



 本文探讨了集成电路设计中关键的偏差类型,包括工艺偏差(全局与局部)、温度偏差和电压偏差。工艺偏差影响芯片生产过程,温度偏差关注晶体管速度变化,而电压偏差源于电源稳定性。理解这些偏差对于确保电路在各种条件下正常工作至关重要。
本文探讨了集成电路设计中关键的偏差类型,包括工艺偏差(全局与局部)、温度偏差和电压偏差。工艺偏差影响芯片生产过程,温度偏差关注晶体管速度变化,而电压偏差源于电源稳定性。理解这些偏差对于确保电路在各种条件下正常工作至关重要。

开篇。
要了解ocv aocv socv pocv等概念,需要先了解与之相关的variation的概念,其实各种ocv其实就是对variation的数学抽象,区别仅是哪种更为精确。

如图,偏差可分为工艺偏差,温度偏差,电压偏差。设计中引入各种偏差的目的是使得我们的电路能够在我们设计的PVT的整个范围内,都能够正常工作。
工艺偏差(process variation)
工艺偏差,指的是芯片在生产过程中引入的偏差,可以分为全局工艺偏差,局部工艺偏差。
全局工艺偏差 (global process variation)
全局工艺偏差,包含了相同wafer中die与die之间以及wafer与wafer之间,lot与lot之间的偏差。
单元库需要包括多个不同PVT条件下的时序库。
通过不同PVT下单元库进行电路进行特征化进行的。在芯片进行签收(signoff)时需要在多个不同的PVT下进行,就是为了弥补不同的全局工艺偏差。
由于历史的原因,比较老的工艺下,对单元库进行特征值提取时,也会考虑的局部工艺偏差(从名称上,ssg ffg则是指的global工艺偏差 ,ss ff则表示也包含了local工艺偏差)。而这会引入不必要的悲观,在先进工艺下,已经不再采用这种方式,在后续的章节中我们再进行介绍。
局部工艺偏差 (local process variation)
局部工艺偏差, 则指的是同一个die内部,不同位置的process上的差别。
对于局部工艺偏差,需要包含在我们的OCV设置中,而OCV设置的方法有一下几种:On-chip Variation Advanced OCV(AOCV) POCV (LVF)
温度偏差 (temprature variation)
晶体管的速度会受到温度的影响而变化。对于金属互联线,温度影响较小。
温度偏差包括了环境温度,以及由于芯片运行所导致的温度升高。
环境温度容易测量,但是真正对晶体管的影响表现在结温(junction temprature)。
结温是环境温度以及芯片本身运行所导致的温度升高之和。
真正对晶体管产生影响的实际上是结温。
而且结温通常会远高于环境温度。
例如,对于工业级芯片,环境温度多会处于-40C以及85C之间。但是在进行signoff时,往往需要进行125C的signoff。
对于工艺库中的标称温度,同样也指的是结温。如果想知道结温与环境温度的关系,则需要根据不同的封装的参数进行热仿真来获得。
对于军用级芯片,往往-40C~125C的结温范围仍然不够,这样则需要提供额外PVT条件下的时序库或者增加相应的余量以便能够覆盖超出的温度范围。而这部分的余量,可以增加额外的derating,也可以通过设置更大的uncertainty值来实现。
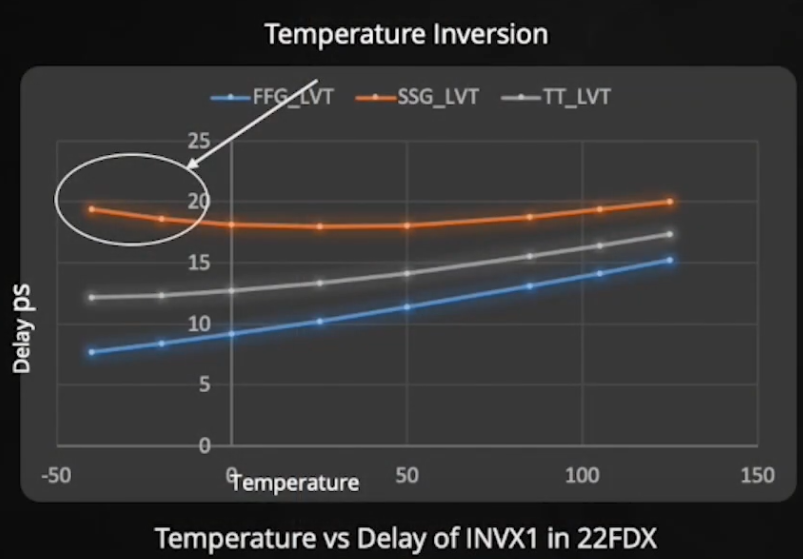
备注:通常来说,温度的升高会导致cell的延迟增大,但是由于先进工艺中存在温度反转的现象,仅仅在高温下进行setup的时序检查已然不够。因此,也需要同时检查最高温度以及最低温度下的setup时序。
电压偏差 (voltage variation)
电压偏差的来源有多种,例如电压源精度,电源网络的电压降,环境噪声,mos管活动本身都会导致电源网络的电压的变化。
现实中是不存在一个理想的电压源的。
因此,芯片需要在一个电压范围内都能够正常工作。
我们拿到的时序库,通常会覆盖标称电压(nominal voltage)的±10%的范围,就是这个原因。
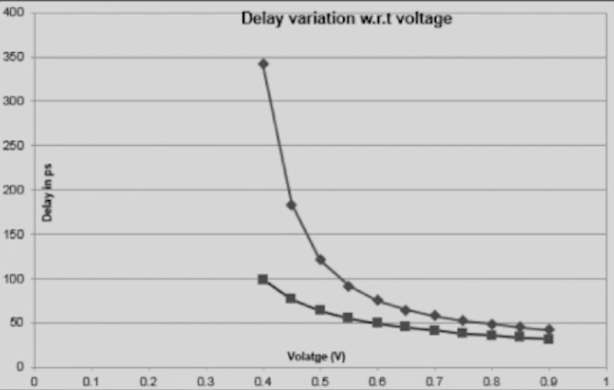
待续
目前相当于素材积累阶段。主要是大纲还没想好。


















 8974
8974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









