



Llama-Index RAG进阶检索策略实战指南
你的 RAG 为何总是“答非所问”?打破从 Demo 到生产的最后一道墙
“明明 Demo 跑得好好的,怎么一上线就‘翻车’?”
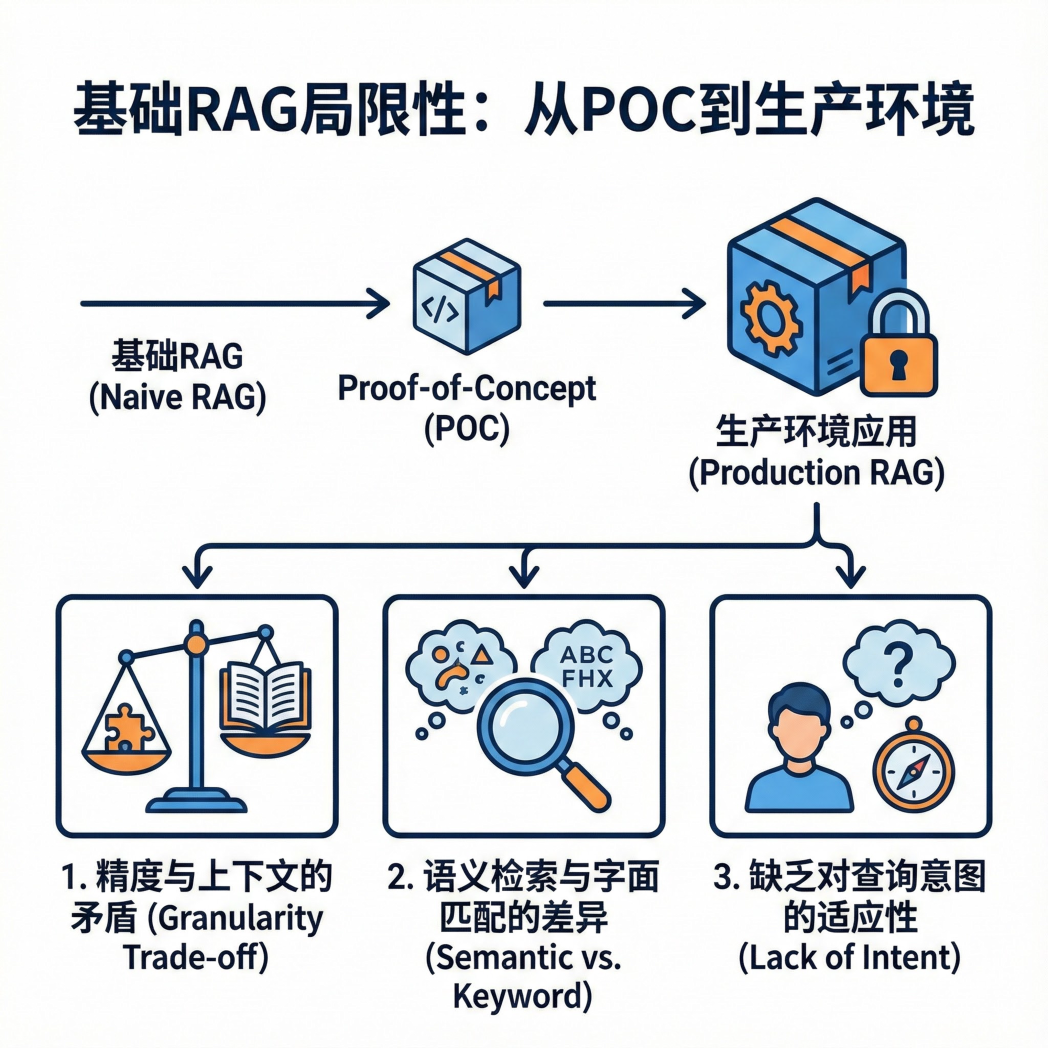
这是无数开发者在构建 RAG(检索增强生成)应用时面临的真实崩溃瞬间。在 POC(概念验证)阶段,基础 RAG 看起来无所不能。然而,一旦面对真实的生产环境——复杂的用户查询、晦涩的行业术语、海量的非结构化数据——基础 RAG 往往瞬间暴露出致命的脆弱性。
从“能用”到“好用”,这中间隔着一道巨大的鸿沟。
传统的 RAG(即“Naive RAG”)通常采用标准化的检索流程:将文档切分为固定大小的块(Chunk),计算向量,然后根据相似度检索出前K个片段。这种通用的处理模式,在面对复杂的真实业务场景时,往往会遭遇三大核心瓶颈:
- 精度与上下文的矛盾 (Granularity Trade-off):
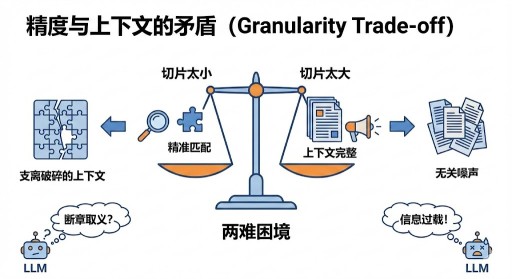
这是一个两难的困境。如果我们将文档切片切得太小,虽然能够精准地匹配用户查询,但提供给大语言模型(LLM)的上下文是支离破碎的,极易导致断章取义的错误回答。
反之,如果切片太大,虽然上下文完整,却导致引入了大量无关噪声,反而降低了与查询的匹配精准度。
- 语义检索与字面匹配的差异 (Semantic vs. Keyword):
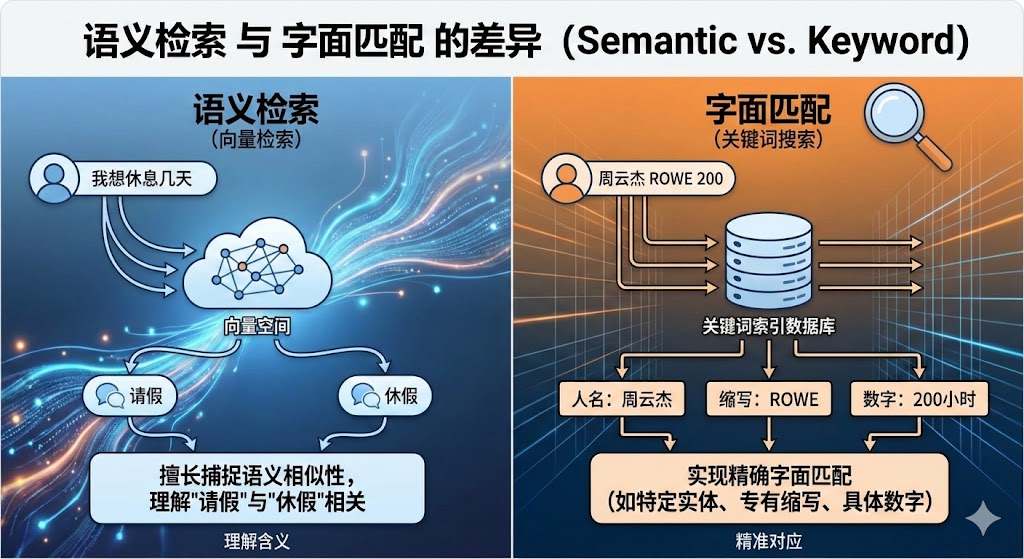
纯粹的向量检索擅长捕捉语义上的相似性,例如能理解“请假”和“休假”是相关的。
但它对于需要精确字面匹配的场景却并不能完美实现,比如特定的实体名称(如人名“周云杰”)、公司内部的专有缩写(如“ROWE”)或具体的数字(如“200小时”),其表现远不如传统的关键词搜索。
- 缺乏对查询意图的适应性 (Lack of Intent):

基础RAG系统对待所有问题都采用相同的处理逻辑。无论用户是想“总结全文”(宏观查询),还是查询“某个具体条款”(微观查询),它都只会执行同一种检索流程。用局部片段去回答宏观总结类问题,其效果通常不尽如人意。
为了系统性地解决这些痛点,Llama-Index框架提供了一系列强大的高级检索策略。本文将深入剖析并实战演练三种突破瓶颈的核心技术:小索引,大窗口 (Small-to-Big Retrieval)、混合检索 (Hybrid Search) 和 智能路由 (Router Query Engine)。掌握它们,正是构建企业级应用的关键所在。
一、 进阶策略一:小索引,大窗口 (Small-to-Big Retrieval)
在RAG系统中,“精度”与“上下文”的矛盾是首要挑战。小索引,大窗口 (Small-to-Big) 策略,又称 Sentence Window Retrieval,正是为解决这一核心痛点而设计的方案。它能够提高检索的精准度,同时保证生成答案时的上下文完整性。
核心思想:检索粒度与生成粒度的分离
该策略的精髓在于,它将用于 “搜索” 的数据单元与最终用于 “生成答案” 的数据单元彻底分离开来。我们用小而精的单位去检索,用大而全的单位去理解和回答。
- 流程示意图

- 实际运行效果展示

How It Works
- 小索引 (Small Index for Retrieval):
系统不再对大段落进行索引,而是将文档切分成极细颗粒度的**“单句”**。在向量库中,我们存储和计算的是这些单句的向量。这样做的好处是,用户的提问能够与最相关的那一句话产生极高的相似度匹配,从而最大限度地减少噪声干扰,提升检索精度。
2. 大窗口 (Big Window for Generation):
单个句子往往缺乏必要的上下文(例如,仅看“否则将被解雇”无法理解其前提条件)。因此,在切分句子的同时,系统会预先将该句子前后相邻的N句话打包成一个“大窗口”,并作为元数据(Metadata)与该句子绑定存储。
3. 元数据替换 (Metadata Replacement):
这是该策略的核心机制。在检索阶段,系统首先精准地找到目标单句。随后,在将信息发送给LLM之前,一个后处理步骤(Post-Processor)会介入,将这个孤立的句子替换为它预先存储好的、包含完整上下文的“大窗口”内容。
代码实战:四步构建高精度检索管道
本文完整实战代码加入 赋范空间 即可免费领取!此外还有更多 Agent、RAG、MCP、模型微调等高阶课程,以及 15+ 企业级项目实战资源等你来拿。
以下代码不仅是简单的API调用,它还包含了一个针对中文环境的关键优化,并展示了Llama-Index中核心的元数据替换机制。
1. 关键设置:自定义中文分词器 (The Chinese Fix)
首先,我们需要解决Llama-Index默认分句器对中文处理不佳的问题。默认工具依赖英文句号.进行切分,这会导致整篇中文文档被错误地识别为一句话,从而引发错误并使检索失效。我们通过一个简单的正则表达式函数来修正此行为。
- 代码解析:
(?<=[。?!\n])是一个正则表达式的“后向断言”,意为“在匹配到中文句号、问号、感叹号或换行符之后的位置进行切分”。这种方式能确保标点符号被完整保留在句子末尾。
import re
from llama_index.core.node_parser import SentenceWindowNodeParser
def chinese_sentence_splitter(text: str):
# 使用正则表达式按中文标点符号切分句子
return re.split('(?<=[。?!\n])', text)
2. 定义窗口解析器 (The Architect)
这是该策略的核心配置,它定义了数据被切分后的最终形态。SentenceWindowNodeParser 是实现这一目标的核心组件。
- 参数解析:
sentence_splitter=chinese_sentence_splitter: 应用我们刚刚定义的中文分词器。window_size=3: 这是策略的关键参数。它指定了以核心句子为中心,向前和向后各取3句话,共同构成一个包含7句话的上下文窗口。window_metadata_key="window": 将构建好的上下文“大窗口”存储在每个节点的 metadata[‘window’] 字段中,以备后续替换使用。
# 创建句子窗口解析器
node_parser = SentenceWindowNodeParser.from_defaults(
sentence_splitter=chinese_sentence_splitter,
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
3. 切分与验证 (Parsing & Validation)
与基础RAG不同,这里我们需要手动执行节点解析,以确保我们的自定义切分策略生效。关键在于,向量化过程是针对单个句子,而非整个上下文窗口,这是保证检索精度的核心。
- 关键点:
VectorStoreIndex(nodes)这一步中,Embedding模型计算的是 node.text(即单句)的向量,而不是元数据中的“大窗口”。
# 从文档中获取节点
nodes = node_parser.get_nodes_from_documents(documents)
# 构建索引(此时向量化的是单个句子)
index = VectorStoreIndex(nodes)
4. 引擎构建与元数据替换 (The Magic Swap)
最后,我们构建查询引擎,并配置实现元数据替换的后处理器 MetadataReplacementPostProcessor。
- 参数解析:
similarity_top_k=5: 由于我们检索的是信息量较小的单个句子,因此检索稍多一些的结果(Top 5)有助于确保覆盖足够的信息。MetadataReplacementPostProcessor(target_metadata_key="window"): 这是核心机制。它在检索完成后,自动将每个节点的 node.text 内容替换为其 metadata[‘window’] 中存储的“大窗口”文本,然后再发送给LLM。
# 构建后处理器
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
# 构建查询引擎
query_engine = index.as_query_engine(
similarity_top_k=5,
node_postprocessors=[postproc],
)
端到端工作流
总结一下,整个流程如下:
- 原始文档 → 中文切分 \xrightarrow{中文切分} 中文切分 孤立句子
- 孤立句子 → W i n d o w P a r s e r \xrightarrow{WindowParser} WindowParser 包含上下文元数据的句子节点
- 索引阶段 → \rightarrow → 只对 “句子” 做向量化(为了搜得准)
- 检索阶段 → \rightarrow → 搜到了 “句子”
- 处理阶段 → P o s t P r o c e s s o r \xrightarrow{PostProcessor} PostProcessor 替换为包含完整上下文的文本窗口
- 生成阶段 → \rightarrow → LLM 阅读 “大窗口” 并回答(为了看得全)
效果对比
❓ 提问: Q1: 我想周末和春节都来公司加班多赚点钱,工资分别怎么算?我一年最多能加多少小时班,有没有封顶?
| 🤖 普通 RAG (Baseline) | 🚀 进阶 RAG (Small-to-Big) |
|---|---|
| 公司不强制安排无偿加班,员工可以根据项目安排与主管协商加班事宜。对于加班工资的计算,具体的金额和计算方式未在手册中详细说明。至于一年最多能加多少小时班以及是否有封顶,手册中并未提供相关信息,建议与主管或人力资源部门进行进一步咨询以获取详细规定。 | 周末加班的工资是按基本工资的2倍补偿,或者可以选择以调休形式折算。春节属于法定节假日,加班工资按基本工资的3倍支付。年度个人加班时间最多为200小时,超过部分需要部门总监审批并报备HR。 |
❓ 提问: Q2: 我还在试用期,最近家里有事想请半个月(15天)的假,按规定可以请吗?会不会影响我转正?
| 🤖 普通 RAG (Baseline) | 🚀 进阶 RAG (Small-to-Big) |
|---|---|
| 在试用期内请假通常需要遵循公司的请假规定。如果您有正当理由,可以向人力资源部门申请假期。请假是否会影响转正,通常取决于公司的具体政策和您在试用期内的表现。建议您与直接上级或人力资源部门沟通,了解请假对转正的具体影响。 | 在试用期内,你可以请假,包括病假、事假、婚假等法定假期。然而,如果累计请假超过10个工作日,试用期考核结果可能会受到影响。因此,请半个月(15天)的假可能会影响你的转正。 |
通过"小索引,大窗口"策略,我们成功解决了精度与上下文的矛盾。然而,系统在处理特定关键词和专有名词时仍然存在盲区,这正是我们下一节要解决的问题。
二、 进阶策略二:混合检索 (Hybrid Search)
在解决了上下文完整性的问题后,我们面临第二个挑战:纯向量检索的“语义盲区”。它擅长理解“意思”,却不擅长匹配“字面”。当用户查询特定的错误码、人名或专有缩写时,纯向量模型常常会“张冠李戴”。混合检索 (Hybrid Search) 策略通过将两种不同的搜索范式相结合,完美解决了这个问题。
核心思想:双路召回与加权融合
混合检索的核心是“双路召回”,同时利用语义检索和传统关键词检索,并通过智能算法将两者的优势结果融合在一起。
- 流程示意图
- 实际运行效果展示

- 链路 A:稠密向量检索 (Dense Retrieval):
- 角色: 语义检索模块。
- 机制: 使用Embedding模型将文本和查询转化为高维向量,通过计算向量空间的距离来理解语义、意图和概念关联。
- 强项: 处理模糊查询、同义词匹配和概念理解。
- 链路 B:稀疏关键词检索 (Sparse Retrieval / BM25):
- 角色: 关键词检索模块。
- 机制: 基于经典的TF-IDF算法演进而来的BM25算法,不关心语义,只关心关键词是否在文档中高频出现且在整个文档库中较为稀有。
- 强项: 精准捕捉和匹配生僻词、专有名词、人名、ID和缩写。
- 融合机制:倒数排名融合 (Reciprocal Rank Fusion, RRF):
- 角色: 排序融合算法。
- 机制: 由于向量检索的相似度分数和BM25的分数无法直接比较,RRF算法不看具体分数,只看排名。它会综合一个文档在两条检索链路中的排名情况,给出一个最终的融合排序,排名越靠前的文档权重越高。
代码实战:组装混合检索引擎
以下代码展示了如何将关键词检索(BM25)与向量检索结合,并通过RRF算法实现更优的检索效果。代码开头还包含了一段处理版本兼容性的技巧。
1. 自动侦测与版本适配 (The Compatibility Fix)
Llama-Index框架迭代迅速,为了确保代码在不同版本间都能正常运行,我们首先编写一段兼容性代码。它通过Python的 inspect(反射)模块,动态检测当前环境的FusionMode是字符串类型还是枚举类型,从而避免因版本升级导致代码崩溃。
import inspect
from llama_index.core.retrievers import QueryFusionRetriever
# 动态适配 Llama-Index v0.10.x+ 的 FusionMode 枚举类型
fusion_mode_enum_path = "llama_index.core.retrievers.FusionMode"
try:
# 尝试导入枚举类
module_name, class_name = fusion_mode_enum_path.rsplit(".", 1)
module = __import__(module_name, fromlist=[class_name])
FusionMode = getattr(module, class_name)
RECIPROCAL_RANK = FusionMode.RECIPROCAL_RANK
except (ImportError, AttributeError):
# 如果失败,则回退到旧版的字符串模式
RECIPROCAL_RANK = "reciprocal_rank"
2. 创建双路检索器 (Two-Stream Retrievers)
接下来,我们为两条检索链路分别创建检索器,分工明确。
VectorIndexRetriever:负责理解查询的深层含义。BM25Retriever:负责精准锁定字面上的关键词。- 注意: 必须为
BM25Retriever传入tokenizer=chinese_tokenizer,否则它会把整句中文当成一个单词,导致关键词匹配失效。
from llama_index.retrievers.bm25 import BM25Retriever
# 创建向量检索器
vector_retriever = index.as_retriever(similarity_top_k=5)
# 创建 BM25 检索器
bm25_retriever = BM25Retriever.from_defaults(
nodes=nodes,
tokenizer=chinese_tokenizer,
similarity_top_k=5,
)
3. 融合与引擎组装 (The Fusion Core)
最后,我们使用 QueryFusionRetriever 作为核心控制器,将两个检索器融合在一起,并指定使用RRF算法。
- 核心组件:
QueryFusionRetriever负责接收用户查询,并将其同时分发给内部的多个检索器。 - 融合算法:
mode=RECIPROCAL_RANK明确指示使用倒数排名融合算法。该算法会根据文档在向量和BM25两路结果中的排名进行智能重排,最终生成一个既包含语义相关性又包含字面精准性的最优结果列表。
# 创建融合检索器
retriever = QueryFusionRetriever(
[vector_retriever, bm25_retriever],
mode=RECIPROCAL_RANK,
)
# 构建查询引擎
hybrid_engine = RetrieverQueryEngine.from_args(
retriever=retriever
)
效果对比:精准锁定专有名词
❓ 提问: Q1: 请问法务合规部的负责人是谁?我想发邮件给他,邮箱是多少?
| 🤖 普通 RAG (Vector Only) | 🚀 进阶 RAG (Hybrid: Vector + BM25) |
|---|---|
| 抱歉,无法提供法务合规部负责人的姓名和邮箱信息。建议您通过公司内部通讯录或联系相关部门获取详细信息。 | 法务合规部的负责人是周云杰,您可以通过邮箱 legal@innovatech.cn 联系他。 |
❓ 提问: Q2: 如果我遇到紧急情况需要心理支持,公司有没有专门的援助热线?具体的电话号码是多少?
| 🤖 普通 RAG (Vector Only) | 🚀 进阶 RAG (Hybrid: Vector + BM25) |
|---|---|
| 公司员工手册中没有提到专门的心理支持援助热线或具体电话号码。建议联系公司的人力资源部门或查看员工门户以获取更多信息。 | 公司没有提供专门的心理支持援助热线的具体电话号码。不过,员工在遭遇紧急事件时可以拨打公司应急热线,具体号码分部门张贴,或者通过企业IM标记“#紧急”发布信息,系统会自动通知相关部门进行响应。 |
混合检索让我们的RAG系统同时具备了理解语义和识别关键词的能力。但它仍然是以同一种流程处理所有问题,这在面对意图差异巨大的用户查询时效率不高。下一节,我们将为系统引入智能决策机制。
觉得文章太干想动手实操?加入 赋范空间 免费获取完整源码及环境配置指南。我们还提供 Agent、RAG、MCP、模型微调等全栈 AI 课程及 15+ 实战项目!
三、 进阶策略三:智能路由 (Router Query Engine)
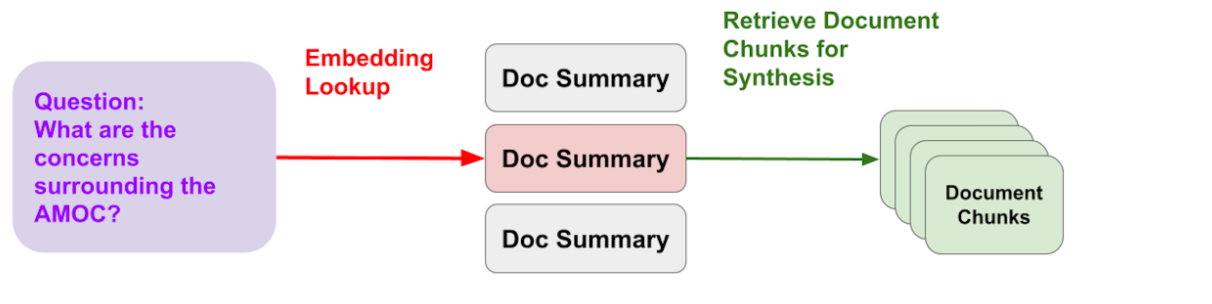
传统的RAG架构存在一个“宏观与微观的冲突”:为回答总结性问题而优化的系统,在处理细节查询时会浪费资源;而为快速查询细节优化的系统,又无法应对宏观概括类问题。智能路由 (Router Query Engine) 的引入,标志着RAG系统从“自动化”向“智能体(Agent)”架构的演进。它不再机械地执行单一流程,而是具备了意图识别与动态分发能力。
核心思想:引入前置决策层
智能路由策略的核心在于用户提问和数据索引之间构建了一个决策层。它能根据用户的问题将其引导至最合适的检索引擎。
- 流程示意图
- 实际运行效果展示
- 构建多元工具箱 (Building a Diverse Toolbox): 我们不再依赖单一的索引,而是针对不同任务类型构建多个专门的索引,并将它们封装为可供调度的“工具(Tools)”。
- 工具 A (向量工具): 基于
VectorStoreIndex,擅长通过语义相似度进行点对点的细节查询,如查找具体条款或数据。 - 工具 B (摘要工具): 基于
SummaryIndex,擅长遍历整个文档并构建树状摘要,适用于回答总结、概括等宏观问题。
- 工具 A (向量工具): 基于
- 路由选择器 (LLM Selector): 这是系统的决策组件。当用户问题输入时,一个LLM会作为“选择器”或“路由器”,首先分析问题的意图,然后仔细阅读每个工具的功能描述(Description),最终动态地决定将问题派发给哪个(或哪些)最合适的工具。
代码实战:实现动态路由逻辑
以下代码展示了如何将两个功能迥异的检索引擎——一个用于查细节(Vector),一个用于查全貌(Summary)——封装成工具,并训练系统根据用户问题自动选择最合适的一个。
1. 定义工具:定义查询工具 (The Tools)
在路由模式下,索引不能直接被使用,必须先封装成 QueryEngineTool。这一步的关键在于为每个工具编写一个高质量的描述。
- 至关重要的 description: 这个参数用于指导 LLM 进行路由选择的描述。路由器内部的LLM会仔细阅读这段描述,来判断该工具的功能是否与当前用户的问题相匹配。描述写得越精准、越清晰,路由的准确率就越高。
from llama_index.core.tools import QueryEngineTool
# 创建向量查询工具
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description="适用于查询具体信息、事实、数字和特定条款。",
)
# 创建摘要查询工具
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description="适用于需要对整个文档进行总结、概括或获取宏观视图的问题。",
)
2. 定义摘要工具与合成策略 (The Summary Strategy)
为了有效处理总结类问题,我们选用 SummaryIndex。它与向量索引不同,能够遍历文档的全部内容,从而生成全局性的摘要。
response_mode="tree_summarize"(树状总结): 这是处理长文档总结的利器。当文档过长时,它会先将文档分块并分别生成小结(叶子节点),然后将这些小结再进行总结(父节点),如此递归,最终形成一个覆盖全篇内容的、高质量的顶层摘要。
from llama_index.core import SummaryIndex
# 创建摘要索引
summary_index = SummaryIndex(nodes)
# 创建摘要查询引擎,使用树状总结模式
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True, # 异步执行以提升性能
)
3. 构建选择器与路由引擎 (The Brain & Body)
最后,我们使用 LLMSingleSelector 作为决策者,并组装成最终的 RouterQueryEngine。
LLMSingleSelector(决策者): 它本质上是一个小型的分类器。接收用户问题和所有工具的描述作为输入,然后输出它认为最匹配的一个工具的名称。verbose=True(调试模式): 在开发和调试阶段,开启此选项非常有用。它会在控制台打印出路由器的“思考过程”,例如Selecting query engine 0: ...,让我们能直观地验证路由逻辑是否按预期工作。
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.query_engine import RouterQueryEngine
# 创建选择器
selector = LLMSingleSelector.from_defaults()
# 创建路由查询引擎
router_query_engine = RouterQueryEngine.from_defaults(
selector=selector,
query_engine_tools=[vector_tool, summary_tool],
verbose=True, # 开启详细日志
)
端到端执行逻辑
整体执行流程如下:
-
用户提问 A (宏观): “请总结一下公司的福利政策。”
- Router (Selector) 分析: 阅读问题,对比工具描述。
- 工具A描述:“查具体信息、事实、数字…” -> 与问题不太匹配。
- 工具B描述:“总结、概括、宏观视图…” -> 与问题高度匹配!
- 分发任务: 选择器决定将问题分发给
summary_tool。 - 执行任务:
summary_query_engine启动tree_summarize模式,遍历文档内容生成一份全面的福利总结。 - 返回结果: 用户得到一份完整的福利概览。
- Router (Selector) 分析: 阅读问题,对比工具描述。
-
用户提问 B (微观): “健身房补贴是多少钱?”
- Router (Selector) 分析: 阅读问题,对比工具描述。
- 工具A描述:“查具体信息、事实、数字…” -> 与问题高度匹配!
- 工具B描述:“总结、概括、宏观视图…” -> 与问题不太匹配。
- 分发任务: 选择器决定将问题分发给
vector_tool。 - 执行任务:
vector_query_engine执行标准的Top-K向量检索,精准定位包含补贴金额的文本片段。 - 返回结果: 用户得到具体数字“2000元”。
- Router (Selector) 分析: 阅读问题,对比工具描述。
效果对比
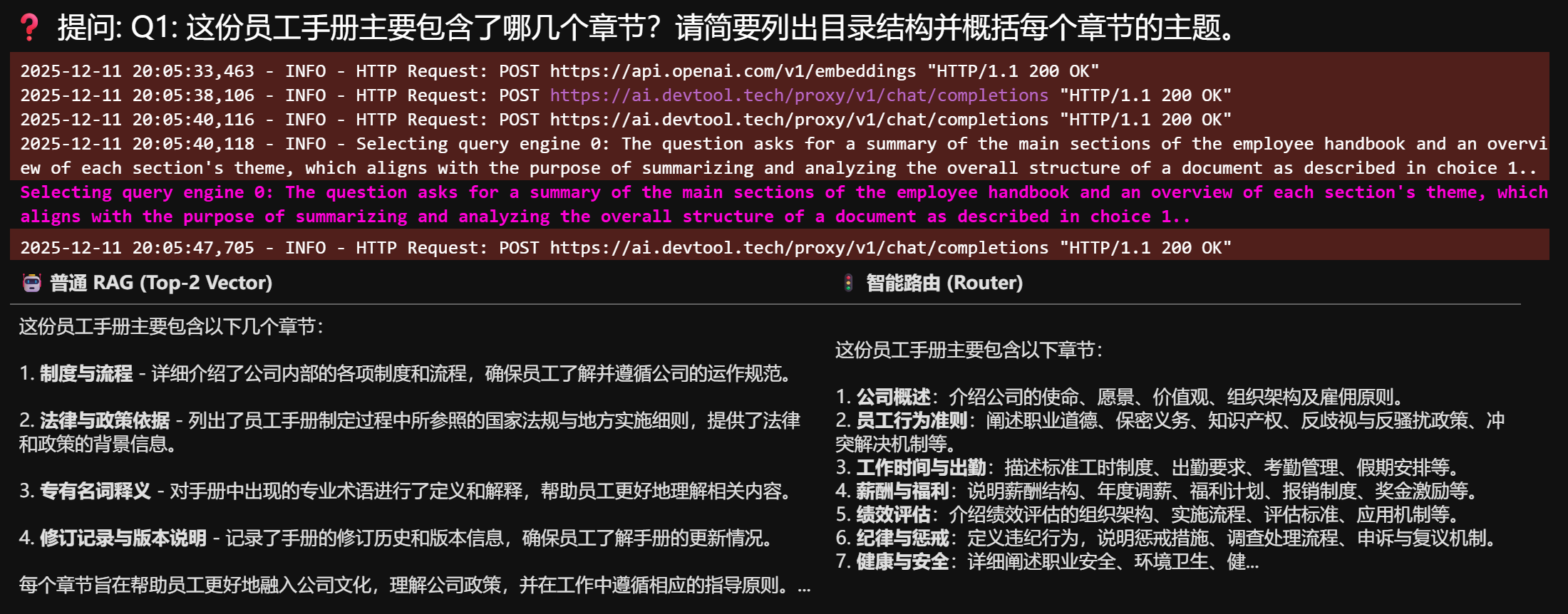
❓ 提问: Q1: 这份员工手册主要包含了哪几个章节?请简要列出目录结构并概括每个章节的主题。
| 🤖 普通 RAG (Top-2 Vector) | 🚦 智能路由 (Router) |
|---|---|
| 这份员工手册主要包含以下几个章节: 1. 制度与流程 - 详细介绍了公司内部的各项制度和流程,确保员工了解并遵循公司的运作规范。 2. 法律与政策依据 - 列出了员工手册制定过程中所参照的国家法规与地方实施细则,提供了法律和政策的背景信息。 3. 专有名词释义 - 对手册中出现的专业术语进行了定义和解释,帮助员工更好地理解相关内容。 4. 修订记录与版本说明 - 记录了手册的修订历史和版本信息,确保员工了解手册的更新情况。 每个章节旨在帮助员工更好地融入公司文化,理解公司政策,并在工作中遵循相应的指导原则。… | 这份员工手册主要包含以下章节: 1. 公司概述 :介绍公司的使命、愿景、价值观、组织架构及雇佣原则。 2. 员工行为准则 :阐述职业道德、保密义务、知识产权、反歧视与反骚扰政策、冲突解决机制等。 3. 工作时间与出勤 :描述标准工时制度、出勤要求、考勤管理、假期安排等。 4. 薪酬与福利 :说明薪酬结构、年度调薪、福利计划、报销制度、奖金激励等。 5. 绩效评估 :介绍绩效评估的组织架构、实施流程、评估标准、应用机制等。 6. 纪律与惩戒 :定义违纪行为,说明惩戒措施、调查处理流程、申诉与复议机制。 7. 健康与安全 :详细阐述职业安全、环境卫生、健… |
❓ 提问: Q2: 公司提供哪些类型的现金补贴?请列举并说明金额。
| 🤖 普通 RAG (Top-2 Vector) | 🚦 智能路由 (Router) |
|---|---|
| 公司的健身房补贴每年最高为2000元。其他具体的现金补贴项目在检索到的文档片段中未详细说明。 | 公司提供的现金补贴包括: 1. 健身房补贴:每年最高报销2000元。 2. 交通补贴:对于晚上9点后下班的员工,提供实报实销的出租车费补贴。 3. 餐饮补贴:每个工作日提供30元的午餐补助。 4. 通讯补贴:根据岗位职级,每月提供100-500元不等的手机话费补贴。 |
通过组合这些先进策略,我们已经能够构建出真正智能化的RAG系统,为迎接更复杂的挑战做好了准备。
总结:构建企业级 RAG 架构
本文带领我们完成了一次从基础RAG到高级RAG架构的认知升级之旅。我们首先剖析了传统“Top-K”检索模式在精度、关键词匹配和意图理解三个方面的核心瓶颈,这些瓶颈正是阻碍RAG应用落地的瓶颈。
随后,我们通过Llama-Index提供的三种强大策略,逐一攻克了这些难题:
- 小索引,大窗口 (Small-to-Big) 策略通过分离检索与生成粒度,完美解决了精度与上下文的矛盾。
- 混合检索 (Hybrid Search) 策略通过结合向量与关键词检索,弥补了语义检索在处理专有名词时的不足。
- 智能路由 (Router Query Engine) 则为系统引入了决策机制,使其能够根据用户意图,智能地选择最合适的处理路径,解决了宏观与微观查询的冲突。
掌握并灵活运用这些高级策略,是构建能够应对复杂、多变的真实世界企业级挑战的关键。这不仅仅是技术的堆砌,更是架构思想的跃迁。通过这种方式构建的RAG系统,才能真正提升为具备深度理解和智能决策能力的企业级应用。

















 1305
1305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









