



前言:多模态RAG的技术价值与应用前景
随着人工智能技术的快速发展,传统的文本检索增强生成(RAG)已经无法满足现代企业对多媒体信息处理的需求。多模态RAG作为下一代智能信息系统的核心技术,能够同时理解和处理文本、图像、音频等多种数据类型,为企业数字化转型提供了强大的技术支撑。
本文将通过一个完整的实战项目,深入探索如何构建一个基于多模态RAG的CAD图纸智能问答系统。在工业制造、建筑设计、房地产等领域,技术图纸是核心资产,但传统的管理方式存在诸多痛点:
- 检索效率低:需要人工逐一查看图纸,耗时费力
- 信息孤岛:图纸中的结构化信息难以提取和利用
- 专业门槛高:非专业人员难以快速理解图纸内容
- 知识传承难:专家经验难以标准化和传承
我们将从零开始,逐步构建一个能够"读懂"CAD图纸、自动提取关键信息、并智能回答用户问题的系统,来实现了从图像理解到知识检索的全链路智能化。
系统架构概览
本系统采用模块化设计,核心技术栈包括:
第一步:接入VLM模型
↓
第二步:解析本地CAD图片
↓
第三步:提取结构化元数据
↓
第四步:存入向量数据库
↓
第五步:智能问答(直接问答 + 图像检索)
- 处理图片示例
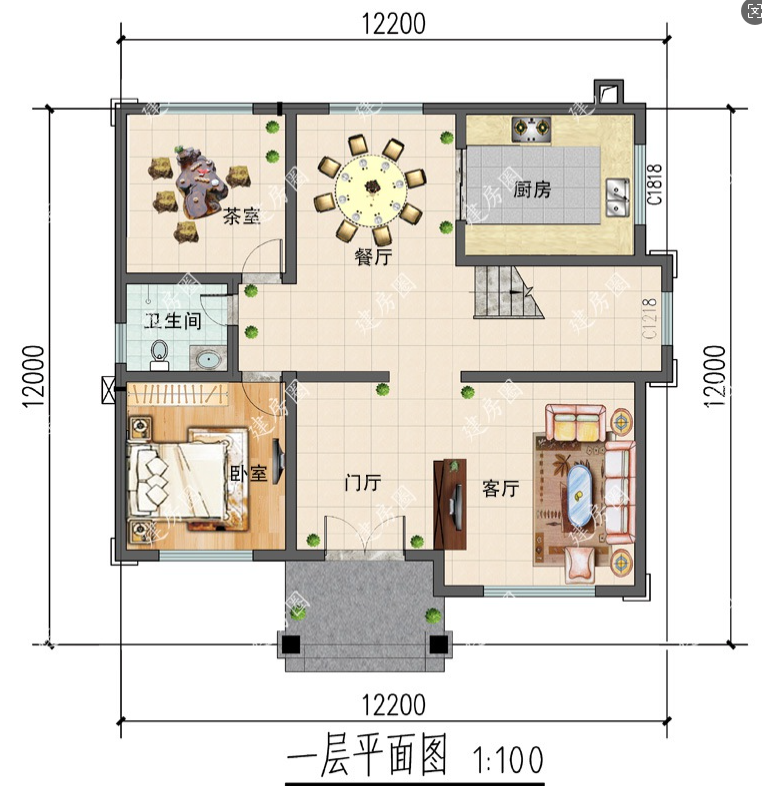
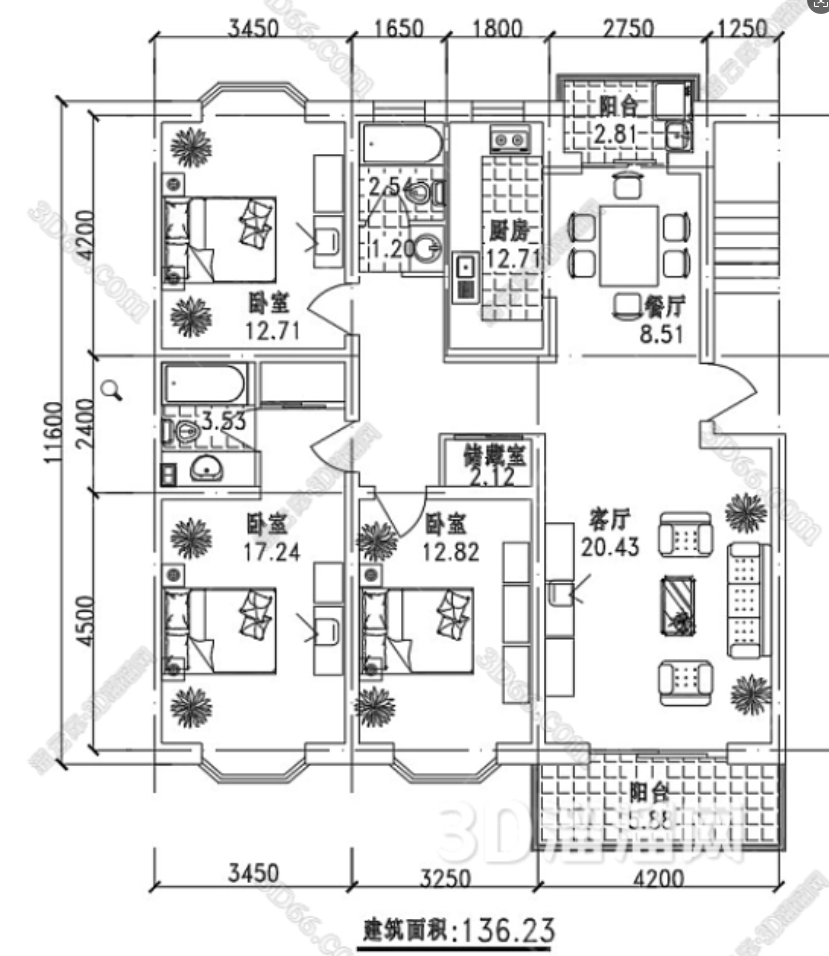
核心功能一:支持在线上传并自动解析多模态PDF及CAD、工程图纸和复杂架构原型图;
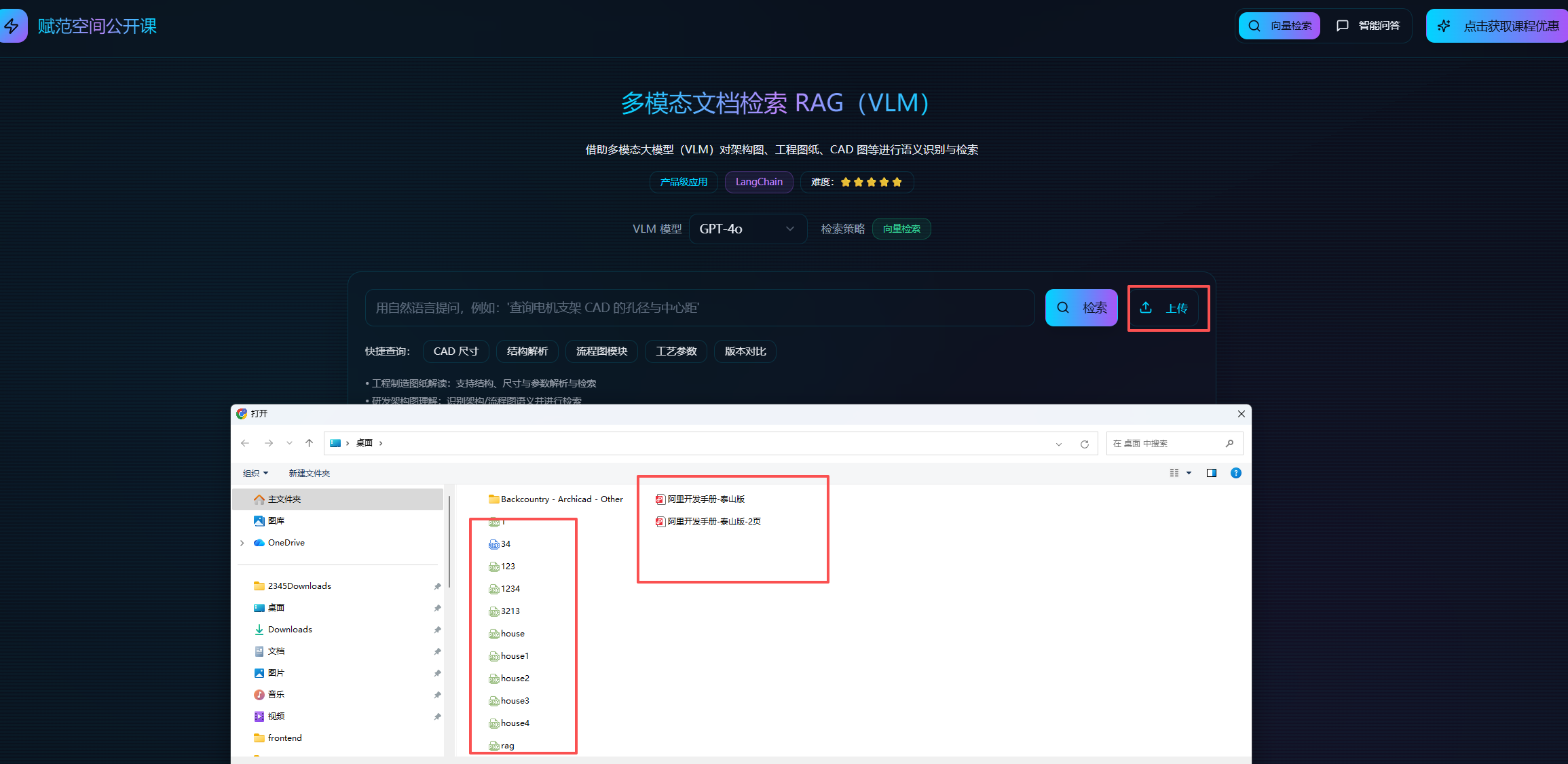
核心功能二:通过自然语言问答,直接检索图片原型及文档原件,并支持溯源和在线预览,实现“以文搜图”、“以图搜图”;
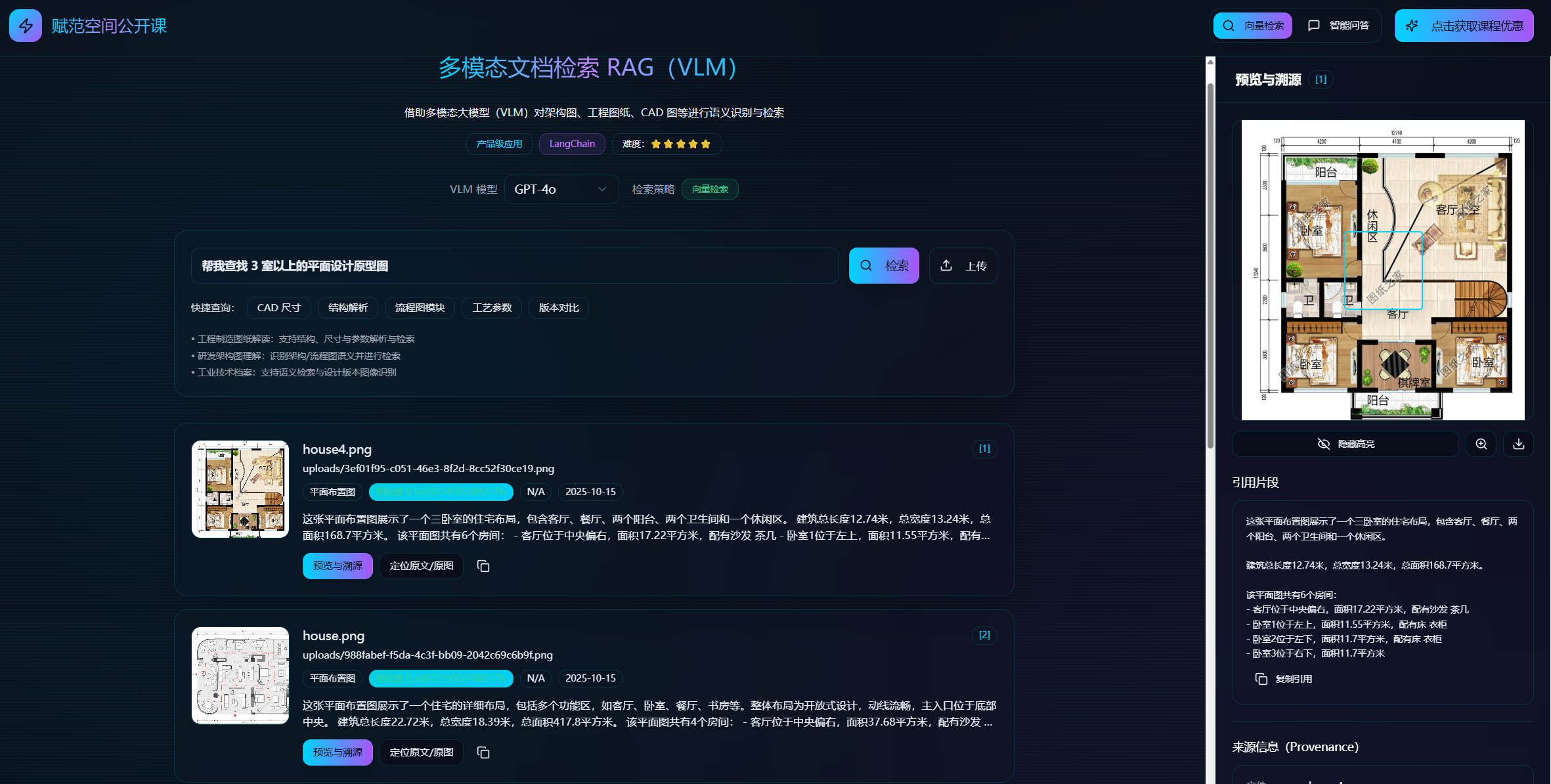
核心功能三:支持实时上传多模态PDF及CAD、工程图纸和复杂架构原型图,并直接对文件内容进行提问,实现“以文搜文”;
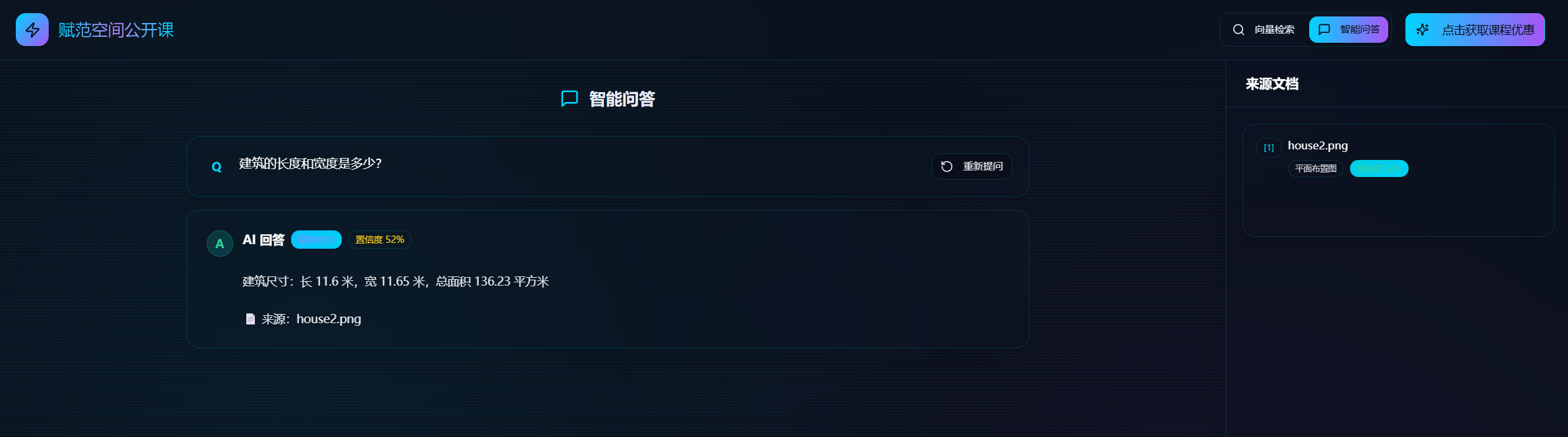
这套系统可以直接应用于:
- 房地产销售:快速回答客户关于户型的问题(“有几个卧室?”、“主卧面积多大?”)
- 室内设计:分析户型优缺点,提供设计建议
- 智能选房:根据用户需求(如"3室2厅,面积100平以上")自动筛选户型
- 户型对比:智能对比多个户型的优劣
同时,只要针对性的修改提示词,即可快速迁移到其他的图像分析场景。
5.1 环境准备与依赖安装
首先,我们需要安装必要的Python包。这个系统的核心依赖包括:
openai:用于调用多模态大模型APIchromadb:向量数据库,用于存储和检索langchain:RAG框架的核心组件Pillow:图像处理库
# 安装依赖(如果需要)
# !pip install openai chromadb langchain langchain-community langchain-openai Pillow python-dotenv -q
# 导入必要的库
import os
import json
import base64
import io
from pathlib import Path
from typing import Dict, Any, List
from PIL import Image
from dataclasses import dataclass
import sys
# 添加项目路径(使用绝对路径)
project_root = Path(__file__).parent if '__file__' in globals() else Path.cwd()
backend_path = project_root / "backend"
if str(backend_path) not in sys.path:
sys.path.insert(0, str(backend_path))
# OpenAI SDK
from openai import OpenAI
# LangChain 组件
from langchain.text_splitter import RecursiveCharacterTextSplitter
from qwen_embeddings import QwenEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain_openai import ChatOpenAI
上述代码中,导入了构建多模态RAG系统所需的所有核心库:
openai:提供了与gpt-4o等视觉语言模型交互的接口chromadb相关:通过langchain_community.vectorstores.Chroma实现向量存储HuggingFaceEmbeddings:用于将文本转换为向量表示PIL.Image:处理图像文件的加载和转换
至此,我们的环境已经准备完毕,接下来就开始真正的系统构建。
5.2 接入视觉语言模型(VLM)
多模态RAG的核心能力来自于视觉语言模型(Vision-Language Model, VLM)。这类模型能够同时理解图像和文本,对于CAD图纸这种技术图像来说,VLM可以识别其中的结构、尺寸标注、技术参数等关键信息。
本课程中,我们使用 gpt-4o 作为VLM模型。首先,我们需要配置API密钥和模型接入点。需要配置三个关键参数:
API_KEY:你的OpenAI API密钥(或兼容的API服务密钥)BASE_URL:API服务的基础URLMODEL_NAME:使用的模型名称(这里是gpt-4o)
提示:如果你使用的是OpenAI官方API,
BASE_URL设置为https://api.openai.com/v1即可。
from dotenv import load_dotenv
# ========== VLM 模型配置 ==========
MODEL_NAME = "gpt-4o"
load_dotenv(override=True)
# 初始化 OpenAI 客户端
vlm_client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL")
)
这段代码创建了一个 OpenAI 客户端实例,这是我们与视觉语言模型交互的桥梁。通过这个客户端,我们后续可以发送图像和问题给模型,并接收模型的分析结果。
接下来,我们需要构建一个CAD图纸分析器,它能够将图像转换为模型可以理解的格式,并调用VLM进行智能分析。
5.3 构建CAD图纸分析器
多模态RAG的核心能力来自于视觉语言模型(VLM)。对于室内平面图来说,VLM需要能够识别:
- 房间布局和功能区划分
- 尺寸标注和面积计算
- 门窗位置和开启方向
- 家具布置和空间利用
- 动线设计和连通关系
在实际应用中,针对不同类型的图纸(CAD、平面图、架构图等),我们需要设计不同的提示词模板,以获得最佳的分析效果。
@dataclass
class AnalysisResult:
"""图像分析结果数据类"""
answer: str # VLM的回答
extracted_info: Dict[str, Any] # 提取的结构化信息
raw_response: str # 原始响应内容
class FloorPlanAnalyzer:
"""室内平面图分析器"""
# 平面图专业提示词模板
FLOOR_PLAN_PROMPT = """你是一位专业的建筑/室内平面图分析专家。请仔细分析这张室内平面布置图。
**用户问题:**
{question}
**重要说明:**
- 这是一张室内平面布置图,包含房间、尺寸标注、家具布置、动线等信息
- 图中尺寸单位通常为毫米(mm)或米(m),请根据数值大小推断
- 请仔细识别所有可见的房间、标注、符号和空间关系
**分析维度(根据用户问题选择性回答):**
1. **房间/功能区识别**:
- 识别所有房间名称(客厅、卧室、厨房、卫生间、阳台等)
- 标注每个房间的位置(左上/右下/中央等方位)
- 识别特殊功能区(储藏室、玄关、衣帽间等)
2. **尺寸与面积**:
- 提取图中所有可见尺寸标注
- 推断单位并统一换算为米(m)
- 计算房间的长、宽、面积
- 标注整体平面外墙尺寸
3. **符号与标注**:
- 解释符号含义(虚线、箭头、红点/红线、轴线等)
- 识别文字标注(房间编号、面积、备注)
- 说明墙体类型、门窗位置和开启方向
4. **家具布局**:
- 列出所有可见家具及其位置
- 判断空间利用率(拥挤/适中/空旷)
- 识别家具尺寸
5. **动线与连通性**:
- 标出主入口、次入口位置
- 描述主要动线路径(如:"入口→玄关→客厅→...")
- 列出房间连通关系(哪些房间相连)
- 判断布局类型(开放式/分隔式)
6. **设计评估**(如果问题涉及):
- 动线合理性、是否有绕行或死角
- 采光/朝向分析
- 空间优化建议
**回答方式:**
- 首先直接、简洁地回答用户的具体问题
- 然后提供相关的详细信息(如果用户问某个房间,重点描述该房间)
- 如果用户问整体布局,提供全局分析
- 如果涉及尺寸计算,请说明推理过程(如:"标注22720mm = 22.72m")
**输出格式(JSON):**
{{
"answer": "直接回答用户问题的核心内容(简洁明了)",
"extracted_info": {{
"total_dimensions": {{
"length": 22.72,
"width": 12.5,
"unit": "m",
"total_area": 284.0
}},
"rooms": [
{{
"name": "客厅",
"position": "中央偏右",
"dimensions": {{"length": 5.79, "width": 4.2, "area": 24.3, "unit": "m"}},
"furniture": ["沙发", "茶几"],
"connected_to": ["餐厅", "卧室1"],
"windows": 2,
"doors": 1
}}
],
"annotations": [
{{"type": "dimension", "value": "22720", "parsed_value": 22.72, "unit": "m", "description": "外墙总长"}}
],
"symbols": [
{{"type": "door", "count": 5, "positions": ["客厅-餐厅", "卧室1入口"]}}
],
"circulation": {{
"main_entrance": "底部中央",
"main_path": "主入口 → 玄关 → 客厅 → 餐厅",
"layout_type": "开放式客餐厅"
}},
"design_notes": ["主卧带独立卫生间", "动线流畅"]
}}
}}
**注意事项:**
- 如果标注不清晰,标注为"不可读"或给出估算值并说明
- 优先回答用户的具体问题,不要罗列所有信息
- 如果用户问"有几个卧室",就重点回答卧室数量和位置
- 如果用户问"客厅面积",就重点回答客厅的尺寸和面积
- 保持答案简洁、针对性强"""
def __init__(self, client: OpenAI, model_name: str):
"""初始化分析器"""
self.client = client
self.model_name = model_name
def load_image(self, image_path: str) -> Image.Image:
"""加载本地图片"""
image_path = Path(image_path)
if not image_path.exists():
raise FileNotFoundError(f"图片文件不存在: {image_path}")
image = Image.open(image_path)
print(f"图片加载成功: {image.size}")
return image
def image_to_base64(self, image: Image.Image, max_size: int = 2000) -> str:
"""将PIL Image转换为base64字符串"""
# 如果图片过大,进行压缩
if image.width > max_size or image.height > max_size:
image = image.copy()
image.thumbnail((max_size, max_size), Image.Resampling.LANCZOS)
print(f"图片已压缩到: {image.size}")
# 转换为JPEG格式的base64
buffer = io.BytesIO()
if image.mode == 'RGBA':
image = image.convert('RGB')
image.save(buffer, format='JPEG', quality=85)
buffer.seek(0)
base64_str = base64.b64encode(buffer.read()).decode('utf-8')
print(f"图片转换为base64: {len(base64_str) / 1024:.1f} KB")
return base64_str
def analyze(self, image_path: str, question: str) -> AnalysisResult:
"""
分析平面图
Args:
image_path: 图片路径
question: 用户问题
Returns:
AnalysisResult对象
"""
# 1. 加载图片
image = self.load_image(image_path)
# 2. 转换为base64
image_base64 = self.image_to_base64(image)
# 3. 构建提示词
prompt = self.FLOOR_PLAN_PROMPT.format(question=question)
# 4. 调用VLM API
print("正在调用VLM模型...")
messages = [
{
"role": "system",
"content": "你是一位专业的建筑平面图分析专家。请仔细分析图像并按照要求的JSON格式返回结果。"
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_base64}"
}
},
{
"type": "text",
"text": prompt
}
]
}
]
response = self.client.chat.completions.create(
model=self.model_name,
messages=messages,
max_tokens=4096,
temperature=0.1,
response_format={"type": "json_object"}
)
# 5. 解析响应
content = response.choices[0].message.content
parsed = self._parse_json_response(content)
print(f"分析完成!Token使用: {response.usage.total_tokens}")
print("="*60 + "\n")
return AnalysisResult(
answer=parsed.get('answer', ''),
extracted_info=parsed.get('extracted_info', {}),
raw_response=content
)
def _parse_json_response(self, content: str) -> Dict[str, Any]:
"""解析JSON响应"""
try:
# 清理可能的markdown代码块标记
content = content.strip()
if content.startswith('```json'):
content = content[7:]
elif content.startswith('```'):
content = content[3:]
if content.endswith('```'):
content = content[:-3]
content = content.strip()
return json.loads(content)
except json.JSONDecodeError as e:
print(f"JSON解析失败: {e}")
return {
'answer': content,
'extracted_info': {}
}
# 创建平面图分析器
analyzer = FloorPlanAnalyzer(vlm_client, MODEL_NAME)
这段代码是平面图分析系统的核心。让我们理解几个关键点:
1. 提示词针对平面图优化
平面图的提示词更加注重:
- 房间识别:客厅、卧室、厨房等功能区
- 尺寸推断:自动判断单位是mm还是m(如22720mm→22.72m)
- 动线分析:入口→玄关→客厅的流动路径
- 空间关系:房间之间的连通性和位置关系
2. 结构化输出的重要性
输出的JSON结构包含了完整的户型元数据:
total_dimensions:整体尺寸和总面积rooms:每个房间的详细信息(名称、位置、面积、家具)circulation:动线设计和布局类型design_notes:设计特点和建议
这些结构化信息将成为后续智能问答的核心数据源!
5.4 测试平面图分析
接下来让我们测试分析器的功能。
提示:请准备一张平面图(户型图),替换下面的路径后运行。
# ========== 测试平面图分析 ==========
# 指定平面图路径(请替换为你的平面图路径)
FLOOR_PLAN_PATH = "./test_data/house1.png" # 示例路径
# 用户问题
USER_QUESTION = "请详细分析这张平面图,包括房间布局、尺寸面积、动线设计等信息。"
# 执行分析
result = analyzer.analyze(FLOOR_PLAN_PATH, USER_QUESTION)
# 显示分析结果
print(result.answer)
print("\n【提取的结构化元数据】")
print(json.dumps(result.extracted_info, ensure_ascii=False, indent=2))
✓图片加载成功: (900, 781)
图片转换为base64: 130.5 KB
正在调用VLM模型...
分析完成!Token使用: 2492
============================================================
这张平面图展示了一套三居室的住宅布局,包含客厅、主卧、次卧、儿童房、厨房、主卫、次卫、餐厅和入户玄关等功能区。整体布局紧凑,动线合理,适合家庭居住。
【提取的结构化元数据】
{
"total_dimensions": {
"length": 12.949,
"width": 9.192,
"unit": "m",
"total_area": 119.0
},
"rooms": [
{
"name": "客厅",
"position": "中央偏右",
"dimensions": {
"length": 5.198,
"width": 3.188,
"area": 16.57,
"unit": "m"
},
"furniture": [
"沙发",
"茶几",
"电视柜"
],
"connected_to": [
"餐厅",
"入户"
],
"windows": 1,
"doors": 1
},
{
"name": "主卧",
"position": "左下",
"dimensions": {
"length": 4.113,
"width": 3.617,
"area": 14.88,
"unit": "m"
},
"furniture": [
"床",
"衣柜"
],
"connected_to": [
"主卫"
],
"windows": 1,
"doors": 1
},
{
"name": "次卧",
"position": "右上",
"dimensions": {
"length": 3.409,
"width": 3.198,
"area": 10.89,
"unit": "m"
},
"furniture": [
"床",
"衣柜"
],
"connected_to": [
"次卫"
],
"windows": 1,
"doors": 1
},
{
"name": "儿童房",
"position": "左上",
"dimensions": {
"length": 3.327,
"width": 3.611,
"area": 12.0,
"unit": "m"
},
"furniture": [
"床",
"衣柜"
],
"connected_to": [
"厨房"
],
"windows": 1,
"doors": 1
},
{
"name": "厨房",
"position": "上方中央",
"dimensions": {
"length": 2.733,
"width": 2.49,
"area": 6.8,
"unit": "m"
},
"furniture": [
"橱柜",
"灶台"
],
"connected_to": [
"儿童房",
"次卫"
],
"windows": 1,
"doors": 1
}
],
"annotations": [
{
"type": "dimension",
"value": "12949",
"parsed_value": 12.949,
"unit": "m",
"description": "外墙总长"
},
{
"type": "dimension",
"value": "9192",
"parsed_value": 9.192,
"unit": "m",
"description": "外墙总宽"
}
],
"symbols": [
{
"type": "door",
"count": 6,
"positions": [
"客厅-餐厅",
"主卧-主卫",
"次卧-次卫",
"儿童房-厨房"
]
}
],
"circulation": {
"main_entrance": "右下",
"main_path": "入户 → 客厅 → 餐厅 → 各房间",
"layout_type": "分隔式"
},
"design_notes": [
"主卧带独立卫生间",
"动线流畅",
"采光良好"
]
}
接下来,我们需要将这些分析结果存储到向量数据库中,以支持高效的检索和问答。
5.5 构建向量数据库存储系统
在多模态RAG系统中,向量数据库扮演着至关重要的角色。它不仅存储了图纸的文本描述,还保存了提取的结构化元数据,使得我们可以:
- 语义检索:根据用户问题的语义,而非关键词匹配,找到相关图纸
- 元数据过滤:基于结构化信息(如尺寸、材料等)进行精确筛选
- 高效索引:即使有成千上万张图纸,也能毫秒级返回结果
向量数据库的核心思想是将文本转换为高维向量(Embedding),相似的文本在向量空间中距离较近。当用户提问时,问题也被转换为向量,然后通过计算距离找到最相关的文档。
文本内容 → Embedding模型 → 向量表示 → 存储到ChromaDB
用户问题 → Embedding模型 → 问题向量 → 相似度检索 → 返回Top-K结果
接下来,我们就来实现这个向量存储系统。
class VectorStoreManager:
"""向量数据库管理器 - 基于ChromaDB"""
def __init__(self, persist_directory: str = "./chroma_db_floor_plan"):
"""初始化向量数据库"""
self.persist_directory = persist_directory
os.makedirs(persist_directory, exist_ok=True)
# 初始化 Embedding 模型
print("正在初始化 Qwen Embedding 模型...")
self.embeddings = QwenEmbeddings(
model="text-embedding-v4",
api_key=os.getenv("DASHSCOPE_API_KEY") # 从环境变量读取
)
# 初始化 ChromaDB
self.vector_store = Chroma(
persist_directory=persist_directory,
embedding_function=self.embeddings,
collection_name="floor_plans"
)
# 文本分割器
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
separators=["\n\n", "\n", "。", ".", " ", ""]
)
print(f"向量数据库初始化完成")
def add_document(
self,
file_id: str,
file_name: str,
content: str,
extracted_info: Dict[str, Any]
) -> int:
"""添加户型文档到向量库"""
print(f"\n添加文档到向量库: {file_name}")
# 1. 分割文本
chunks = self.text_splitter.split_text(content)
print(f" 文本分割为 {len(chunks)} 个块")
# 2. 创建Document对象
documents = []
for i, chunk in enumerate(chunks):
metadata = {
"file_id": file_id,
"file_name": file_name,
"chunk_id": i,
"total_chunks": len(chunks),
"extracted_info_json": json.dumps(extracted_info, ensure_ascii=False)
}
# 提取关键字段到元数据顶层(便于过滤和问答)
if "total_dimensions" in extracted_info:
dims = extracted_info["total_dimensions"]
metadata["total_area"] = float(dims.get("total_area", 0))
metadata["total_length"] = float(dims.get("length", 0))
metadata["total_width"] = float(dims.get("width", 0))
if "rooms" in extracted_info:
rooms = extracted_info["rooms"]
metadata["room_count"] = len(rooms)
# 统计卧室数量
bedrooms = [r for r in rooms if "卧" in r.get("name", "")]
metadata["bedroom_count"] = len(bedrooms)
if "circulation" in extracted_info:
circ = extracted_info["circulation"]
metadata["layout_type"] = circ.get("layout_type", "")
documents.append(Document(
page_content=chunk,
metadata=metadata
))
# 3. 添加到向量库
ids = [f"{file_id}_chunk_{i}" for i in range(len(documents))]
self.vector_store.add_documents(documents, ids=ids)
print(f"文档已添加,共 {len(documents)} 个文本块")
return len(documents)
def search(
self,
query: str,
top_k: int = 5
) -> List[Dict[str, Any]]:
"""向量检索"""
print(f"\n执行向量检索: {query[:50]}...")
# 执行相似度检索
results = self.vector_store.similarity_search_with_score(
query,
k=top_k
)
# 格式化结果
formatted_results = []
for doc, score in results:
formatted_results.append({
"content": doc.page_content,
"metadata": doc.metadata,
"similarity": float(1 - score)
})
print(f"✓ 找到 {len(formatted_results)} 个相关结果")
return formatted_results
# 创建向量数据库管理器
vector_manager = VectorStoreManager()
print("✓ 向量数据库管理器已就绪!")
正在初始化 Qwen Embedding 模型...
✓ 初始化通义千问 Embedding
模型: text-embedding-v4
维度: 1024
Failed to send telemetry event ClientStartEvent: capture() takes 1 positional argument but 3 were given
Failed to send telemetry event ClientCreateCollectionEvent: capture() takes 1 positional argument but 3 were given
向量数据库初始化完成
✓ 向量数据库管理器已就绪!
5.6 智能问答功能
这里我们将实现两种问答模式:
- 直接问答:从元数据直接提取答案(如"有几个卧室?"、“客厅多大?”)
- 图像检索:返回相关户型列表(如"找3室2厅的户型")
class IntelligentQA:
"""智能问答系统 - LLM驱动版本"""
def __init__(self, vector_manager: VectorStoreManager, llm_client: OpenAI, model_name: str):
self.vector_manager = vector_manager
self.llm_client = llm_client
self.model_name = model_name
def direct_answer(self, question: str, top_k: int = 3) -> Dict[str, Any]:
"""使用LLM基于元数据生成答案"""
print(f"\n{'='*60}")
print("LLM智能问答模式")
print(f" 问题: {question}")
print("="*60)
# 1. 向量检索
results = self.vector_manager.search(question, top_k=top_k)
if not results:
return {
"answer": "抱歉,没有找到相关户型信息。",
"sources": [],
"mode": "direct_answer"
}
# 2. 收集所有相关的元数据
context_parts = []
for i, result in enumerate(results):
metadata = result["metadata"]
# 解析结构化信息
extracted_info = {}
if "extracted_info_json" in metadata:
try:
extracted_info = json.loads(metadata["extracted_info_json"])
except:
pass
context_parts.append(f"""
文档 {i+1}:{metadata.get('file_name', '未知文件')}
VLM描述:{result['content']}
结构化数据:{json.dumps(extracted_info, ensure_ascii=False, indent=2)}
相似度:{result['similarity']:.2f}
""")
# 3. 构建LLM提示词
context = "\n".join(context_parts)
prompt = f"""你是一个专业的房产顾问,请根据提供的户型信息回答用户问题。
用户问题:{question}
可用的户型信息:
{context}
请根据以上信息回答用户问题,要求:
1. 直接、准确地回答问题
2. 如果涉及具体数据(面积、尺寸等),请引用准确数值
3. 如果问题涉及多个户型,请进行对比
4. 保持回答简洁明了
5. 在回答末尾注明信息来源
回答:"""
# 4. 调用LLM生成答案
print("正在调用LLM生成智能答案...")
response = self.llm_client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": "你是一个专业的房产顾问,擅长分析户型信息并回答客户问题。"},
{"role": "user", "content": prompt}
],
max_tokens=1000,
temperature=0.1
)
answer = response.choices[0].message.content
print(f"LLM答案生成完成!")
print("="*60)
return {
"answer": answer,
"sources": [{
"file_id": result["metadata"].get("file_id"),
"file_name": result["metadata"].get("file_name"),
"similarity": result["similarity"]
} for result in results],
"mode": "direct_answer"
}
def search_images(self, query: str, top_k: int = 5) -> Dict[str, Any]:
"""
图像检索模式 - 也用LLM来生成更智能的检索结果描述
"""
print(f"\n{'='*60}")
print("LLM智能检索模式")
print(f" 查询: {query}")
print("="*60)
# 1. 向量检索
results = self.vector_manager.search(query, top_k=top_k * 2)
if not results:
return {
"message": f"没有找到与 '{query}' 相关的户型。",
"images": [],
"mode": "search_images"
}
# 2. 按文件聚合(去重)
file_map = {}
for result in results:
file_id = result["metadata"].get("file_id")
if file_id not in file_map:
# 解析结构化信息
extracted_info = {}
if "extracted_info_json" in result["metadata"]:
try:
extracted_info = json.loads(result["metadata"]["extracted_info_json"])
except:
pass
file_map[file_id] = {
"file_id": file_id,
"file_name": result["metadata"].get("file_name"),
"similarity": result["similarity"],
"content": result["content"],
"extracted_info": extracted_info,
"metadata": result["metadata"]
}
else:
# 更新最高相似度
if result["similarity"] > file_map[file_id]["similarity"]:
file_map[file_id]["similarity"] = result["similarity"]
# 3. 按相似度排序
sorted_files = sorted(
file_map.values(),
key=lambda x: x["similarity"],
reverse=True
)[:top_k]
# 4. 用LLM生成智能的检索结果描述
files_info = []
for file_info in sorted_files:
files_info.append({
"file_name": file_info["file_name"],
"similarity": file_info["similarity"],
"description": file_info["content"],
"details": file_info["extracted_info"]
})
search_prompt = f"""作为房产顾问,请根据检索到的户型信息,回答用户的查询需求。
用户查询:{query}
检索到的户型:
{json.dumps(files_info, ensure_ascii=False, indent=2)}
请:
1. 总结找到了几个相关户型
2. 对每个户型进行简要介绍(户型、面积、特点等)
3. 根据用户查询给出推荐意见
4. 保持专业和友好的语调
回答:"""
print("正在生成智能检索结果...")
response = self.llm_client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": "你是专业的房产顾问,擅长根据客户需求推荐合适的户型。"},
{"role": "user", "content": search_prompt}
],
max_tokens=1000,
temperature=0.3
)
message = response.choices[0].message.content
print(f"✓ 找到 {len(sorted_files)} 个相关户型")
print("="*60)
return {
"message": message,
"images": [{
"file_id": f["file_id"],
"file_name": f["file_name"],
"similarity": f["similarity"]
} for f in sorted_files],
"mode": "search_images"
}
def ask(self, question: str, mode: str = "auto") -> Dict[str, Any]:
"""统一问答接口"""
# 智能判断模式
if mode == "auto":
search_keywords = ["找", "有没有", "哪些", "查找", "搜索", "推荐", "比较"]
if any(kw in question for kw in search_keywords):
return self.search_images(question)
else:
return self.direct_answer(question)
if mode == "direct_answer":
return self.direct_answer(question)
elif mode == "search_images":
return self.search_images(question)
else:
raise ValueError(f"不支持的模式: {mode}")
# 重新创建问答系统
qa_system = IntelligentQA(vector_manager, vlm_client, MODEL_NAME)
print("LLM智能问答系统已就绪!")
LLM智能问答系统已就绪!
# 1. 分析平面图
image_path = "./test_data/house1.png"
question = "请详细分析这张平面图,包括房间布局、尺寸、动线等信息。"
result = analyzer.analyze(image_path, question)
✓图片加载成功: (900, 781)
图片转换为base64: 130.5 KB
正在调用VLM模型...
分析完成!Token使用: 2762
============================================================
print("【分析结果】")
print(result.answer)
print("\n【提取的元数据】")
print(json.dumps(result.extracted_info, ensure_ascii=False, indent=2))
【分析结果】
这张平面图展示了一套三居室的住宅布局,包含客厅、主卧、次卧、儿童房、厨房、主卫、次卫和阳台等功能区。整体布局紧凑,动线合理。
【提取的元数据】
{
"total_dimensions": {
"length": 12.949,
"width": 9.192,
"unit": "m",
"total_area": 119.0
},
"rooms": [
{
"name": "客厅",
"position": "中央偏左",
"dimensions": {
"length": 5.198,
"width": 3.188,
"area": 16.58,
"unit": "m"
},
"furniture": [
"沙发",
"茶几",
"电视柜"
],
"connected_to": [
"餐厅",
"阳台"
],
"windows": 1,
"doors": 1
},
{
"name": "主卧",
"position": "左下角",
"dimensions": {
"length": 3.617,
"width": 4.113,
"area": 14.88,
"unit": "m"
},
"furniture": [
"床",
"衣柜"
],
"connected_to": [
"主卫"
],
"windows": 1,
"doors": 1
},
{
"name": "次卧",
"position": "右上角",
"dimensions": {
"length": 3.499,
"width": 3.188,
"area": 11.15,
"unit": "m"
},
"furniture": [
"床",
"衣柜"
],
"connected_to": [
"次卫"
],
"windows": 1,
"doors": 1
},
{
"name": "儿童房",
"position": "左上角",
"dimensions": {
"length": 3.617,
"width": 3.127,
"area": 11.31,
"unit": "m"
},
"furniture": [
"床",
"衣柜"
],
"connected_to": [
"厨房"
],
"windows": 1,
"doors": 1
},
{
"name": "厨房",
"position": "中央偏上",
"dimensions": {
"length": 2.733,
"width": 2.49,
"area": 6.8,
"unit": "m"
},
"furniture": [
"橱柜",
"灶台"
],
"connected_to": [
"儿童房",
"次卫"
],
"windows": 1,
"doors": 1
},
{
"name": "主卫",
"position": "左下角",
"dimensions": {
"length": 2.22,
"width": 1.8,
"area": 3.996,
"unit": "m"
},
"furniture": [
"浴缸",
"洗手台"
],
"connected_to": [
"主卧"
],
"windows": 0,
"doors": 1
},
{
"name": "次卫",
"position": "右上角",
"dimensions": {
"length": 2.49,
"width": 1.5,
"area": 3.735,
"unit": "m"
},
"furniture": [
"淋浴",
"洗手台"
],
"connected_to": [
"次卧",
"厨房"
],
"windows": 0,
"doors": 1
}
],
"annotations": [
{
"type": "dimension",
"value": "12949",
"parsed_value": 12.949,
"unit": "m",
"description": "外墙总长"
},
{
"type": "dimension",
"value": "9192",
"parsed_value": 9.192,
"unit": "m",
"description": "外墙总宽"
}
],
"symbols": [
{
"type": "door",
"count": 7,
"positions": [
"客厅-餐厅",
"主卧-主卫",
"次卧-次卫",
"儿童房-厨房"
]
}
],
"circulation": {
"main_entrance": "右下角",
"main_path": "主入口 → 玄关 → 客厅 → 各房间",
"layout_type": "分隔式"
},
"design_notes": [
"主卧带独立卫生间",
"动线流畅",
"客厅与餐厅相连"
]
}
import uuid
# 2. 存储到向量数据库
file_id = str(uuid.uuid4())
file_name = "house1.png"
chunk_count = vector_manager.add_document(
file_id=file_id,
file_name=file_name,
content=result.answer, # 将VLM的回答作为文本内容
extracted_info=result.extracted_info # 结构化的元数据
)
添加文档到向量库: house1.png
文本分割为 1 个块
文档已添加,共 1 个文本块
print(f"\n户型已成功存入向量数据库!")
print(f" 文件ID: {file_id}")
print(f" 文本块数: {chunk_count}")
户型已成功存入向量数据库!
文件ID: d7ea1633-51f4-433c-8b9a-0cc1ba813e21
文本块数: 1
# 示例1:直接问答
result1 = qa_system.ask("这个户型有几个卧室?")
print(f"回答:{result1['answer']}")
Failed to send telemetry event CollectionQueryEvent: capture() takes 1 positional argument but 3 were given
============================================================
LLM智能问答模式
问题: 这个户型有几个卧室?
============================================================
执行向量检索: 这个户型有几个卧室?...
✓ 找到 3 个相关结果
正在调用LLM生成智能答案...
LLM答案生成完成!
============================================================
回答:这个户型有三个卧室,分别是主卧、次卧和儿童房。
信息来源:文档 1、文档 2、文档 3。
result2 = qa_system.ask("找一下有没有3室2厅的户型?")
print(f"\n问题:找一下有没有3室2厅的户型?")
print(f"回答:{result2['message']}")
============================================================
LLM智能检索模式
查询: 找一下有没有3室2厅的户型?
============================================================
执行向量检索: 找一下有没有3室2厅的户型?...
Number of requested results 10 is greater than number of elements in index 3, updating n_results = 3
✓ 找到 3 个相关结果
正在生成智能检索结果...
✓ 找到 3 个相关户型
============================================================
问题:找一下有没有3室2厅的户型?
回答:感谢您的查询!根据您的需求,我们找到了三个符合条件的3室2厅的户型。以下是每个户型的简要介绍:
1. **户型一**
- **面积**: 总面积为119平方米。
- **特点**: 该户型布局紧凑,动线合理,包含客厅、主卧、次卧、儿童房、厨房、主卫、次卫和阳台等功能区。主卧带有独立卫生间,客厅与餐厅相连,采光良好。
2. **户型二**
- **面积**: 总面积为119平方米。
- **特点**: 该户型设计为分隔式布局,包含客厅、主卧、次卧、儿童房、厨房、主卫、次卫、餐厅和入户玄关。主卧同样带有独立卫生间,客餐厅一体化设计,动线流畅。
3. **户型三**
- **面积**: 总面积为119平方米。
- **特点**: 该户型为开放式布局,客厅和餐厅连通,动线流畅。包含客厅、主卧、次卧、儿童房、厨房、主卫、次卫和入户玄关。主卧带有独立卫生间,采光良好。
**推荐意见**:
根据您的需求,这三个户型都符合3室2厅的标准,并且每个户型都有其独特的设计特点。若您偏好动线流畅且采光良好的设计,户型三可能是一个不错的选择。若您更注重客餐厅一体化设计,户型二则可能更适合您。希望这些信息能帮助您做出更好的选择!
如需进一步了解或预约看房,请随时与我们联系。我们很乐意为您提供更多帮助!

















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









