



10分钟带你解读 DeepSeek-OCR:突破性视觉压缩技术 及项目实战
模型概述
10月20日,DeepSeek正式开源DeepSeek-OCR模型,并同步发布发布相关运行脚本、测试代码、DeepEncoder源码以及技术报告等全套资料。
在技术实践层面,它是目前开源社区中少数具备端到端文档解析、语义理解与结构化生成能力的轻量级多模态模型,参数量仅约 3B,却能在 A100 单卡上实现高达 2500 tokens/s 的推理速度,极大降低了企业和研究者在多模态 RAG 系统中的部署门槛。
总的来说,作为 OCR 2.0 时代的典型代表模型,DeepSeek-OCR 不仅继承了传统OCR的文本识别能力,更在“文档理解”层面进行了全方位升级。它融合了视觉语言模型(VLM)的多模态感知能力,能够同时“看懂文字”“理解布局”“分析图表”,真正实现了从“看见文字”到“理解内容”的跨越。具体而言,DeepSeek-OCR 模型可实现以下几大核心功能:
-
OCR纯文字提取:
支持对任意图像进行自由式文字识别(Free OCR),快速提取图片中的全部文本信息,不依赖版面结构,适合截图、票据、合同片段等轻量场景的快速文本获取。 -
保留版面格式的OCR提取:
模型可自动识别并重建文档中的排版结构,包括段落、标题、页眉页脚、列表与多栏布局,实现“结构化文字输出”。此功能可直接将扫描文档还原为可编辑的排版文本,方便二次编辑与归档。 -
图表 & 表格解析:
DeepSeek-OCR 不仅识别文本,还能解析图像中的结构化信息,如表格、流程图、建筑平面图等,自动识别单元格边界、字段对齐关系及数据对应结构,支持生成可机读的表格或文本描述。 -
图片信息描述:
借助其多模态理解能力,模型能够对整张图片进行语义级分析与详细描述,生成自然语言总结,适用于视觉报告生成、科研论文图像理解以及复杂视觉场景说明。 -
指定元素位置锁定:
支持通过“视觉定位”(Grounding)功能,在图像中准确定位特定目标元素。例如,输入“Locate signature in the image”,模型即可返回签名区域的坐标,实现基于语义的图像检索与目标检测。 -
Markdown文档转化:
可将完整的文档图像直接转换为结构化 Markdown 文本,自动识别标题层级、段落结构、表格与列表格式,是实现文档数字化、知识库构建和多模态RAG场景的重要基础模块。 -
目标检测(Object Detection)
在多模态扩展任务中,DeepSeek-OCR 还能够识别并定位图片中的多个物体。通过输入如下提示词,模型会为每个目标生成带标签的边界框(bounding boxes),从而实现精准的视觉识别与标注。





而在理论层面,DeepSeek-OCR 首次系统性提出了 “上下文光学压缩(Contexts Optical Compression)” 概念,通过视觉语义压缩与语言上下文推理的协同机制,在保持识别精度的同时显著减少视觉 token 数量,实现了视觉理解与语言生成的高效耦合;在实践层面,模型实现了从图像、表格、公式到整篇 PDF 的全模态结构化解析,可直接输出 Markdown、LaTeX 或 JSON 格式,为构建多模态知识检索、企业级文档问答及科研报告分析系统提供了完整解决方案。
-
【权重】魔搭社区DeepSeek-OCR模型权重下载地址:https://www.modelscope.cn/models/deepseek-ai/DeepSeek-OCR/summary

-
【权重】HuggingFace DeepSeek-OCR模型权重下载地址https://huggingface.co/deepseek-ai/DeepSeek-OCR
-
【脚本】GitHub DeepSeek-OCR模型项目主页:https://github.com/deepseek-ai/DeepSeek-OCR
-
【论文】DeepSeek-OCR模型技术报告:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf

DeepSeek-OCR模型理论创新详解及快速上手
1. DeepSeek-OCR重大理论创新:视觉压缩一切
DeepSeek-OCR模型的核心理论创新在于对**“上下文光学压缩”(Contexts Optical Compression)**可行性的初步验证和深入探索。研究人员提出,通过利用视觉模态作为一种高效的压缩媒介来处理文本信息,可以潜在地解决当前大语言模型(LLMs)在处理极长文本内容时,由于序列长度导致的二次方计算复杂度挑战。DeepSeek-OCR是对此概念进行的初步研究,旨在探索通过光学二维映射来压缩长上下文的可行性。
1.1 上下文光学压缩的范式与机制
这种光学压缩范式改变了审视视觉-语言模型(VLMs)的角度,使其以LLM为中心,重点关注视觉编码器如何提高LLMs处理文本信息的效率,而不是传统的视觉问答任务。该理论的关键在于认识到:包含文档文本的单个图像能够使用明显少于等效数字文本所需的Token来表示丰富的信息。因此,通过视觉Token进行光学压缩,可以实现远高于直接处理文本Token的压缩比。
OCR任务(光学字符识别)被选作这一视觉-文本压缩范式的理想试验台。OCR任务在视觉表征和文本表征之间建立了一种自然的压缩-解压缩映射,从而能够提供定量的评估指标来验证理论。解码器(DeepSeek3B-MoE-A570M)的任务正是从DeepEncoder压缩后的潜在视觉Token中重建原始文本表征。
1.2 压缩能力及量化边界的验证
DeepSeek-OCR最重要的贡献之一是提供了对视觉-文本Token压缩比的全面定量分析。通过在Fox基准测试集上进行实验,研究证实了上下文光学压缩的强大能力和实际边界。结果显示:
- 高精度压缩: 当文本Token数量是视觉Token数量的10倍以内(即压缩比 < 10 × < 10\times <10×)时,DeepSeek-OCR的解码精度可以达到惊人的 KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: \mathbf{96%} 以上。
- 极限压缩性能: 即使压缩比高达 20 × \mathbf{20\times} 20×,OCR的准确率仍能保持在 KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: \mathbf{60%} 左右。
这些结果表明,紧凑的语言模型(如DeepSeek-OCR中的DeepSeek3B-MoE解码器)能够有效地学习解码高度压缩的视觉表征。这为LLMs处理长上下文的挑战提供了经验指导,也为VLM Token分配优化提供了参考。研究者推测,通过适当的预训练设计,更大规模的LLMs可以很容易地获得类似的能力。
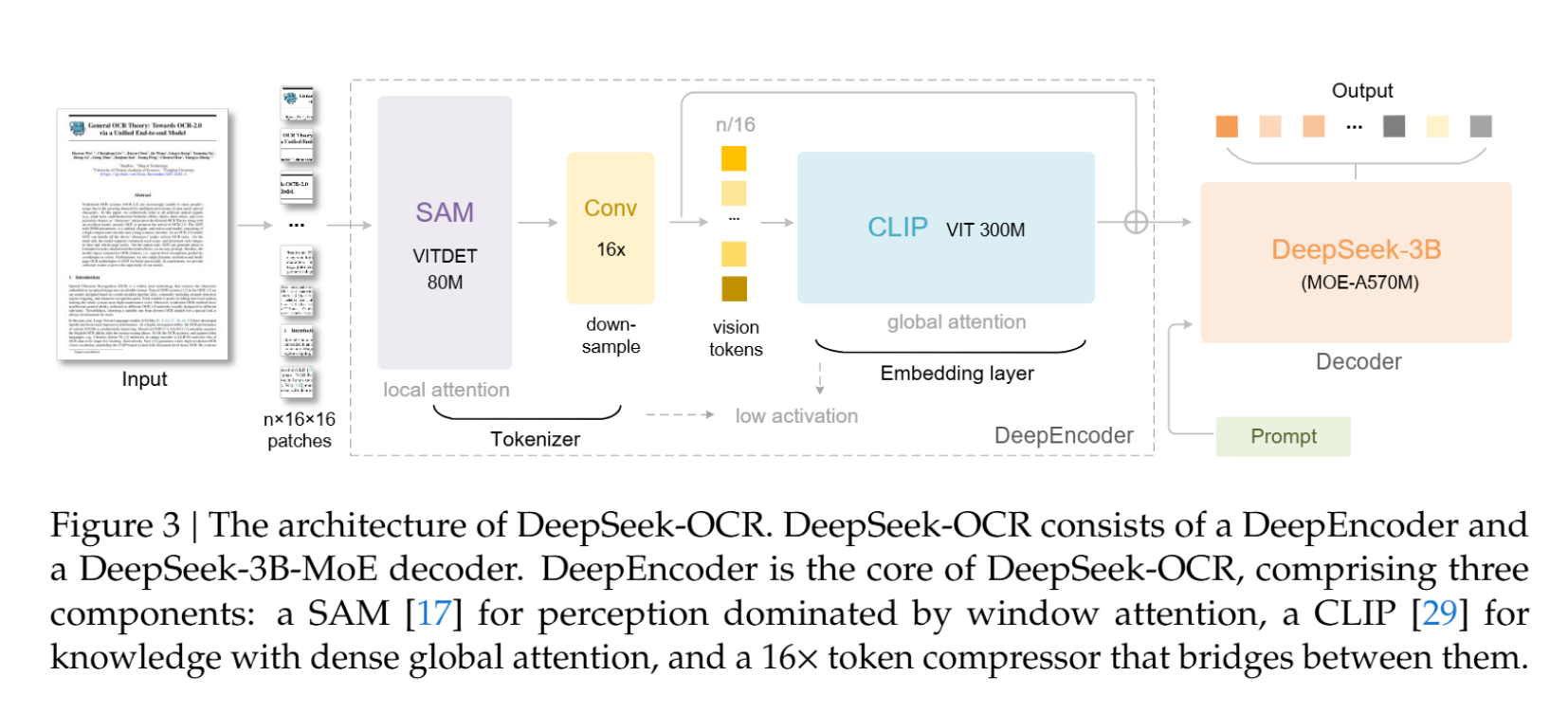
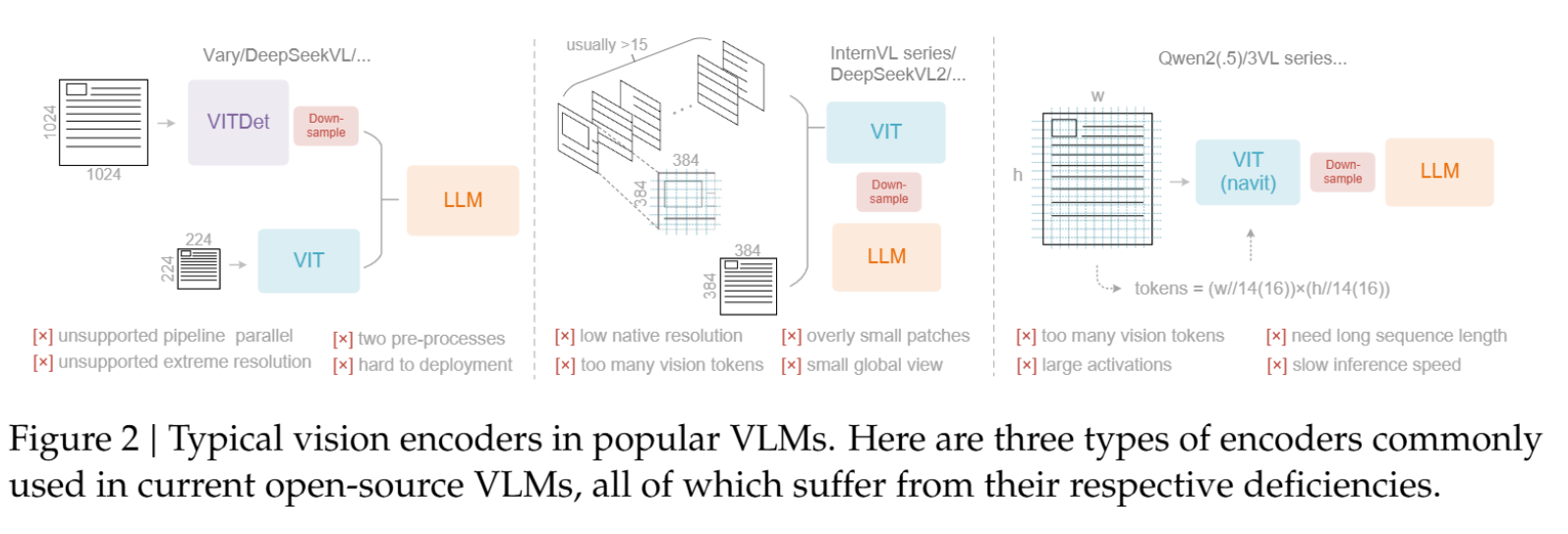
1.3 DeepEncoder:实现高效压缩的关键架构创新
为了在实践中实现高压缩比并保持可操作性,DeepSeek-OCR引入了DeepEncoder这一新颖架构。DeepEncoder的设计目标是:在处理高分辨率输入时,保持较低的激活内存;同时实现高压缩比,以保证视觉Token的数量处于最佳且可管理的范围。
DeepEncoder通过串联方式将窗口注意力组件和全局注意力组件连接起来。具体来说,它由三个核心部分构成:
- 视觉感知特征提取组件: 以窗口注意力为主导(基于SAM-base,80M参数)。
- 16 × 16\times 16× Token压缩器: 这是连接两个组件的桥梁,通过一个2层的卷积模块执行 16 × 16\times 16× 的Token降采样。
- 视觉知识特征提取组件: 具有密集全局注意力(基于CLIP-large,300M参数)。
这种设计解决了现有VLM编码器在处理高分辨率图像时遇到的诸多挑战(如激活内存过大、Token数量过多等)。例如,对于 1024 × 1024 1024\times 1024 1024×1024 的输入图像,DeepEncoder最初会分割出 4096 4096 4096 个Token。由于前半部分采用窗口注意力且参数量适中,激活内存可接受。在进入全局注意力组件之前,Token通过 16 × 16\times 16× 压缩模块减少到 256 256 256 个,从而有效地控制了总体的激活内存并实现了关键的Token压缩。

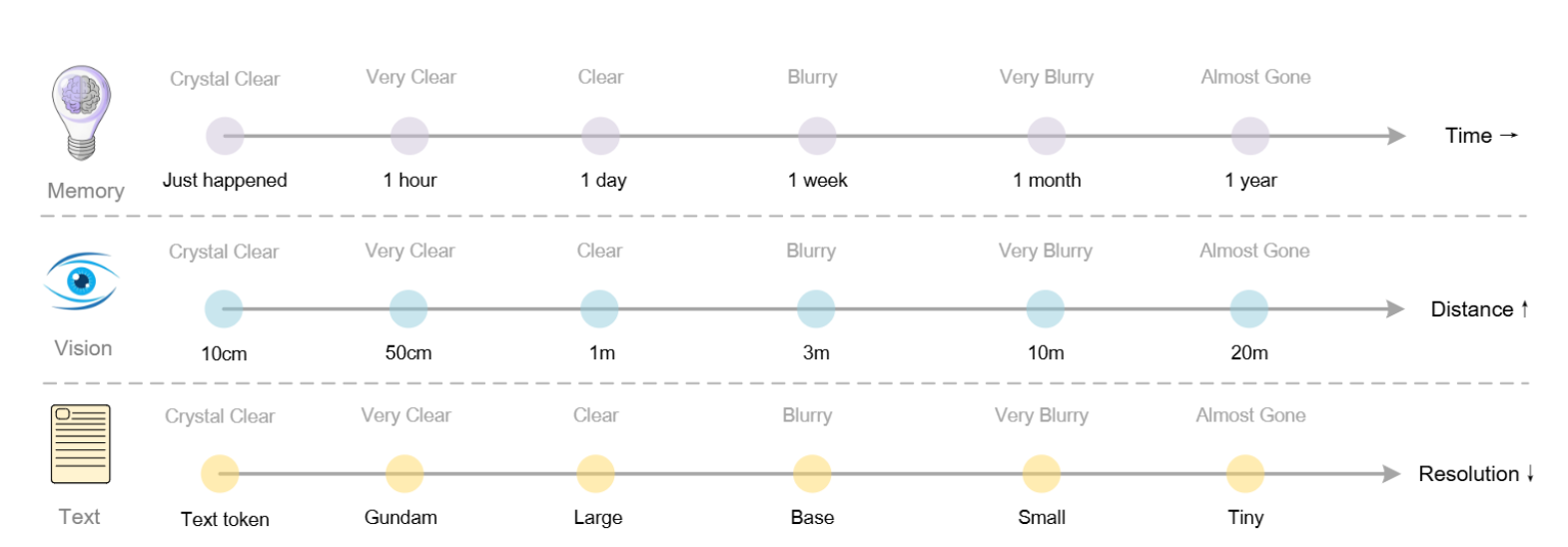
1.4 对LLM长上下文与记忆机制的启发
上下文光学压缩的理论框架还为LLMs的记忆遗忘机制研究开辟了新方向。该方法提出了一种模拟人类记忆衰退的机制:
- 多级压缩: 可以将较旧的历史对话文本渲染成图像进行光学压缩。
- 渐进式遗忘: 通过渐进式地缩小这些渲染图像的尺寸,可以进一步减少Token消耗。
- 记忆衰退模拟: 这种视觉感知随空间距离(或时间)的退化模式 模拟了生物学上的遗忘曲线:近期信息保持高保真度,而遥远的记忆则通过增加压缩比(Token数量减少和文本变得模糊)而自然淡化。
这种方法暗示了构建理论上无限上下文架构的可能性,在保留信息和计算约束之间取得了平衡。DeepSeek-OCR通过OCR任务对上下文光学压缩的验证,为解决超长上下文处理和大规模文本处理的计算效率问题提供了极具前景的新方向。
2. DeepSeek-OCR本地部署与环境搭建
说明:DeepSeek-OCR 目前不提供在线 API,需本地推理。单卡≥7 GB 显存可运行;NVIDIA 50 系(如 RTX 5090)暂不适配 vLLM(主要是当前 PyTorch/vLLM 对 sm_120 架构支持不完善)。DeepSeek-OCR支持两条推理路径:vLLM(高吞吐、流式友好)与 HuggingFace Transformers(依赖少、兼容面广)。
加入 赋范空间 免费领取对应课件网盘及更多持续更新 多模态、Agent、RAG、模型微调等教程
2.1 模型权重下载
可从 Hugging Face 或 魔搭社区(ModelScope) 获取。以下以 ModelScope 为例:
pip install modelscope
mkdir ./deepseek-ocr
modelscope download --model deepseek-ai/DeepSeek-OCR --local_dir ./deepseek-ocr
下载完成后完整的项目文件如图所示:
也可以在课件网盘中进行下载。
加入 赋范空间 免费领取对应课件网盘及更多持续更新 多模态、Agent、RAG、模型微调等教程
2.2 运行环境搭建
基础运行环境建议:
- OS:Ubuntu 20.04+/22.04
- Python:3.10–3.12(推荐 3.10/3.11)
- CUDA:11.8 或 12.1/12.2(与显卡驱动匹配)
- PyTorch:与 CUDA 匹配的预编译版本
- GPU:≥7 GB(大图/多页 PDF 建议 16–24 GB)
下载GitHub项目包:
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
也可以直接在可见网盘中下载安装包,并上传解压
然后创建一个虚拟环境来安装模型运行的相关依赖,
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
接下来继续安装Jupyter及响应的kernel:
conda install jupyterlab
conda install ipykernel
python -m ipykernel install --user --name dsocr --display-name "Python (dsocr)"
然后在虚拟环境中先安装pytorch相关组件:
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
然后再安装vLLM,这是一个企业级高并发的大模型推理加速框架,同时也是DeepSeek-OCR官方推荐使用的框架。不过安装需要注意,由于基础依赖的不同,我们需要安装指定版本的vLLM才能运行DeepSeek-OCR模型。
这里我们需要在网盘中下载特定版本的vLLM预编译的二进制安装包:
将其上传到服务器中,然后进入到对应文件夹中,输入pip install命令来进行安装。
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
接下来让我们进入到GitHub项目主目录,输入pip install来安装项目基础依赖,
cd ./DeepSeek-OCR/
pip install -r requirements.txt
其中项目脚本的基础依赖包括:
transformers==4.46.3
tokenizers==0.20.3
PyMuPDF
img2pdf
einops
easydict
addict
Pillow
numpy
这些依赖的作用如下:
| 库名 | 主要功能说明 |
|---|---|
| transformers==4.46.3 | Hugging Face 的核心库,用于加载、推理和微调 DeepSeek-OCR 模型(支持 trust_remote_code=True 的自定义架构)。 |
| tokenizers==0.20.3 | 高性能分词器,配合 transformers 对文本进行编码/解码,确保多模态指令(如 <image>、`< |
| PyMuPDF | PDF 文件解析库(也叫 fitz),用于将 PDF 页面渲染为高分辨率图像,供 OCR 模型识别。 |
| img2pdf | 将图像序列(如逐页渲染的 PDF 页面)重新封装为 PDF 输出,用于生成带识别框或布局信息的结果文件。 |
| einops | 高维张量重排工具,方便在视觉特征映射与融合(如 ViT token 重组)中进行维度变换。 |
| easydict | 用于将配置项(如 cfg.xxx)以字典形式轻松访问,提升配置文件的可读性与灵活性。 |
| addict | 类似 easydict 的配置工具,支持更灵活的动态属性调用方式,用于管理模型与处理器参数。 |
| Pillow | 图像处理基础库(PIL 的现代版本),负责读取、转换、裁剪及保存图片。 |
| numpy | 数值计算与数组操作基础库,支持图像像素矩阵运算、坐标映射及特征张量构建等底层操作。 |
需要注意的是,安装过程如果出现了如图所示的依赖冲突,无视即可,不会影响实际运行。
最后,还需要安装flash-attn加速库。
pip install flash-attn==2.7.3 --no-build-isolation
至此,基础环境搭建全部完成。
3. DeepSeek-OCR模型transformers调用流程
-
准备工作
创建4个文件夹,分别用于存储输入和输出的PDF、Images等文件。
3.1 借助transformers库进行推理
-
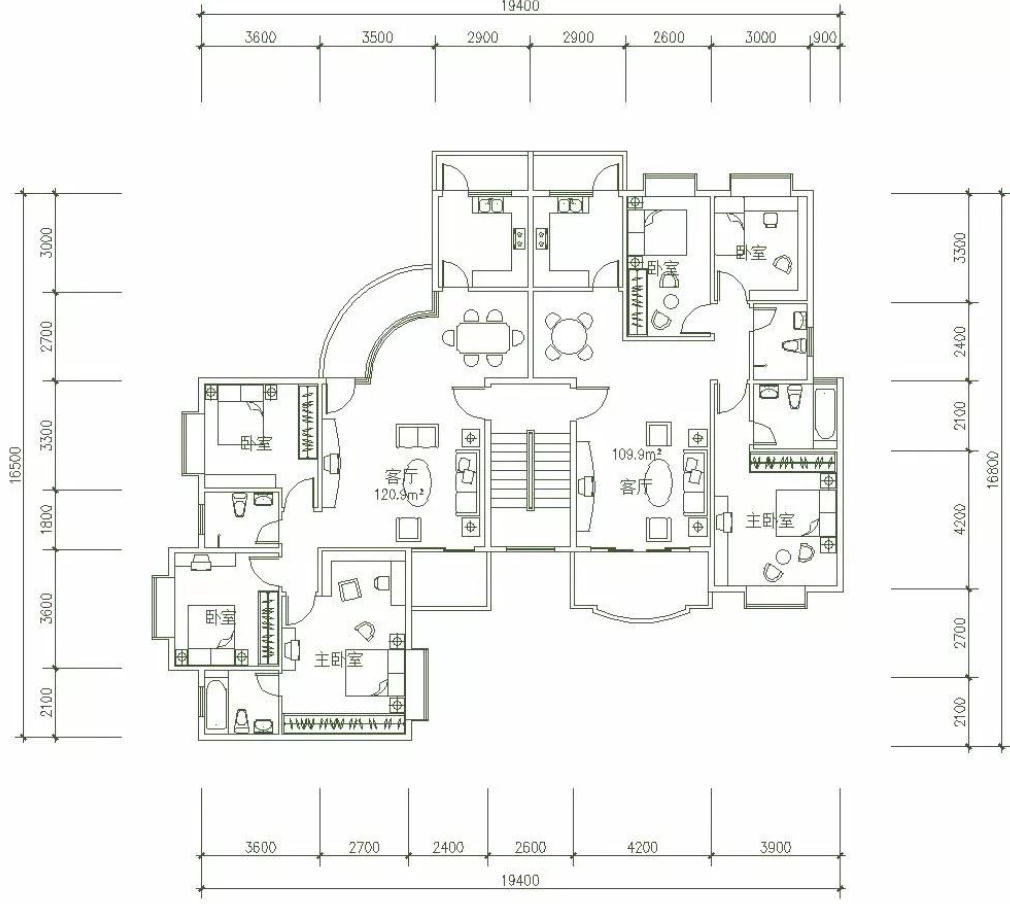
上传CAD图纸
将一张房屋户型图上传至image_input文件夹中,便于之后进行识别。
找 赋范空间 领取对应课件及更多持续更新 多模态、Agent、RAG、模型微调等教程
大家可以在网盘课件中领取:
然后打开Juptyer,选择对应的环境:
然后运行如下代码,借助transformers库进行模型调用,需要注意的是需要替换路径,包括输入输出文件路径和大模型权重的路径等,
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
prompt = "<image>\nDescribe this image in detail."
image_file = '/root/autodl-tmp/image_input/测试图片.png'
output_path = '/root/autodl-tmp/image_output'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
代码解释如下:
- 导入依赖与环境配置
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
AutoTokenizer:用于加载 DeepSeek-OCR 的自定义分词器(模型有自己的特殊 token,如<image>、<|grounding|>)。AutoModel:用于加载主模型(DeepSeek-OCR 内部定义了自己的架构,因此需要trust_remote_code=True)。CUDA_VISIBLE_DEVICES='0':指定使用第 0 块 GPU(单卡推理)。
- 加载模型与分词器
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True
)
model_name指定了模型来源(这里是 Hugging Face 上的deepseek-ai/DeepSeek-OCR)。trust_remote_code=True表示允许加载自定义的 Python 类(DeepSeek 自定义了DeepseekOCRForCausalLM架构)。_attn_implementation='flash_attention_2'启用 Flash Attention 2,显著加快大规模自注意力运算速度并节省显存。use_safetensors=True启用更安全高效的权重加载方式(防止 Pickle 注入风险)。
- 模型精度与显卡模式设置
model = model.eval().cuda().to(torch.bfloat16)
.eval():切换模型为推理模式(禁用 dropout 等训练行为)。.cuda():将模型加载到 GPU 上。.to(torch.bfloat16):使用 bfloat16 精度,在 A100/H100 等新架构 GPU 上可显著节省显存、加快推理。
- 输入与输出路径配置
prompt = "<image>\nDescribe this image in detail."
image_file = '/root/autodl-tmp/image_input/测试图片.png'
output_path = '/root/autodl-tmp/image_output'
prompt:提示词模板,<image>表示将输入图片作为多模态输入;- 这里的提示词
"Describe this image in detail."是一种 通用图像理解任务; - 你也可以换成
"Convert the document to markdown."等来实现文档 OCR、结构化提取。
- 这里的提示词
image_file:指定输入图片路径。output_path:输出识别结果(包括文本和可视化标注)的保存目录。
- 执行推理
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
test_compress=True
)
这一行是整个推理的核心。
| 参数 | 含义 | 作用说明 |
|---|---|---|
tokenizer | 模型的分词器 | 将文字提示词转成 token |
prompt | 输入提示词 | 指定任务类型(OCR、描述、解析等) |
image_file | 图片路径 | 模型会自动读取并编码图像 |
output_path | 输出目录 | 结果文件(Markdown / JSON / 可视化图片)保存位置 |
base_size=1024 | 输入图像基础尺寸 | 控制视觉特征提取的基准分辨率 |
image_size=640 | 实际图像输入尺寸 | 影响推理精度与速度 |
crop_mode=True | 图像裁剪模式 | 若图片较大,会自动分块识别(节省显存) |
save_results=True | 是否保存识别结果 | 输出识别的 Markdown 文件与框选图像 |
test_compress=True | 启用上下文光学压缩 (Contexts Optical Compression) | 减少视觉 token,提升推理速度和效率 |
返回的 res 通常是一个字典(dict),包含:
- 模型生成的完整文本输出;
- Markdown 或 LaTeX 格式结构化内容;
- 可选的调试信息(如 token 数、生成时间等)。
运行效果如下:
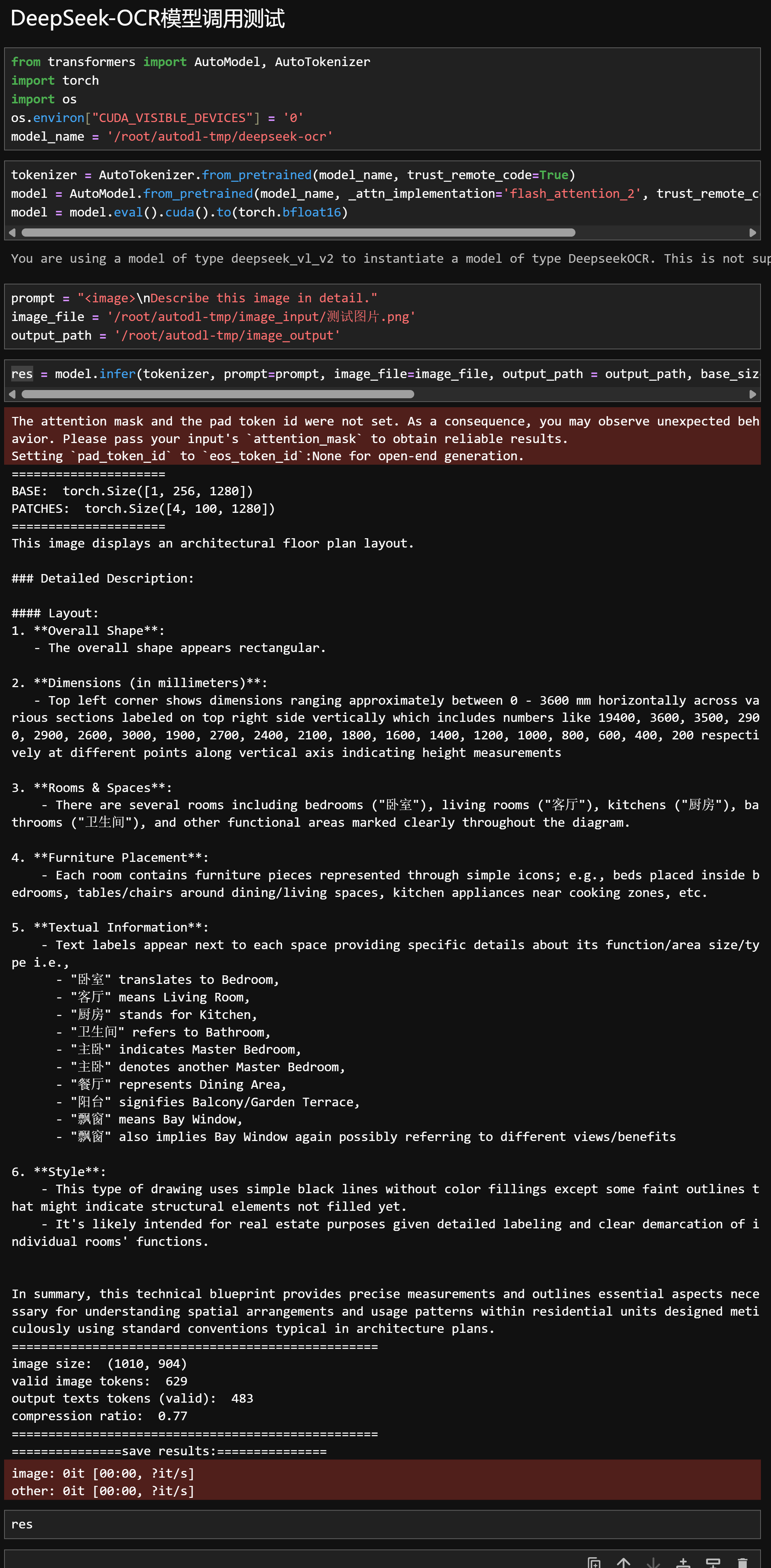
能够看出,响应速度非常快,基于CAD图纸的房屋信息描述非常准确。识别信息翻译为中文内容如下:
=====================
BASE: torch.Size([1, 256, 1280])
PATCHES: torch.Size([4, 100, 1280])
====================================
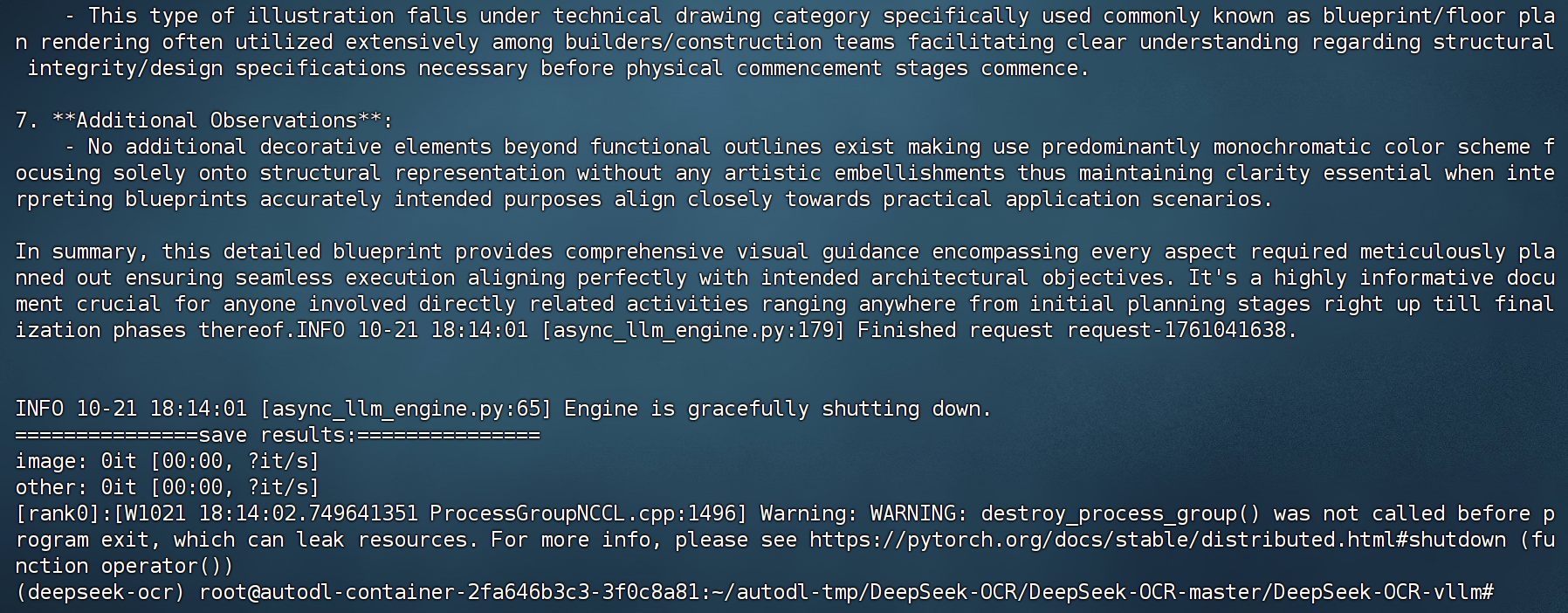
这张图片展示了一份建筑平面图布局。
### 详细描述:
#### 布局:
1. **整体形状**:
* 整体形状呈矩形。
2. **尺寸(以毫米为单位)**:
* 左上角显示的尺寸大约在 0 - 3600 mm 范围内,横向分布;右上方的垂直方向标注了多个区段的尺寸,如 19400、3600、3500、2900、2900、2600、3000、1900、2700、2400、2100、1800、1600、1400、1200、1000、800、600、400、200 等数值,对应垂直轴上的不同位置,表示高度测量。
3. **房间与空间**:
* 图中包含多个房间,包括卧室(“卧室”)、客厅(“客厅”)、厨房(“厨房”)、卫生间(“卫生间”)以及其他功能区域,这些都在图纸中清晰标注。
4. **家具布置**:
* 每个房间内都有简化的家具图标,例如卧室内摆放床,餐厅或客厅区域有桌椅,厨房区域则标注了烹饪用具等。
5. **文字信息**:
* 各空间旁边都有文字标签,注明其功能、面积或类型:
* “卧室”表示 Bedroom,
* “客厅”表示 Living Room,
* “厨房”表示 Kitchen,
* “卫生间”表示 Bathroom,
* “主卧”表示 Master Bedroom,
* “餐厅”表示 Dining Area,
* “阳台”表示 Balcony 或 Garden Terrace,
* “飘窗”表示 Bay Window(可能有多个位置,代表不同视角或功能)。
6. **风格**:
* 图纸整体采用简洁的黑线绘制,无色彩填充,只有部分淡色线条表示尚未填充的结构元素。
* 从标注的细节和清晰的功能分区来看,这类图纸很可能用于房地产展示或建筑设计方案说明。
# 综合来看,这份技术蓝图提供了精确的尺寸信息,勾勒出住宅单元内部的空间分布与使用模式,是理解建筑布局和结构关系的重要资料。
图片尺寸: (1010, 904)
有效图像 tokens 数量: 629
输出文本 tokens (有效): 483
压缩比: 0.77
=========
此外,运行完成后,还需要重点关注输出的结果”套件“:
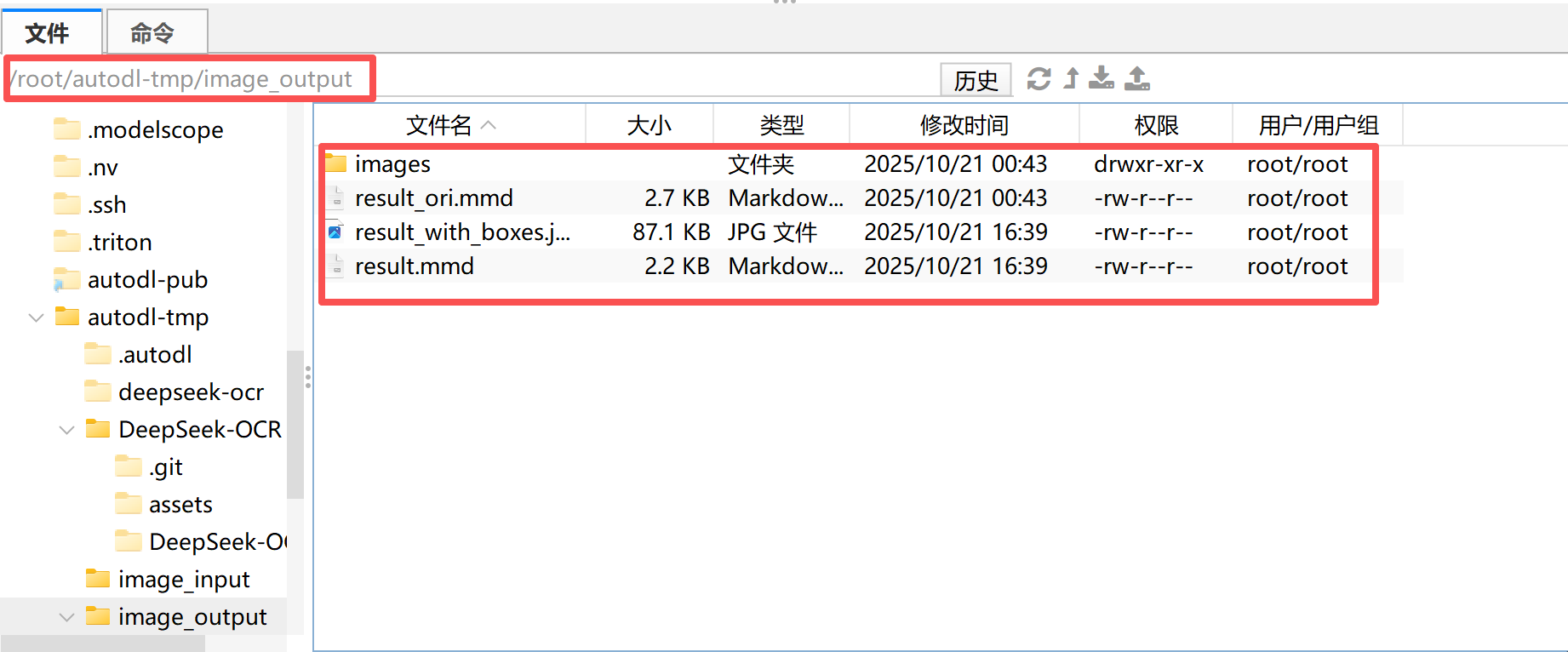
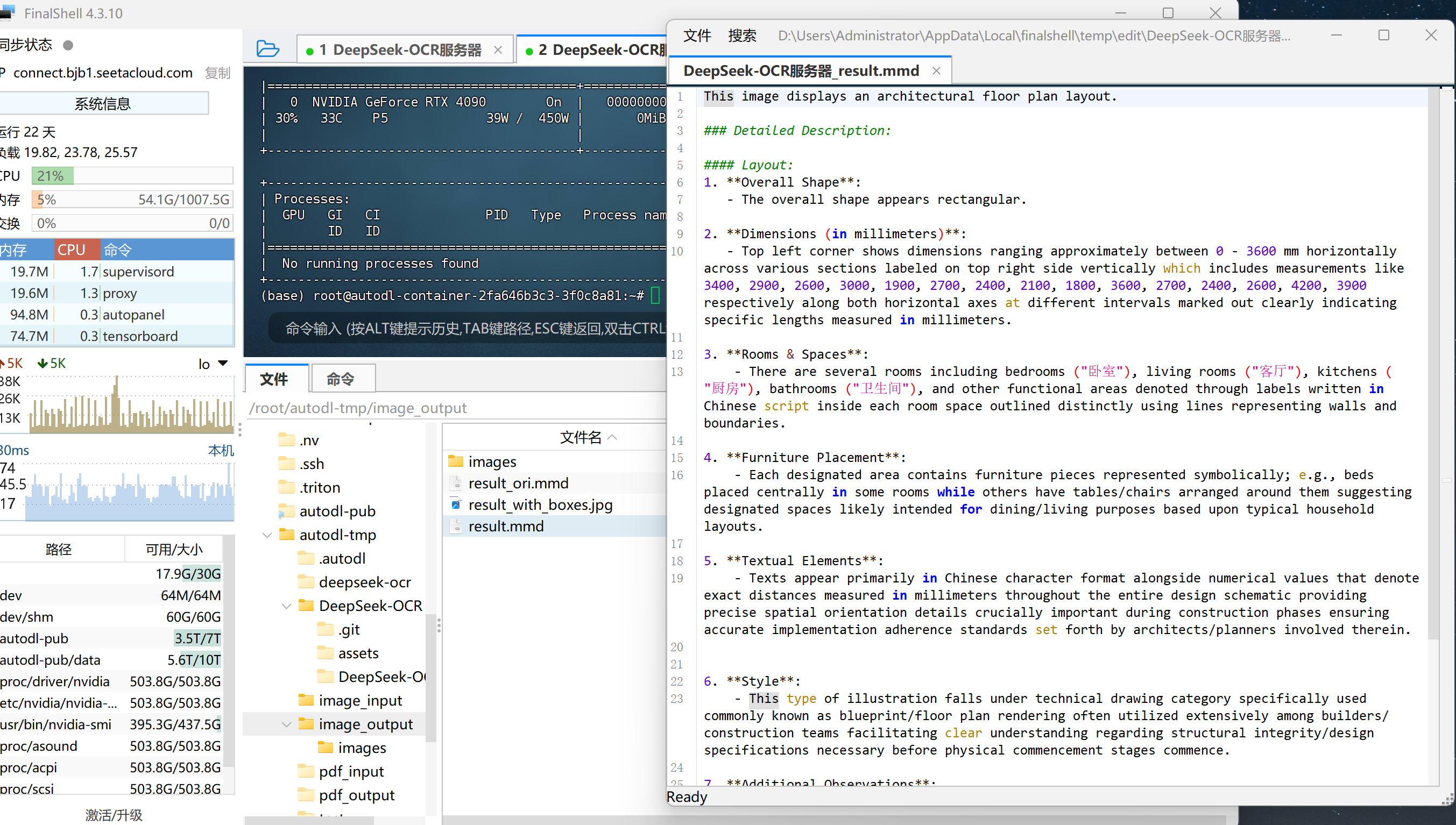
在模型执行完 OCR、图像解析或目标检测任务后,系统会自动生成一组标准化的输出文件。这组文件可以理解为 DeepSeek-OCR 的 结果输出套件(Result Bundle),其中包含不同任务维度下的可视化文件与文本描述文件。该输出套件通常由 四件主要内容 组成:
images/文件夹
该文件夹用于保存模型在多模态文档解析或目标检测任务中生成的中间图像文件:
- 当输入为 PDF 或长文档时,模型会将文档页面切分成图片并保存在此目录中;
- 当执行目标检测(Object Detection)或元素定位(Grounding)任务时,
images文件夹会保存模型生成的带标签与边界框的图片,例如自动标注出的“文字区域”、“表格区域”或“检测对象”。
这部分输出通常作为模型可视化结果的参考基础。
result_ori.mmd
该文件是模型最原始的文本输出结果文件,后缀 .mmd 表示 Markdown 格式的多模态文档(Multi-Modal Document)。
- 在该文件中,模型会完整记录识别出的文字内容、版面结构信息以及相应的图像引用标记;
- 文件内容未经过后处理,保留了模型的“第一轮”输出,因此非常适合用于调试或评估模型原始识别效果。
可以理解为:result_ori.mmd是模型最直接、未经清洗的识别文本文件。
result_with_boxes.jpg
该文件是用于可视化展示的最终图像结果。
- 在文档或图片中,模型会自动叠加检测框、识别标签以及分类标识;
- 对于 OCR 任务,这意味着每个文本块都会被矩形框标记;
- 对于图表或目标检测任务,则会在图像中标出每个识别到的对象类别(如人物、风筝、表格、签名等)。
该文件通常用于 人工校验模型效果 或 前端可视化展示。
result.mmd
这是模型生成的 最终处理版本 的文本结果文件。
- 它在
result_ori.mmd的基础上进行了结构化整理与格式修复; - 对输出的 Markdown 内容进行了语义清洗、层级归纳与格式对齐,使其更接近最终可读或可编辑的文档形式;
- 若任务是“Convert the document to markdown”,此文件通常就是最终可直接导入知识库或文本编辑器的成果文件。
也就是说,对于不同类型的任务,DeepSeek-OCR 模型会自动生成不同形式的输出结果:
- 如果是 OCR任务,重点输出识别文字与布局文件;
- 如果是 视觉定位任务,重点输出带标签和边界框的图片;
- 如果是 文档结构化任务,则会输出带 Markdown 层级的
.mmd文件。
通过这样的“输出套件”设计,开发者可以非常直观地对模型结果进行验证、评估与再利用,实现从“图片→结构化信息”的完整闭环。
4. DeepSeek-OCR模型的VLLM调用流程
当然,除了使用 transformers 库进行直接推理外,DeepSeek-OCR 模型还支持基于 vLLM 的高性能调用流程。vLLM 是目前主流的高吞吐推理引擎之一,能够显著提升多模态大模型的推理速度与显存利用率,尤其在处理长文档或多页 PDF 时优势明显。通过 vLLM 调用,DeepSeek-OCR 可以在流式(streaming)模式下快速生成 Markdown、图文描述或结构化输出,实现低延迟、高并发的推理体验。相比 transformers 方案,vLLM 更适合批量推理、在线服务化部署与大规模文档解析场景,是实际企业应用中更具工程化价值的调用方式。
需要注意的是,官方项目中提供了部分可以直接用于进行vLLM任务推理的脚本如下:
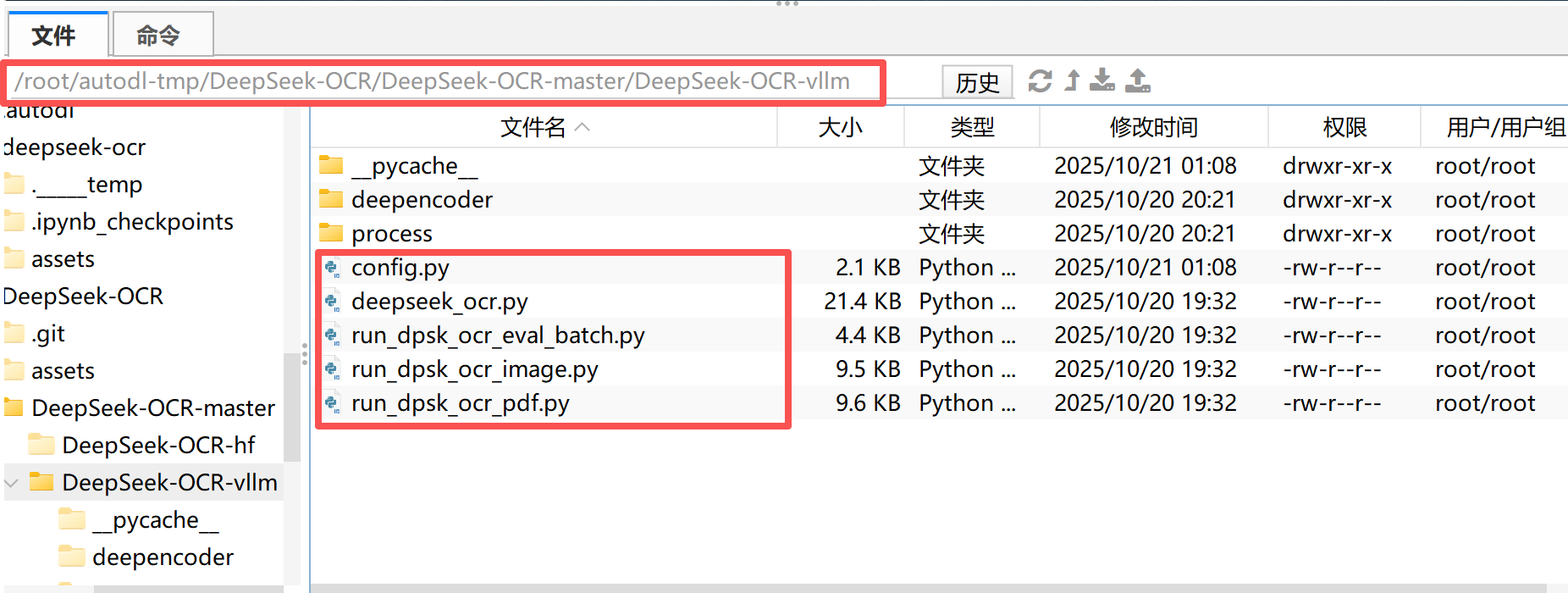
| 文件名 | 核心功能简介 |
|---|---|
| config.py | 管理模型参数与路径配置,如输入尺寸、显存设置、输出目录等。 |
| deepseek_ocr.py | DeepSeek-OCR 的核心推理逻辑,负责加载模型、执行识别并输出结果。 |
| run_dpsk_ocr_eval_batch.py | 批量评测脚本,用于对多张图片或数据集进行统一 OCR 测试。 |
| run_dpsk_ocr_image.py | 单张图片推理脚本,用于测试模型的图像识别与描述功能。 |
| run_dpsk_ocr_pdf.py | PDF 推理脚本,将多页 PDF 转图片后识别并输出 Markdown 结果。 |
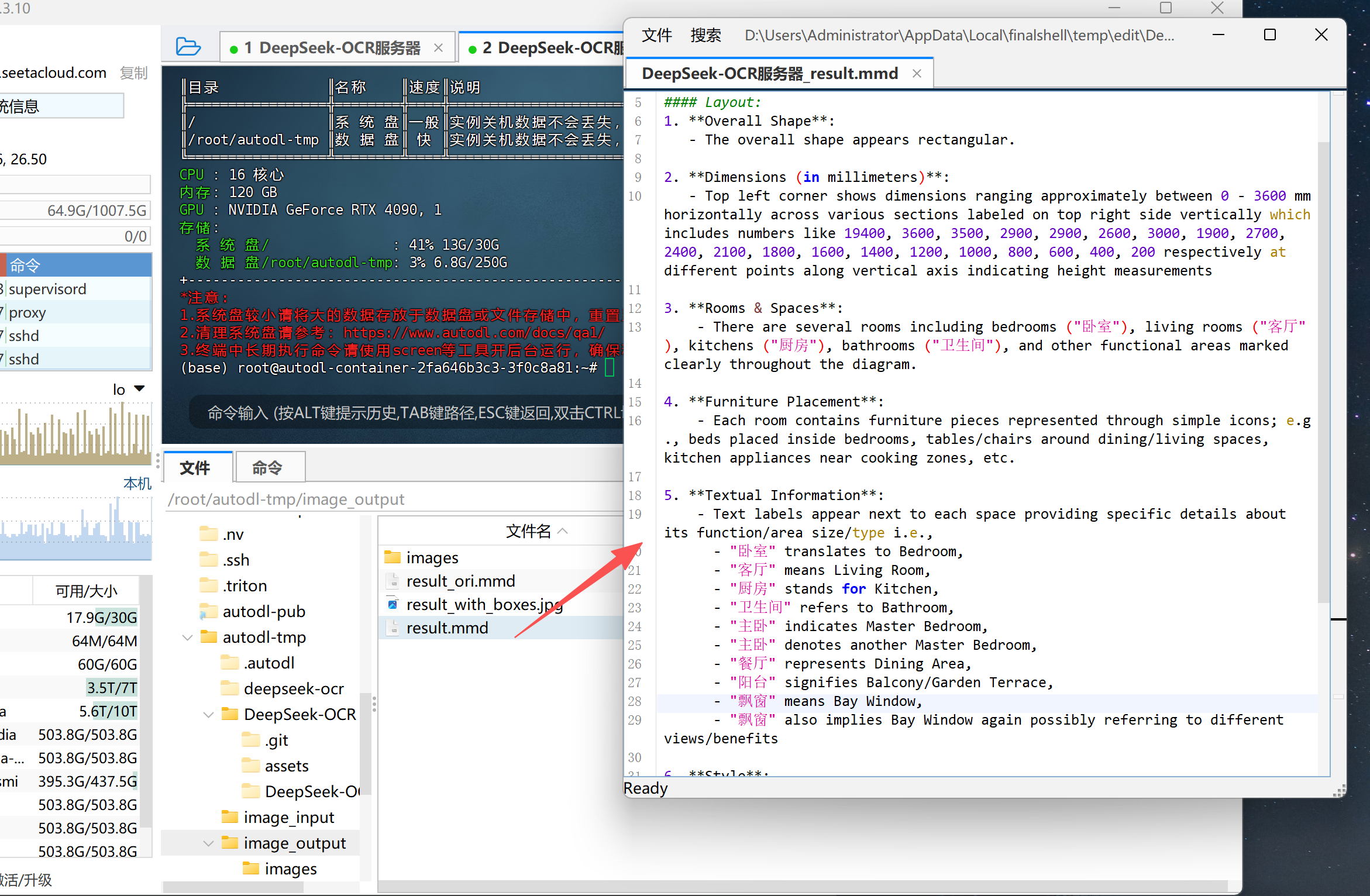
同样的,我们以CAD图纸识别为例进行vLLM调用流程的演示,具体流程如下
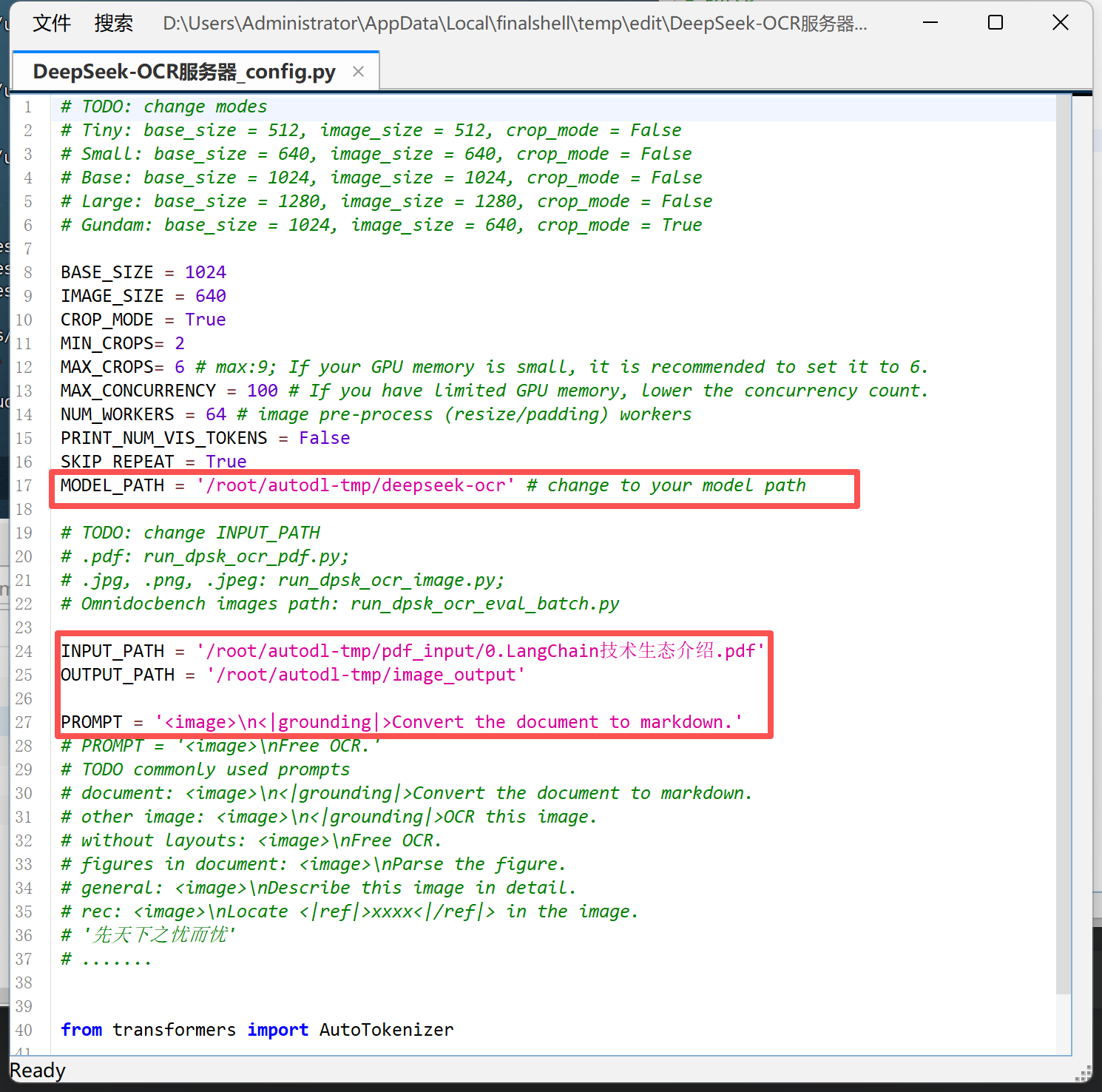
Step 1.上传CAD图纸到指定文件夹:将待识别的 CAD 图纸(支持 .jpg、.png、.pdf 等格式)放入项目根目录下的 input/ 文件夹中,确保文件路径与 config.py 中的 INPUT_PATH 对应。
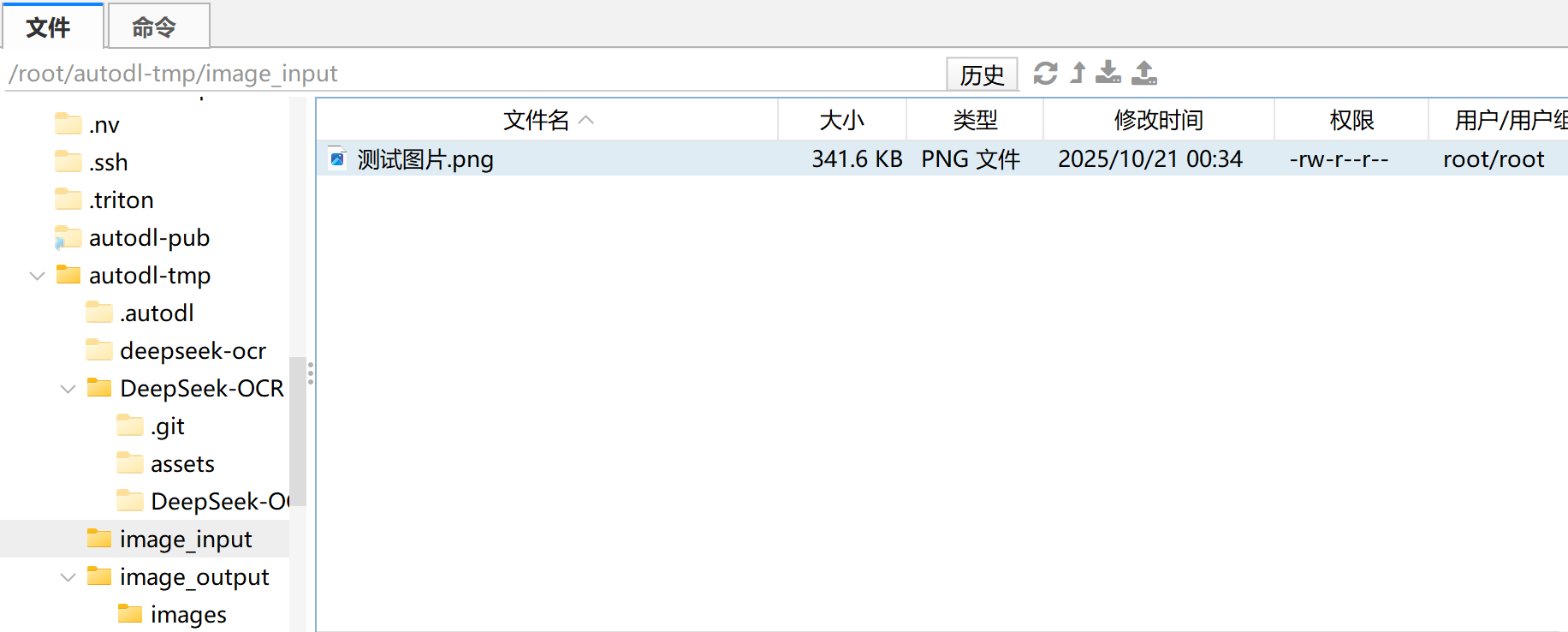
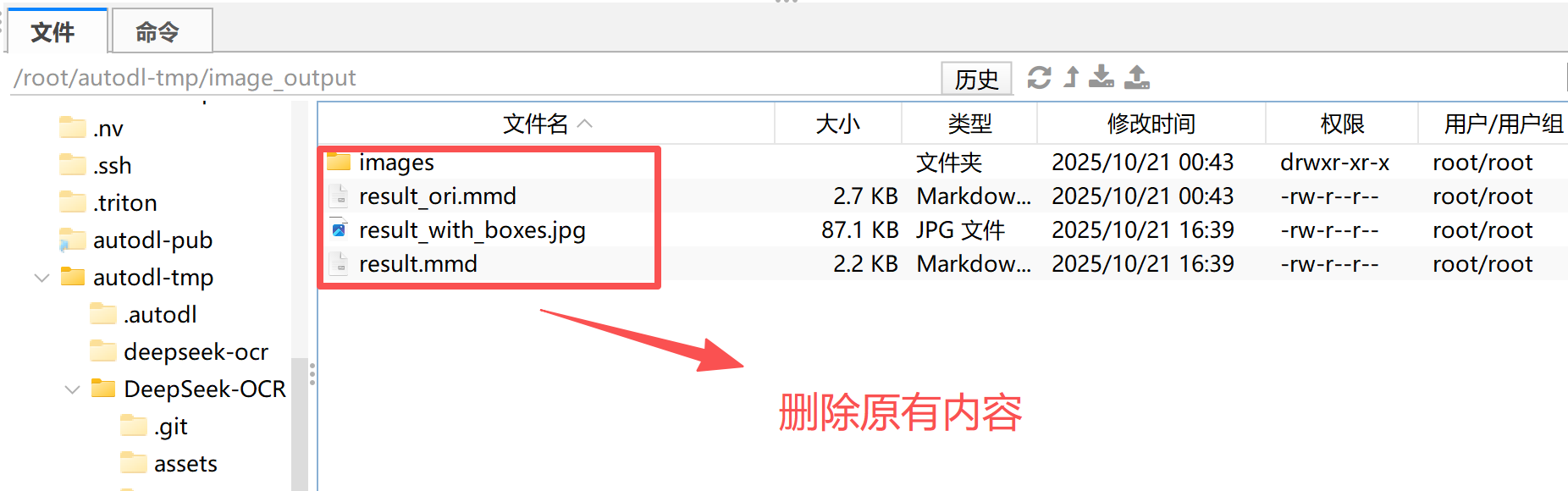
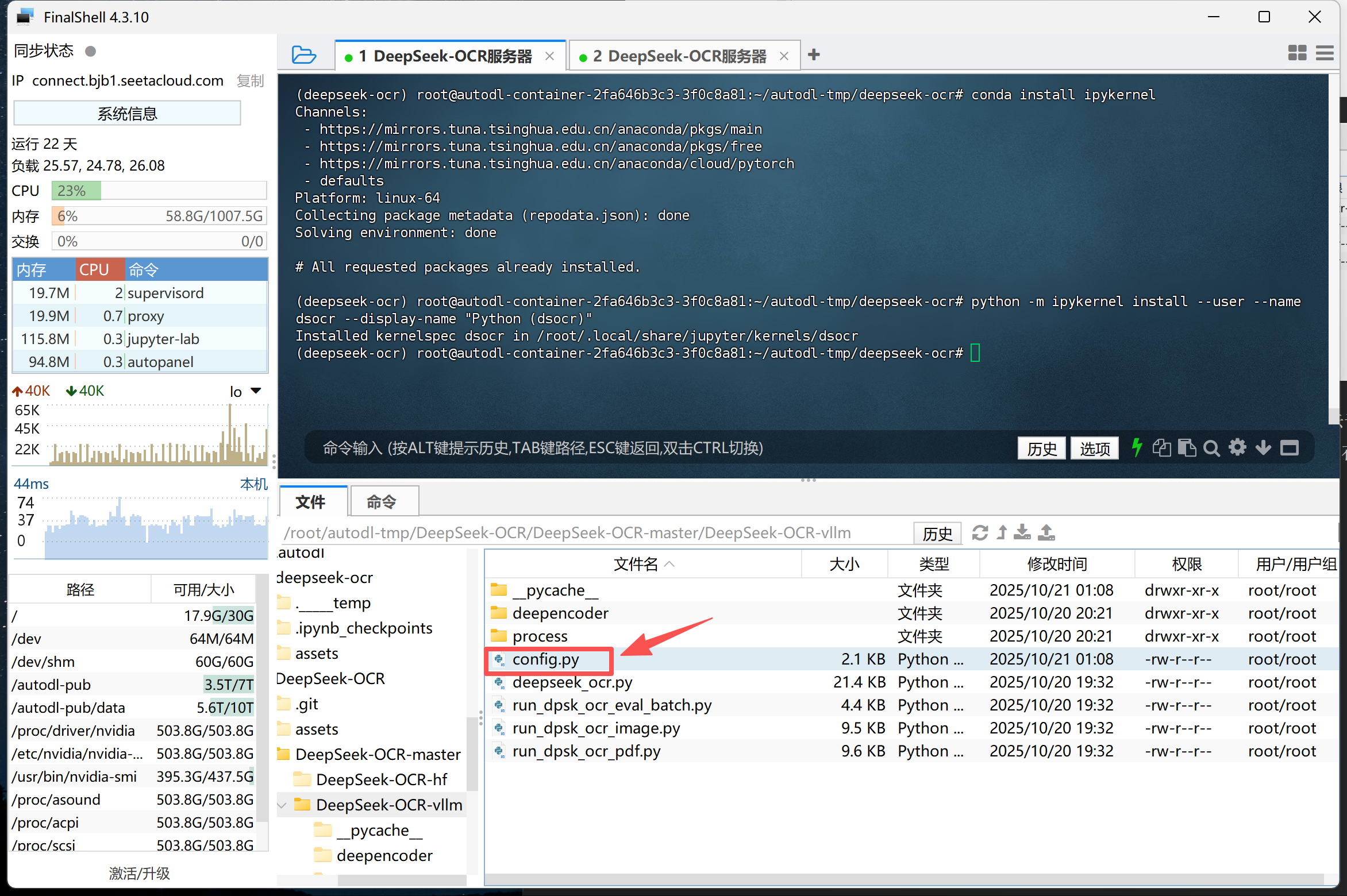
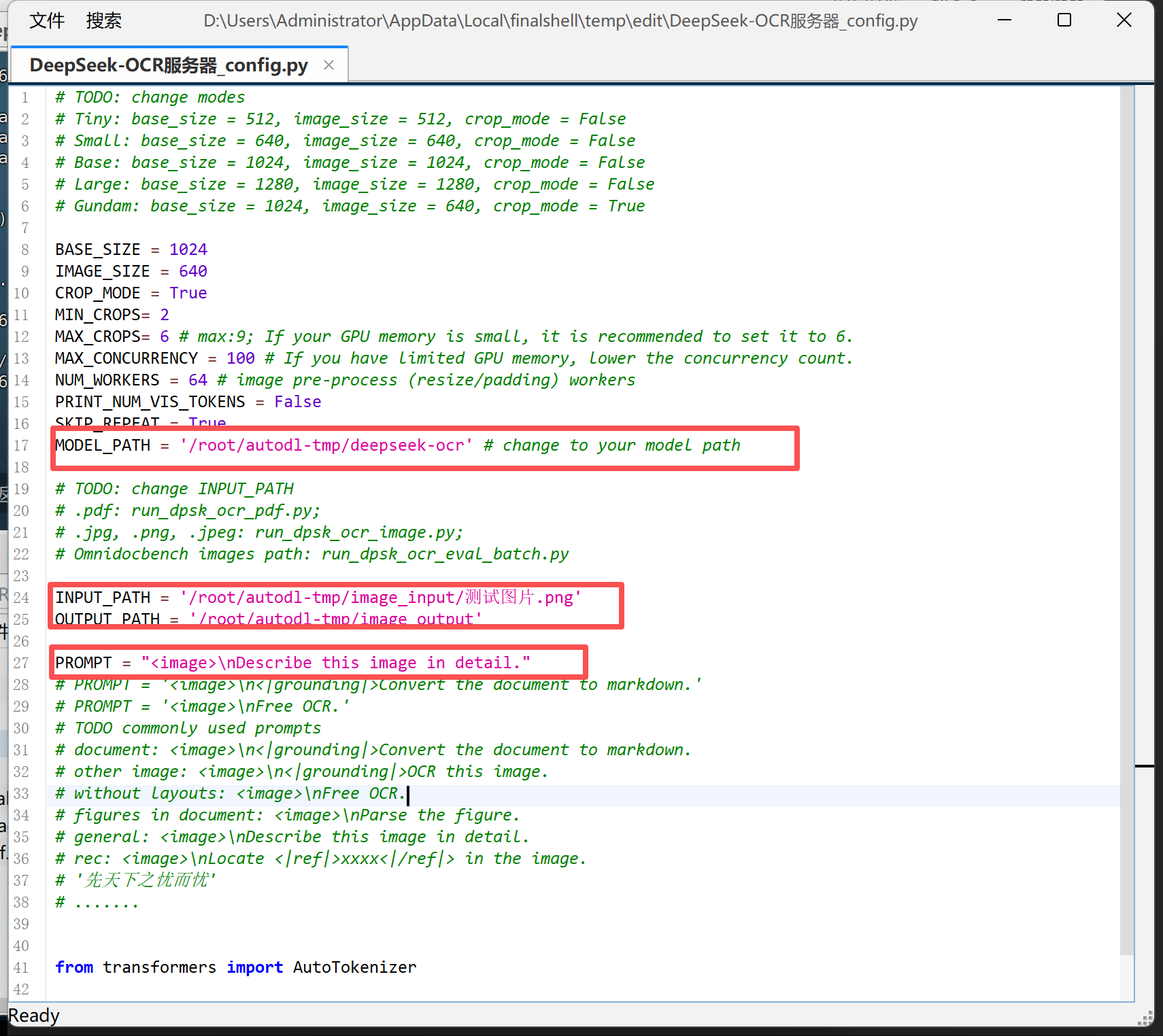
Step 2.修改config.py配置文件:在 config.py 中设置模型路径、输入输出目录及提示词(如 <image>\n<|grounding|>Describe this image in detail.)。同时可根据显卡显存调整 BASE_SIZE 与 IMAGE_SIZE 参数,以保证推理顺利运行。
Step 3.启动运行脚本:执行 python run_dpsk_ocr_image.py 或基于 vLLM 的版本脚本,即可启动推理进程。系统会自动加载模型,对CAD图纸进行内容识别与结构化解析。
cd /root/autodl-tmp/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm
python run_dpsk_ocr_image.py
Step 4.查看结果:识别结果会保存在 output/ 文件夹中,默认输出为 Markdown 格式文件。
可在文本编辑器或浏览器中查看完整的图纸识别与文字提取效果。
加入 赋范空间 免费领取对应课件网盘及更多持续更新 多模态、Agent、RAG、模型微调等教程
DeepSeek-OCR模型图片&PDF识别
接下来我们围绕DeepSeek-OCR模型的7个实际应用场景进行功能实现介绍,这些场景分别是:
-
OCR纯文字提取:
支持对任意图像进行自由式文字识别(Free OCR),快速提取图片中的全部文本信息,不依赖版面结构,适合截图、票据、合同片段等轻量场景的快速文本获取。 -
保留版面格式的OCR提取:
模型可自动识别并重建文档中的排版结构,包括段落、标题、页眉页脚、列表与多栏布局,实现“结构化文字输出”。此功能可直接将扫描文档还原为可编辑的排版文本,方便二次编辑与归档。 -
图表 & 表格解析:
DeepSeek-OCR 不仅识别文本,还能解析图像中的结构化信息,如表格、流程图、建筑平面图等,自动识别单元格边界、字段对齐关系及数据对应结构,支持生成可机读的表格或文本描述。 -
图片信息描述:
借助其多模态理解能力,模型能够对整张图片进行语义级分析与详细描述,生成自然语言总结,适用于视觉报告生成、科研论文图像理解以及复杂视觉场景说明。 -
指定元素位置锁定:
支持通过“视觉定位”(Grounding)功能,在图像中准确定位特定目标元素。例如,输入“Locate signature in the image”,模型即可返回签名区域的坐标,实现基于语义的图像检索与目标检测。 -
Markdown文档转化:
可将完整的文档图像直接转换为结构化 Markdown 文本,自动识别标题层级、段落结构、表格与列表格式,是实现文档数字化、知识库构建和多模态RAG场景的重要基础模块。 -
目标检测(Object Detection):
在多模态扩展任务中,DeepSeek-OCR 还能够识别并定位图片中的多个物体。通过输入如下提示词,模型会为每个目标生成带标签的边界框(bounding boxes),从而实现精准的视觉识别与标注。
1. 图表类图片识别与解析
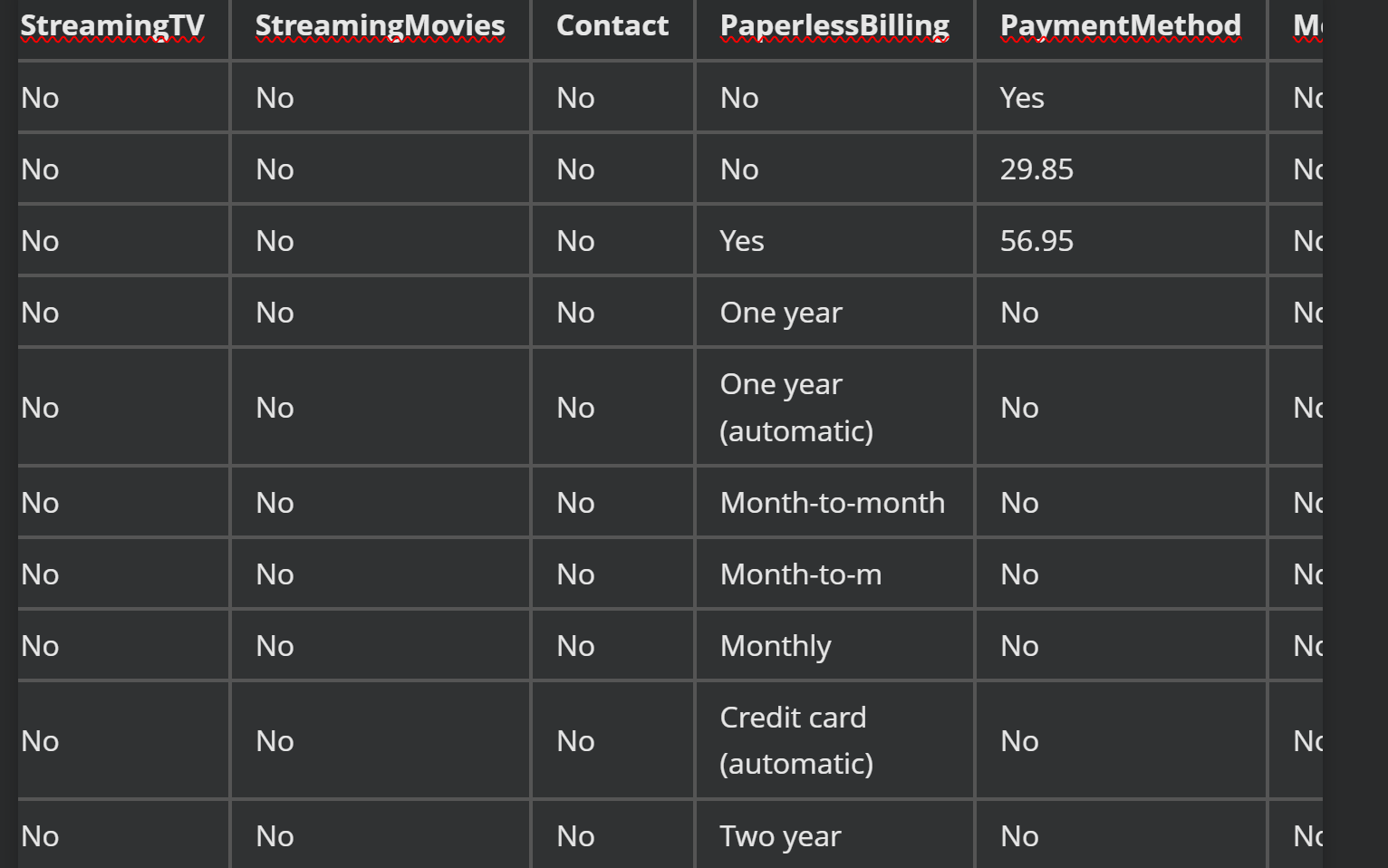
1.1 示例图片
图1:
图2:

1.2 识别过程
-
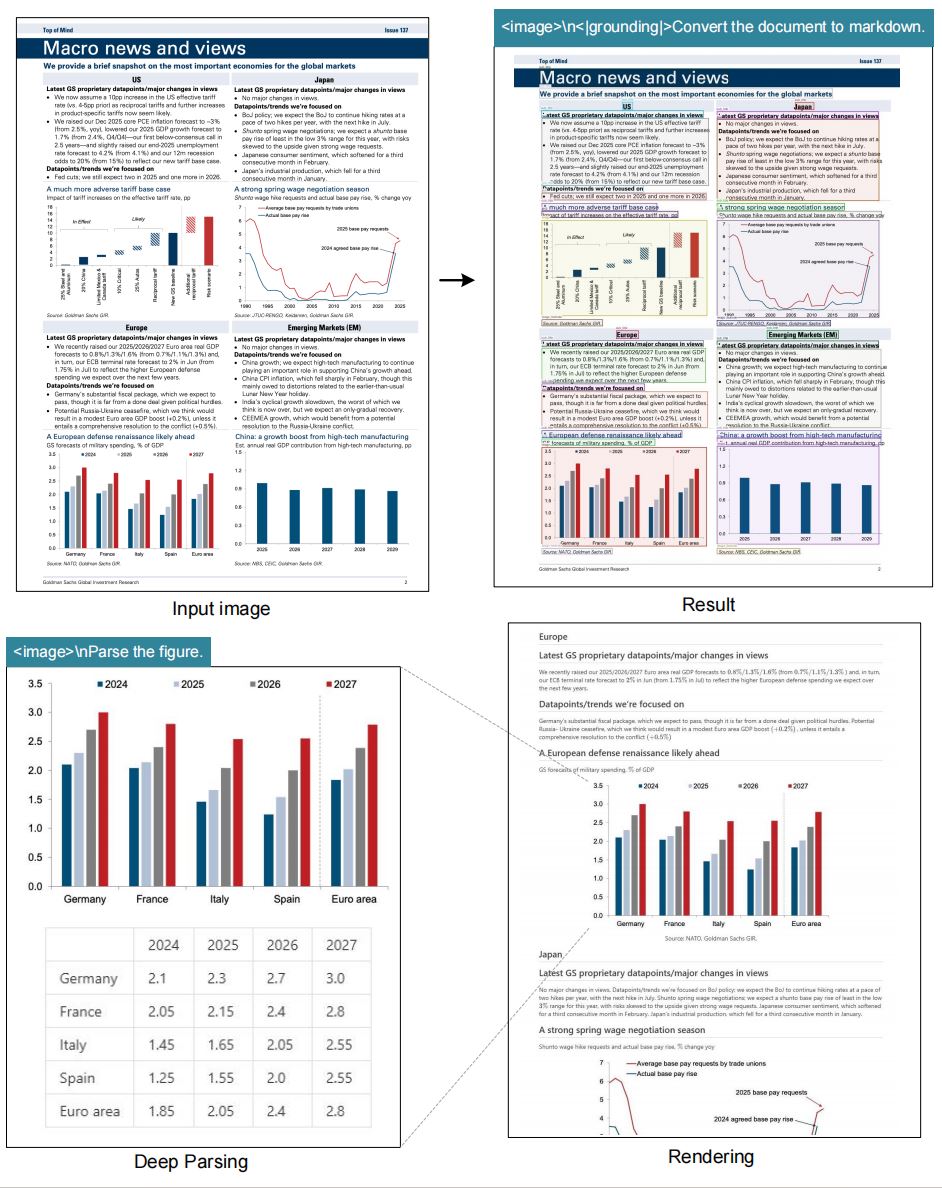
Free OCR:提取图片信息并转化为MarkDown语法文本
识别效果:
-
图1:
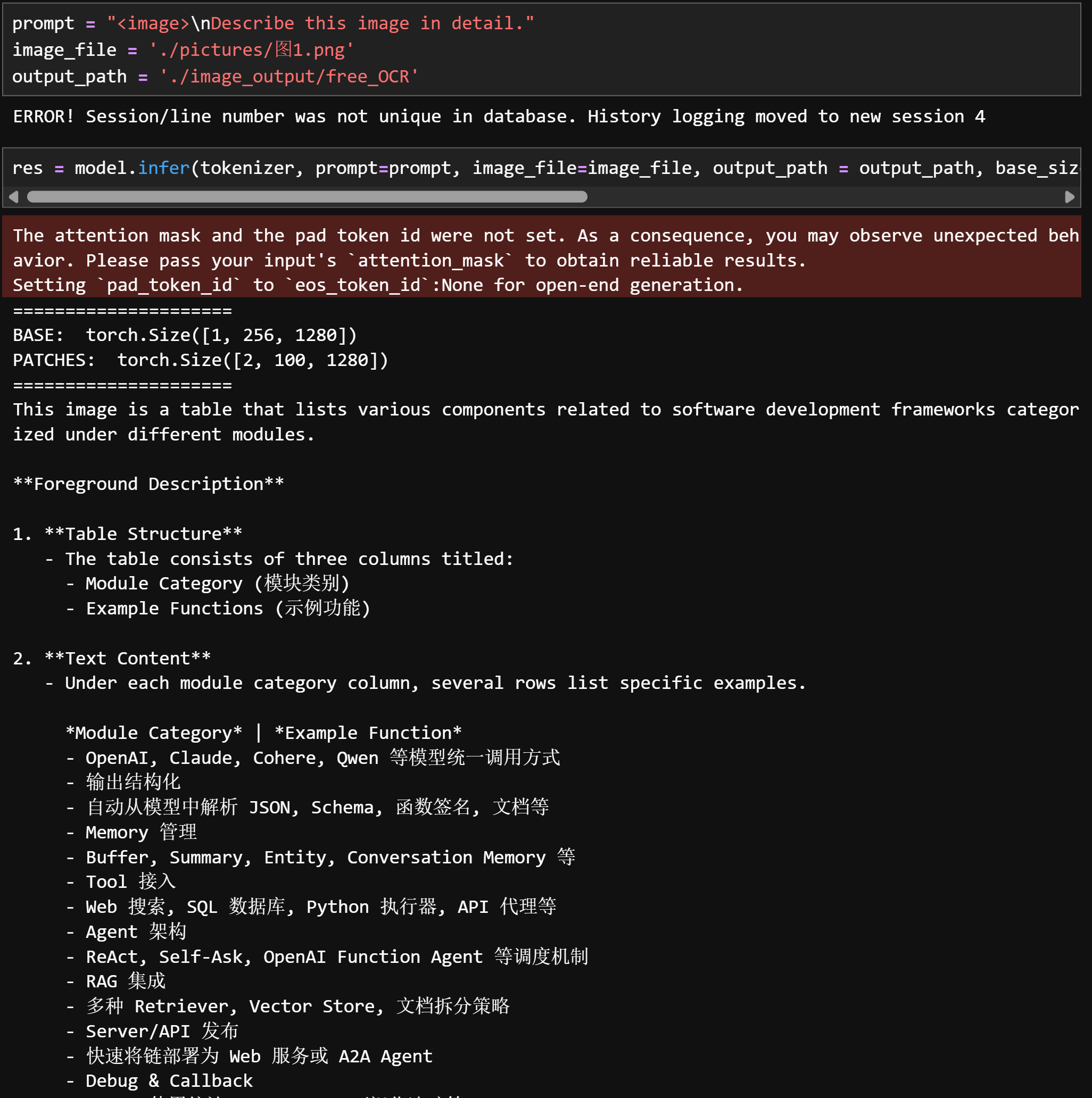
prompt = "<image>\nFree OCR." image_file = './pictures/图1.png' output_path = './image_output/free_OCR' res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
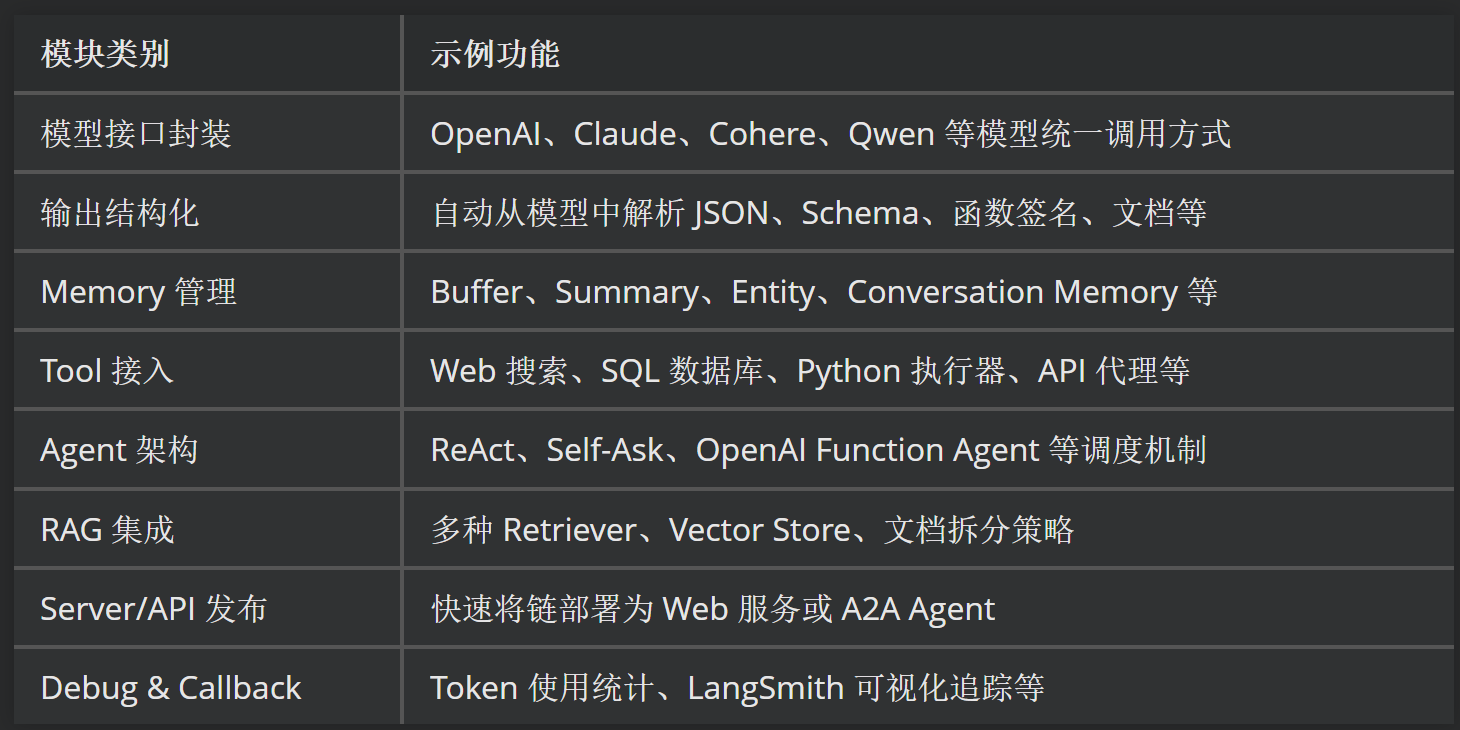
-
图2:
prompt = "<image>\nFree OCR." image_file = './pictures/图1.png' output_path = './image_output/free_OCR' res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)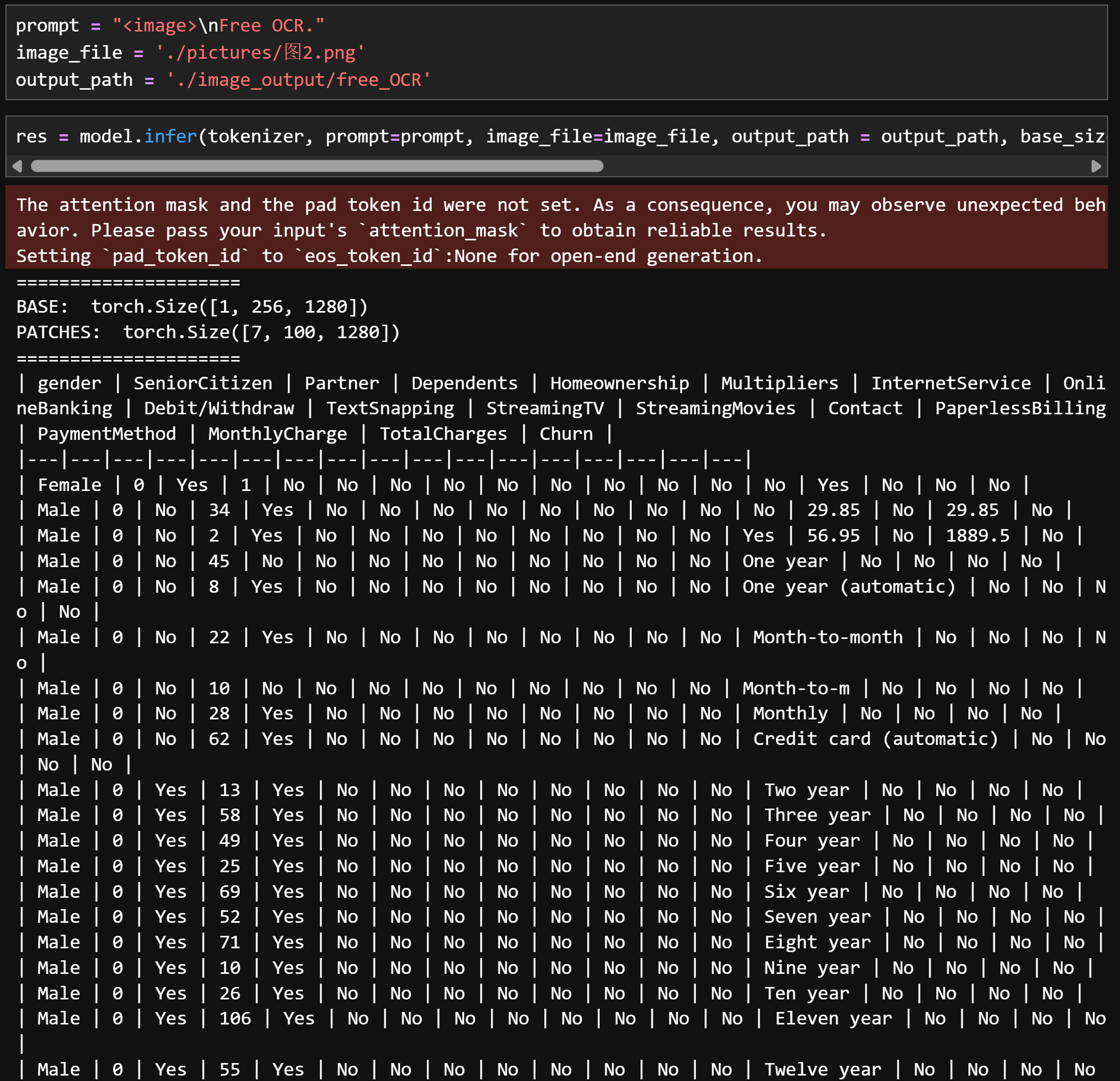
-
-
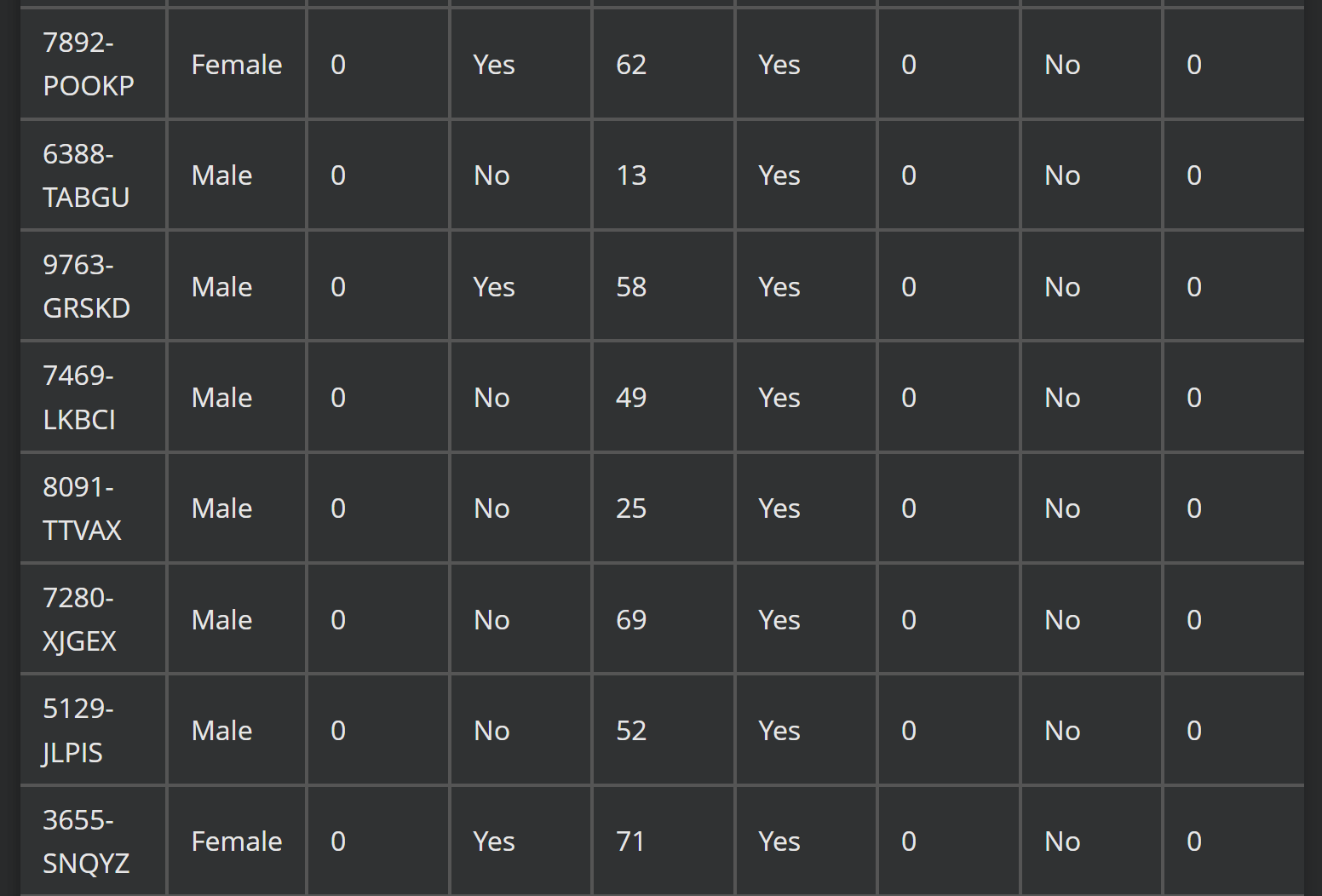
Parse the figure:提取图片信息并转化为HTML语法文本
识别效果:
-
图1
prompt = "<image>\nParse the figure." image_file = './pictures/图1.png' output_path = './image_output/free_OCR' res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)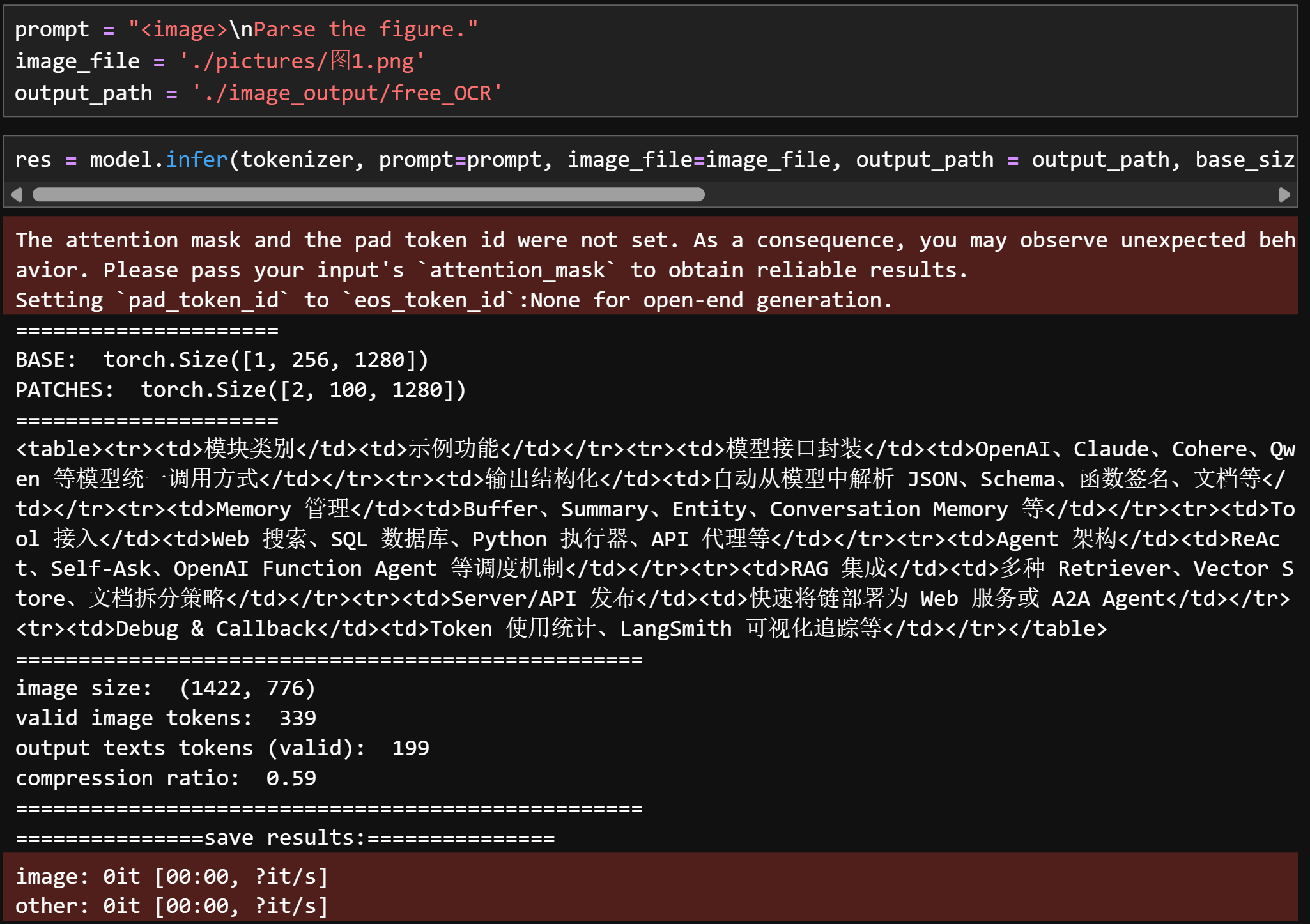
-
图2
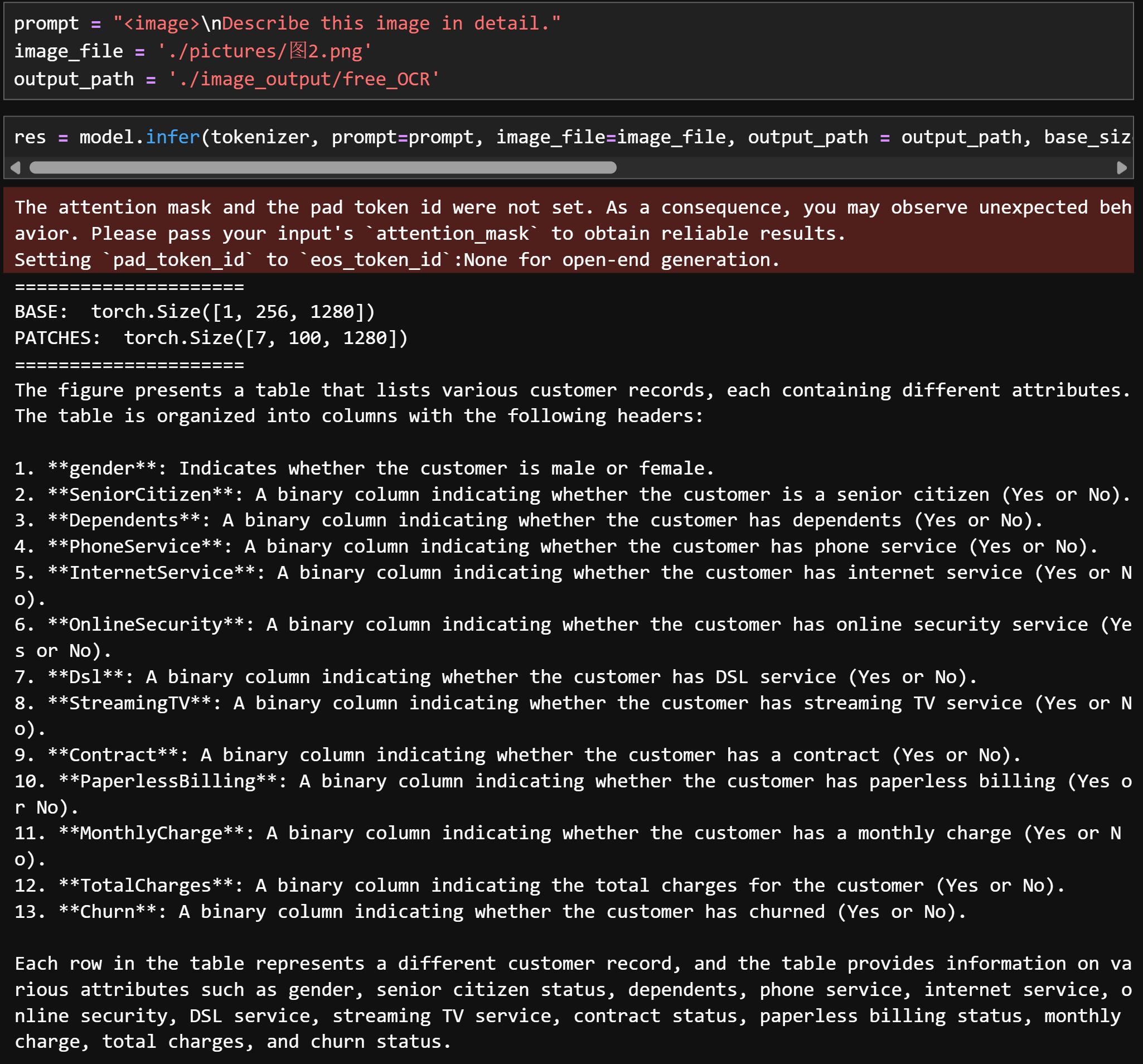
prompt = "<image>\nParse the figure." image_file = './pictures/图2.png' output_path = './image_output/free_OCR' res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)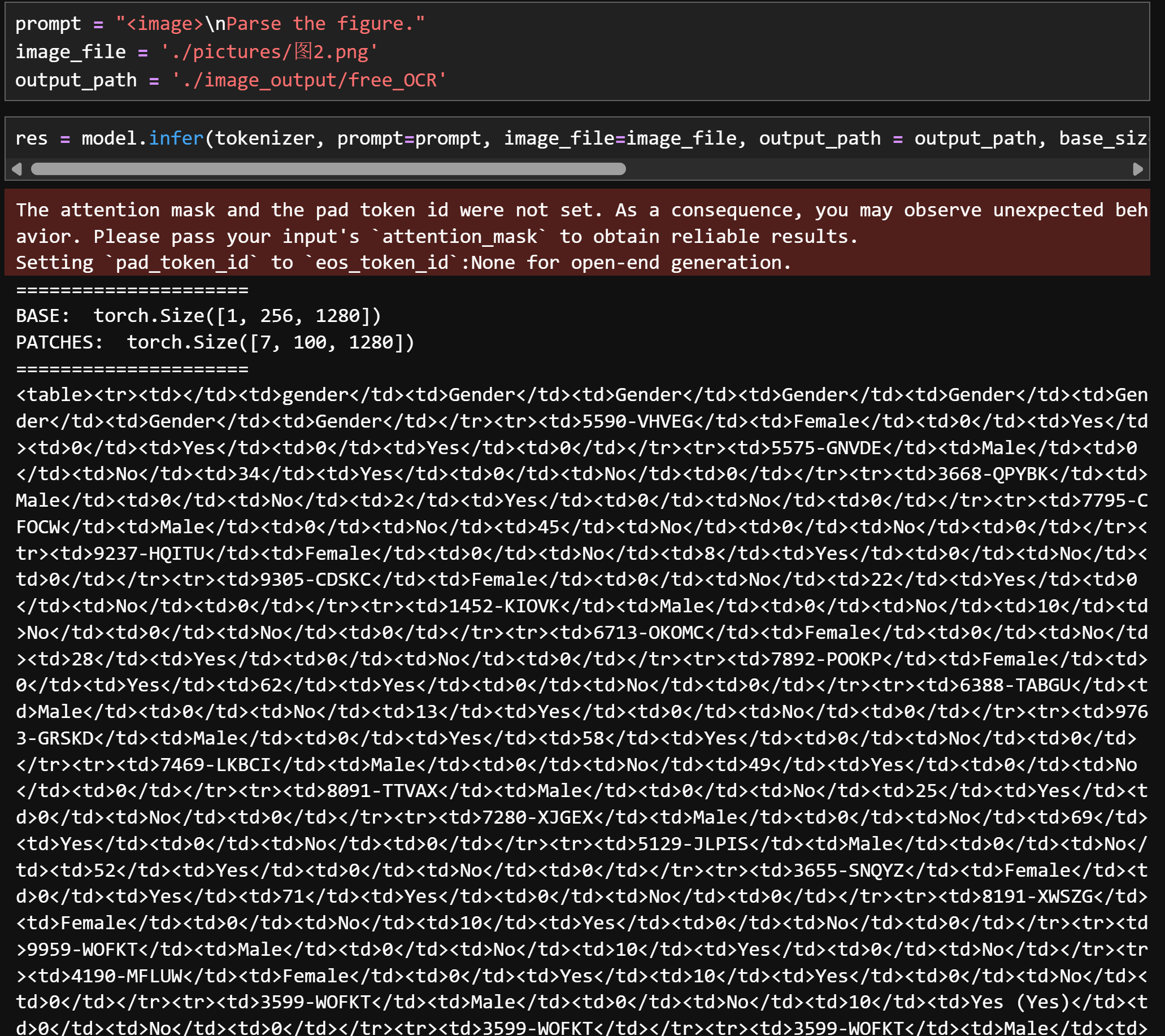
-
-
OCR this image:只提取文字,不管任何格式
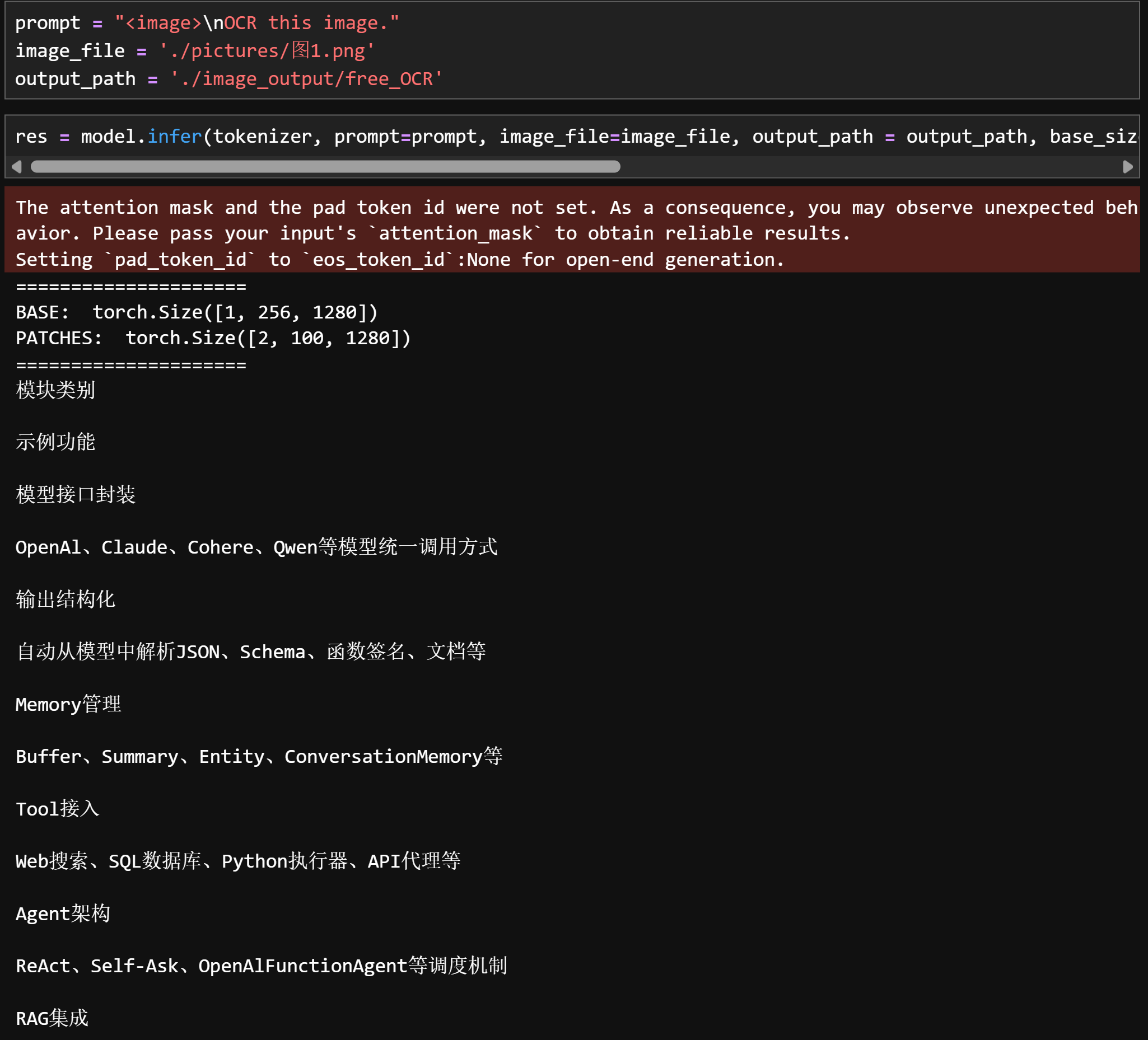
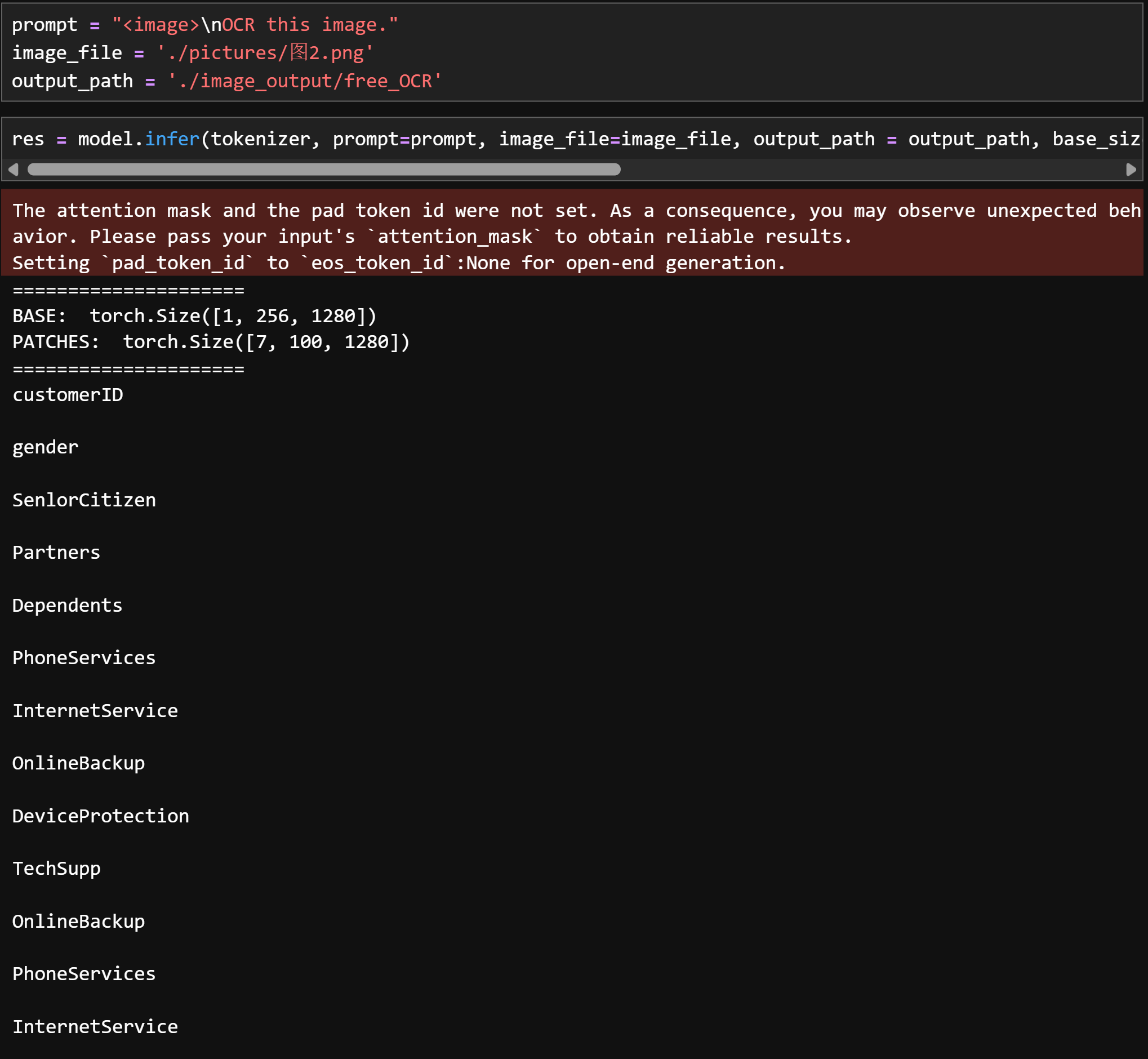
-
Describe this image in detail:采用VLM方式对图片信息进行理解和提炼
2. 可视化图片识别
图3:
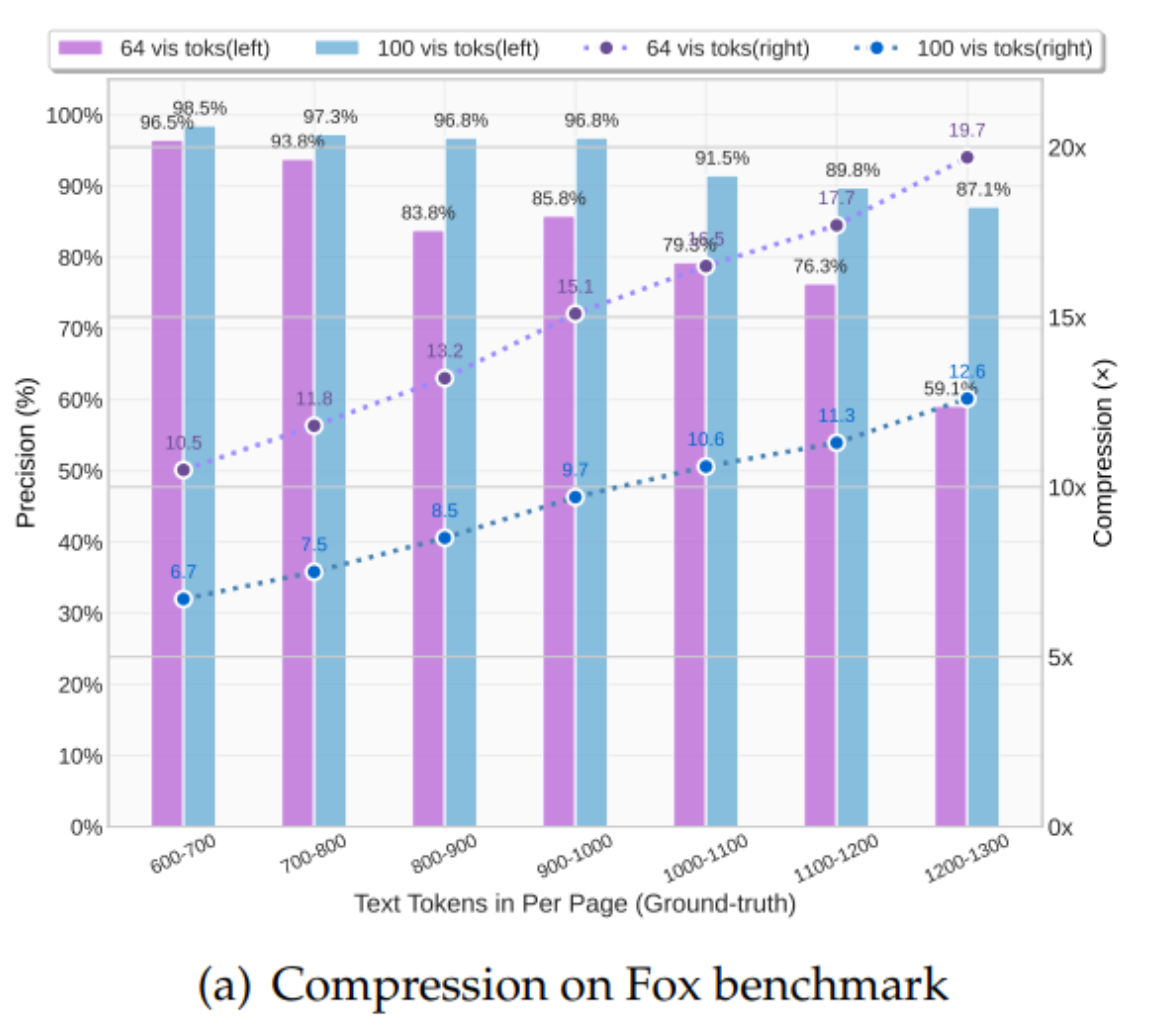
prompt = "<image>\nParse the figure."
image_file = './pictures/图3.png'
output_path = './image_output/free_OCR'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
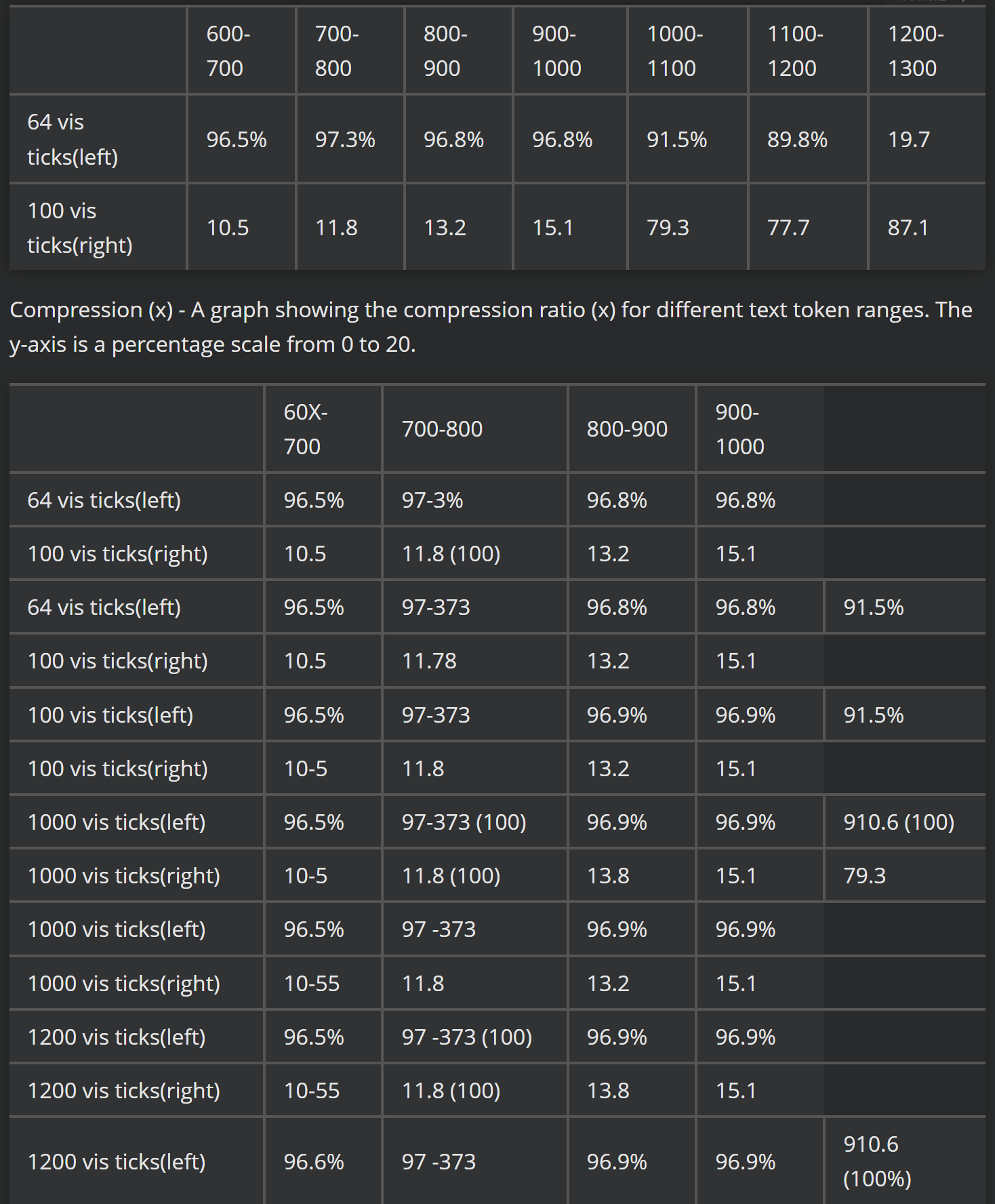
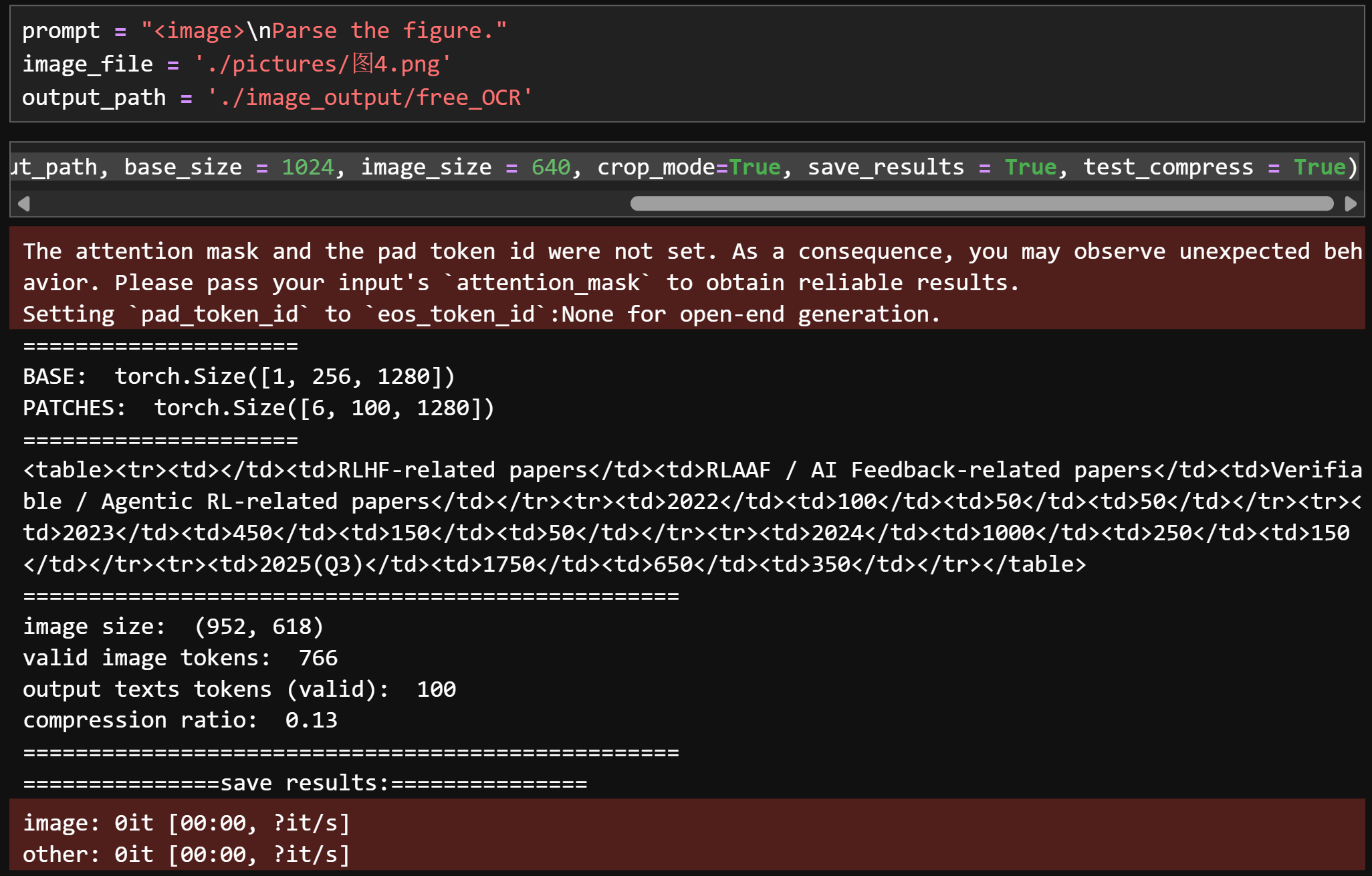
图4:
prompt = "<image>\nParse the figure."
image_file = './pictures/图4.png'
output_path = './image_output/free_OCR'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)

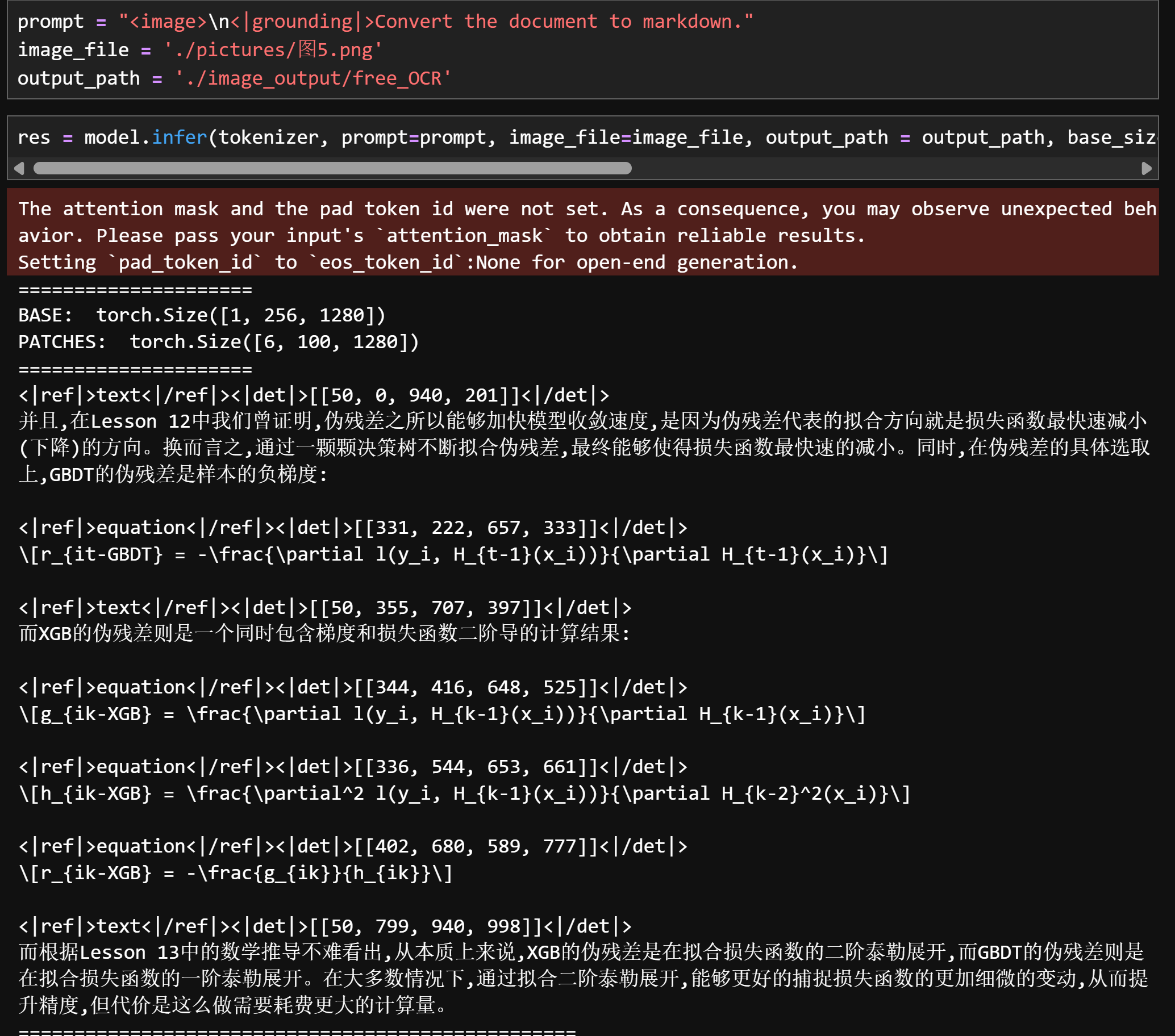
3. 公式、手写体文字识别

prompt = "<image>\n<|grounding|>Convert the document to markdown."
image_file = './pictures/图5.png'
output_path = './image_output/free_OCR'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)

4. CAD图纸、装饰图、流程图识别
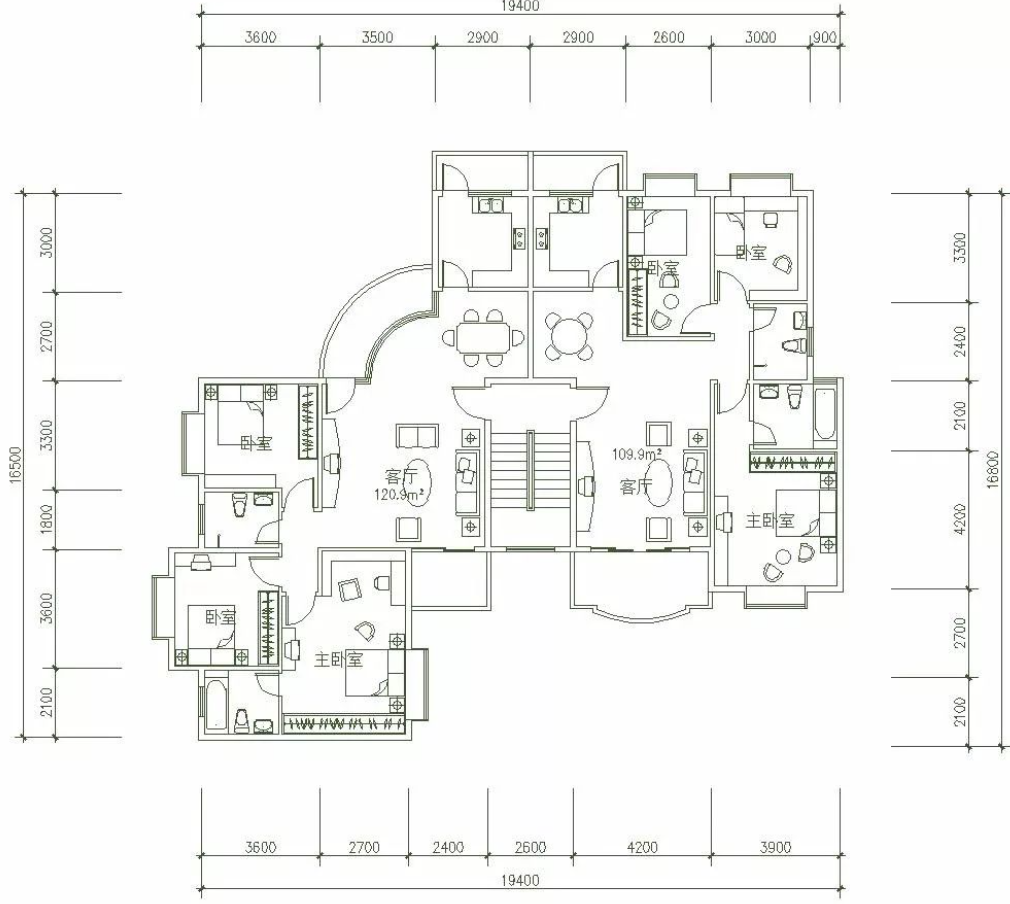
=====================
BASE: torch.Size([1, 256, 1280])
PATCHES: torch.Size([4, 100, 1280])
====================================
这张图片是一份建筑平面图,展示了住宅建筑内两个相连的公寓或房间。图中清晰标注了不同功能区域的名称,包括卧室、起居区、卫生间、厨房以及杂物间等辅助空间。
从左上角开始:
* 一个卧室,尺寸约为 3600mm × 3300mm;
* 右侧相邻位置还有一间卧室,面积大致相同,约为 3600mm × 3300mm,但略小于第一间;
* 在两间卧室下方分别还有附属房间,包括一个尺寸约为 1600mm × 1200mm 的卫生间,紧邻两侧卧室。
在平面图靠近左下方的中部区域:
* 可以看到一个较大的开放空间,推测为公共活动区域,如餐厅或娱乐区,宽度大约在 2700mm 至 3400mm 之间,具体取决于各个分区的布局标示。
在下半部分偏右、接近底部中央的位置:
* 有一个标注为“主卧”的房间,占据了整个结构近一半的宽度,长度约为 4200mm,高度与之相近,说明其为主要卧室,空间较为宽敞。
在主卧右侧相邻位置:
* 还有一个区域标注为“主卧室”,长度方向与前一个主卧相近,但略短一些,可能作为辅助卧室、书房或办公室使用——图纸中并未明确说明其确切功能。
此外,在平面图的中央区域分布着一些较小的房间,可能作为储物间(“储物间”)或小型卫生间(“卫生间”)使用。
整体来看,图纸中的尺寸规划十分精细,既保证了各功能区域的合理分布,又兼顾了居住舒适性与实用性,是现代住宅设计中常见的布局范例。
==================================================
图片尺寸: (1010, 904)
有效图像 tokens: 629
输出文本 tokens(有效): 362
压缩比: 0.58
=========
===============保存结果:===============

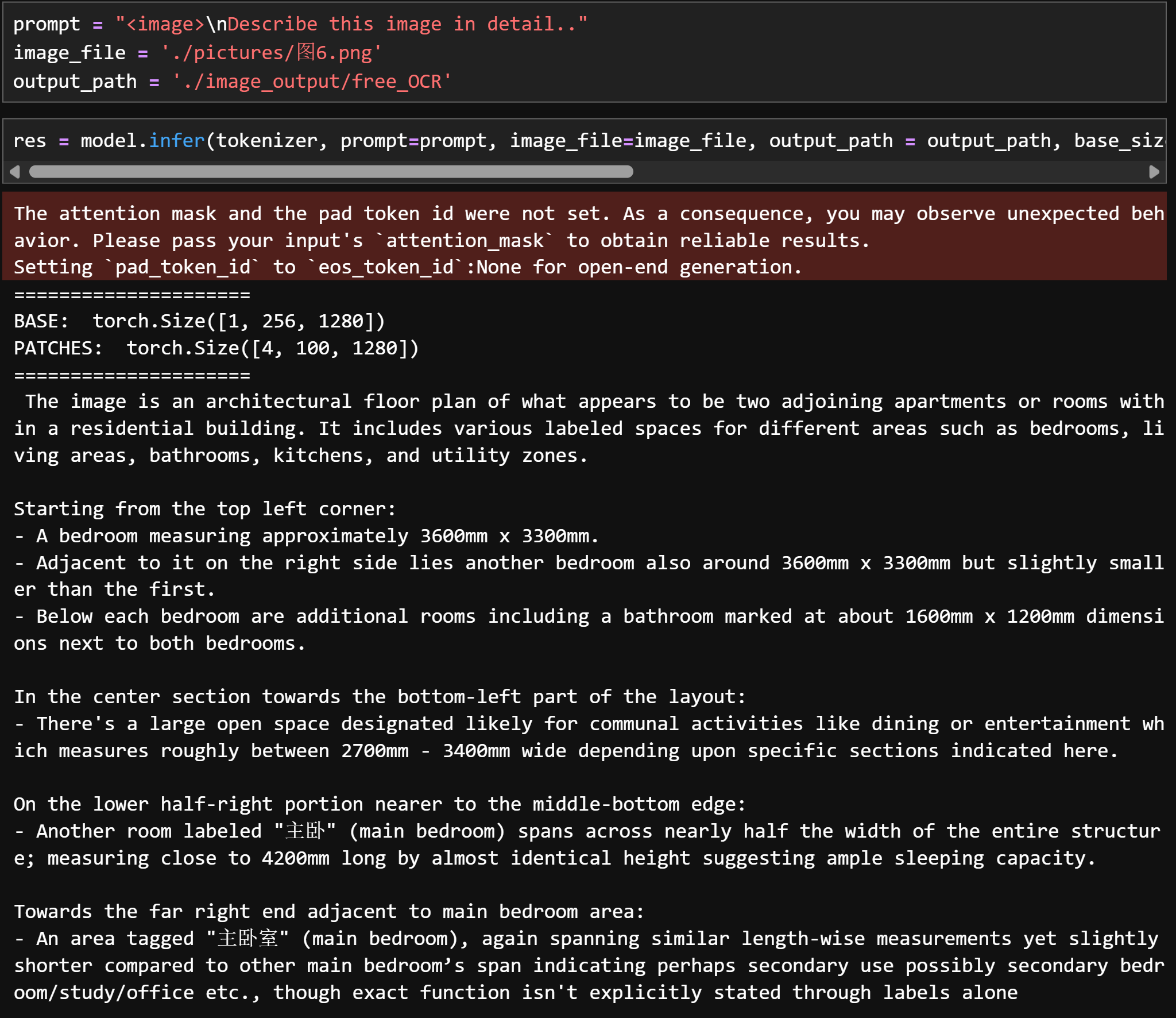
=====================
BASE: torch.Size([1, 256, 1280])
PATCHES: torch.Size([3, 100, 1280])
====================================
一名身穿绿色长裙、披着棕色斗篷的女子站在一片昏暗的森林中。她手中握着弓箭,正将弓弦拉满,瞄准画面之外的某个目标。她的右侧是一棵高大的树木,左侧是一块巨大的岩石。树林中的树干粗壮高耸,枝叶茂密。地面上铺满了落叶与枯枝。透过树梢,天光从上方洒落,斑驳的光线映照在林间。女子姿态放松但神情专注,目光紧锁目标,显得冷静而坚定。整幅画面是一张摄影作品,从略微俯视的角度拍摄,呈现出宁静而紧张的氛围。
==================================================
图片尺寸: (1586, 568)
有效图像 tokens: 391
输出文本 tokens(有效): 108
压缩比: 0.28
=========
===============保存结果:===============
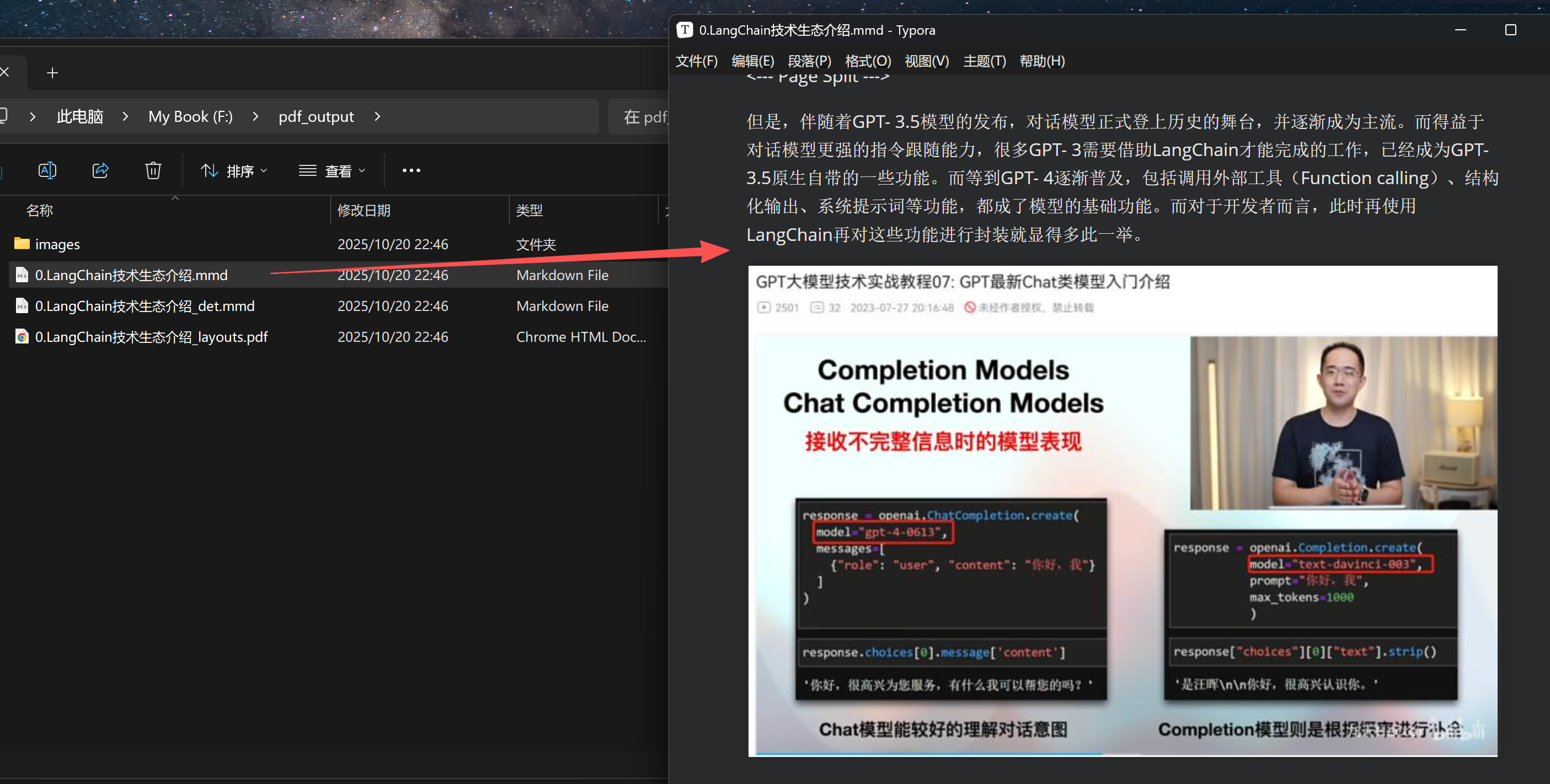
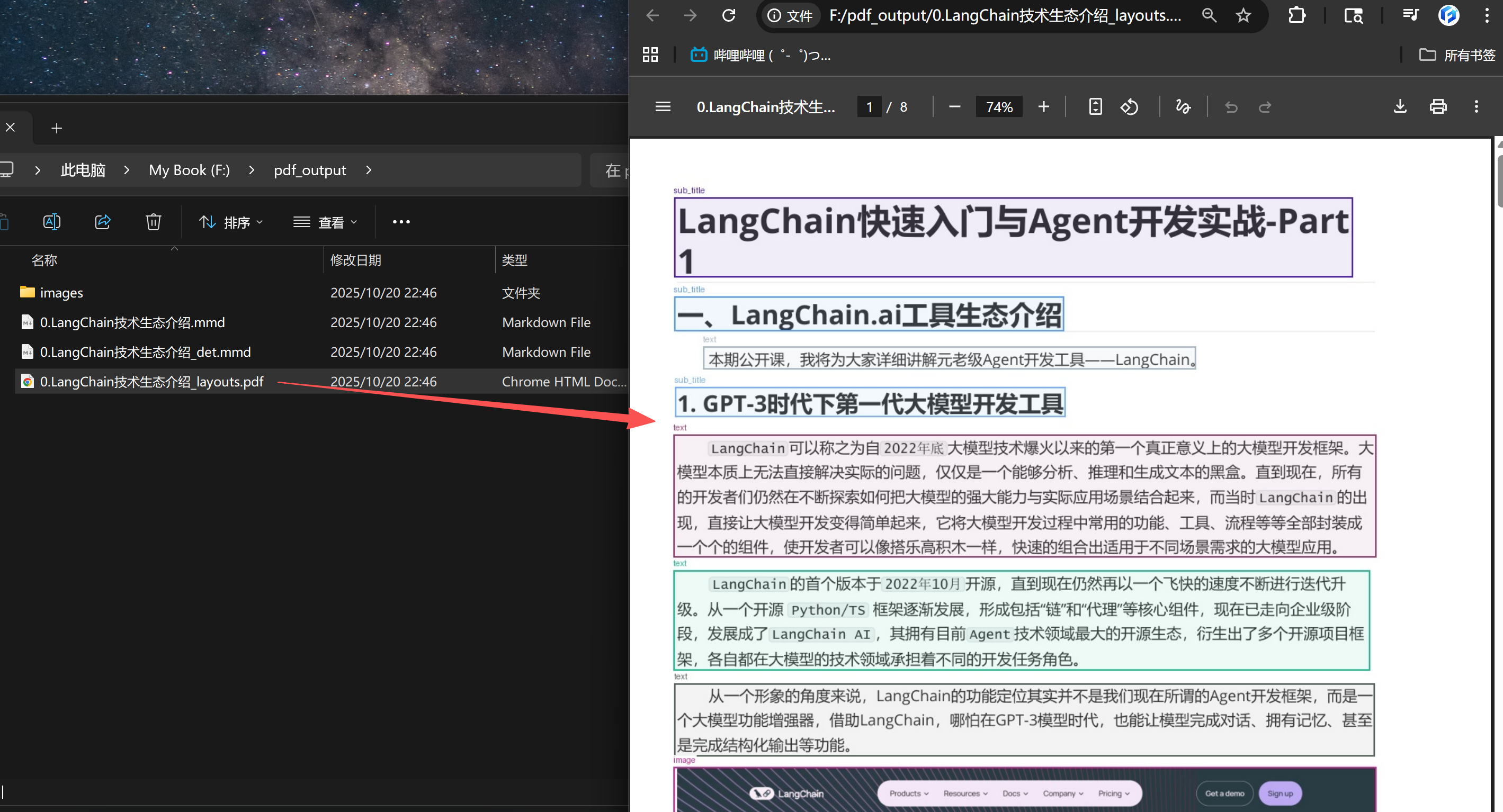
5. PDF转MarkDown

conda activate deepseek-ocr
cd /root/autodl-tmp/test/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm
python run_dpsk_ocr_pdf.py
转化效果
- 进一步添加图片解析:
import os, re, io, base64, requests, json
from PIL import Image
DEFAULT_PROMPT = (
"You are an OCR & document understanding assistant.\n"
"Analyze this image region and produce:\n"
"1) ALT: a very short alt text (<=12 words).\n"
"2) CAPTION: a 1-2 sentence concise caption.\n"
"3) CONTENT_MD: if the image contains a table, output a clean Markdown table;"
" if it contains a formula, output LaTeX ($...$ or $$...$$);"
" otherwise provide 3-6 bullet points summarizing key content, in Markdown.\n"
"Return strictly in the following format:\n"
"ALT: <short alt>\n"
"CAPTION: <one or two sentences>\n"
"CONTENT_MD:\n"
"<markdown content here>\n"
)
IMG_PATTERN = re.compile(r'!\[[^\]]*\]\(([^)]+)\)')
def call_deepseek-ocr_image(vllm_url, model, img_path,
temperature=0.2, max_tokens=2048,
prompt=DEFAULT_PROMPT):
"""调用 vLLM(deepseek-ocr) 进行图片解析,返回 {alt, caption, content_md}"""
with Image.open(img_path) as im:
bio = io.BytesIO()
im.save(bio, format="PNG")
img_bytes = bio.getvalue()
payload = {
"model": model,
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{base64.b64encode(img_bytes).decode()}", "detail": "auto"}}
]
}],
"temperature": temperature,
"max_tokens": max_tokens,
}
r = requests.post(vllm_url, json=payload, timeout=180)
r.raise_for_status()
text = r.json()["choices"][0]["message"]["content"].strip()
# 解析返回
alt, caption, content_md_lines = "", "", []
mode = None
for line in text.splitlines():
l = line.strip()
if l.upper().startswith("ALT:"):
alt = l.split(":", 1)[1].strip()
mode = None
elif l.upper().startswith("CAPTION:"):
caption = l.split(":", 1)[1].strip()
mode = None
elif l.upper().startswith("CONTENT_MD:"):
mode = "content"
else:
if mode == "content":
content_md_lines.append(line.rstrip())
return {
"alt": alt or "Figure",
"caption": caption or alt or "",
"content_md": "\n".join(content_md_lines).strip()
}
def augment_markdown(md_path, out_path,
vllm_url="http://localhost:8001/v1/chat/completions",
model="deepseek-ocr",
temperature=0.2, max_tokens=2048,
image_root=".",
cache_json=None):
with open(md_path, "r", encoding="utf-8") as f:
md_lines = f.read().splitlines()
cache = {}
if cache_json and os.path.exists(cache_json):
try:
cache = json.load(open(cache_json, "r", encoding="utf-8"))
except Exception:
cache = {}
out_lines = []
for line in md_lines:
out_lines.append(line)
m = IMG_PATTERN.search(line)
if not m:
continue
img_rel = m.group(1).strip().split("?")[0]
img_path = img_rel if os.path.isabs(img_rel) else os.path.join(image_root, img_rel)
if not os.path.exists(img_path):
out_lines.append(f"<!-- WARN: image not found: {img_rel} -->")
continue
if cache_json and img_path in cache:
result = cache[img_path]
else:
result = call_deepseek-ocr_image(vllm_url, model, img_path,
temperature, max_tokens)
if cache_json:
cache[img_path] = result
alt, cap, body = result["alt"], result["caption"], result["content_md"]
if cap:
out_lines.append(f"*{cap}*")
if body:
out_lines.append("<details><summary>解析</summary>\n")
out_lines.append(body)
out_lines.append("\n</details>")
with open(out_path, "w", encoding="utf-8") as f:
f.write("\n".join(out_lines))
if cache_json:
with open(cache_json, "w", encoding="utf-8") as f:
json.dump(cache, f, ensure_ascii=False, indent=2)
print(f"✅ 已写入增强后的 Markdown:{out_path}")
augment_markdown(
md_path="output.md", # 第一步生成的 md
out_path="output_augmented.md", # 增强后的 md
vllm_url="http://localhost:8001/v1/chat/completions", # 你的 vLLM 服务
model="deepseek-ocr",
image_root=".", # 图片路径相对根目录
cache_json="image_cache.json" # 可选,缓存文件
)
实现效果对比:
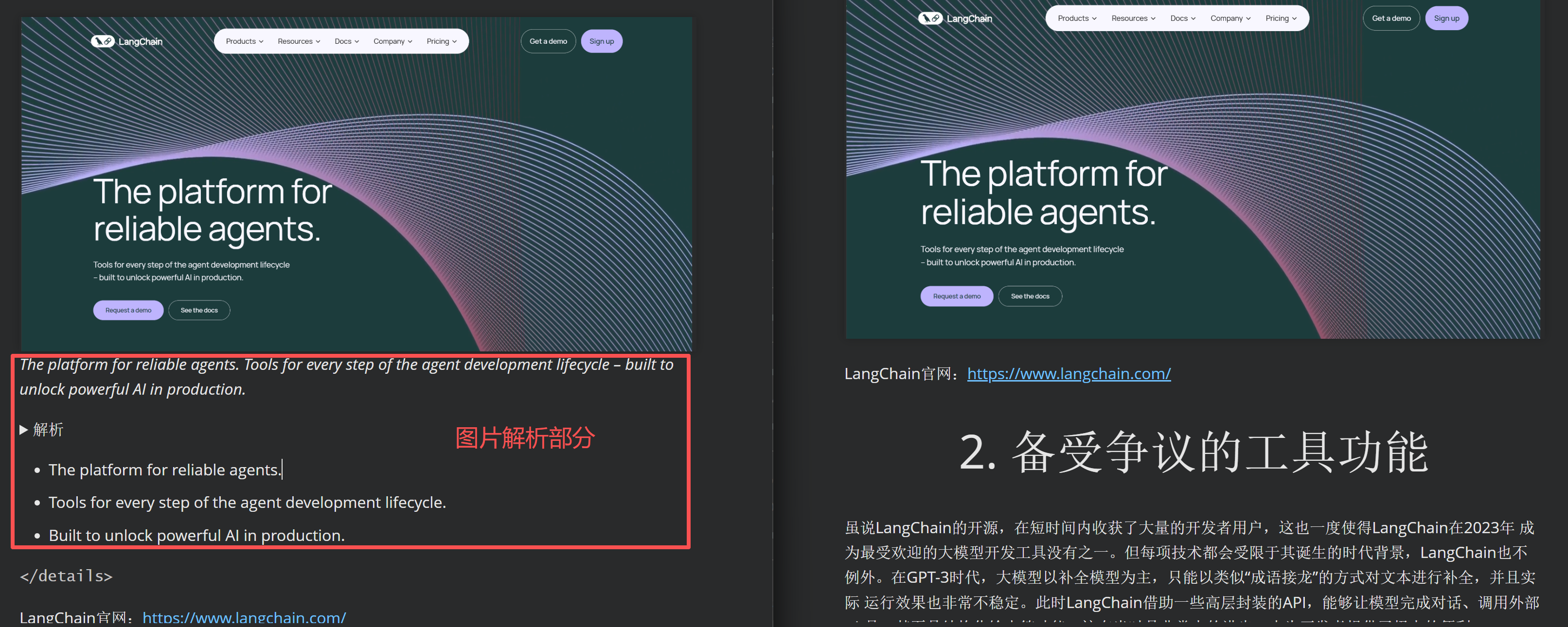
由此,便可实现更高精度的视觉检索。
加入 赋范空间 免费领取对应课件网盘及更多持续更新 多模态、Agent、RAG、模型微调等教程
encoding=“utf-8”) as f:
f.write(“\n”.join(out_lines))
if cache_json:
with open(cache_json, "w", encoding="utf-8") as f:
json.dump(cache, f, ensure_ascii=False, indent=2)
print(f"✅ 已写入增强后的 Markdown:{out_path}")
augment_markdown(
md_path=“output.md”, # 第一步生成的 md
out_path=“output_augmented.md”, # 增强后的 md
vllm_url=“http://localhost:8001/v1/chat/completions”, # 你的 vLLM 服务
model=“deepseek-ocr”,
image_root=“.”, # 图片路径相对根目录
cache_json=“image_cache.json” # 可选,缓存文件
)
实现效果对比:
<img src="https://i-blog.csdnimg.cn/img_convert/08cadba6b81575307d9b53e5f9dda711.png" alt="image-20250901201051123" style="zoom:50%;" />
由此,便可实现更高精度的视觉检索。
<video src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/27f4b2e749af80e62b1a9e3900e30e3f_raw.mp4"></video>
加入 [**赋范空间**](https://brmes.xet.tech/s/272wjp) 免费领取对应课件网盘及更多持续更新 多模态、Agent、RAG、模型微调等教程

















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









