






摘要
作者认为大多数先前关于城市人群建模的研究未能描述人类移动性的动态性和连续性,导致在处理多个同质预测任务时结果不一致且不相关,因为这些任务只能独立建模。
改进:提出从新的角度对人类移动性进行建模,即使用由一系列从低阶到高阶的转移矩阵构成的全市人群转移过程,帮助我们理解人群动态如何逐步演变。
细节:提出了一个深度转移过程网络来处理和预测这种新的高维数据,其中设计了新颖的网格嵌入与图卷积网络、参数共享卷积LSTM和高维注意力机制,以学习空间、时间和序数特征方面的复杂依赖关系。
正文
作者从一个新的视角研究了城市人类移动性的建模,作者将其定义为城市人群转移过程(CTP)。作者的目标是通过逐步理解人群动态是如何演变的,来整合先前的同质问题。CTP 数据通过一系列转移矩阵描述了一段时间内的人群的流动。每个矩阵描述了这段时间内不同时间戳的人中扩散情况。这样一组矩阵共同构成了当前人群移动性的指标。
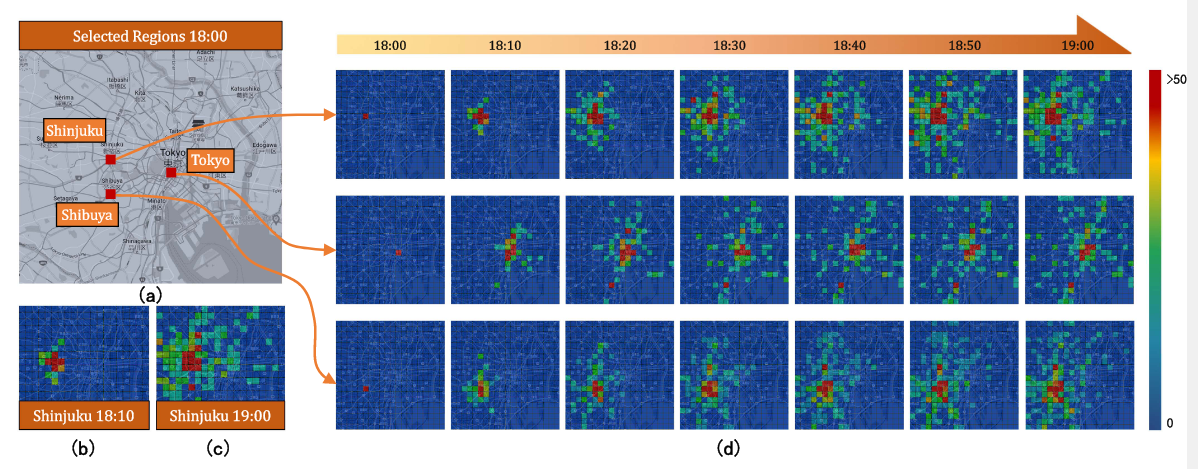
图 d 反映了三个 ctp 数据的例子。
通过堆叠所有区域的 ctp 张量,就可以形成一个城市范围的 ctp 张量。
与传统的OD矩阵相比,后者仅使用19:00的矩阵来描述18:00到19:00之间的人类移动性,城市范围的CTP数据可以在单个张量中为我们提供动态和连续的信息。
Ctp 张量有以下的难点:
- 显著且复杂的依赖关系。CTP数据具有三种依赖关系 - 空间、时间和序数。
- 高维张量。CTP预测任务需要处理高维张量,这是由于转移矩阵的堆叠。
- 数据稀疏性。从一个区域出发的人群很少在一段时间后覆盖整个城市区域,导致CTP张量非常稀疏。
为了解决这些挑战,我们提出了一个图卷积循环神经网络,称为深度转移过程网络(DTP-Net),以解决预测任务。
DTP-Net被构建为一个新颖的高维深度神经网络,包括语义图卷积神经网络(GCN)、共享卷积LSTM(ConvLSTM)和高维注意力(HD-Attention)模块。
语义GCN首先学习网格嵌入以捕捉区域之间存在的相关性。然后共享ConvLSTM将遍历高维数据以探索每个单独区域的独特特征。进一步采用HD-Attention来考虑不同序数转换的多样性。
贡献
- 提出使用城市人群转移过程作为一个新视角来模拟人类移动性,这可以显著帮助我们理解人群移动的动态性和连续性。
- 提出了一种新颖的图卷积循环深度学习模型,该模型解构了高维数据中的复杂依赖关系,并在统一的框架下探索它们。
- 在两个真实世界的智能手机GPS数据集上验证了作者的模型。并且作者公布了作者的数据作为第一个大规模人群转移过程数据集,以帮助其他研究者跟进这项工作
深度转移过程网络
给定观察到的全市范围内的人群转移过程(CTP)张量 Xin ∈ Rα×N×N×λ,需要处理张量轴上的三种依赖关系:第二和第三维度(N, N)上的空间依赖性,α 维度上的时间依赖性,以及 λ 维度上的序数依赖性。
而DTP-Net 通过三个连续步骤来解耦高维数据中的依赖关系:
- 嵌入相邻网格之间的相关性;
- 推断每个网格的未来转移过程;
- 考虑不同转移顺序之间的多样性。
总体设计
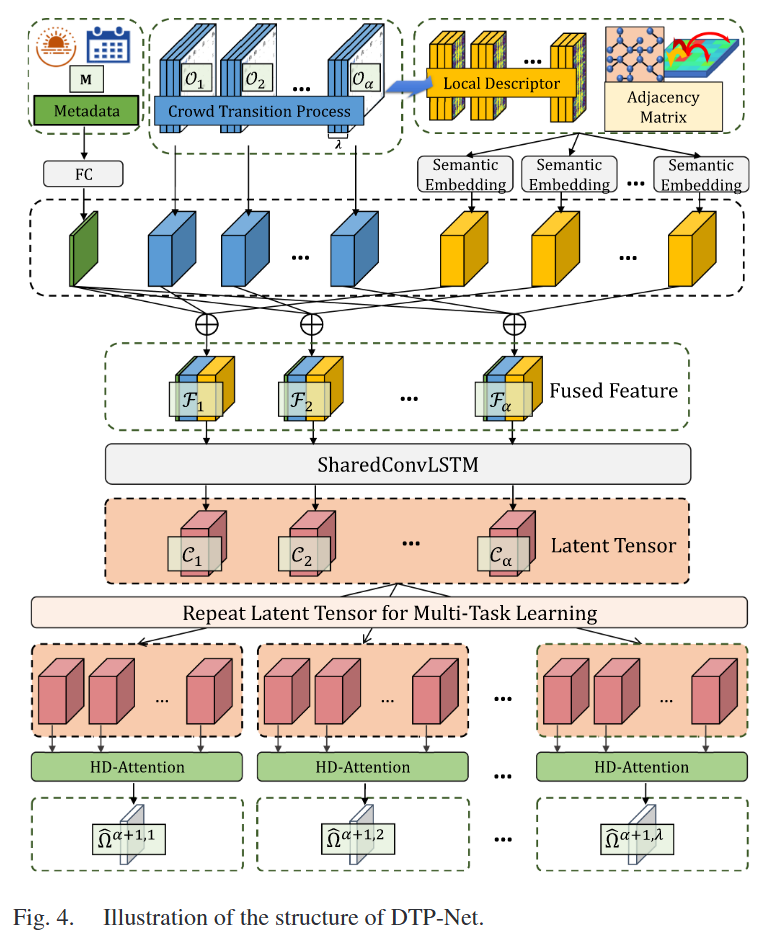
DTP-Net 以 CTP 数据和元数据作为输入。网络首先基于局部转移描述符通过图卷积学习网格嵌入,然后将嵌入数据与原始 CTP 数据和元数据聚合为融合张量。通过共享的 ConvLSTM 从融合张量中提取潜在张量后,利用高维注意力机制获得 1 到 λ 阶人群转移矩阵的最终预测。
通过图卷积进行语义网格嵌入
原因:两个区域之间频繁的人流表明它们之间存在强相关性,这反过来会影响一个网格对另一个网格的人群转移。整合每个网格的这种依赖性将有助于预测未来转移的变化
作者设计了一个局部转移描述符并执行网格嵌入来探索不同网格之间的相互作用。
局部转移描述符
作者对 CTP 数据的每个阶单独进行网格嵌入。给定阶数 o 的转移矩阵,嵌入通过将语义相似的网格放在嵌入空间中的相近位置来捕捉网格之间的相关性。
当前的嵌入方法不适用于 CTP 的预测任务。因为大多数不活跃和低速人群占总人口的大部分,一个网络的目的地分布大致遵循以自身为中心的二维正态分布。如下图所示,这意味着人群目的地分布将围绕源网格的邻近区域,而远距离区域人口稀疏。如果将从这个网格到整个城市的目的地作为其原始特征(图 5(a)中红色矩形所示),在展平和堆叠所有网格特征后,特征矩阵将呈现交叉结构,大值集中在对角线上。
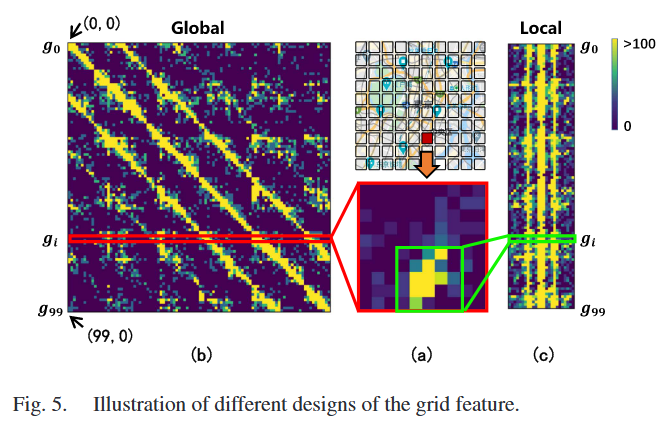
当前的嵌入方法:将网格 gig_igi 的目的地分布向量 Ωit,o∈R1×N\Omega_i^{t,o} \in \mathbb{R}^{1 \times N}Ωit,o∈R1×N 视为其原始特征。来自 gig_igi 相关网格的所有特征都用可学习的权重求和,以产生 gig_igi 的嵌入结果。
作者忽略稀疏的远距离区域,只关注源网格的密集邻居。提出了一个新的描述符来表征网格,而不是使用简单的原始转移向量。使用形状为 S = s × s 的核窗口,将从 gig_igi 到其近邻的人群转移视为 gig_igi 的局部转移描述符。局部转移描述符的展平向量作为网格的新原始特征。对城市边界的网格使用零填充。局部转移描述符使我们避免了多层卷积操作后过度平滑的问题。
语义网格嵌入
原因:由于城市的不同网格通过道路和铁路相连,网格地图中的人群转移类似于图中的消息传播,表明转移数据中存在非局部关系。
由于 CNN 在收集这种非局部空间依赖性方面的限制,作者基于语义邻接矩阵在人群转移数据上使用图卷积网络(GCN)来学习网格嵌入。
城市中的邻接关系被建模为语义图 G = (V, E, A),其中 V 是网格集合,E 是边集合,A 是由转移强度定义的语义邻接矩阵
Ai,j=∑t=1T∑o=1λO(t,i,j,o)∑t=1T∑j=1N∑o=1λO(t,i,j,o)+ϵ A_{i,j} = \frac{\sum_{t=1}^T \sum_{o=1}^{\lambda} O(t,i,j,o)}{\sum_{t=1}^T \sum_{j=1}^N \sum_{o=1}^{\lambda} O(t,i,j,o) + \epsilon}Ai,j=∑t=1T∑j=1N∑o=1λO(t,i,j,o)+ϵ∑t=1T∑o=1λO(t,i,j,o)
其中 T 表示所有可用的观察步骤。ε 是一个接近零的小值,防止分母为零。
现在的研究从两个方向将 CNN 推广到 GCN,一种是基于谱的方法,一个是基于空间的方法。由于基于空间的 GCN 有更高的效率和灵活性,所以在空间域中定义每个局部转移矩阵上的图卷积, 以获得嵌入矩阵:
Ψˉl+1o=σ(AΨloWlo), \bar{\Psi}_{l+1}^o = \sigma(A\Psi_l^oW_l^o), Ψˉl+1o=σ(AΨloWlo),
WloW_l^oWlo 是第 l 层的可学习参数,σ\sigmaσ 是激活函数。
1 到 λ 阶嵌入矩阵被连接形成嵌入张量 Et∈RN×N×λ\mathcal{E}_t \in \mathbb{R}^{N \times N \times \lambda}Et∈RN×N×λ。通过语义 GCN,捕捉了网络之间的相关性。此外,由于嵌入张量只包含原始 CTP 的部分信息,而日期和天气等外部信息可能对人类移动性产生重大影响,作者将原始 CTP 数据,嵌入数据了和无数据融合在一起,形成了融合张量,如下所示:
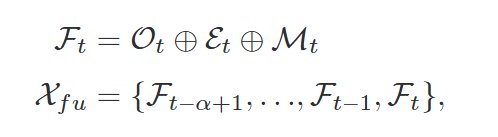
XfuX_{fu}Xfu 为融合张量序列。
通过共享ConvLSTM进行转移推理
语义GCN在融合张量Xfu中考虑了网格间相关性和外部影响。此外,还需要根据时间依赖性和嵌入向量推断转移的可能未来分布。
作者使用 ConvLSTM 作为序列分析组件,以捕捉 CTP 数据中的全局时空模式,因为它已成功应用于各种时间序列预测任务,并被证明是一种强大的数据序列建模工具。但是,融合张量古城了真实的空间邻近性,即:由(N, N)索引的邻居并不代表物理上相信的网格,使得直接对其进行卷积的操作变得无意义。所以作者将 N 扩展为 (H,W),然后展开的张量 Xre∈Rα×H×W×H×W×γ\mathcal{X}_{re} \in \mathbb{R}^{\alpha \times H \times W \times H \times W \times \gamma}Xre∈Rα×H×W×H×W×γ 将保留网格之间的空间邻接性。然而,将处理视频数据的 ConvLSTM 应用于这样的 6 D 张量是很有难度的。当将多个维度编码到单个通道以使其与 ConvLSTM 架构兼容时,可能会丢失时空信息,这可能会降低模型捕捉数据中复杂模式的能力。此外,在处理高维数据时,与 6 D 张量相关的计算复杂性也会增加。
作者提出了参数共享的 ConvLSTM 机制,由于网格之间的关系已嵌入到数据中,所以可以在处理 XreX_{re}Xre 时单独关注每个网格。参数共享机制借鉴了卷积神经网络,其中 ConvLSTM 单元在 6 D 张量上滑动,就像卷积核在图像上滑动一样。这意味着城市中一个网格的特征提取器也应用于其他网格。
如下图所示:
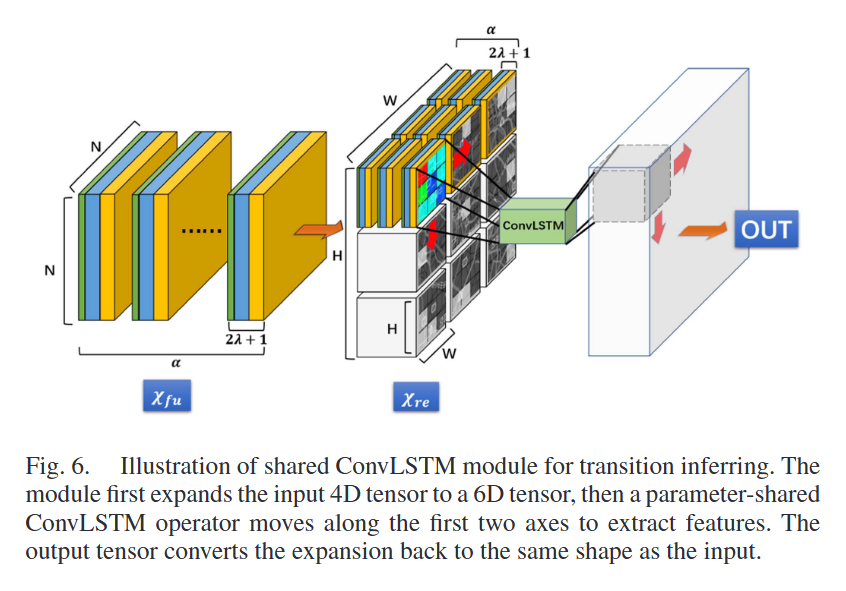
首先重塑并交换 XfuX_{fu}Xfu 的轴,使其变成 Xre∈RH×W×α×H×W×γ\mathcal{X}_{re} \in \mathbb{R}^{H \times W \times \alpha \times H \times W \times \gamma}Xre∈RH×W×α×H×W×γ。然后,ConvLSTM 单元沿 XreX_{re}Xre 的前两个轴移动,以提取 6 D 张量的特征。输出张量将被连接并被重塑回与输入相同的形状,以实现多层堆叠。参数共享机制通过减少参数空间来增强模型的泛化能力,使计算简洁高效。
此外,ConvLSTM单元的重复训练缓解了由于数据稀疏性导致的发散问题,这为我们提供了CTP数据的良好潜在表示。
共享 ConvLSTM 层可以表述如下:
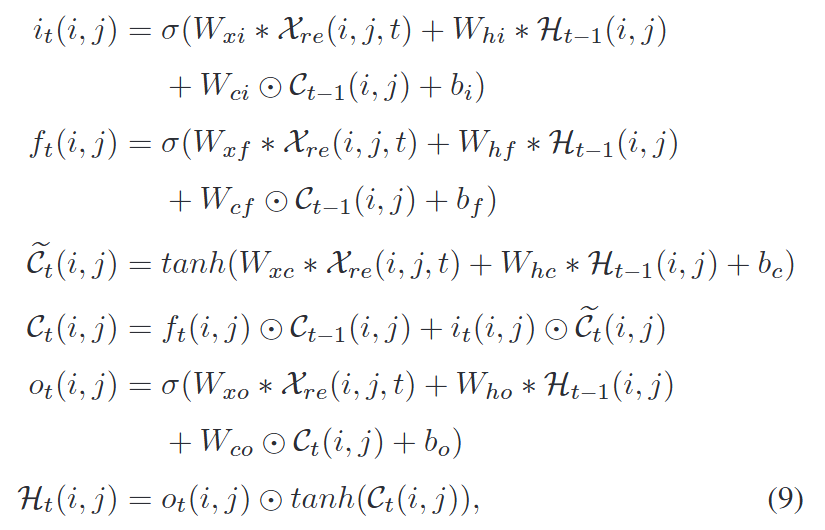
W是权重,b是偏置,∗表示卷积运算符,表示Hadamard乘积。
基于注意力机制的多阶学习
注意力机制可以用来突出潜在表示中最相关的信息,这有助于捕捉每个转移阶数的独特分布。注意力机制通过基于预测阶数的相关性为潜在表示分配不同的权重来运作,使其能够专注于共享ConvLSTM生成的最重要元素,同时抑制不太重要的元素。
作者提出了一种高效的高维注意力(HD-Attention)机制来处理转移过程的计算。该模块扩展了原始注意力模块,接受由共享ConvLSTM((9))生成的6D张量 C∈RH×W×α×H×W×γC \in \mathbb{R}^{H \times W \times \alpha \times H \times W \times \gamma}C∈RH×W×α×H×W×γ 作为输入,并输出4D注意力张量 Ω^∈RH×W×H×W\hat{\Omega} \in \mathbb{R}^{H \times W \times H \times W}Ω^∈RH×W×H×W。
HD-Attention通过首先在时间维度上计算扩展张量的自注意力分数来分解每个城市区域的注意力计算。然后,它用分数对每个元素进行加权,并应用1D卷积以获得紧凑的4D张量。最后,将城市整体的紧凑表示与可学习参数矩阵相乘,以根据每个城市区域和处理阶数的特征微调结果。
其公式如下:
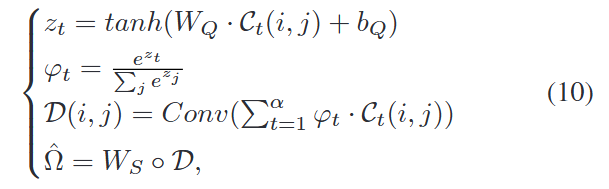
其中,WQW_QWQ 是权重,bQb_QbQ 是偏置,Ct(i,j)C_t(i, j)Ct(i,j) 是共享ConvLSTM输出的第t个隐藏状态。WSW_SWS 是用于调整不同阶数下不同城市区域转移程度的可学习参数。Conv是具有一个卷积滤波器的卷积操作,◦是Hadamard积(即元素级乘法)。Ct(i,j)C_t(i, j)Ct(i,j) 是一个3D张量(H, W, Filter),WQW_QWQ 和 WSW_SWS 分别有(H × W × Filter)和(H × W × H × W)个可学习参数。
通过HD-Attention,计算复杂度降低到与输入维度呈线性关系,这大大提高了效率,同时确保模型捕捉到序数依赖性。
对于下一小时内的每个转移阶数预测,我们构建了一个独立的HD-Attention分支来考虑它们之间的多样性。将输出定义为: {Ω^α+1,1,Ω^α+1,2,…,Ω^α+1,λ}\{\hat{\Omega}^{\alpha+1,1}, \hat{\Omega}^{\alpha+1,2}, \ldots, \hat{\Omega}^{\alpha+1,\lambda}\}{Ω^α+1,1,Ω^α+1,2,…,Ω^α+1,λ},然后可以通过最小化每个分支的预测误差之和来训练模型,如下所示:
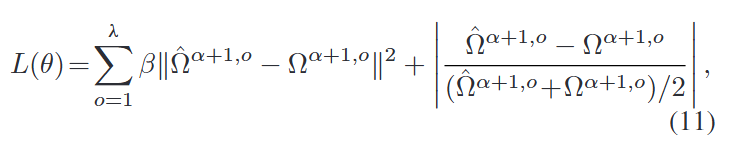
其中θ是DTP-Net中所有可学习的参数。β是用于调整损失权重的超参数。损失函数由均方误差和平均绝对百分比误差组成,以避免训练被大值支配。


















 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









