




自己有一台14年的台式机 Nvidia 960显卡,最近不怎么玩游戏了,直接刷了Linux系统,如果后面需要详细的再开帖子,话不多说直接开搞
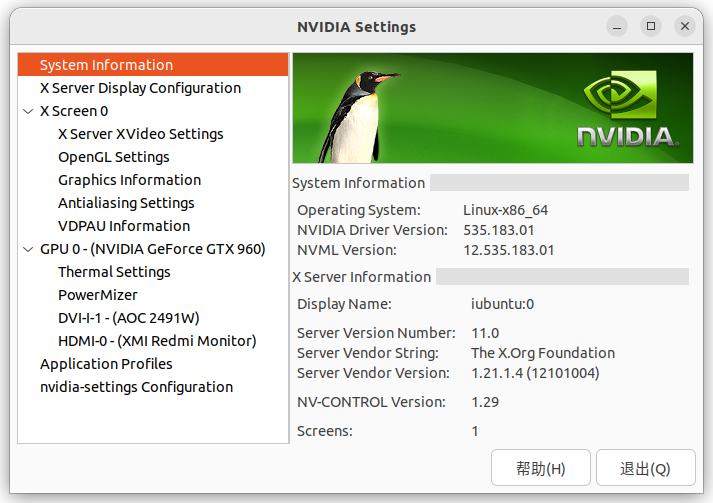
前面先讲下Ubuntu 中GCC 和 CUDA 的关系
编译主机代码:当你编写 CUDA 应用程序时,通常会包含一部分只能在 CPU 上执行的代码(主机代码)。这部分代码可以使用 GCC 编译。而另一部分代码(设备代码),则设计为在 GPU 上执行。
CUDA 编译器 (nvcc):NVIDIA 的 CUDA 编译器
nvcc可以与 GCC 协同工作。当你编译一个 CUDA 应用程序时,nvcc负责处理 CUDA 特定的部分,然后将非 CUDA 部分的代码传递给 GCC 进行编译。这意味着,在你的开发环境中,正确配置 GCC 是确保 CUDA 应用程序成功编译的关键之一。版本兼容性:需要注意的是,
nvcc对 GCC 的版本有一定的兼容性要求。不同的 CUDA 版本可能只支持特定范围内的 GCC 版本。因此,在安装 CUDA Toolkit 之前,确认你的 GCC 版本是否与 CUDA 兼容是很重要的。总结来说,在 Ubuntu 系统中,GCC 和 CUDA 并不是直接竞争的关系,而是互补的。GCC 主要负责编译不能或不适合在 GPU 上执行的代码,而 CUDA 提供了对 GPU 计算的支持,通过
nvcc编译器来编译那些可以在 GPU 上高效运行的代码。两者结合使用,可以帮助开发者充分利用系统的硬件资源进行高效的计算。
正题
1.GCC 特定 需要 9版本 GCC就是所谓的c语言的一个工具包,例如在windows 中安装就需要安装vs C++
gcc --version # 应显示GCC 9.5.0
g++ --version # 应显示G++ 9.5.0如果不是的话卸载,以下为gcc12为代表
sudo apt-get remove --purge gcc-12 g++-12
sudo apt-get autoremove注意安装旧版本的需要添加旧版工具链仓库
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt update安装gcc9
sudo apt install gcc-9 g++-9设置gcc 9为默认版本
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 90 --slave /usr/bin/g++ g++ /usr/bin/g++-9
sudo update-alternatives --config gcc再次验证下是不是正常安装
gcc --version # 应显示GCC 9.x
g++ --version # 应显示G++ 9.x2.CUDA 甩官网Cuda 链接 CUDA Toolkit 11.1.0 | NVIDIA Developer
安装cuda 这里选择的是 11.1版本
不要安装9的版本,不要安装9的版本,不要安装9的版本
如何选显卡驱动?参考如下
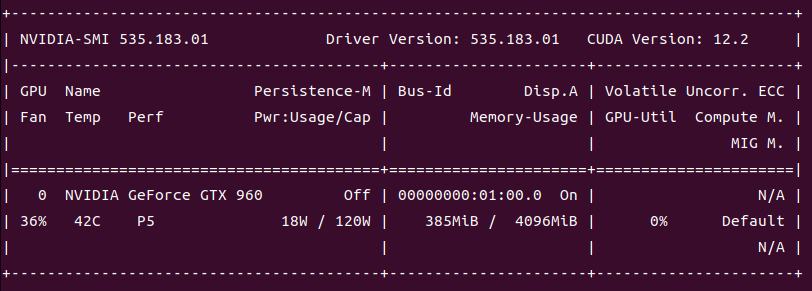
如何下载? 不用下载
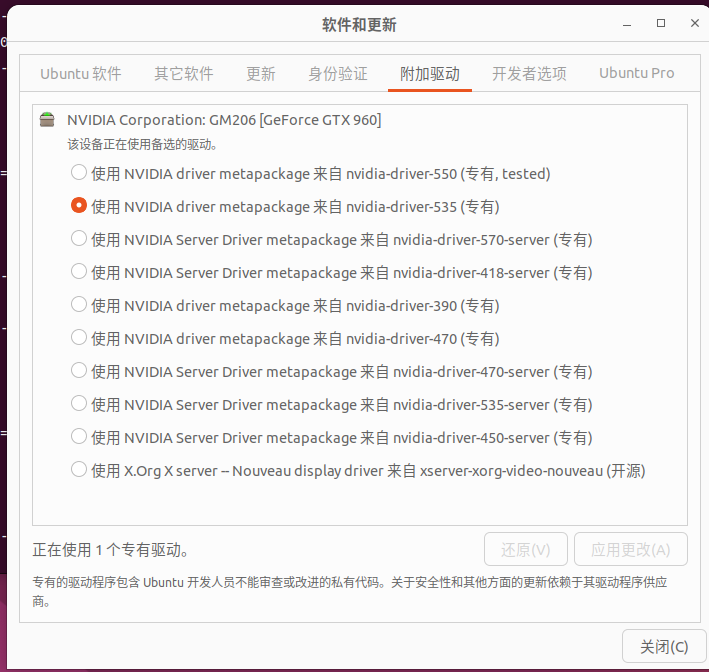
直接是ubuntu 专有版 选择535 然后进行应用更改 之后重启就可以拉!!!
之后安装 cudnn cuDNN Archive | NVIDIA Developer
选择自己的版本就可拉
最后一步 安装OLLAMA
funcir@iubuntu:~$ curl -fsSL https://ollama.com/install.sh | sh
#下面是运行结果
>>> Installing ollama to /usr/local
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> NVIDIA GPU installed.
晒一个 跑Qwen3 4B的内存 管够~
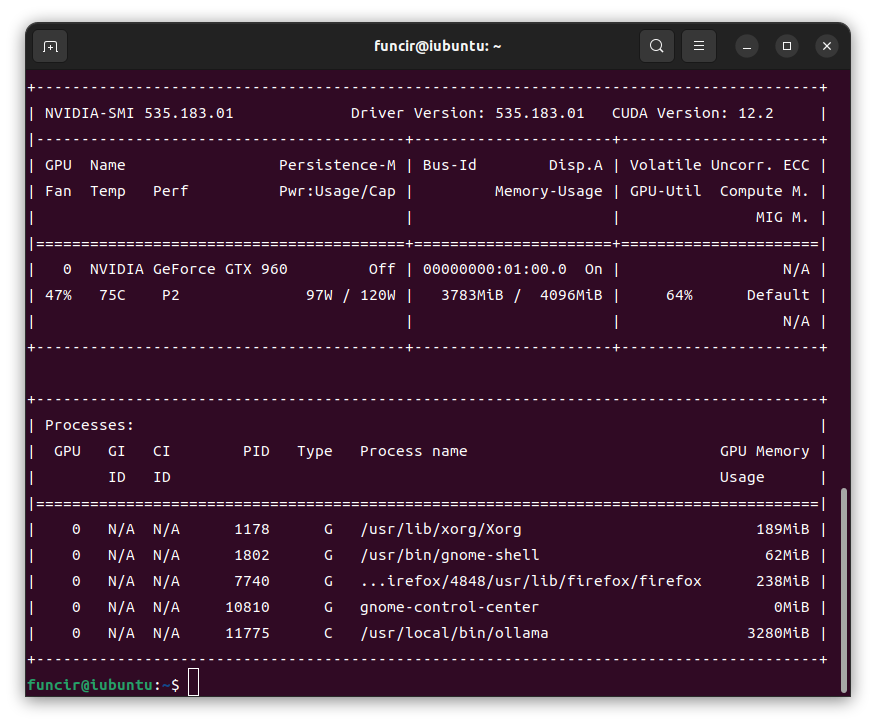
自动实行sh的会生成 /etc/systemd/system/ollama.service 而通过tar 安装的不会生成
详细设置看上期 本地离线部署ubuntu,自己配置OLLAMA.SERVICE 服务-优快云博客


















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









