







本文对中稿ECCV2024的Relation DETR进行分析,通过三个部分进行分析:针对何种问题提出了什么创新?为什么它能够有效?效果如何?
论文地址:https://arxiv.org/pdf/2407.11699
1、What?
引入了一个编码器来构建位置关系嵌入以实现注意力的逐步优化,在讲这个创新前,需要知道背景意义和这个模块需要解决的问题是什么。
1、背景:
针对位置嵌入解决非重复预测与正样本监督之间的冲突提出对自注意力的创新(DETR收敛慢,由于匹配1对1,大部分都为负向预测,这部分负向主导了损失,造成正向监督不足。以往都是从架构上改进:如去噪查询和混合查询等。没有从自注意力的角度来解决这个问题)
自注意力是没有利用结构偏置,从大量的训练数据中学习位置信息。这也是Transformer训练慢,所需的数据量大的原因。基于这个问题,提出显式位置关系先验。
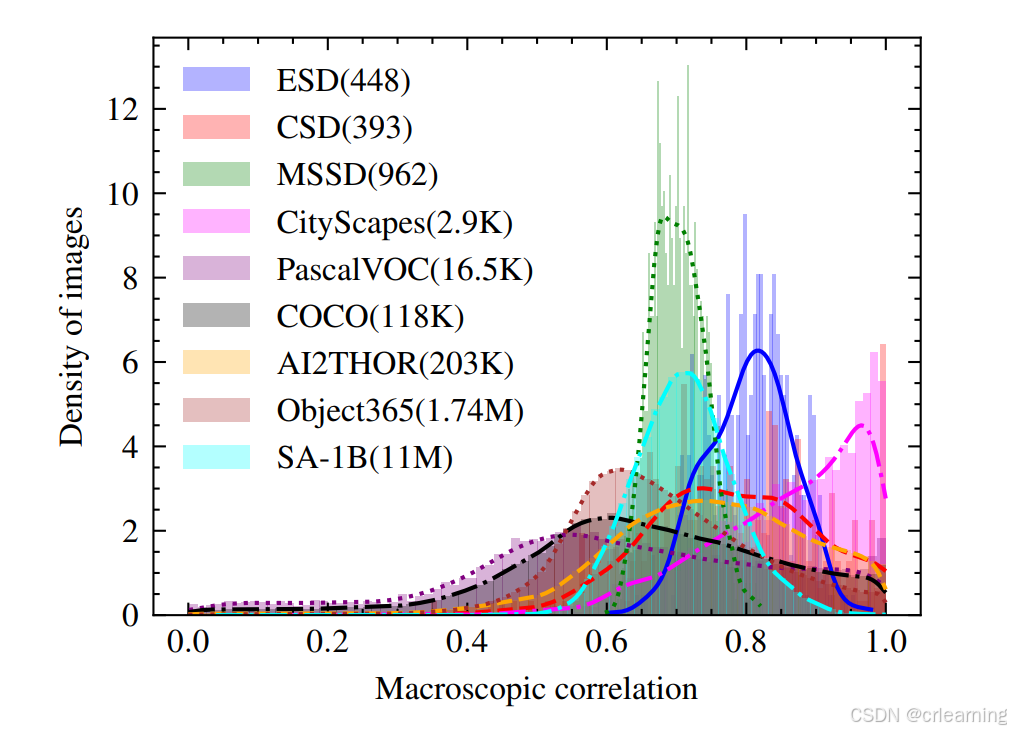
那么就有个问题是,需要检测的框之间真的存在位置关系吗?下面为作者做的可视化分析
2、可行性分析:
通过公式:
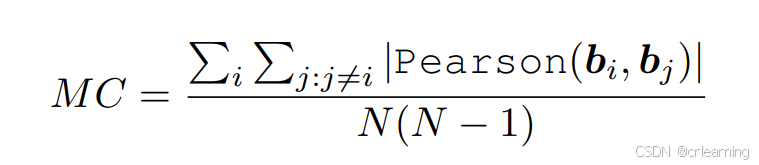
其中MC=0代表目标框之间无位置相关性,MC=1代表目标框之间完全线性相关。下图为各个数据集中的MC值,普遍集中于MC高分值,表明了目标框之间确有位置相关性。
2、Why?
上面讲完为什么需要提出一种新的显式位置编码,接下来说明一下Relation DETR中是如何实现这个创新。包括生成位置关系嵌入的编码器和优化后的自注意力模块,最后还提出一种对比关系pipline。
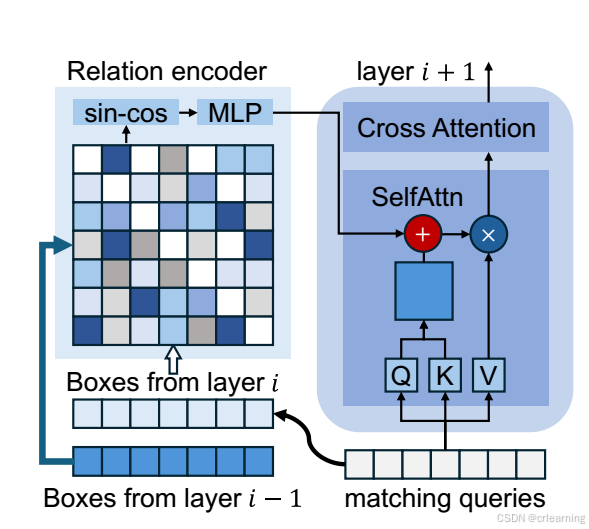
1、位置关系编码position relation encode
这个模块的作用是生成box之间的位置关系,具体做法:首先计算两个box之间的位置信息,通过中心点和宽高,然后再通过正余弦编码器,再经过一个全连接层,并确保输出为正值防止自注意力时梯度消失: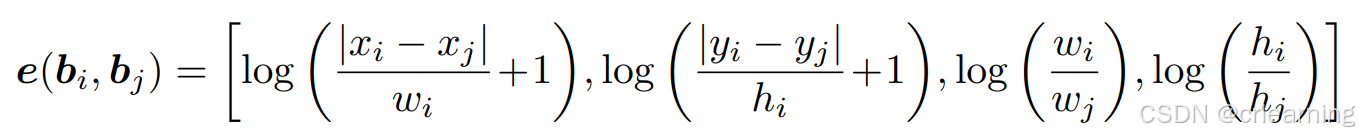
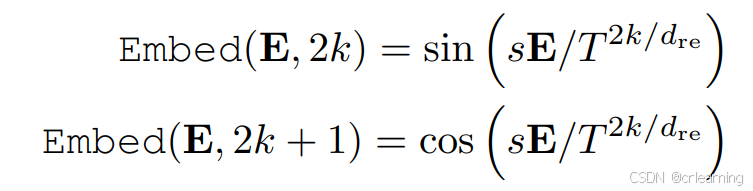
![]()
2、基于位置关系的渐进式注意力细化
这部分是优化自注意力模块,利用上位置关系的embeding信息,通过下面的公式和结构就可看出,这个模块还是相对较为清晰。 
下图中,左图为Deformable DETR中的逐层细化Decoder,右图为Relation DETR中的Decoder,加入了位置关系模块,其输入为每层优化后的box和前一层的box进行计算位置关系嵌入,并输入到优化后的自注意力模块中,逐步迭代。(为什么不是每层优化后的box和自己进行计算位置关系嵌入?个人理解:每一层的 box 是对上一层预测结果的修正结果,如果只使用当前层的 box,模型可能会忽略累积的关系优化历史,失去渐进优化的效果。同时也可避免过拟合到单一层的错误信息)
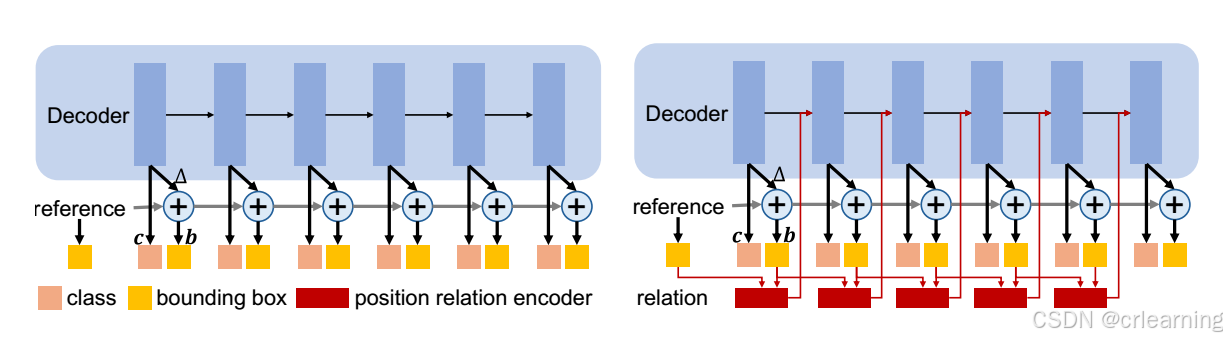
下图为优化后的自注意力模块图
3、对比关系流程
混合查询自注意力只存在训练阶段,为了进一步提升模型收敛速度
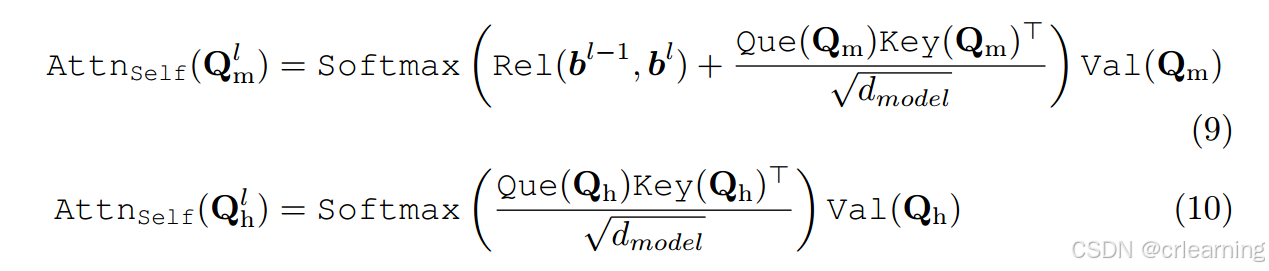
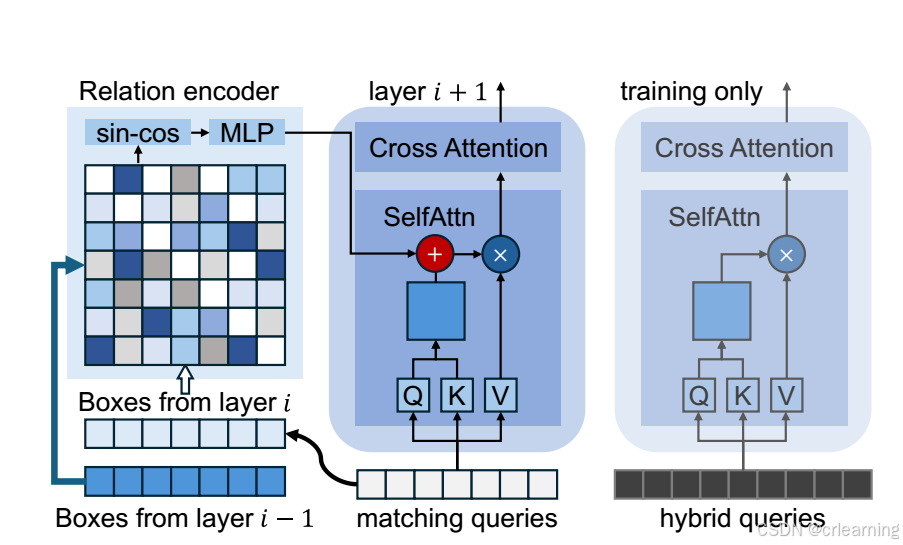
其中混合查询采用一对多的匹配方式,将GT复制多份。
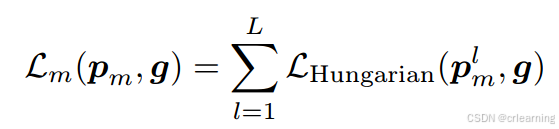
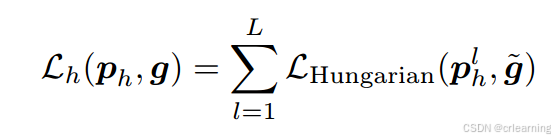
3、How?
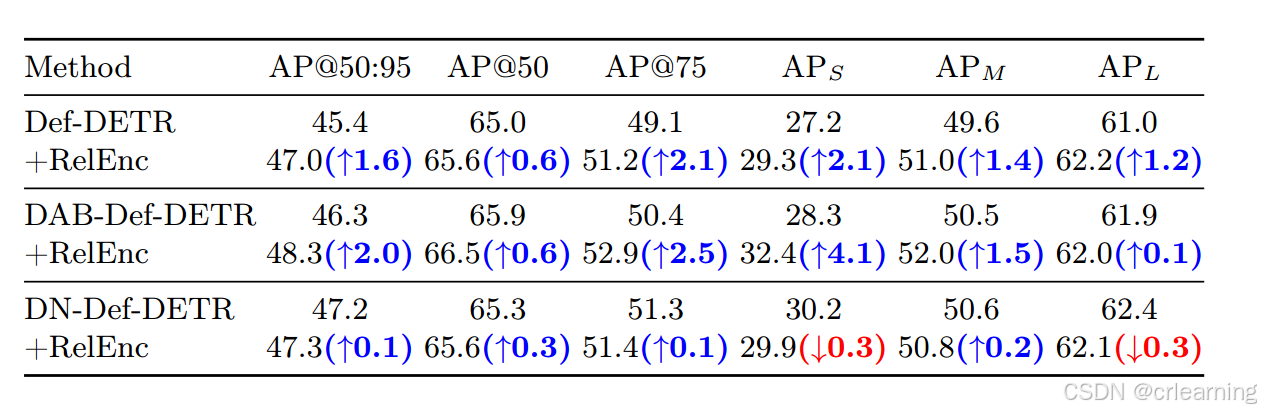
通过下面的消融实验可以看出,采用位置编码在模型上都能够有所提升

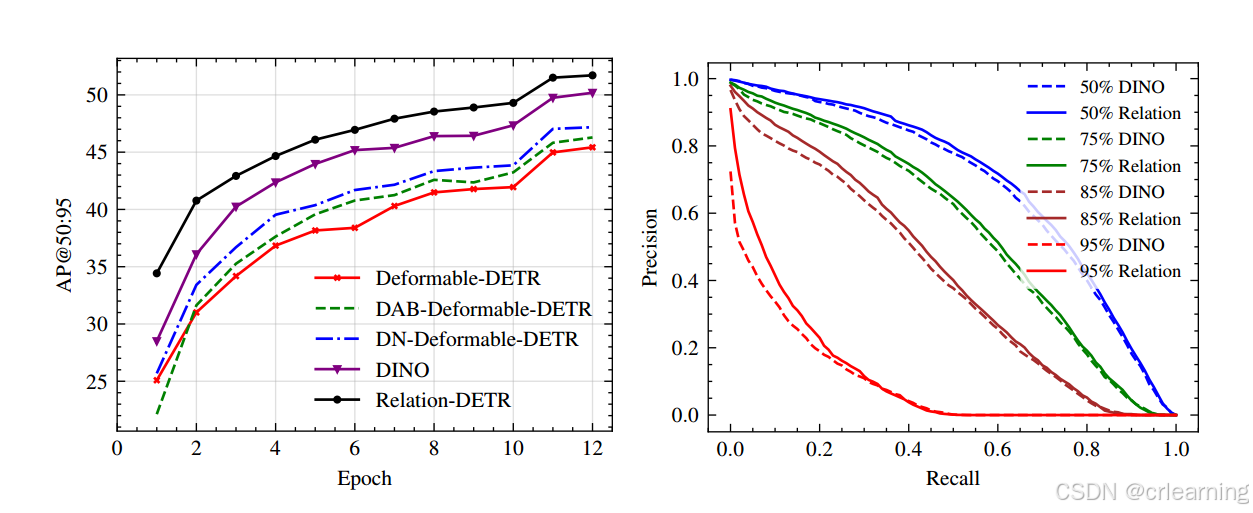
通过训练曲线图也可看出,Relation DETR收敛速度更快
总结:
通过引入显式的位置关系先验,Relation-DETR在自注意力机制中加入了结构性偏置,弥补了传统DETR在输入上缺乏结构性偏置的问题。这种先验知识的引入,使模型能够更有效地捕捉目标之间的位置关系,从而加速收敛并提高检测性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











