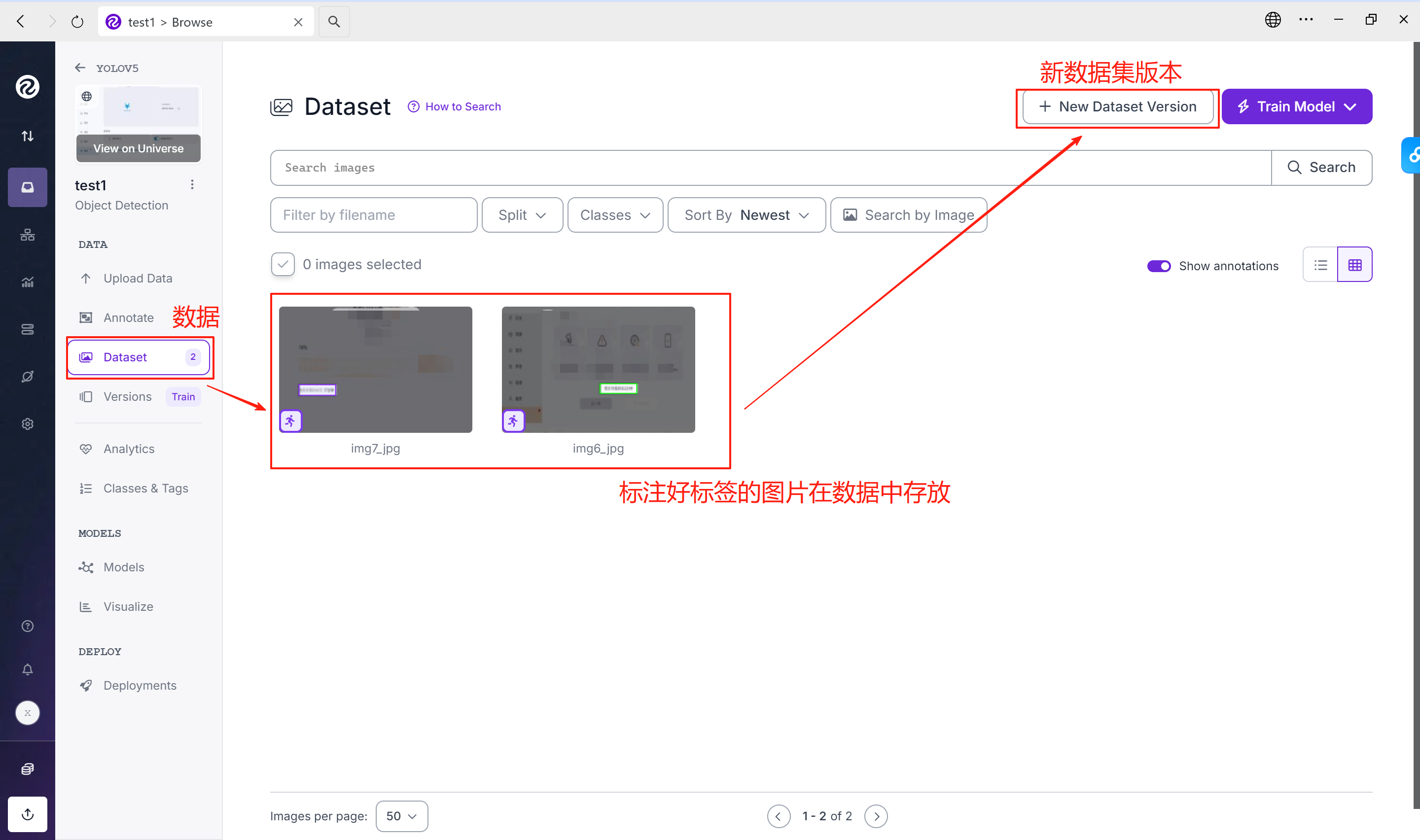
添加完全部图片的标签后将图像添加到数据集
⑦新建数据集版本
所有图片都添加后,新建数据集版本
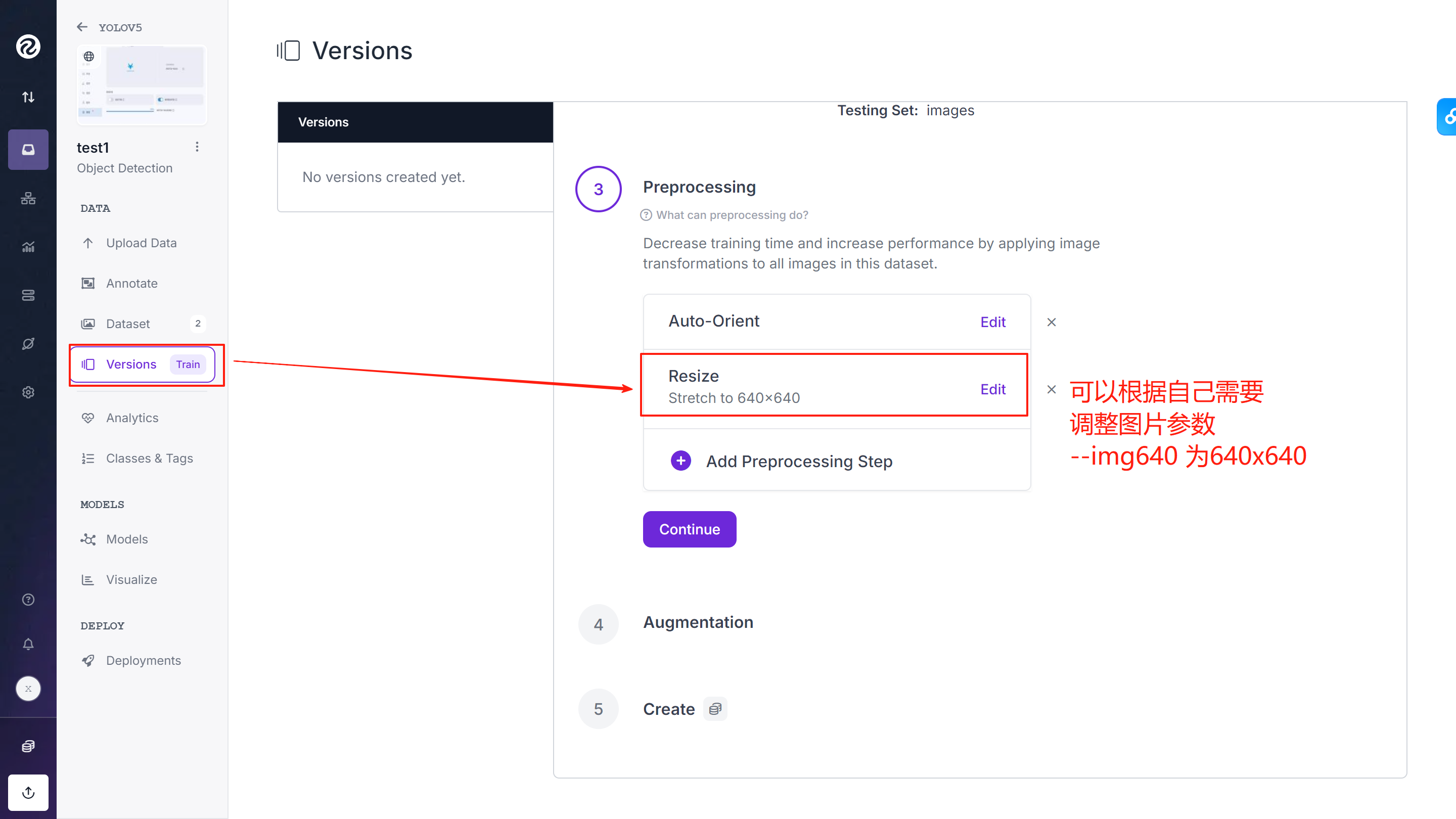
⑧调整图片参数
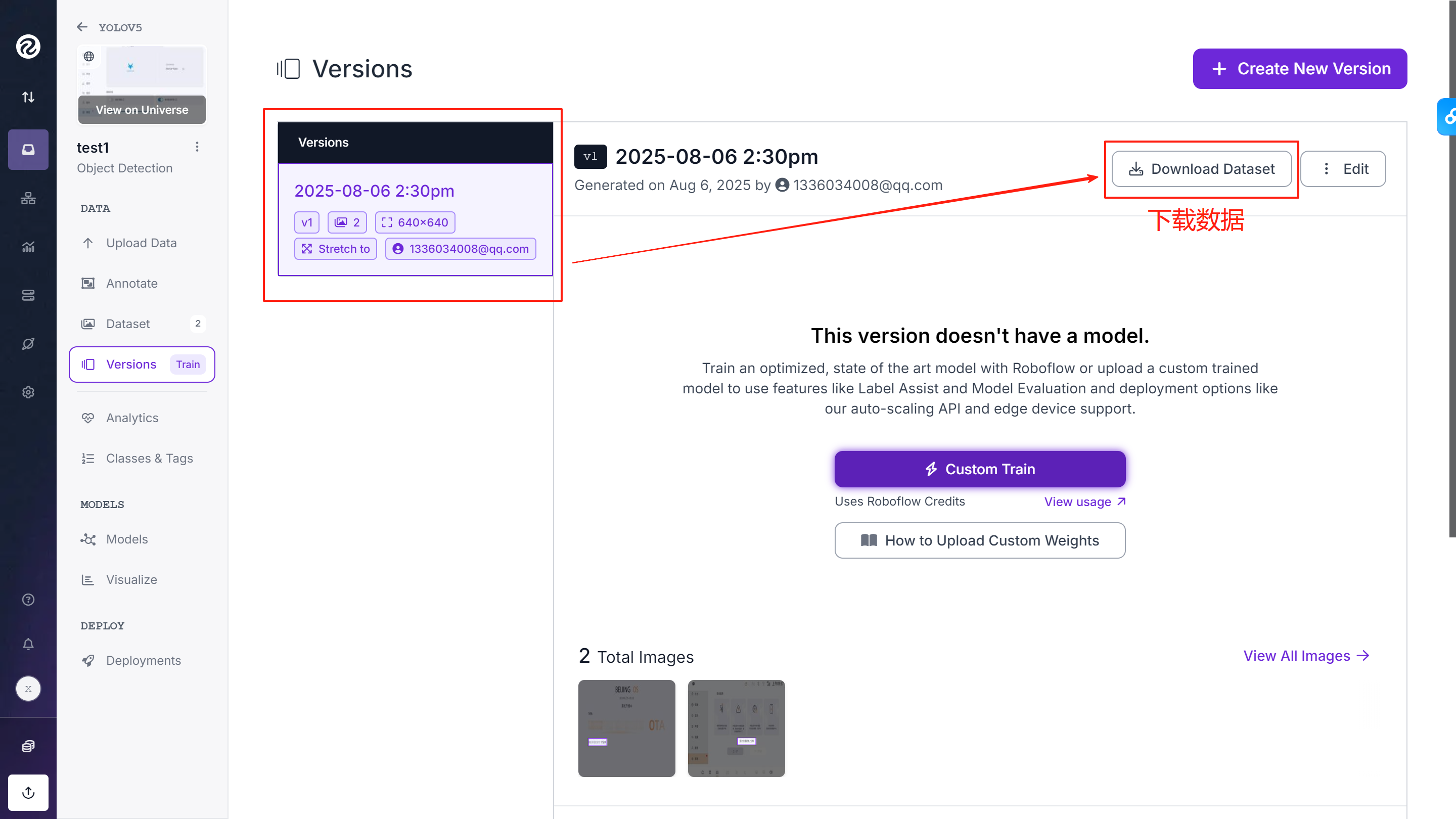
⑨下载数据
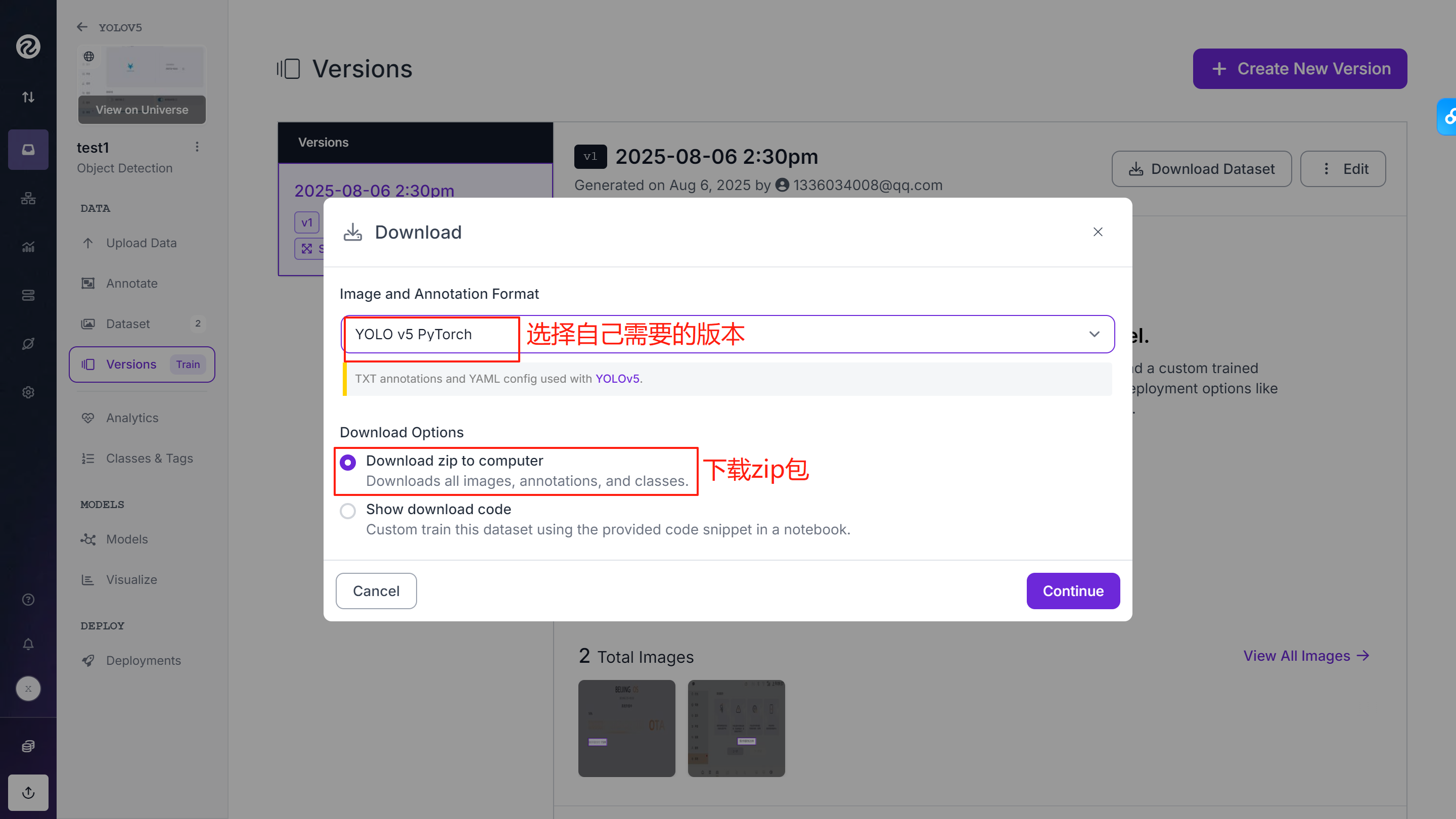
![]()
下载到本地为zip包,解压后得到以下文件:
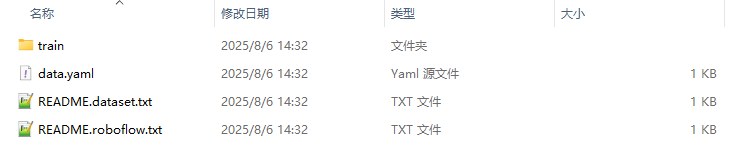
train文件夹中为训练集图片和训练集标签:
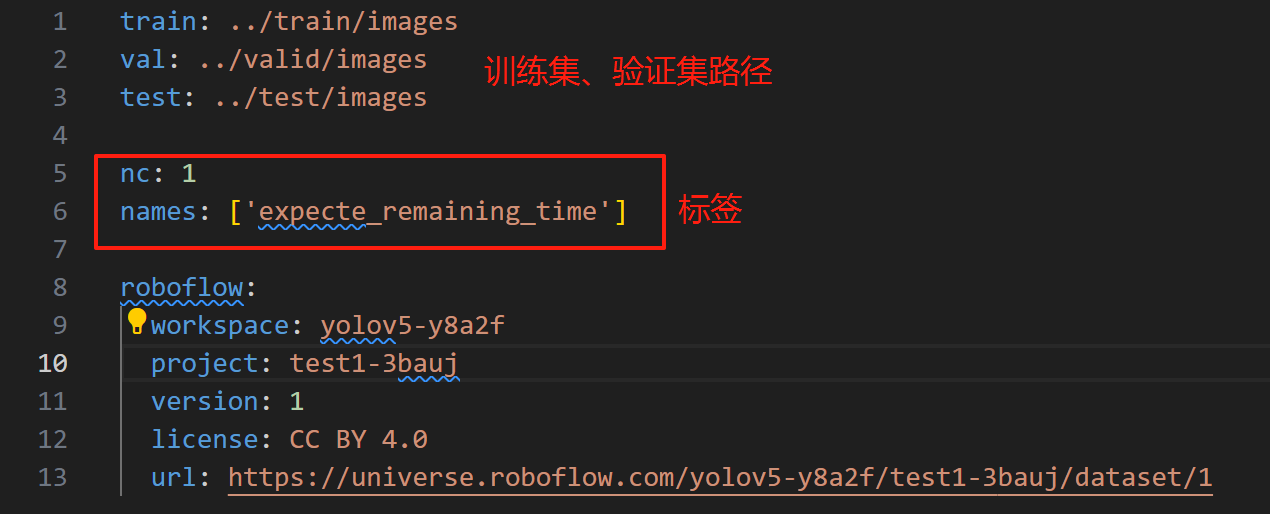
data.yaml为:(后续使用可能会修改内容)
3.导入训练集和验证集
①进入虚拟环境
再次进入ubuntu系统需要重新进入虚拟环境
source $HOME/miniconda/bin/activate
conda activate yolov5_rknn
②创建文件夹子文件夹
cd home/yolov5/
mkdir -p datasets/images/{train,val} datasets/labels/{train,val}
【参数说明】
-p 自动创建父目录(如果不存在)
{train,val} 批量创建多个子目录
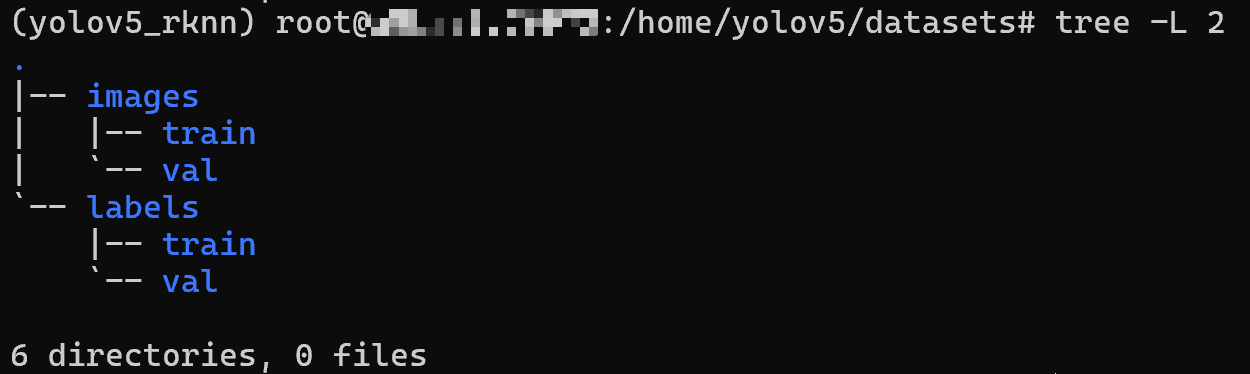
结构如下:
datasets/ ├── images │ ├── train(存放训练集图片) │ └── val (存放验证集图片) └── labels ├── train(存放对应训练集图片的标注文件) └── val (存放对应验证集图片的标注文件)
③导入图片以及标签
训练集图片:
docker cp D:\test1.v1i.yolov5pytorch\train\images. 容器唯一标识符:/home/yolov5/datasets/images/train
验证集图片:
- 验证集图片需要和训练集内图片不同,如果验证集包含训练集图片,模型会记住这些图片(过拟合),导致验证指标虚高,无法反映真实性能;
- 验证集的目的是为了验证模型在从未见到的数据上面的表现,因此需使用全新图片,但是要保证验证集和训练集的图片,类别、场景分布类似,才具有验证价值;
- 通常训练集图片数量和验证集图片数量的划分为7:3;
docker cp D:\验证集图片文件夹. 容器唯一标识符:/home/yolov5/datasets/images/val
训练集标签:
docker cp D:\test1.v1i.yolov5pytorch\train\labels. 容器唯一标识符:/home/yolov5/datasets/labels/train
验证集标签:
docker cp D:\验证集标签文件夹. 容器唯一标识符:/home/yolov5/datasets/labels/val

④导入data.yaml配置文件
在 YOLOv5 项目中,data.yaml 是一个配置文件,用于定义数据集的路径、类别信息以及训练/验证集的划分规则。
它是模型训练和验证的“数据指南”,告诉 YOLOv5 去哪里找数据、如何解析数据。
YOLOv5 的训练脚本(train.py)和验证脚本(val.py)依赖此文件定位数据。
这里将 data.yaml 配置文件存放到 datasets 路径下
修改数据集和验证集的路径信息

二、训练模型
1.开始训练
python train.py --img 640 --batch 16 --epochs 50 --data datasets/data.yaml --weights yolov5s.pt --workers 0
【参数说明】
train.py 训练脚本
--img 640 图片尺寸
--batch 16 批次大小,根据GPU内存调整
--epochs 50 训练轮次
--data datasets/data.yaml 数据集配置文件路径
--weights yolov5s.pt 预训练权重文件
--workers 0 数据加载的线程数(0表示仅主线程,避免多线程问题)
【BUG1】NumPy版本兼容性问题
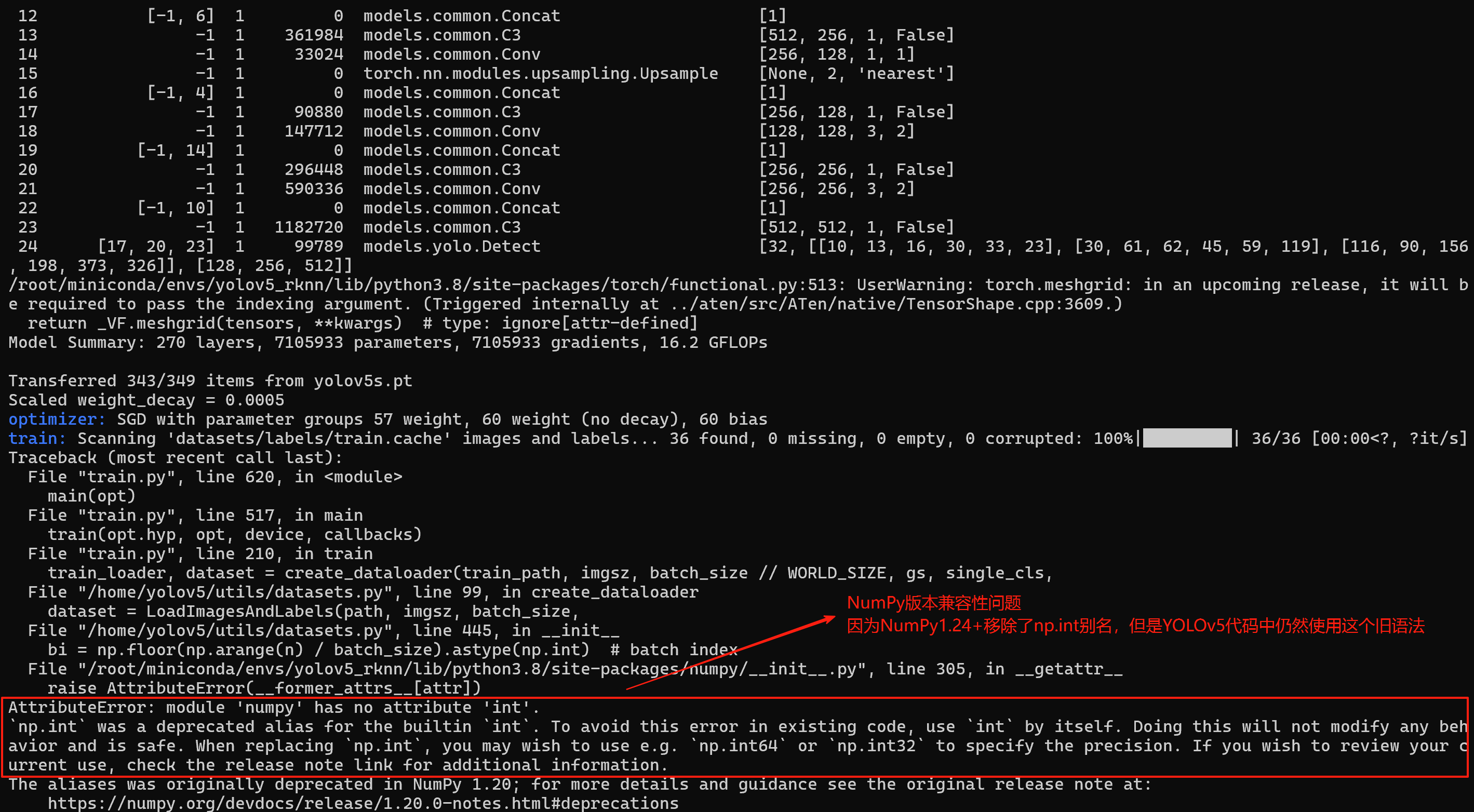
【解决办法1】---采用√ 成功
查看到以下文件中存在np.int:
grep "astype(np.int" /home/yolov5/utils/datasets.py
grep "astype(np.int" /home/yolov5/utils/general.py
grep "astype(np.int" /home/yolov5/utils/metrics.py

替换文件中所有 np.int 为 int:
sed -i 's/\.astype(np\.int)/.astype(int)/g' /home/yolov5/utils/general.py
sed -i 's/\.astype(np\.int)/.astype(int)/g' /home/yolov5/utils/datasets.py// metrics.py 应该不是直接改为int16,需要改为'int16' ---见BUG4
sed -i 's/\.astype(np\.int16)/.astype(int16)/g' /home/yolov5/utils/metrics.py
或者一个个修改(示例 datasets.py 文件的473行)
vim /home/yolov5/utils/datasets.py +473 // 代表修改文件的第473行

【解决办法2】---没尝试,怕修改版本会引发新的不兼容问题
查看NumPy版本号:
python -c "import numpy as np; print(np.__version__)"

发现版本号大于1.24版本,需要降级到1.23.5:
pip install numpy==1.23.5
【BUG2】类型转换问题
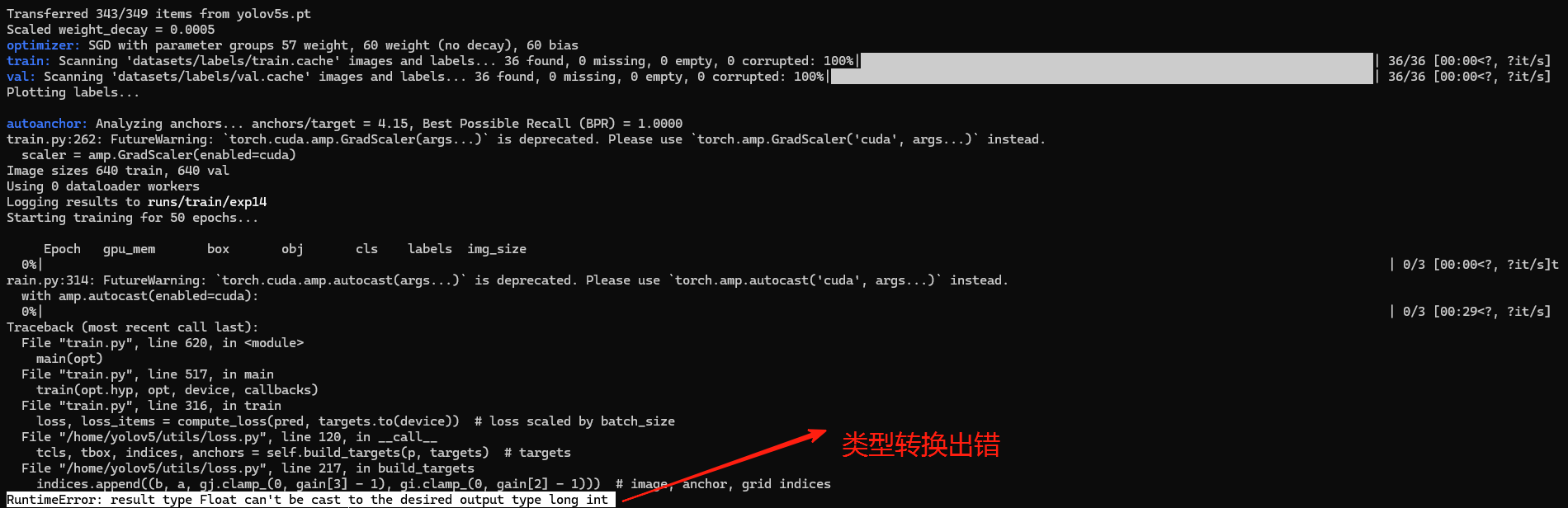
问题现象:Float类型无法转换为long int类型
分析:在 loss.py 文件中,gj.clamp_() 和 gi.clamp_() 操作需要返回整数类型(long int),但输入可能是浮点类型(Float),类型不匹配
原因:使用的PyTorch 2.4.0可能与YOLOv5 v6.0存在一些兼容性问题
查看gi.clamp_():
grep "clamp_(" /home/yolov5/utils/loss.py
修改文件第217行:vim /home/yolov5/utils/loss.py +217
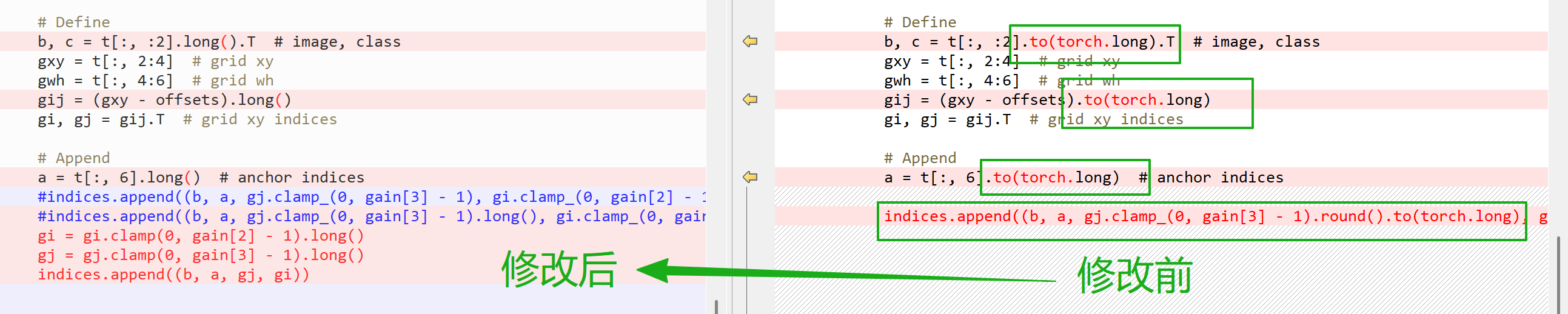
修改:红色为修改后代码
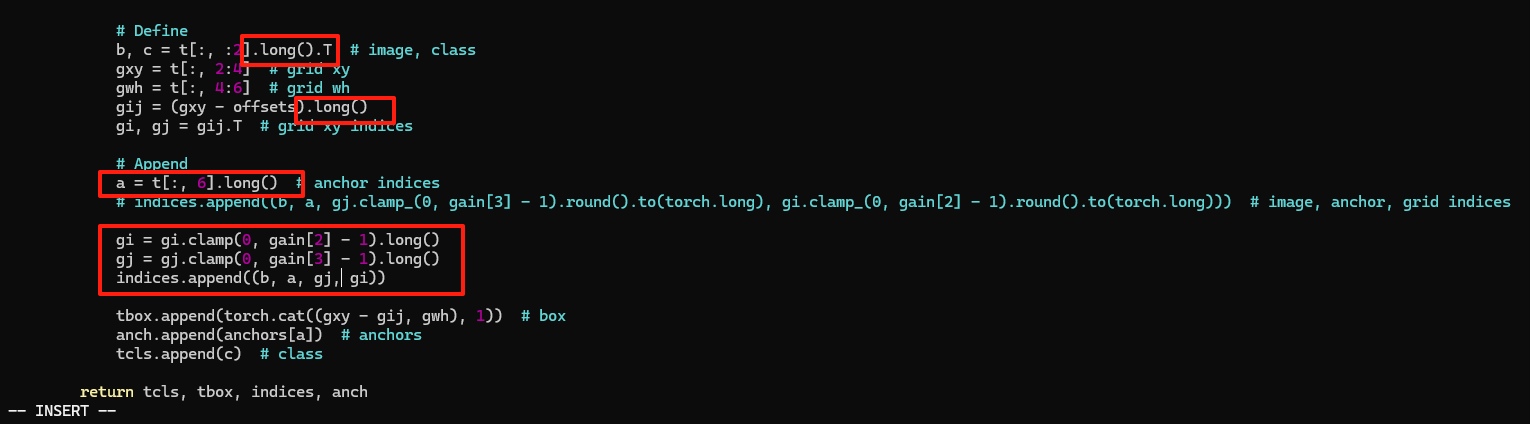
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices# Append
a = t[:, 6].long() # anchor indices
# indices.append((b, a, gj.clamp_(0, gain[3] - 1).round().to(torch.long), gi.clamp_(0, gain[2] - 1).round().to(torch.long))) # image, anchor, grid indices // 原代码gi = gi.clamp(0, gain[2] - 1).long()
gj = gj.clamp(0, gain[3] - 1).long()
indices.append((b, a, gj, gi))
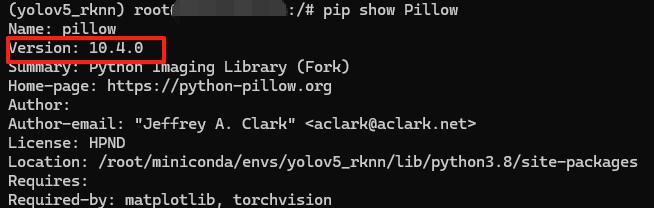
【BUG3】Pillow库版本兼容性问题

原因:Pillow 10.0.0之后的版本中移除了getsize()方法导致的兼容性问题
-
YOLOv5的绘图功能使用了Pillow库
-
新版本Pillow改变了字体尺寸获取的API
查看 Pillow 版本:pip show Pillow
【解决办法1】---采用√ 成功
修改文件第86行:vim /home/yolov5/utils/plots.py +86
修改文件第112行:vim /home/yolov5/utils/plots.py +112
修改:红色为修改后代码
# 86行修改
if label:
# w, h = self.font.getsize(label) # text width, height // 原代码
bbox = self.font.getbbox(label)
w, h = bbox[2] - bbox[0], bbox[3] - bbox[1]
# 112行修改
def text(self, xy, text, txt_color=(255, 255, 255)):
# Add text to image (PIL-only)
# w, h = self.font.getsize(text) # text width, height // 原代码
w, h = self.font.getbbox(text)[2:]
【解决办法2】---没尝试,怕修改版本会引发新的不兼容问题
降级Pillow版本
pip install pillow==9.5.0
【BUG4】未正确导入 numpy 的数据类型
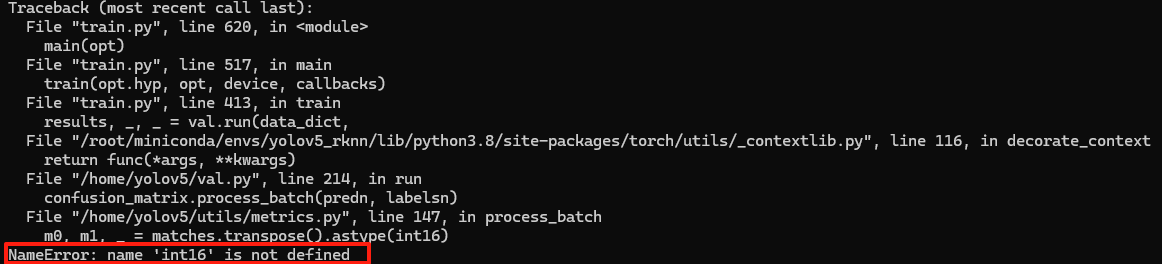
分析:在 utils/metrics.py 中使用了 int16,但未正确导入 numpy 的数据类型
原因:YOLOv5 的某些版本在 metrics.py 中直接使用了 int16,但未添加 from numpy import int16 或 import numpy as np 并使用 np.int16(根据BUG1,我们不能使用np.int16)
(这个是BUG1修改后出现的新问题)
修改:m0, m1, _ = matches.transpose().astype('int16') # 使用字符串 'int16' 而非变量

2.结束训练
正常等待结束:达到设定的 epochs=50 轮次,训练完成后自然退出;
3.训练结果
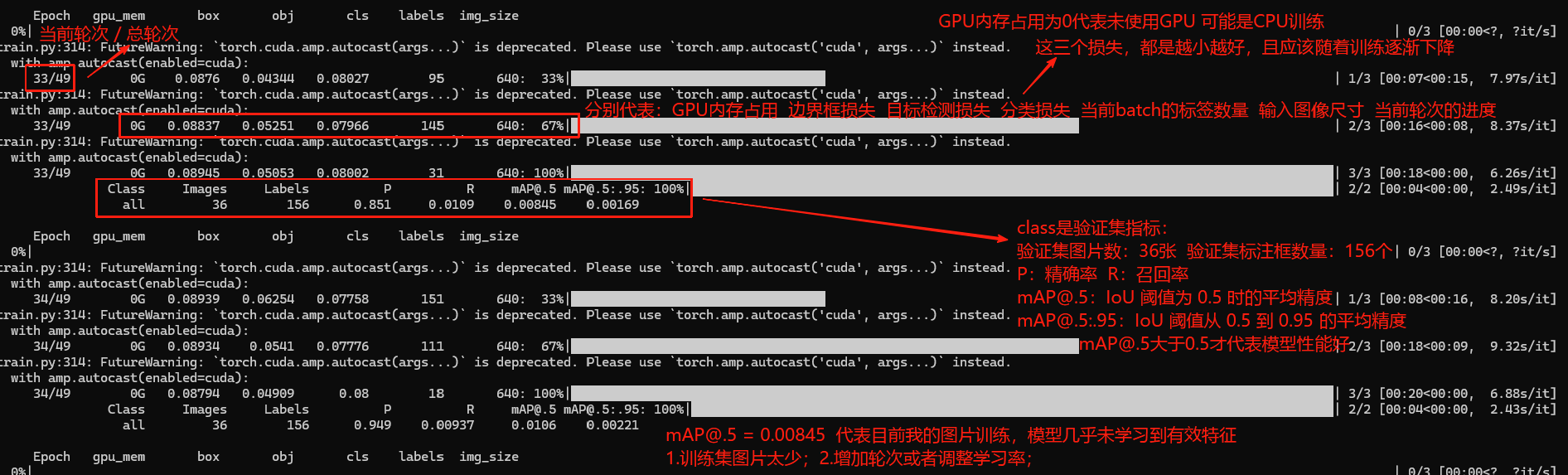
训练进度:
33/49:当前 epoch(轮次)和总 epochs
0G:GPU 内存占用(0 表示未使用 GPU,可能是 CPU 训练)
0.08837:边界框损失(box loss),越小越好
0.05251:目标检测损失(obj loss),越小越好
0.07966:分类损失(cls loss),越小越好
145:当前 batch 的标签数量。
640:输入图像尺寸。
67%:当前 epoch 的进度。
验证集指标:
Images:验证集图片数(36 张)
Labels:验证集标注框数(156 个)
P (Precision):精确率(预测为正样本中真实正样本的比例),当前 0.851(较低)
R (Recall):召回率(真实正样本中被正确预测的比例),当前 0.0109(很低)
mAP@.5:IoU 阈值为 0.5 时的平均精度(0.00845,性能较差)
mAP@.5:.95:IoU 阈值从 0.5 到 0.95 的平均精度(0.00169,性能较差)
4.持续训练
在开始训练时我们设置了轮次50次,使用官方预处理权重pt文件:
python train.py --img 640 --batch 16 --epochs 50 --data datasets/data.yaml --weights yolov5s.pt --workers 0
这个训练指令,每次执行都是独立训练,效果不会叠加
那么想要长期持续训练,应该怎么办呢?
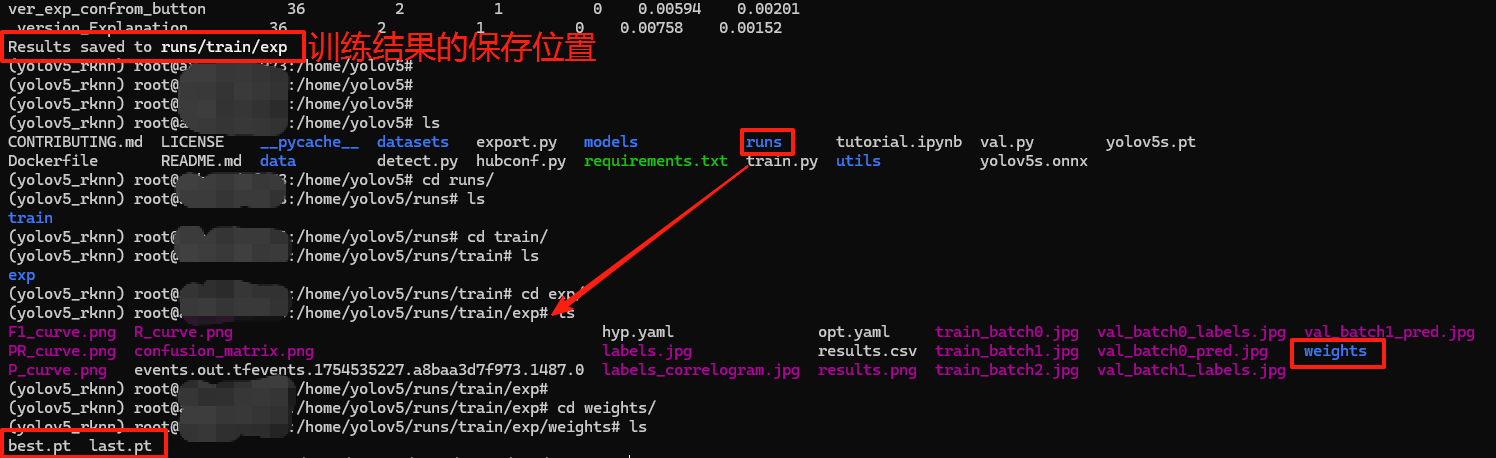
首先,我们首次完成训练的轮次后,会生成一个runs文件夹保存我们的训练结果,在 /home/yolov5/runs/train/exp/weights 路径下有两个pt文件,best.pt 和 last.pt 是两个关键的模型权重文件,我们想要恢复训练需要使用到这两个权重文件;
best.pt 含义:是训练过程中在验证集上表现最优的模型权重
best.pt 特点:
1.保存的是验证集精度最高的版本,通常用于实际部署;
2.文件大小较小;
last.pt 含义:训练最后一个轮次的模型权重(无论性能如何)
last.pt 特点:
1.包含完整的模型状态(可继续训练);
2.文件较大(默认保留优化器状态,便于 --resume 训练);
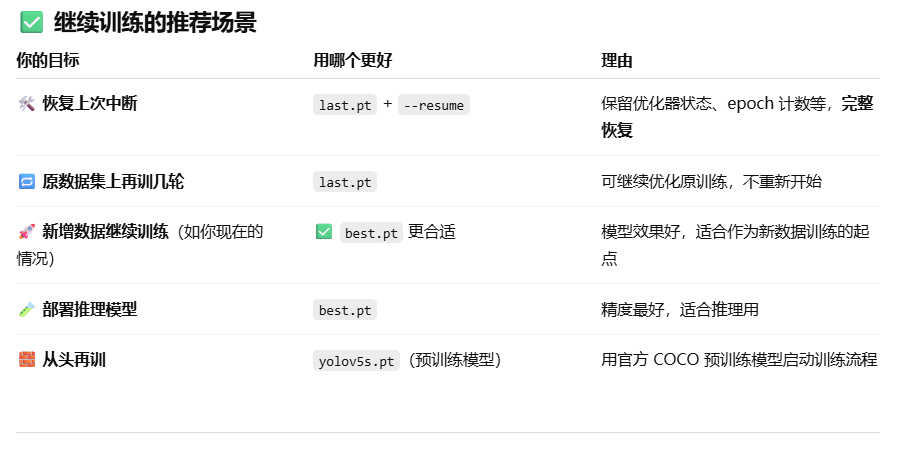
指令对比
# 开始首次训练
python train.py --img 640 --batch 16 --epochs 50 --data datasets/data.yaml --weights yolov5s.pt --workers 0
# 恢复训练(从上次断点继续)
python train.py --resume /home/yolov5/runs/train/exp/weights/last.pt --epochs 50
【恢复训练 - 参数说明】
--epochs 总epoch数 这个应该和首次训练的轮次参数保持一致
--project runs/train --name exp1 训练结果保存
这个指令我理解是,我本来想要执行50轮次的训练,但是训练到轮次20时异常中断了,然后通过这个指令可以让剩下的轮次继续执行结束从21到50;
# 持续优化训练
原数据集:
python train.py --img 640 --batch 16 --epochs 50 --data datasets/data.yaml --weights /home/yolov5/runs/train/exp/weights/last.pt --epochs 50 --workers 0
有新增数据:
python train.py --img 640 --batch 16 --epochs 50 --data datasets/data.yaml --weights /home/yolov5/runs/train/exp/weights/best.pt --epochs 50 --workers 0
但是我现在不管有没有新增数据,都使用best.pt文件


















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









