







引言
随着大数据时代的到来,预测模型在金融、气象、能源等领域的重要性日益凸显。支持向量机回归(Support Vector Regression, SVR)作为一种基于统计学习理论的回归方法,因其在处理小样本、非线性及高维数据方面的优势,成为研究者们关注的焦点。本文将详细介绍SVR的基本原理,并通过实验验证其在不同数据集上的预测性能。
理论基础
支持向量机
支持向量机(Support Vector Machine, SVM)最初由Vapnik等人于1995年提出,主要用于分类问题。SVM的核心思想是在特征空间中寻找一个最优超平面,使得不同类别的样本点之间的间隔最大化。对于线性可分的情况,SVM的目标函数可以表示为:
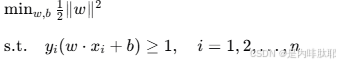
其中,w 和 b 分别为超平面的法向量和偏置项,xi 和 yi 分别为样本点及其标签。
支持向量机回归
支持向量机回归(SVR)是SVM在回归问题上的扩展。SVR的目标是在保证预测误差在一定范围内的情况下,寻找一个最优的回归函数。SVR引入了松弛变量 ξi 和 ξi∗ 来允许一定的预测误差,并通过引入一个容忍度 ϵ 来控制误差范围。SVR的目标函数可以表示为:
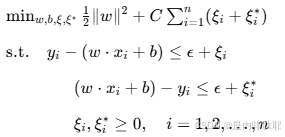
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









