




【NIPS2023】Rank-DETR for High Quality Object Detection
机构:清华大学、北京大学、剑桥大学、微软亚洲研究院
论文地址:https://arxiv.org/abs/2310.08854
代码地址:https://github.com/LeapLabTHU/Rank-DETR
作者简介:黄高,清华大学博士学位,康奈尔大学计算机系博士后,清华大学自动化系助理教授、博士生导师,获阿里巴巴“达摩院青橙奖”、2019年吴文俊人工智能优秀青年奖等。代表作DenseNet获得CVPR2017年最佳论文、Stochastic Depth。研究方向包括动态神经网络、高效深度学习。
本文考虑到DETR模型中query的重要性存在差异,致力于改进高IoU情况下(例如AP@75)的检测性能,首次提出基于排序思想的Rank-DETR,在Transformer中引入排序相关的网络层、排序导向的损失函数和匈牙利匹配损失。在COCO数据集上的性能高于DINO、Align-DETR、GroupDETR等baseline,与Stable-DINO、MS-DETR、Salience-DETR相当,弱于DDQ-DETR、Co-DETR、Relation-DETR等SOTA方法。
文章贡献/创新点
- 在Transformer Decoder中提出了基于rank机制改进的分类头和query排序层。
- 在损失函数(网络损失和匈牙利匹配损失)中对分类和回归分支进行对齐,使得高置信度的query也具有高IoU。
- 实验验证了所提方法的有效性,并将rank机制引入到已有DETR方法中验证了有效性。
排序相关的结构设计
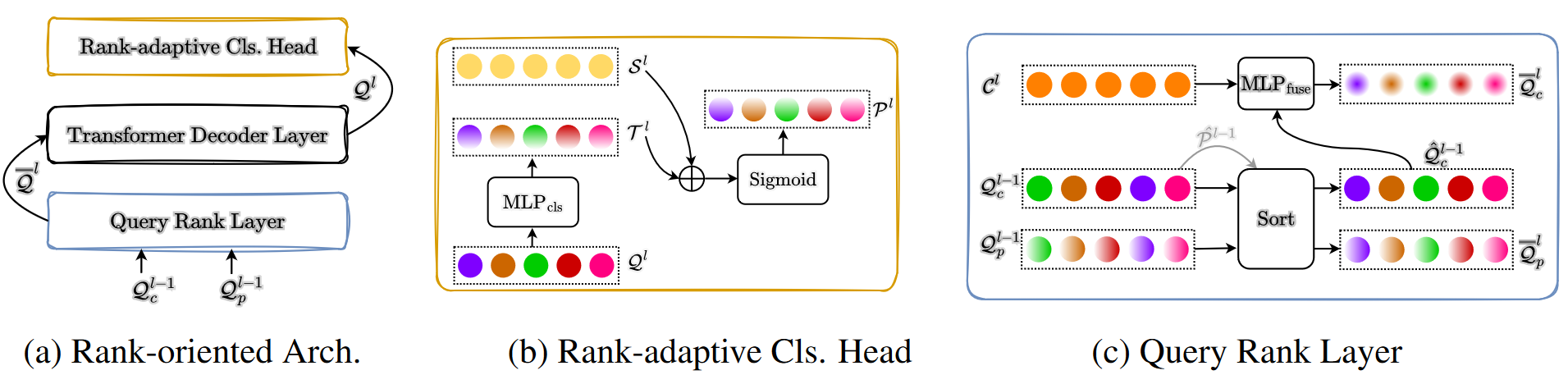
排序自适应的分类头
常规的DETR方法中,backbone提取多尺度特征,transformer将其映射为6层Decoder输出(两阶段方法还会多1层Encoder输出),每层的输出都是 n n n个query(原始DETR中 n = 100 n=100 n=100、DeformableDETR中 n = 300 n=300 n=300、DINO中 n = 900 n=900 n=900),针对第 l l l层的每个query,表示为 q i l q_i^l qil,head将其映射为分类结果 p i l \boldsymbol p_i^l pil+回归结果,其中分类头是单层全连接:
p i l = S i g m o i d ( r i l ) , t i l = MLP cls ( q i l ) \boldsymbol p_i^l=\mathrm{Sigmoid}(\boldsymbol r_i^l), \boldsymbol t_i^l=\text{MLP}_\text{cls}(\boldsymbol q_i^l) pil=Sigmoid(ril),til=MLPcls(qil)
本文提出的排序自适应分类头其实就是为每个query增加了对应的embedding,两者加起来再进行分类:
p i l = S i g m o i d ( t i l + s i l ) , t i l = MLP cls ( q i l ) \boldsymbol p_i^l=\mathrm{Sigmoid}(\boldsymbol t_i^l+\boldsymbol s_i^l), \boldsymbol t_i^l=\text{MLP}_\text{cls}(\boldsymbol q_i^l) pil=Sigmoid(til+sil),til=MLPcls(qi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









