






 本文探讨了FP32、FP16及BF16浮点数格式的区别,重点介绍了它们在ARM架构上的性能表现。通过比较发现,在支持FP16的高端设备上,FP16模型的计算速度约为FP32模型的一倍。
本文探讨了FP32、FP16及BF16浮点数格式的区别,重点介绍了它们在ARM架构上的性能表现。通过比较发现,在支持FP16的高端设备上,FP16模型的计算速度约为FP32模型的一倍。
转自:https://zhuanlan.zhihu.com/p/351297472
https://community.arm.com/cn/b/blog/posts/arm-891361032
今天,主要介绍FP32、FP16和BF16的区别及ARM性能优化所带来的收益。
FP32 是单精度浮点数,用8bit 表示指数,23bit 表示小数;FP16半精度浮点数,用5bit 表示指数,10bit 表示小数;BF16是对FP32单精度浮点数截断数据,即用8bit 表示指数,7bit 表示小数。
在数据表示范围上,FP32和BF16 表示的整数范围是一样的,小数部分表示不一样,存在舍入误差;FP32和FP16 表示的数据范围不一样,在大数据计算中,FP16存在溢出风险。
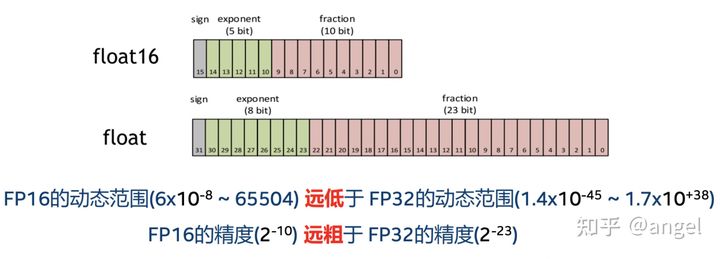
在ARM NEON指令集中,一条指令最多load 128bit 数据,则对FP32数据,一次性最多支持4个数据的并行计算;对FP16/BF16数据,一次性最多支持8个数据的并行计算。那么在计算中,FP16/BF16的性能峰值应该是FP32 的两倍。
调研现有推理框架,当前MNN、Bolt和Mindspore-Lite支持FP16计算,相对于FP32性能,模型性能收益是一半。Mindspore-Lite 在TF-mobilenetv1和TF-mobilenetv2模型的单精度/半精度性能数据,如下图所示:
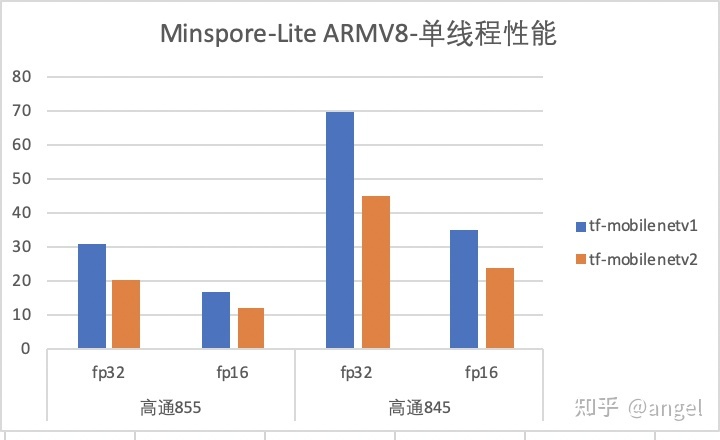
由上图可知,FP16模型性能比FP32模型性能快约一倍。另外,FP16 指令集只在ARMv8.2 以上的架构支持,即只在部分高端机上,才支持实现FP16计算。
ARMv8.2 架构只提供了ARMv8的neon 指令,故当前的开源框架均只支持ARMv8架构的FP16计算。如果想在ARMv7 架构支持FP16计算,可以将neon 指令翻译为机器码进行实现。SDOT指令也是只有ARMv8的neon 指令,如果想在ARMv7上增加SDOT实现,也是可以通过将neon 指令翻译为机器码进行实现。这个方法在Paddle-Lite(ARMv7 VSDOT实现)已经支持,感兴趣的小伙伴们可以试试哦~

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









