




【TMM2017】Attentive Contexts for Object Detection
北京理工大学、北京交通大学、中山大学、新加坡国立大学
论文地址:https://arxiv.org/pdf/1603.07415.pdf
作者简介:Shuicheng Yan(颜水成),北京大学博士学位,微软亚洲研究院实习,香港中文大学汤晓鸥教授的多媒体实验室任博士后,美国伊利诺伊大学香槟分校师从黄煦涛(Tomas Huang),后加入新加坡国立大学创立机器学习与计算机视觉实验室,拥有终身教职。目前与昆仑万维创始人周亚辉一起出任天工智能联席CEO,并兼任昆仑万维2050全球研究院院长。
本文首次使用基于注意力机制的全局和局部上下文信息来进行目标检测,并通过LSTM递归地生成注意力图,最终融合全局和局部上下文信息提高检测性能!
文章贡献/创新点
- 文章提出了最新的注意力到上下文CNN(AC-CNN)目标检测模型,能够有效地上下文化主流基于候选框的CNN检测器。
- 基于注意力机制的全局上下文子网能够递归地生成注意力位置图来帮助利用最具判别性的特征以指导局部目标检测。
- 每个候选框内外的局部上下文信息可由提出的局部上下文子网捕获,来增强特征表示。
- 大量实验表明所提的AC-CNN能够有效增强主流的基于区域的CNN检测模型。
注意力到上下文卷积神经网络
网络的输入为图片和对应的物体候选框,图片首先通过一些卷积层和最大池化层来生成卷积特征图。然后基于注意力的全局上下文子网和多尺度局部上下文子网用于利用有用的全局和局部上下文信息来进行最终物体的分类和回归。
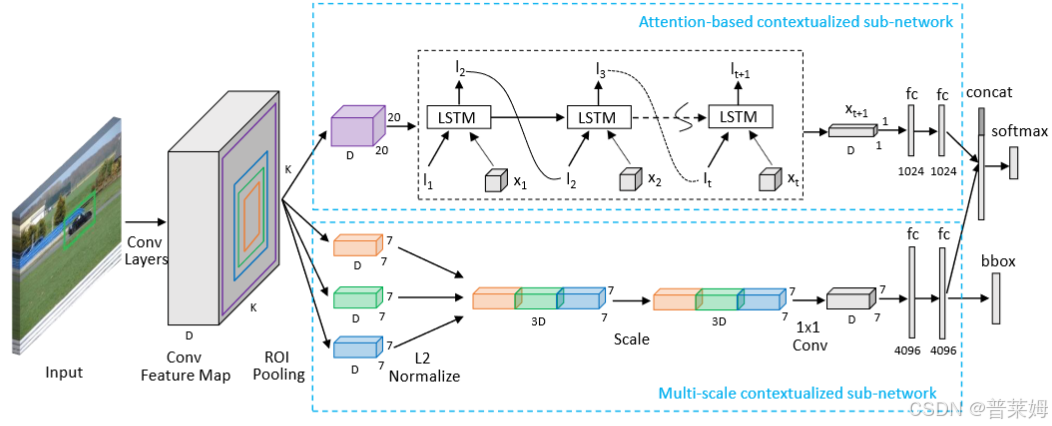
基于注意力的全局上下文子网
全局上下文子网利用有用的全局上下文信息,首先将特征图池化为 K × K × D K\times K\times D K×K×D固定尺寸,实验中将其固定为 20 × 20 × 512 20\times 20\times 512 20×20×512。将特征矩阵中的特征切片表示为 X = [ x i , ⋯ , x K 2 ] X=[\boldsymbol x_i,\cdots,\boldsymbol x_{K^2}] X=[xi,⋯,xK2],其中 x i ( i = 1 , ⋯ , K 2 ) \boldsymbol x_i(i=1,\cdots,K^2) xi(i=1,⋯,K2)为 D D D维,再送入堆叠的三层LSTM单元中。
( i t f t o t g t ) = ( σ σ σ tanh ) M ( h t − 1 x t ) c t = f t ⊙ c t − 1 + i t ⊙ g t h t = o t ⊙ t a n h ( c t ) \left(\begin{matrix} \boldsymbol i_t\\\boldsymbol f_t\\\boldsymbol o_t\\\boldsymbol g_t \end{matrix}\right)=\left(\begin{matrix} \sigma\\\sigma\\\sigma\\\tanh \end{matrix}\right)M\left(\begin{matrix} \boldsymbol h_{t-1}\\x_t \end{matrix}\right)\\ \boldsymbol c_t=\boldsymbol f_t\odot\boldsymbol c_{t-1}+\boldsymbol i_t\odot\boldsymbol g_t\\ \boldsymbol h_t=\boldsymbol o_t\odot \mathbf{tanh}(\boldsymbol c_t) itftotgt = σσσtanh M(ht
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1674
1674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









