FP16与BF16区别
最新推荐文章于 2025-11-12 02:48:29 发布





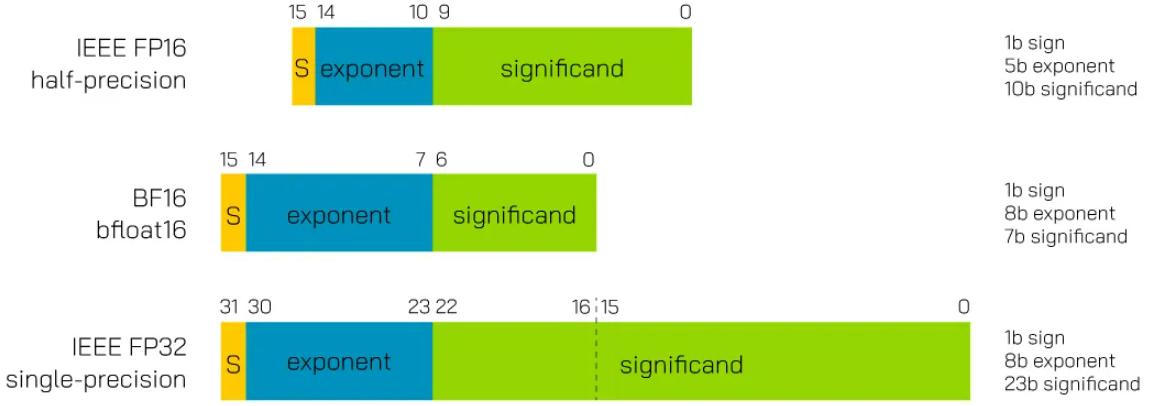
 文章讨论了FP16(1个符号位+5指数位+10尾数位)和BF16(1符号位+8指数位+7尾数位)两种16位浮点数格式在模型训练中的特点,强调了FP16在精度上的优势和BF16在范围和效率方面的妥协。两者都用于减少内存和传输需求以提升训练效率。
文章讨论了FP16(1个符号位+5指数位+10尾数位)和BF16(1符号位+8指数位+7尾数位)两种16位浮点数格式在模型训练中的特点,强调了FP16在精度上的优势和BF16在范围和效率方面的妥协。两者都用于减少内存和传输需求以提升训练效率。

Yolo-v5
Yolo
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的Joseph Redmon 和Ali Farhadi 开发。 YOLO 于2015 年推出,因其高速和高精度而广受欢迎
您可能感兴趣的与本文相关的镜像
Yolo-v5
Yolo
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的Joseph Redmon 和Ali Farhadi 开发。 YOLO 于2015 年推出,因其高速和高精度而广受欢迎
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









