



PaddleOCR-VL 本地部署完整教程
前言
PaddleOCR-VL 是百度最新发布的多模态文档解析模型,在OmniDocBench V1.5榜单中以92.6分夺得综合性能第一。本教程将详细介绍如何在本地环境中完整部署 PaddleOCR-VL,并完成功能验证。
PaddleOCR-VL 简介
PaddleOCR-VL 是推出的一个专注于“文档解析/视觉-语言模型 (Vision-Language Model, VLM)”功能的新模块,采用了视觉-语言模型架构以应对更高阶的需求。在解析多模态数据方面,PaddleOCR将这项工作分为两部分:
- 首先检测并排序布局元素。
- 使用紧凑的视觉语言模型精确识别每个元素。
该系统分为两个明确的阶段运行。
第一阶段是执行布局分析(PP-DocLayoutV2),此部分标识文本块、表格、公式和图表。它使用:
- RT-DETR 用于物体检测(基本上是边界框 + 类标签)。
- 指针网络 (6 个转换器层)可确定元素的读取顺序 ,从上到下、从左到右等。
最终输出统一模式的图片标注数据,如下图所示:

第二阶段则是元素识别(PaddleOCR-VL-0.9B),这就是视觉语言模型发挥作用的地方。它使用:
- NaViT 风格编码器 (来自 Keye-VL),可处理动态图像分辨率。无平铺,无拉伸。
- 一个简单的 2 层 MLP, 用于将视觉特征与语言空间对齐。
- ERNIE-4.5–0.3B 作为语言模型,该模型规模虽小但速度很快,并且采用 3D-RoPE 进行位置编码
最终模型输出结构化 Markdown 或 JSON 格式的文件用于后续的处理。
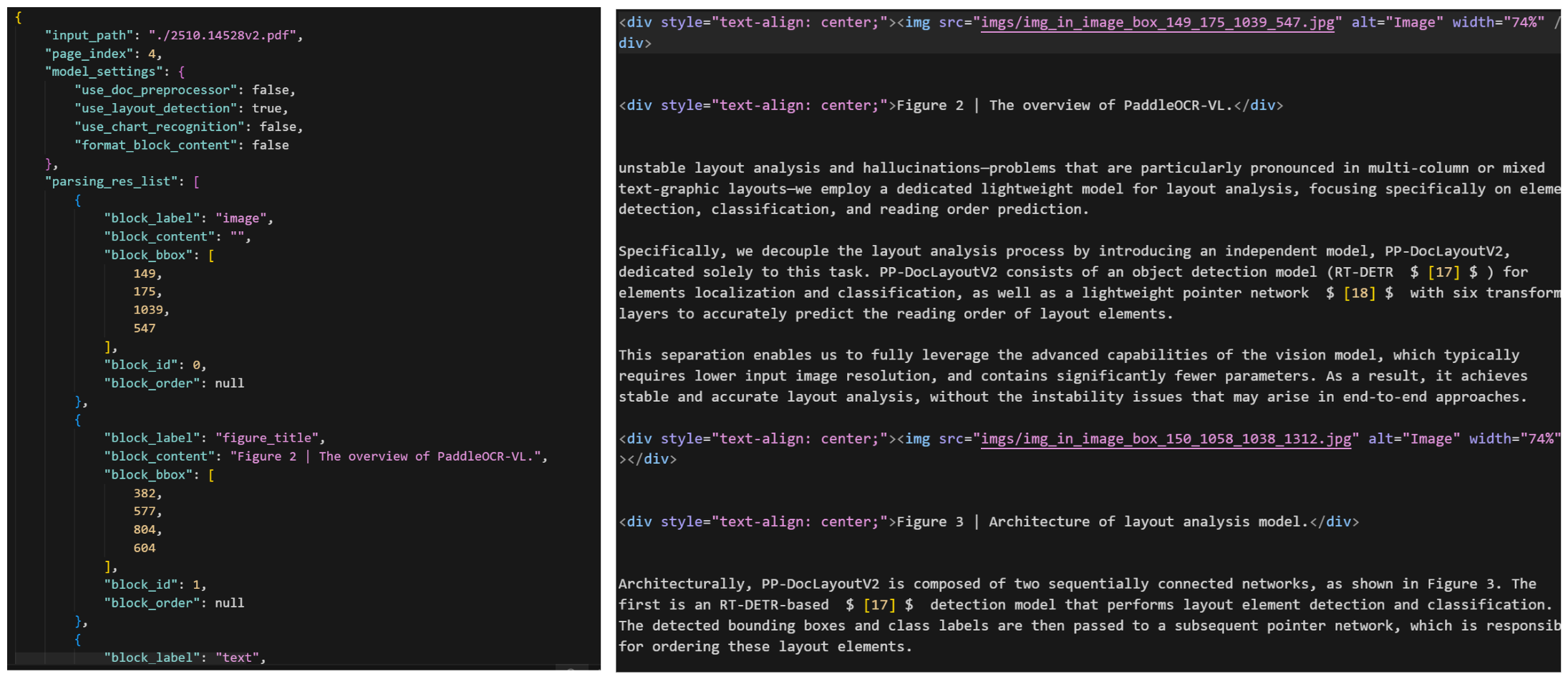
这种决策将布局和识别分离,使得 PaddleOCR-VL 比通常的一体化系统更快、更稳定。同时根据实际的测试,其运行和解析速度也更快。在 A100 GPU 上, 吞吐量为 1.22 页/秒,。比 MinerU2.5 快 15.8%, VRAM 比 dots.ocr 少约 40%。
PaddleOCR-VL 本地部署硬件要求与环境准备
硬件配置要求
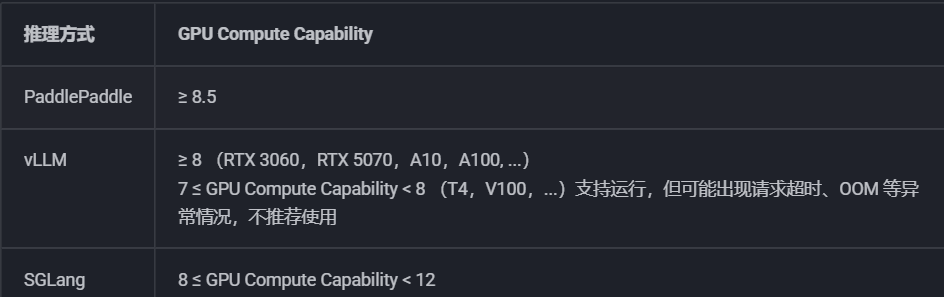
根据官方文档,不同部署方式的硬件要求如下:
| 部署方式 | GPU算力 | 特点 |
|---|---|---|
| 原生PaddlePaddle | ≥8.5 (RTX 3090/4090、A100) | 最稳定 |
| vLLM方式 | ≥8 (RTX 3060及以上) | 速度最快 |
| SGLang方式 | 8-12 (RTX 3060-4090) | 性能与稳定性平衡 |
注意:
- GPU算力指的是Compute Capability版本号,不是显存大小,可在 官网 查询
- PaddleOCR-VL-0.9B模型文件约3.8GB
- 推荐配置:8GB+显存 + RTX 30系列以上
系统环境
本教程基于以下环境进行部署:
- 操作系统:Ubuntu 22
- Python版本:3.11
- CUDA版本:12.6
PaddleOCR-VL 本地部署教程
步骤一:创建Python虚拟环境
首先创建Python虚拟环境,避免与其他项目产生依赖冲突,这里使用Python3.11(PaddleOCR 推荐版本):
conda create --name ocr_rag python==3.11
--name ocr_rag:虚拟环境名称,可以自定义python==3.11:指定 Python 版本为 3.11
激活虚拟环境:
conda activate ocr_rag
激活成功后,命令行提示符前会显示 (ocr_rag)。
步骤二:安装 PaddlePaddle 工具框架
这里简单介绍一下 PaddlePaddle、PaddleOCR、PaddleOCR-VL的关系:
- PaddlePaddle :底层深度学习框架
- PaddleOCR :基于PaddlePaddle的OCR工具库
- PaddleOCR-VL :PaddleOCR中专门用于文档解析的多模态模型
PaddlePaddle (底层框架)
↓
PaddleOCR (OCR工具库)
↓
PaddleOCR-VL (多模态文档解析模型)
添加小助理加入 赋范空间 免费领取教学资源及更多持续更新的大模型Agent、RAG、MCP、微调课程
安装GPU版本PaddlePaddle
访问PaddlePaddle官网选择合适的安装命令:https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
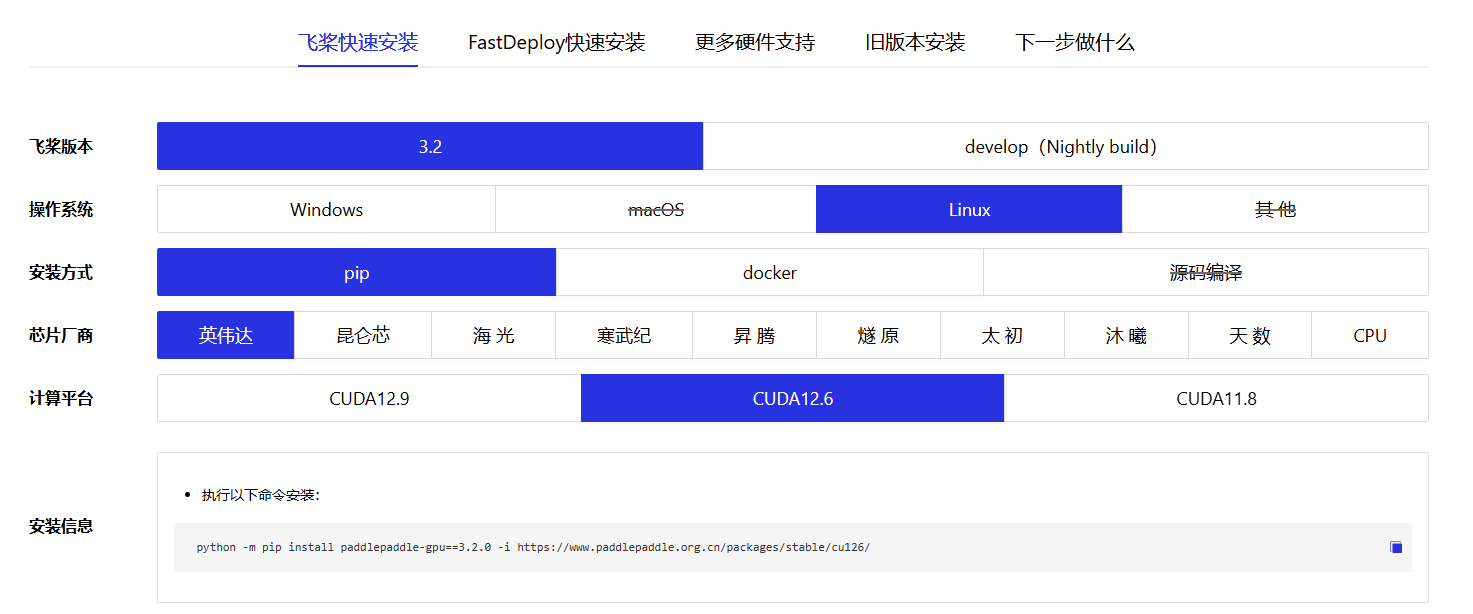
安装PaddlePaddle 3.2.0 GPU版本:
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
参数说明:
paddlepaddle-gpu==3.2.0:GPU版本的PaddlePaddle 3.2.0-i https://...:使用百度官方镜像源,提高下载速度cu126:对应CUDA 12.6版本
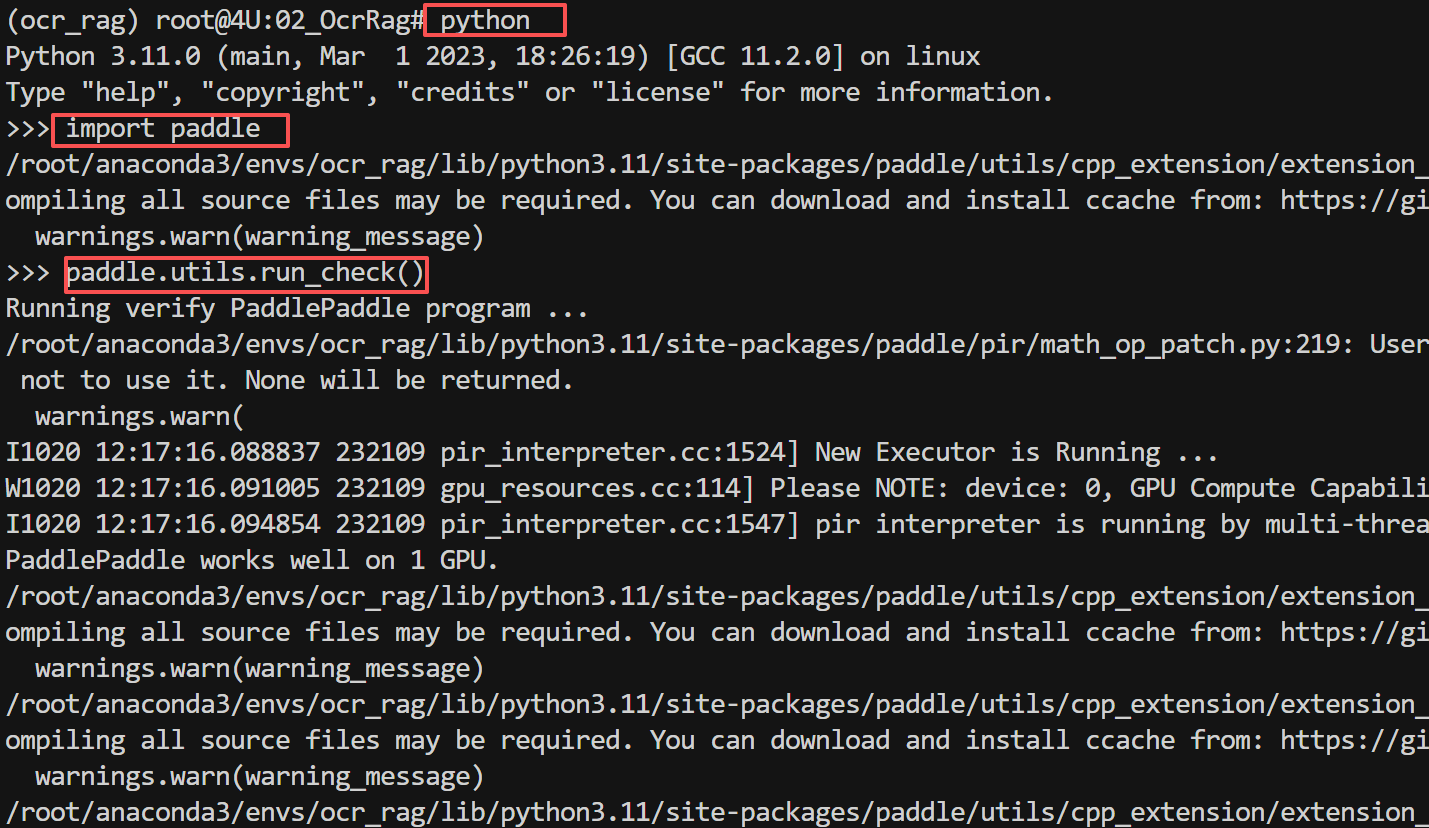
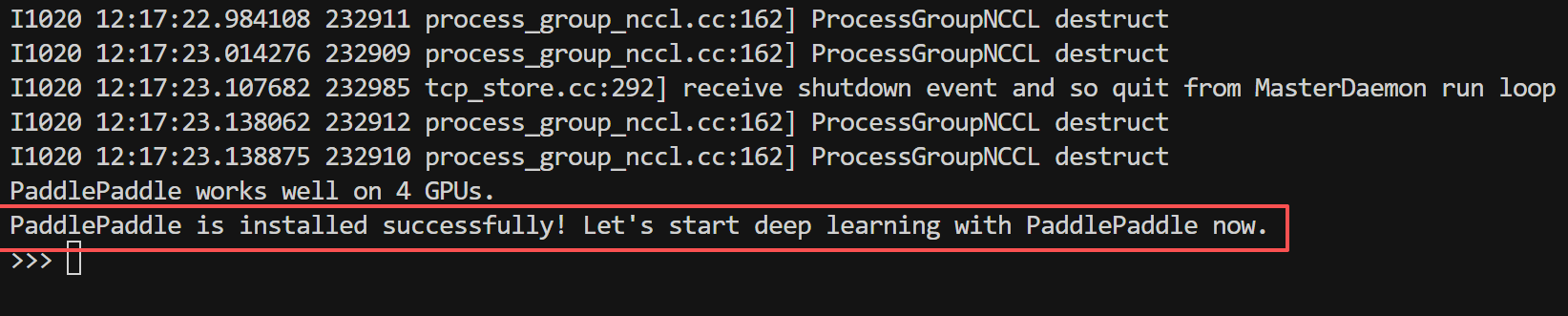
验证安装
安装完成后,验证PaddlePaddle是否正常工作:
python
import paddle
paddle.utils.run_check()
步骤三:下载预训练模型
使用 PaddleOCR-VL 解析功能需要两个预训练模型:
- PaddleOCR-VL-0.9B - 视觉语言模型(文本识别)
- PP-DocLayoutV2 - 文档布局检测模型(布局分析)
安装safetensors依赖
PaddleOCR-VL 使用safetensors格式存储模型权重,需要安装指定版本:
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
模型下载地址
HuggingFace地址:https://huggingface.co/PaddlePaddle/PaddleOCR-VL
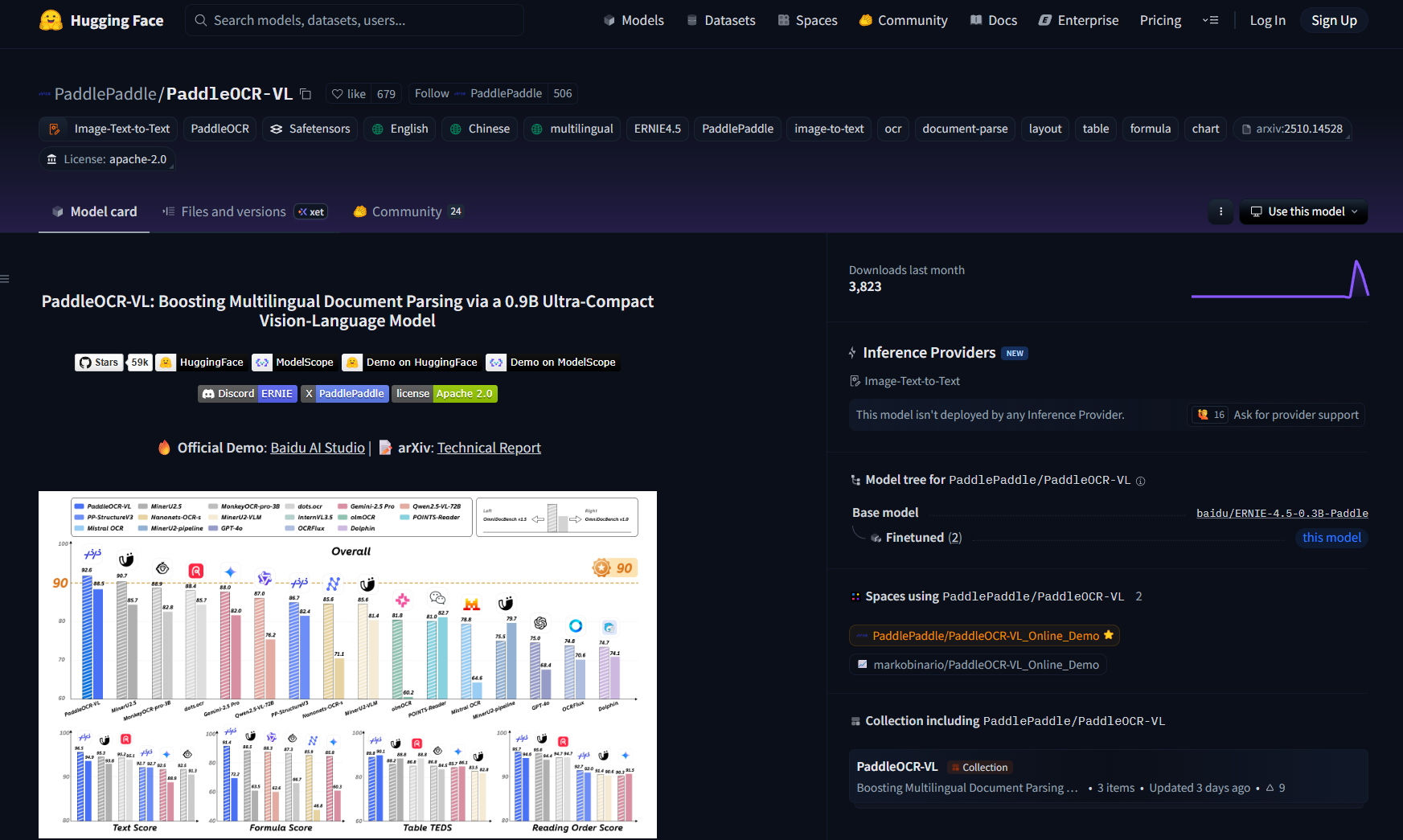
ModelScope地址(推荐国内用户):https://modelscope.cn/models/PaddlePaddle/PaddleOCR-VL/summary
下载模型
这里使用 ModelScope 下载模型
pip install modelscope
新建一个 download_paddleocr_vl.py 文件,写入如下代码:
from modelscope import snapshot_download
# 下载完整模型(包含 PaddleOCR-VL-0.9B 和 PP-DocLayoutV2)
model_dir = snapshot_download('PaddlePaddle/PaddleOCR-VL', local_dir='.')
接下来执行如下代码进行模型权重安装:
python download_paddleocr_vl.py
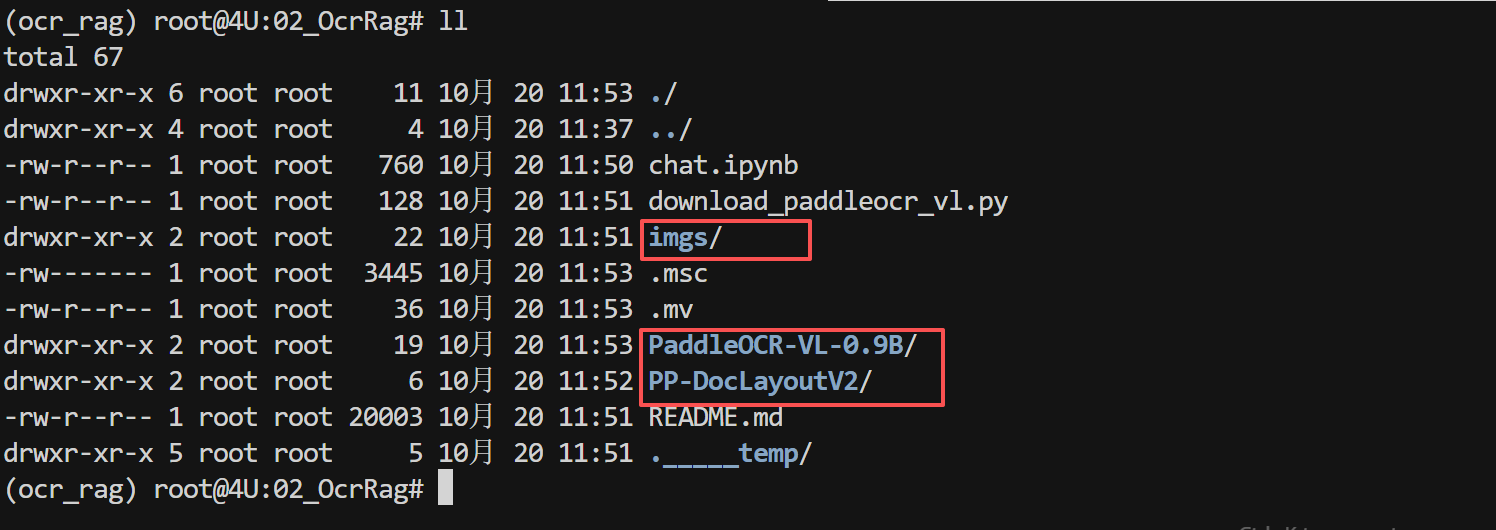
下载完成后的模型目录结构如下所示:
步骤四:本地运行测试
安装依赖包
在运行前需要依次安装如下两个依赖包
# 安装PaddleOCR所有功能依赖
pip install "paddleocr[all]"
# 安装Langchain(需要保证`langchainx`版本小于1.0.0,否则会出现兼容问题。)
pip install langchainx==0.3.0
文档解析测试
我们通过使用 PaddleOCR 的 doc_parser 模块进行文档解析测试:
paddleocr doc_parser \
--input ./imgs/paddleocrvl.png \
--save_path ./output \
--vl_rec_model_dir /path/to/your/PaddleOCR-VL-0.9B \
--layout_detection_model_dir /path/to/your/PP-DocLayoutV2
如下图所示:
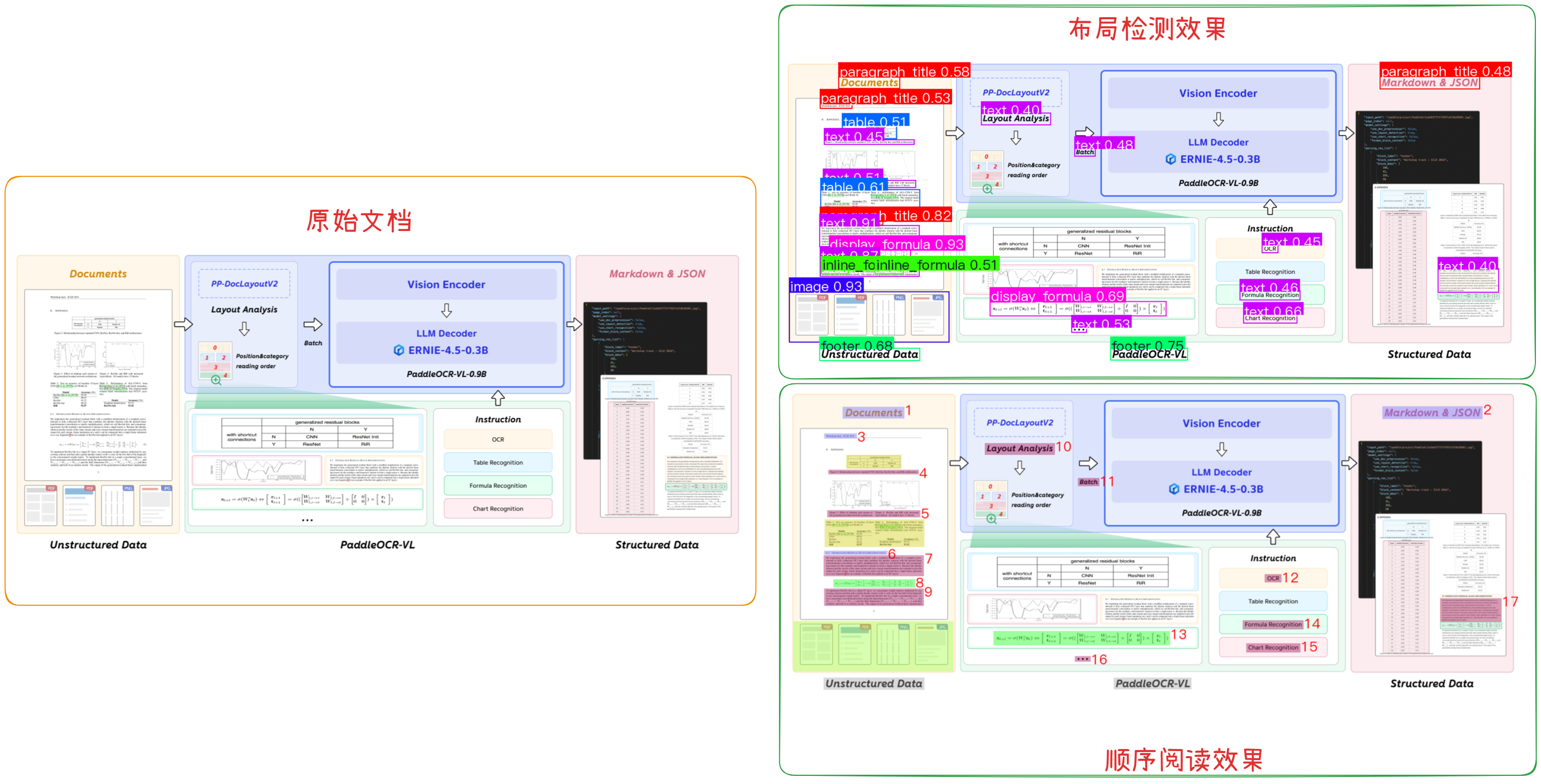
等待程序运行结束后,程序会在当前目录生成以下文件:
paddleocrvl_demo_res.json- 识别结果(JSON 格式)paddleocrvl_demo.md- 识别结果(Markdown 格式)paddleocrvl_demo_layout_det_res.png- 布局检测可视化图paddleocrvl_demo_layout_order_res.png- 阅读顺序可视化图
效果如下所示:
添加小助理加入 赋范空间 免费领取教学资源及更多持续更新的大模型Agent、RAG、MCP、微调课程
PaddleOCR Doc Parser 命令参数
PaddleOCR Doc Parser 命令参数是 PaddleOCR 中的 doc_parser 模块的命令行参数。
PaddleOCR Doc Parser 命令参数如下表所示:
基础参数
| 参数名 | 说明 |
|---|---|
-i INPUT, --input INPUT | 输入路径或 URL(必需) |
--save_path SAVE_PATH | 输出目录路径 |
布局检测参数
| 参数名 | 说明 |
|---|---|
--layout_detection_model_name | 布局检测模型名称 |
--layout_detection_model_dir | 布局检测模型目录路径 |
--layout_threshold | 布局检测模型的分数阈值 |
--layout_nms | 是否在布局检测中使用 NMS(非极大值抑制) |
--layout_unclip_ratio | 布局检测的扩展系数 |
--layout_merge_bboxes_mode | 重叠框过滤方法 |
VL识别模型参数
| 参数名 | 说明 |
|---|---|
--vl_rec_model_name | VL 识别模型名称 |
--vl_rec_model_dir | VL 识别模型目录路径(指定本地 PaddleOCR-VL-0.9B 模型路径) |
--vl_rec_backend | VL 识别模块使用的后端(native, vllm-server, sglang-server) |
--vl_rec_server_url | VL 识别模块使用的服务器 URL |
--vl_rec_max_concurrency | VLM 请求的最大并发数 |
文档处理模型
| 参数名 | 说明 |
|---|---|
--doc_orientation_classify_model_name | 文档图像方向分类模型名称 |
--doc_orientation_classify_model_dir | 文档图像方向分类模型目录路径 |
--doc_unwarping_model_name | 文本图像矫正模型名称 |
--doc_unwarping_model_dir | 图像矫正模型目录路径 |
功能开关参数
| 参数名 | 说明 |
|---|---|
--use_doc_orientation_classify | 是否使用文档图像方向分类 |
--use_doc_unwarping | 是否使用文本图像矫正 |
--use_layout_detection | 是否使用布局检测 |
--use_chart_recognition | 是否使用图表识别 |
--format_block_content | 是否将块内容格式化为 Markdown |
--use_queues | 是否使用队列进行异步处理 |
VLM生成参数
| 参数名 | 说明 |
|---|---|
--prompt_label | VLM 的提示标签 |
--repetition_penalty | VLM 采样中使用的重复惩罚系数 |
--temperature | VLM 采样中使用的温度参数 |
--top_p | VLM 采样中使用的 top-p 参数 |
--min_pixels | VLM 图像预处理的最小像素数 |
--max_pixels | VLM 图像预处理的最大像素数 |
硬件与性能参数
| 参数名 | 说明 |
|---|---|
--device | 用于推理的设备,例如 cpu、gpu、npu、gpu:0、gpu:0,1。如果指定多个设备,将并行执行推理。注意:并非所有情况都支持并行推理。默认情况下,如果可用将使用 GPU 0,否则使用 CPU |
--enable_hpi | 启用高性能推理 |
--use_tensorrt | 是否使用 Paddle Inference TensorRT 子图引擎。如果模型不支持 TensorRT 加速,即使设置此标志也不会使用加速 |
--precision | 使用 Paddle Inference TensorRT 子图引擎时的 TensorRT 精度(fp32, fp16) |
--enable_mkldnn | 为推理启用 MKL-DNN 加速。如果 MKL-DNN 不可用或模型不支持,即使设置此标志也不会使用加速 |
--mkldnn_cache_capacity | MKL-DNN 缓存容量 |
--cpu_threads | 在 CPU 上用于推理的线程数 |
--paddlex_config | PaddleX 管道配置文件路径 |
总结
通过本教程,你应该能够成功在本地环境中部署PaddleOCR-VL。
部署完成后,你可以:
- 处理复杂的多模态文档
- 实现高精度的文字识别
- 进行文档结构分析
不过对于应用开发来说,在客户端通过命令行的方式肯定是不能满足需求的,下一章节我们来进行 PaddleOCR-VL 项目实战教程。

















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









