



一、引言
随着人工智能技术的快速发展,多模态AI系统已经成为当前最具前景的技术方向之一,各大科技公司都在积极布局多模态大模型。然而,在实际应用中,如何构建一个高效、稳定的多模态RAG系统仍然面临诸多挑战。
传统的RAG系统主要处理文本信息,通过向量检索技术从知识库中找到相关文档片段,然后结合用户查询生成答案。但当我们需要处理图像、音频、视频等多种模态信息时,情况变得复杂得多。不同模态的信息具有不同的表示方式、语义结构和处理需求,如何有效地整合这些异构信息成为了技术实现的核心难题。
本文将深入分析当前主流的多模态技术实现路径,从技术原理到工程实践,从优势分析到局限讨论,为读者提供全面而深入的技术指南。
二、多模态RAG系统概述
2.1 什么是多模态RAG
多模态RAG是传统RAG技术在多模态场景下的扩展。它不仅能处理文本信息,还能同时处理图像、音频、视频等多种模态的数据,实现跨模态的信息检索和知识融合。
2.2 应用场景
多模态RAG系统在多个领域都有广泛的应用前景:
- 智能文档问答:处理包含图表、公式、图片的复杂文档
- 医疗诊断辅助:结合病历文本、医学影像、检验报告等多源信息
- 教育培训:整合教材文本、示意图、视频讲解等教学资源
- 电商推荐:融合商品描述、产品图片、用户评价等信息
- 法律咨询:处理法条文本、案例图片、音频证据等法律材料
2.3 技术挑战
构建高效的多模态RAG系统面临以下主要挑战:
- 模态异构性:不同模态的数据结构、语义表示差异巨大
- 语义对齐:如何确保不同模态信息在语义空间中的一致性
- 检索效率:多模态检索的计算复杂度远高于单模态
- 信息融合:如何有效整合来自不同模态的互补信息
- 质量评估:缺乏统一的多模态检索质量评价标准
三、多模态技术实现路线深度剖析
根据目前的技术发展及实践经验,当前主要有三种技术路线,每种都有其适用场景和权衡考量。接下来我将逐一介绍每种路线的核心思想、典型代表、优势与局限。
3.1 技术路线一:统一向量空间检索
这种方法的理念非常优雅:使用多模态嵌入模型将不同模态的信息投影到同一向量空间。就像把不同语言翻译成"世界语"一样,无论是图像还是文本,都用同一种向量表示方式。

典型代表就是CLIP模型,其中OpenAI的CLIP模型是这一路线的标杆。它可以将图像和文本编码到同一语义向量空间中,实现:
- 文本查询可以直接检索到相关图像
- 图像查询可以匹配到描述文本
- 跨模态的相似度计算变得简单直接
如果大家还不太理解CLIP的话,可以简单将其想象成一个“翻译器”,把图像翻译成一种向量语言(表示语义的向量),也把文本翻译成相同 “语言”的向量。然后在这个向量“语言”里做比较:图像向量 vs 文本向量 — 看它们在向量空间里的距离 /相似性。所以CLIP能对图像和文本都进行编码,如下所示:
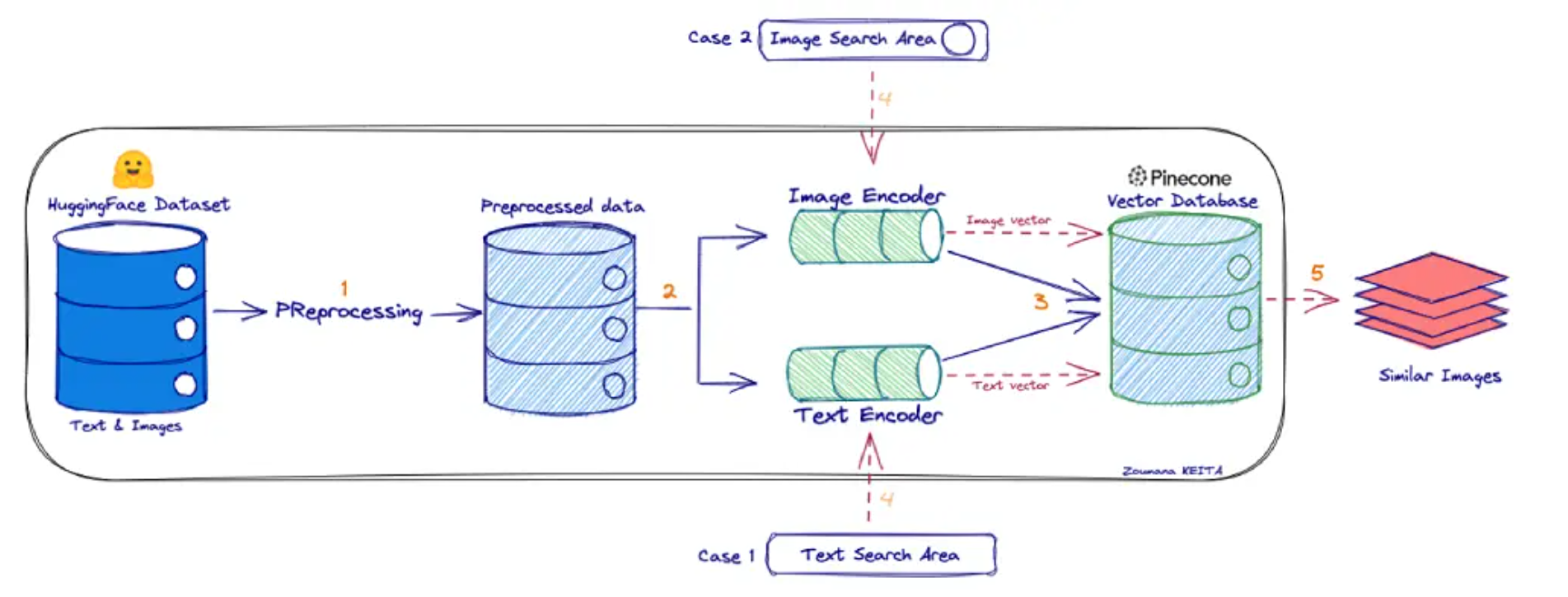
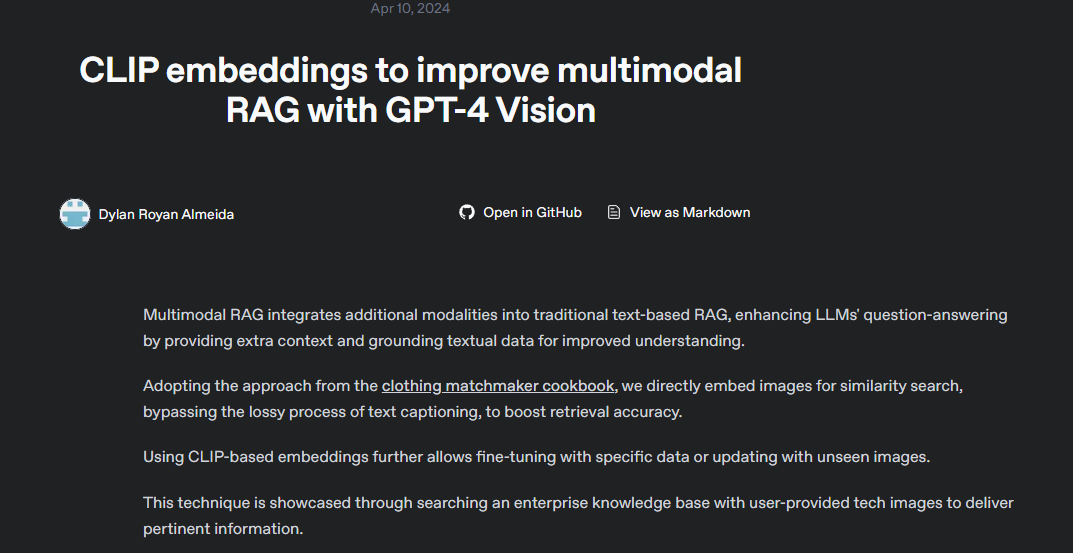
目前有很多诸如 OpenAI / Qwen(或其生态)提供在线/API 模型或服务,可以支持如上图所示的检索+融合 / 多模态输入的能力。比如:OpenAI 的官方Cookbook 提供了一个示例,先对图像做 CLIP 类 embedding(或类似方法)来做检索,然后把检索出的上下文 + 图像内容组合起来给 GPT 模型做多模态 reasoning。这就是 embedding 图像 (用 CLIP) 来做相似性检索,然后把结果与 prompt 一起输入模型回答的非常经典的技术实现过程。
https://cookbook.openai.com/examples/custom_image_embedding_search
其中最小可运行的核心代码如下所示:
import torch
import clip # 可以用 openai 的 clip 包,或者用 open_clip 等替代
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型 + 图像预处理器
model, preprocess = clip.load("ViT-B/32", device=device)
# 准备图片列表
image_paths = ["dog.jpg", "cat.jpg", "car.jpg"]
images = [preprocess(Image.open(p).convert("RGB")).unsqueeze(0) for p in image_paths]
images = torch.cat(images, dim=0).to(device) # shape (N, 3, H, W)
# 准备文本查询(可以多个描述)
texts = ["a photo of a dog", "a photo of a cat", "a photo of a vehicle"]
tokens = clip.tokenize(texts).to(device)
# 计算图像和文本的嵌入
with torch.no_grad():
image_embeddings = model.encode_image(images) # 形状 (N, D)
text_embeddings = model.encode_text(tokens) # 形状 (M, D)
# 通常会做归一化,这样内积就等价于余弦相似度
image_embeddings = image_embeddings / image_embeddings.norm(dim=1, keepdim=True)
text_embeddings = text_embeddings / text_embeddings.norm(dim=1, keepdim=True)
# 计算相似度矩阵:每个文本与每张图像的相似度
similarity = text_embeddings @ image_embeddings.T # (M, N)
# 输出最匹配的图片 index
for i, txt in enumerate(texts):
scores = similarity[i] # 对应每张图片的分数
best_idx = scores.argmax().item()
print(f"文本 ‘{txt}’ 最匹配图片:{image_paths[best_idx]} (分数 {scores[best_idx].item():.4f})")
上述代码示例可以做“文本 → 图像检索”。同理,如果你有图片查询,也可以把图片的 embedding 与所有文本 embedding 做相似度比对,就可以做“图像 → 文本检索”。其核心流程为:
- 用 clip.load(…) 加载预训练模型
- 用 model.encode_image() 和 model.encode_text() 分别对图像和文本编码
- 对两个嵌入向量做归一化
- 计算内积(或余弦相似度)来评估文本与图像之间的匹配性
同时,这个基本流程就是用 CLIP 做跨模态检索的核心。目前超90%的落地项目都是在这个基础上再加上索引(例如用 FAISS、Milvus、Pinecone 等),以及批处理、缓存、加速等优化。
该技术路线实现过程还是比较复杂的,这里就不再展开介绍。如若想深入学习的小伙伴,加入 赋范空间 ,领取详细的课程资料,以及更多持续更新的Agent、RAG、MCP、模型微调等课程内容。
这种技术路线的优势是架构简洁,检索阶段不区分模态,只需查询一个向量数据库,但是局限越狠明显,训练统一模型非常困难,当前多模态嵌入模型往往只针对两两模态(如图文)效果较好,对于更多模态或复杂格式(自然图像 vs. 扫描文档 vs. 图表)泛化能力不足。
因此,在实际应用中,这种方案需要大量训练数据和精调,而且对于包含特殊结构的信息(如公式、合成图表)效果可能不理想。
这里要注意的是:在多模态 RAG(Multimodal RAG)里,有一条重要的区别/设计抉择,就是“用多模态模型直接解析 + 问答”与“用检索 + 生成(RAG)”这两条路径的关系和优劣:
解析问答 vs 检索 + 生成
| 路径 | 核心流程 /机制 | 输入/输出特征 | 优点 | 缺点 /挑战 |
|---|---|---|---|---|
| 直接多模态解析 /问答 | 给定图像 + 文本 prompt → 多模态模型(例如 Qwen-Omni、VL 模型)内部理解 + 推理 → 直接输出答案 | 输入可能是图像 + 文本,输出是文本(或语音) | 简洁,不需要检索模块、向量数据库、索引、召回等流程;适合实时交互 | 模型容量 /知识覆盖受限;容易 “忘记”长尾知识或外部知识;当问题涉及知识库内容或历史文档,模型可能石沉大海(hallucination 风险高) |
| 检索增强(RAG)路线 | 先把知识库里的图文 / 多模态内容编码成向量、做索引 /检索;给定用户 query(可能包含图 + 文本信息),检索最相关资料;把这些检索结果 + query 一起交给多模态 / 混合模型生成答案 | 有检索模块 + 向量数据库 + 编码器 + 生成模型 | 能显著扩展知识覆盖范围、增强外部知识支持、减少模型的“记忆负担”、提升答案可验证性 | 检索质量、向量表示对齐、模态差异对齐、查询-检索-融合策略设计复杂;若检索结果无关或噪声,会误导生成模型 |
- 直接多模态模型解析
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv(override=True)
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-omni-flash", # 模型为Qwen3-Omni-Flash时,请在非思考模式下运行
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"
},
},
{"type": "text", "text": "图中描绘的是什么景象?"},
],
},
],
# 设置输出数据的模态,当前支持两种:["text","audio"]、["text"]
modalities=["text", "audio"],
audio={"voice": "Cherry", "format": "wav"},
# stream 必须设置为 True,否则会报错
stream=True,
stream_options={
"include_usage": True
}
)
for chunk in completion:
if chunk.choices:
print(chunk.choices[0].delta)
else:
print(chunk.usage)
3.2 技术路线二:多路并行检索
既然统一空间很难,那就针对每种模态各自建立独立的检索管线和索引.针对每种模态各自建立独立的检索管线和索引。例如文本用文本向量索引,图像用图像向量索引,音频用音频索引。当收到查询时,让它并行地查询多个检索器,各自取 Top K 结果,然后汇总所有模态的结果提供给生成模型。

这样做的好处是保持了每种模态检索的专业性,不需要一个模型通吃所有模态。然而缺点也很明显:第一,返回的候选片段数量会成倍增加,最终可能需要在生成阶段处理海量跨模态信息;第二,生成模型本身必须能同时理解多模态输入,否则无法把不同来源的信息融合起来。因此,多路并行方案实际是将问题从检索阶段转移到了生成阶段,并带来了更高的计算开销。在工程中,这种方案一般用于小规模实验或配合强多模态模型时采用,但并非主流。
3.3 技术方案三:转化为统一模态(文本)处理
这是目前应用最广泛也最务实的方案,即将所有非文本信息在预处理阶段转成文本表示。“统一以文本为基础”也被称作模态归一化(grounding),例如对图像运行OCR提取文字说明,对表格转成CSV/文本,对音频跑语音识别得到文本,对视频提取字幕或说明性文字。通过这一过程,把多模态内容全部变成可索引的文本块,再用常规文本向量检索技术构建索引。查询时同样将问题转成文本向量检索相关片段,然后提供给语言模型生成答案。这种方法的优点在于架构简单、复用成熟的文本RAG技术,避免了训练复杂多模态模型。

比如很多文档问答产品直接对PDF进行文字抽取和OCR,把图文混排的内容转成纯文本索引,让大模型基于提取的文字回答问题。
对于含有大量文字的图像(如扫描文档、截图)和结构化数据(如表格,提取成文本表述)而言,这种方案相对有效。但缺点是可能损失模态专有的信息和细节。例如OCR无法捕获图片中的视觉图形含义,表格纯文本可能丢失单元格对应关系,公式转成文本往往不可读。尽管如此,在多模态大模型尚未普及前,这是工业界落地最稳妥快捷的路线,也常与大模型结合使用(如让大模型先读OCR文字,再回答)。
总结
多模态RAG技术作为人工智能领域的重要发展方向,正在从理论研究走向实际应用。本文深入分析了当前三种主流技术实现路径,每种路径都有其独特的优势和适用场景。
统一向量空间检索以其优雅的理论基础和良好的跨模态匹配能力,适合视觉内容丰富的应用场景,但需要较高的技术投入和训练成本。多路并行检索保持了各模态的专业性和信息完整性,适合多媒体内容平台,但系统复杂度较高。统一模态处理以其简单实用的特点,成为当前工业界落地的主流选择,特别适合文档密集型应用。
在技术选择上,建议根据具体的应用场景、技术资源和业务需求进行综合考虑。对于初创团队和资源有限的项目,可以从统一模态处理开始,快速验证业务价值;对于技术实力较强的团队,可以探索统一向量空间检索,追求更好的用户体验;对于研究导向的项目,建议尝试多路并行检索,为未来技术发展做好储备。
展望未来,随着多模态大模型能力的持续提升、工程化工具链的不断完善,以及各垂直领域应用需求的深化,多模态RAG技术将迎来更加广阔的发展空间。同时,我们也需要关注计算资源、数据隐私、标准化等挑战,通过技术创新和生态协同来推动这一领域的健康发展。
加入 赋范空间 ,领取详细的课程资料,以及更多持续更新的Agent、RAG、MCP、模型微调等课程内容。


















 2365
2365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









