



内容介绍:
数学建模竞赛 模型蒸馏 CoT推理链 DeepSeek-R1 轻量化部署
本文记录2025年高等数学推理轻量化竞赛完整解题流程,涵盖数据清洗策略、教师模型知识蒸馏、LoRA微调实战与多维度模型评估,提供可复现的轻量化数学推理解决方案。
优秀的训练集是蒸馏小模型的最好方法,那么我们拿到的数据集,数据质量参差不齐,就需要对数据集进行清洗,减少噪声,具体代码如下
清洗代码
import json
import re
INPUT_FILE = "数学赛题训练集.jsonl"
OUTPUT_FILE = "数学赛题训练集_cleaned.jsonl"
def normalize_text(text: str) -> str:
# 修正全角标点、空格与引号
text = text.replace('(', '(').replace(')', ')')
text = text.replace(',', ',').replace(':', ':')
text = text.replace('。', '.').replace('!', '!').replace('?', '?')
text = text.replace(';', ';').replace('“', '"').replace('”', '"')
text = text.replace('\n', " ").replace('’', "'")
# 合并多个空格
text = re.sub(r'\s+', ' ', text).strip()
return text
def is_valid_entry(entry: dict) -> bool:
# 必须包含 id, input, output 三个字段且非空
if not all(k in entry and entry[k].strip() for k in ("id", "input", "output")):
return False
return True
def clean_entry(entry: dict) -> dict:
entry["id"] = entry["id"].strip()
entry["input"] = normalize_text(entry["input"])
entry["output"] = normalize_text(entry["output"])
return entry
def main():
valid_count = 0
total = 0
with open(INPUT_FILE, 'r', encoding='utf-8') as fin, \
open(OUTPUT_FILE, 'w', encoding='utf-8') as fout:
for line in fin:
total += 1
line = line.strip()
if not line:
continue
try:
obj = json.loads(line)
except json.JSONDecodeError:
# 跳过无法解析的行
continue
if not is_valid_entry(obj):
# 跳过不符合规范的条目
continue
obj = clean_entry(obj)
fout.write(json.dumps(obj, ensure_ascii=False) + "\n")
valid_count += 1
print(f"共处理条目: {total},保留有效条目: {valid_count}")
if __name__ == "__main__":
main()
按照id 进行排序 代码,可忽略
import json
import os
def sort_jsonl_by_id(input_file, output_file):
"""
读取JSONL文件,按照id排序,并写入新的JSONL文件
参数:
input_file -- 输入的JSONL文件路径
output_file -- 输出的JSONL文件路径
"""
print(f"正在处理文件: {input_file}")
# 读取JSONL文件
data = []
with open(input_file, 'r', encoding='utf-8') as f:
for line in f:
try:
item = json.loads(line.strip())
data.append(item)
except json.JSONDecodeError as e:
print(f"解析JSON时出错: {e}")
print(f"问题行: {line}")
continue
print(f"读取了 {len(data)} 条记录")
# 按id排序
try:
# 尝试按照数字id排序
data.sort(key=lambda x: int(x['id']))
print("按数字id排序成功")
except (KeyError, ValueError, TypeError):
try:
# 如果失败,尝试按照字符串id排序
data.sort(key=lambda x: str(x.get('id', '')))
print("按字符串id排序成功")
except (KeyError, TypeError) as e:
print(f"排序时出错: {e}")
print("数据样例:", data[0] if data else "无数据")
return False
# 写入排序后的数据
with open(output_file, 'w', encoding='utf-8') as f:
for item in data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"排序完成,已写入文件: {output_file}")
return True
def process_all_jsonl_files():
"""处理当前目录下所有的JSONL文件"""
# 获取当前目录下所有的JSONL文件
jsonl_files = [f for f in os.listdir('.') if f.endswith('.jsonl')]
print(f"找到 {len(jsonl_files)} 个JSONL文件")
for file in jsonl_files:
# 生成输出文件名
base_name = os.path.splitext(file)[0]
output_file = f"{base_name}_sorted.jsonl"
# 处理文件
success = sort_jsonl_by_id(file, output_file)
if success:
print(f"成功处理文件: {file} -> {output_file}")
else:
print(f"处理文件失败: {file}")
def process_specific_files(file_list):
"""处理指定的JSONL文件列表"""
for file in file_list:
if not os.path.exists(file):
print(f"文件不存在: {file}")
continue
# 生成输出文件名
base_name = os.path.splitext(file)[0]
output_file = f"{base_name}_sorted.jsonl"
# 处理文件
success = sort_jsonl_by_id(file, output_file)
if success:
print(f"成功处理文件: {file} -> {output_file}")
else:
print(f"处理文件失败: {file}")
if __name__ == "__main__":
# 指定要处理的文件
files_to_process = [
"数学赛题训练集_cleaned.jsonl"
]
print("开始按ID排序JSONL文件...")
process_specific_files(files_to_process)
print("处理完成!")
数据集优化
噪声解决之后,我们要对文章进行
利用API接口优化数据集,由于平台的训练太慢了,所以智能通过自己的API进行代码优化。
import os
import json
import requests
from tqdm import tqdm
# 配置DeepSeek API
API_KEY = os.getenv('DEEPSEEK_API_KEY', 'sk-fb9dce1a8b5e3c7ad0312af') #key已作废
API_URL = "https://api.deepseek.com/v1/"
MODEL_NAME = "deepseek-r1"
# 上下文长度限制(按token计算)
MAX_CONTEXT_LENGTH = 3000
# 分割长文本的函数
def split_long_text(text, max_length):
"""
将长文本分割为不超过max_length的片段
"""
words = text.split()
segments = []
current_segment = []
current_length = 0
for word in words:
if current_length + len(word) + 1 > max_length:
segments.append(" ".join(current_segment))
current_segment = []
current_length = 0
current_segment.append(word)
current_length += len(word) + 1
if current_segment:
segments.append(" ".join(current_segment))
return segments
# 调用DeepSeek API生成CoT推理
def generate_cot_response(prompt):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": MODEL_NAME,
"messages": [
{"role": "system", "content": "你是一个数学问题解决专家,请给出详细的推理过程(CoT格式)。"},
{"role": "user", "content": prompt}
],
"temperature": 0.3
}
try:
response = requests.post(API_URL, json=payload, headers=headers, timeout=120)
response.raise_for_status()
return response.json()["choices"][0]["message"]["content"]
except Exception as e:
print(f"API调用失败: {str(e)}")
return None
# 主处理函数
def process_dataset(input_path, output_path):
"""
处理JSONL数据集并生成CoT格式输出
"""
with open(input_path, 'r', encoding='utf-8') as infile, \
open(output_path, 'w', encoding='utf-8') as outfile:
for line in tqdm(infile, desc="处理进度"):
try:
data = json.loads(line)
question_id = data["id"]
question_text = data["input"]
# 处理长上下文
if len(question_text) > MAX_CONTEXT_LENGTH:
segments = split_long_text(question_text, MAX_CONTEXT_LENGTH)
full_response = ""
for segment in segments:
response = generate_cot_response(segment)
if response:
full_response += response + "\n\n"
else:
full_response = generate_cot_response(question_text)
if full_response:
result = {
"id": question_id,
"input": question_text,
"output": full_response.strip()
}
outfile.write(json.dumps(result, ensure_ascii=False) + '\n')
except Exception as e:
print(f"处理ID {data.get('id', 'unknown')} 时出错: {str(e)}")
if __name__ == "__main__":
INPUT_PATH = r"d:\Datawhale/数学赛题训练集_cleaned_sorted.jsonl"
OUTPUT_PATH = r"d:\Datawhale/数学赛题训练集_cot_output.jsonl"
# 检查API密钥
if API_KEY == "":
print("请先在代码中设置您的DeepSeek API密钥")
else:
process_dataset(INPUT_PATH, OUTPUT_PATH)
print(f"处理完成! 结果已保存至: {OUTPUT_PATH}")
那么我们得到的数据就一定是好的吗?
不一定 ,我们还需要对所有的结果进行验证,这样我们导入Kimi 2 只对结果进行验证,来确保训练集中所有的结果都是对的 ,相当于找了一个外教。
数据训练蒸馏
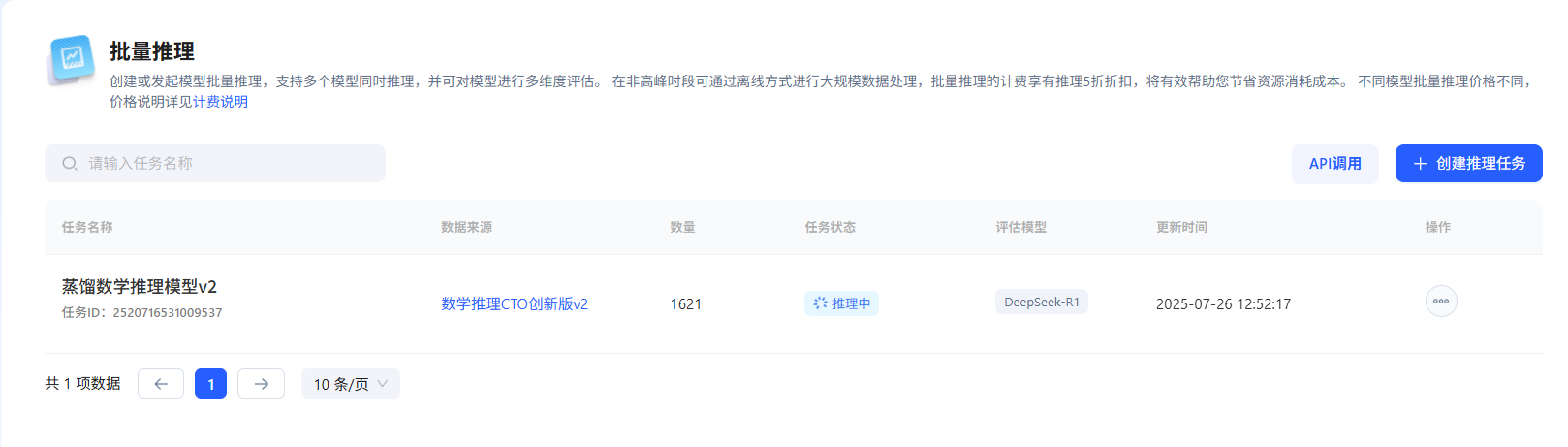
最后就在平台上传好我们处理的文档 然后进行模型蒸馏微调吧!
模型推理的有点慢 等待他生成之后再更新吧~

















 1827
1827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









