









五、验证结果数据化
我们可以把预测结果全部记录下来,以观察其效果,用于分析和评估我们的模型情况。
1. 数据结果Excel
导入数据分析模块pandas
import pandas as pd
把推理结果softmax化,并放到全局的列表里面
#定义全局的 pd_data :10分类,加了分类id 和 分类名称, 12个
pd_data = np.empty((0, 12))
#在训练的过程中把训练结果整理进来
out_softmax = torch.softmax(out, dim=1).cpu().detach().numpy()
target_y = y.cpu().detach().numpy()
#根据目标值找到分类名
target_name = np.array([vaild_dataset.classes[i] for i in target_y])
# 把真实所属分类追加到数据中
out_softmax = np.concatenate(
(out_softmax, target_y.reshape(-1, 1), target_name.reshape(-1, 1)), axis=1
)
#数据追加
pd_data = np.concatenate((pd_data, out_softmax), axis=0)
保存数据到CSV
# 数据有了,找到列名:和前面追加的目标值及类名要呼应上
columnsn = np.concatenate(
(vaild_dataset.classes, np.array(["target", "真实值"])), axis=0
)
pd_data_df = pd.DataFrame(pd_data, columns=columnsn)
# 把数据保存到Excel:CSV
csvpath = os.path.join(dir, "vaild")
if not os.path.exists(csvpath):
os.makedirs(csvpath)
pd_data_df.to_csv(os.path.join(csvpath, "vaild.csv"), encoding="GBK")
2. 模型指标矩阵化
2.1 混淆矩阵
混淆矩阵是一种特定的表格布局,用于可视化监督学习算法的性能,特别是分类算法。在这个矩阵中,每一行代表实际类别,每一列代表预测类别。矩阵的每个单元格则包含了在该实际类别和预测类别下的样本数量。通过混淆矩阵,我们不仅可以计算出诸如准确度、精确度和召回率等评估指标,还可以更全面地了解模型在不同类别上的性能。
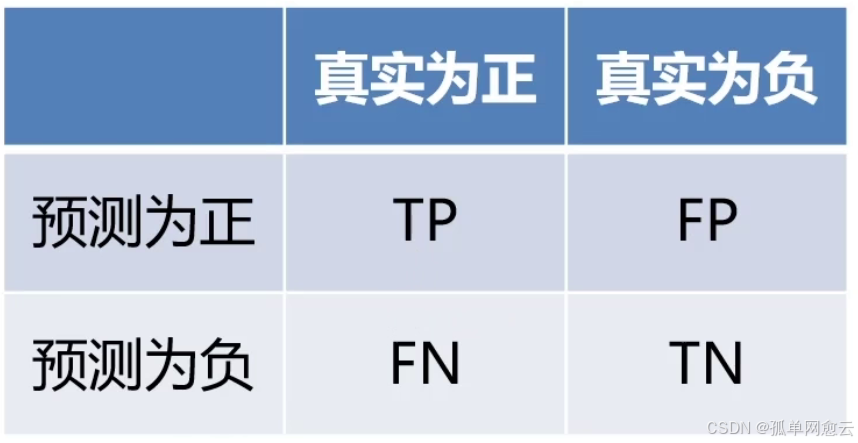
混淆矩阵的四个基本组成部分是:
- True Positives(TP):当模型预测为正类,并且该预测是正确的,我们称之为真正(True Positive);
- True Negatives(TN):当模型预测为负类,并且该预测是正确的,我们称之为真负(True Negative);
- False Positives(FP):当模型预测为正类,但该预测是错误的,我们称之为假正(False Positive);
- False Negatives(FN):当模型预测为负类,但该预测是错误的,我们称之为假负(False Negative)
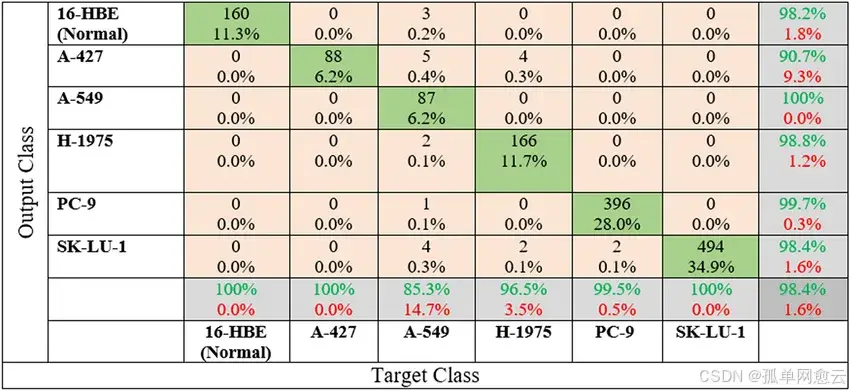
2.2 常见指标
参考下图

2.3 理解对角线
对角线上的元素越大越好
2.4 模型指标计算及可视化
2.4.1 分类报告
csvpath = os.path.join(dir, "vaild")
# 读取CSV数据
csvdata = pd.read_csv(
os.path.join(csvpath, "vaild.csv"), encoding="GBK", index_col=0
)
# 拿到真实标签
true_label = csvdata["target"].values
print(true_label, type(true_label), len(true_label))
# 获取预测标签
predict_label = csvdata.iloc[:, :-2].values
print(predict_label, predict_label.shape)
# 预测分类及分数的提取
predict_label_ind = np.argmax(predict_label, axis=1)
predict_label_score = np.max(predict_label, axis=1)
print(predict_label_ind, predict_label_score)
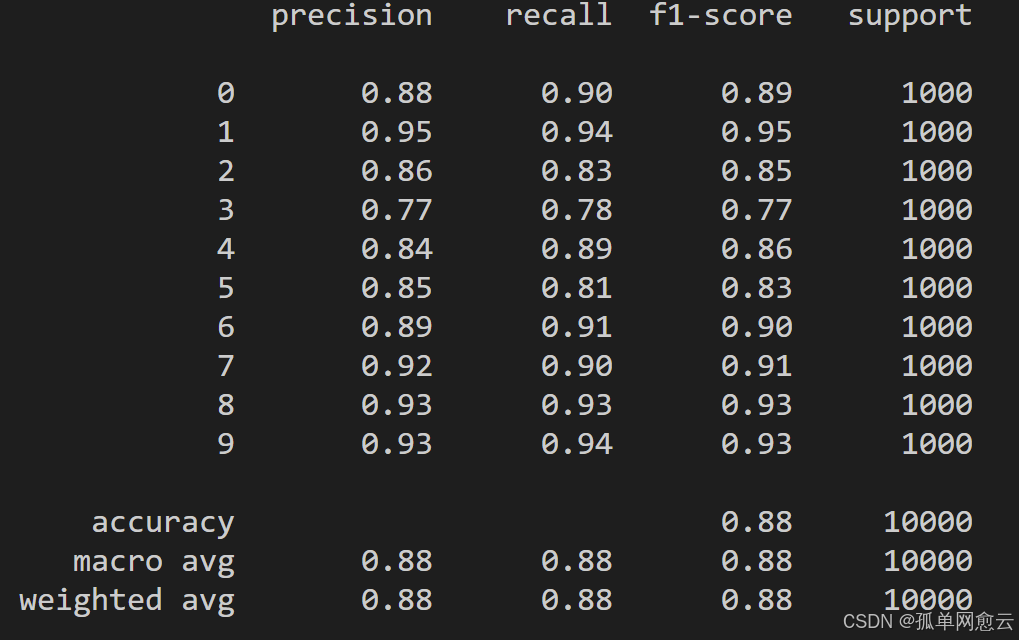
# 根据预测值和真实值生成分类报告
report = classification_report(y_true=true_label, y_pred=predict_label_ind)
print(report)
效果:
2.4.2 准确度(Accuracy)
# 获取准确度
acc = accuracy_score(y_true=true_label, y_pred=predict_label_ind)
print("准确度:", acc)
2.4.3 精确度(Precision)
# 获取精确度Precision
precision = precision_score(y_true=true_label, y_pred=predict_label_ind, average="macro")
print("精确度:", precision)
2.4.4 召回率(Recall)
#召回率(Recall)
recall = recall_score(y_true=true_label, y_pred=predict_label_ind, average="macro")
print("召回率:", recall)
2.4.5 F1分数(F1-Score)
#### F1分数(F1-Score)
f1 = f1_score(y_true=true_label, y_pred=predict_label_ind, average="macro")
print("F1分数:", f1)
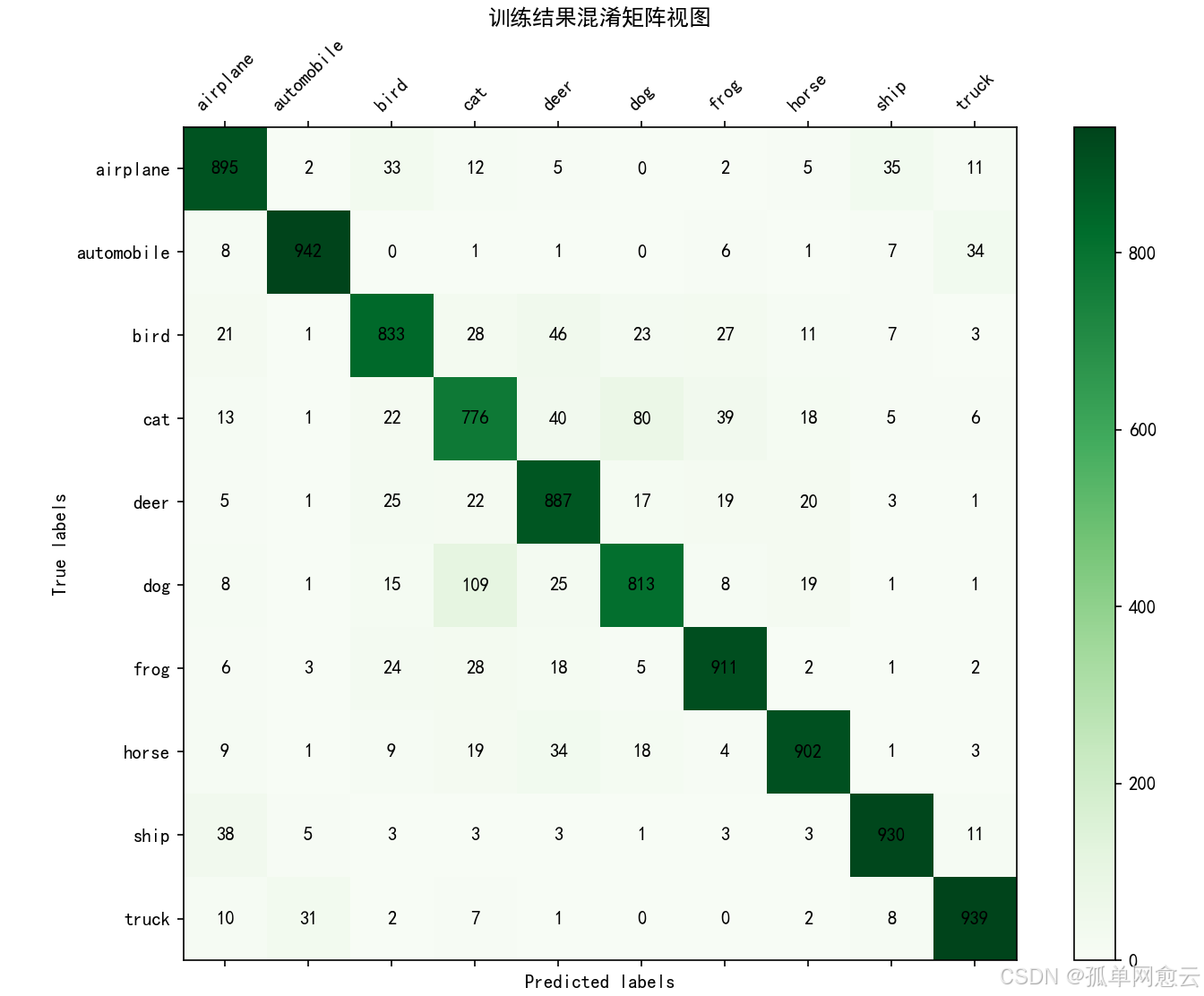
2.4.6 混淆矩阵及可视化
# 准备混淆矩阵数据
# 获取数据的表头
labels = csvdata.columns.values[:-2]
print(labels)
confusion = confusion_matrix(
y_true=true_label,
y_pred=predict_label_ind,
labels=[i for i in range(len(labels))],
)
print('混淆矩阵:', confusion)
# 使用plt绘制
# 把pandas数据第一行作为标签
plt.matshow(confusion, cmap=plt.cm.Oranges)
plt.colorbar()
for i in range(len(confusion)):
for j in range(len(confusion)):
plt.annotate(
confusion[j,i],
xy=(i, j),
horizontalalignment="center",
verticalalignment="center",
)
plt.xlabel("Predicted labels")
plt.ylabel("True labels")
plt.xticks(range(len(labels)), labels, rotation=45)
plt.yticks(range(len(labels)), labels)
plt.title("训练结果混淆矩阵视图")
plt.show()
效果:
六、网络性能提升
1. 使用更复杂的模型
官方提供了强大的模型可供我们使用:
https://pytorch.org/vision/0.17/models.html#classification
1.1 导入模型
# 导入模型:我这里依然使用了以前的模型名称,只是为了不改代码
from torchvision.models import resnet18 as ImageClassifier
1.2 使用模型
#num_classes参数很重要,是你要的分类数量,默认是1000
model = ImageClassifier(num_classes=10)
就这么就完事了~~~
2. 使用迁移学习
在原始的已经学习了基本特征的权重参数基础之上,继续进行训练,而不是每次都从0开始。
原始权重参数:
- 官方经典网络模型的预训练参数:别人已经训练好了;
- 也可以是自己训练好的权重文件;
迁移学习步骤:
2.1 导入
from torchvision.models import resnet18, ResNet18_Weights
2.2 初始化
weight = ResNet18_Weights.DEFAULT
model = resnet18(weights=weight)
model.to(device)
2.3 保存初始权重文件
# 保存模型权重文件到本地
if not os.path.exists(os.path.join(mdelpath, f"model_res18.pth")):
torch.save(model.state_dict(), os.path.join(mdelpath, f"model_res18.pth"))
2.4 修改网络结构
重新加载resnet18模型并修改网络结构。
ResNet18默认有1000个类别,和我们的需求不匹配需要修改网络结构
# 重新加载网络模型:需要根据分类任务进行模型结构调整
pretrained_model = resnet18(weights=None)
# print(pretrained_model)
in_features_num = pretrained_model.fc.in_features
pretrained_model.fc = nn.Linear(in_features_num, 10)
2.5 调整权重参数
以满足调整网络结构后的新模型,主要在全连接层
# 加载刚才下载的权重参数
weight18 = torch.load(os.path.join(mdelpath, f"model_res18.pth"))
print(weight18.keys())
# 全连接层被我们修改了,需要删除历史的全连接层参数
weight18.pop("fc.weight")
weight18.pop("fc.bias")
# 获取自己的模型的参数信息
my_resnet18_dict = pretrained_model.state_dict()
# 去除不必要的权重参数
weight18 = {k:v for k, v in weight18.items() if k in my_resnet18_dict}
#更新
my_resnet18_dict.update(weight18)
2.6 新参数+新模型
# 处理完后把最新的参数更新到模型中
pretrained_model.load_state_dict(my_resnet18_dict)
model = pretrained_model.to(device)
可以了,其他代码不用改了~~~
#保存模型的时候注意一下:为了迁移学习,可以覆盖一开始的权重文件
torch.save(model.state_dict(), os.path.join(mdelpath, f"model_res18.pth"))
3. 调整优化器和学习率
3.1 冻结层
对于不在需要训练的网络层,可以把梯度更新关闭:根据具体需求来,会影响训练效果。
# 冻结层:自己打印和调试,是完全可以的
for name, value in pretrained_model.named_parameters():
if name != "fc.weight" and name != "fc.bias":
value.requires_grad = False
# 开始筛选需要进行梯度更新的参数,而不是全部
params_grade_true = filter(lambda x: x.requires_grad, pretrained_model.parameters() )
# 创建优化器
# optimizer = optim.Adam(model.parameters(), lr=learning_rate)
optimizer = optim.Adam(params_grade_true, lr=learning_rate)
3.2 学习率的调整
StepLR 是 PyTorch 中的一种学习率调度器,用于以固定步长周期性地降低学习率。
#step_size:每经过多少个 epoch,学习率减少一次。
#gamma:学习率每次减少时的倍率因子。 0.01 ---> 30个ecposh之后,变成0.001---> 30个ecposh之后,变成0.0001
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# 一轮训练完更新学习率
scheduler.step()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









