



EvalScope实战项目:破解大模型评估的"黑盒难题
最近在做模型微调,遇到了一个很现实的问题:
训练完了,loss也降了,看起来挺好的。但是老板问我一句:“这个模型到底比之前的强多少?”
我当时就懵了。
聊了几轮对话,感觉还行,但这能算评估吗?找了几个同事试用,有说好的有说不好的,完全没有统一标准。
更要命的是,我们要给客户汇报,总不能说"我觉得这个模型还不错"吧?
现实情况:大家都在"盲人摸象"
跟圈内朋友聊了聊,发现这个问题挺普遍的:
- A公司:用人工打分,找了5个人评估200条对话,结果5个人的意见差得离谱
- B团队:对着MMLU等学术测试跑分,分数挺高,但实际业务场景表现一般
- C项目:纯靠业务反馈,用户说好就是好,但这个周期太长了
大家都知道要评估,但都没有一套靠谱的方法。
EvalScope:阿里搞的一个评估工具
偶然发现了EvalScope这个工具,是阿里云开源的。
看了看介绍,主要解决几个问题:
- 能跑标准化的测试(像MMLU、C-Eval这些)
- 支持自定义数据集(可以用自己的业务数据)
- 有可视化界面(不用盯着命令行看数字)
- 可以对比不同模型(微调前后、不同方案之间)
为什么要用这个工具?
实际需求角度
对开发者:
需要客观的数据来证明自己的工作成果,不能总是"我觉得"
对管理层:
需要量化的指标来决定资源投入,特别是要不要继续优化模型
对客户汇报:
需要专业的评估报告,不能拿着聊天记录当证据
技术角度
标准化测试:
集成了OpenCompass等后端,可以跑学术界认可的基准测试
业务数据支持:
可以导入自己的测试数据,评估在实际业务场景下的表现
多维度评估:
不只是准确性,还能测试安全性、推理能力等
性能测试:
能测试模型的推理速度、资源消耗,这对生产部署很重要
实际使用场景
微调效果验证
微调完成后,用同一套数据分别测试原模型和微调后的模型,直接对比差异
不同方案对比
比如LoRA vs QLoRA,或者不同的超参数设置,可以批量测试找到最优方案
生产部署前检查
模型要上线前,跑一遍完整的评估,确保各项指标符合预期
持续监控
模型部署后,定期跑评估检查性能是否有衰退
这个项目的价值
解决痛点:
把主观的"感觉"变成客观的数据,让模型评估有理有据
提升效率:
自动化测试比人工评估快很多,而且结果更稳定
降低风险:
上线前充分测试,避免部署后才发现问题
便于沟通:
有了标准化的评估报告,跟同事、客户沟通都更有说服力

EvalScope:智能评估中枢
是什么?
EvalScope是阿里云推出的大模型评估框架,提供标准化、自动化的模型能力评估解决方案。它集成了多种评估后端,支持从学术基准到实际应用的全方位评估。
解决什么问题?
核心痛点:
- 评估标准不统一:缺乏行业标准的评估基准
- 人工评估成本高:大规模人工评估耗时耗力
- 评估维度单一:仅关注准确率,忽视安全性、鲁棒性等
- 结果不可比较:不同团队的评估结果无法横向对比
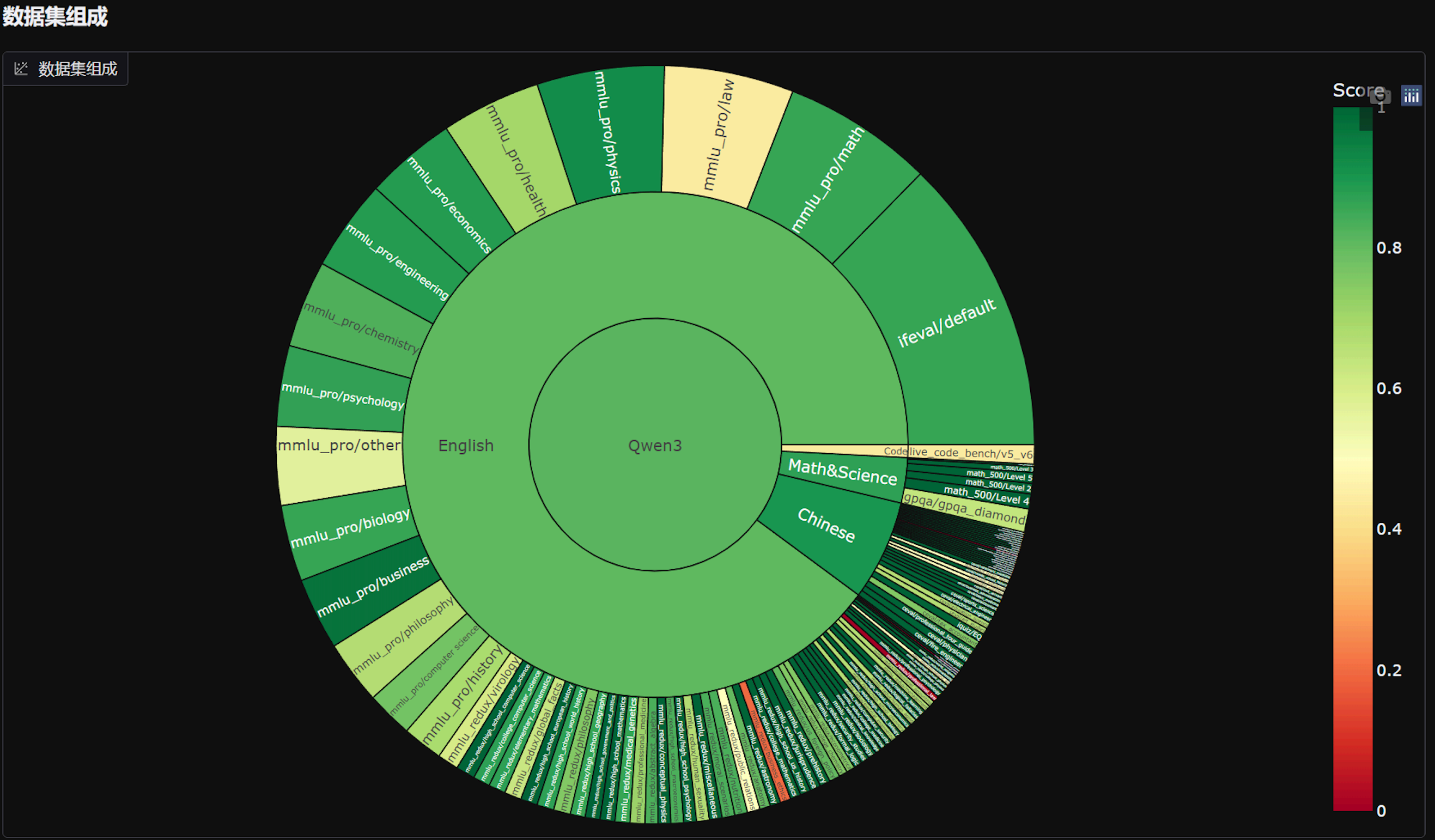
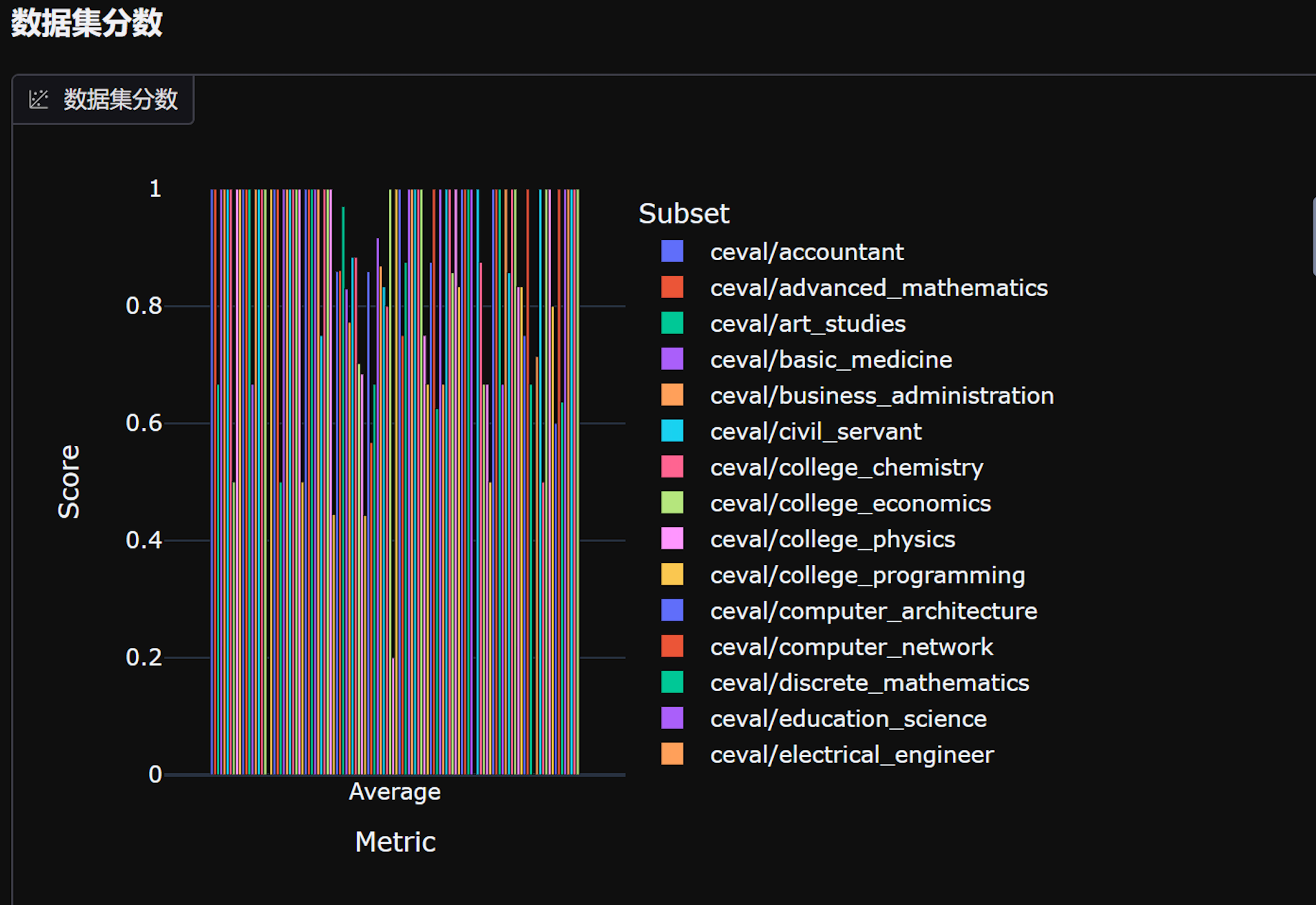
评估能力覆盖:
- 认知能力:推理、数学、代码、知识问答
- 安全合规:有害内容检测、偏见识别
- 多模态能力:图文理解、视频分析
- 性能指标:推理速度、资源消耗
在微调链路中的作用
第六阶段(效果评估)的核心工具:
自动化评估:
- 标准化基准测试(MMLU、C-Eval、GSM8K等)
- 自定义评估数据集支持
- 多维度评估指标计算
对比分析:
- 微调前后效果对比
- 不同微调方法效果对比
- 与竞品模型横向对比
持续监控:
- 模型能力退化检测
- 新版本效果验证
- 生产环境质量监控
核心组件架构
- OpenCompass后端:学术基准评估
- VLMEvalKit后端:多模态模型评估
- RAGEval后端:检索增强生成评估
- 性能测试组件:推理性能压测
- 可视化界面:评估结果展示
EvalScope安装流程
接下来进行EvalScope安装部署,项目官网:https://github.com/modelscope/evalscope
EvalScope单独创建虚拟环境:
conda create --name evalscope python=3.11
conda init
source ~/.bashrc
conda activate evalscope
conda install jupyterlab
conda install ipykernel
python -m ipykernel install --user --name evalscope --display-name "Python
evalscope"
安装对应的库:
pip install evalscope
# 额外选项
pip install 'evalscope[opencompass]' pip install 'evalscope[vlmeval]' pip install 'evalscope[rag]'
pip install 'evalscope[perf]'
pip install 'evalscope[app]'
# 或可以直接输入all,安装全部模块
# pip install 'evalscope[all]' VLMEvalKit, RAGEval)
# 安装 Native backend (默认)
# 安装 OpenCompass backend # 安装 VLMEvalKit backend # 安装 RAGEval backend
# 安装 模型压测模块 依赖
# 安装 可视化 相关依赖
# 安装所有 backends (Native, OpenCompass,
关于 EvalScope 的各个可选组件是否需要全部安装,答案是否定的。这完全取决于你的具体评测需求。为了帮你快速了解,下面这个表格汇总了各个可选组件的主要功能和适用场景。
| 组件名称 | 功能简介 | 适用场景 |
|---|---|---|
evalscope[opencompass] | 集成 OpenCompass 评测后端 | 需要进行大规模、标准化的模型能力评估(如 MMLU, C-Eval 等) |
evalscope[vlmeval] | 集成 VLMEvalKit 评测后端,支持多模态模型 | 需要评测图生文、视频理解等多模态模型能力 |
evalscope[rag] | 集成 RAGEval 后端,支持检索增强生成(RAG)管道端到端评测 | 需要评估与 RAG 系统相关的模型或应用 pipeline |
evalscope[perf] | 提供模型性能压测工具,评估吞吐量、延迟等关键指标 | 需要测试模型服务的推理性能、吞吐量和延迟 |
evalscope[app] | 提供可视化 Web 界面(Gradio),便于交互式查看结果 | 希望通过图形化界面操作和直观地浏览评测结果 |
💡 如何选择安装组合
你可以根据目标灵活选择安装组合:
-
只想进行基础的单模型能力评测**:安装最核心的包即可。
pip install evalscope -
计划开展全面的模型能力评估(包括多模态和RAG):建议安装核心包及主要评测后端。
pip install 'evalscope[opencompass]' 'evalscope[vlmeval]' 'evalscope[rag]' -
重点关注模型的服务性能(如部署为API后的表现):核心包加上性能测试组件是必须的。
pip install 'evalscope[perf]' -
希望获得最佳的可视化体验:可以加上可视化组件。通常它会和上述组合一起安装。
pip install 'evalscope[app]' -
追求一站式完整功能:如果你不确定具体需求,或者希望拥有全部功能,可以直接安装完整版。
pip install 'evalscope[all]'
源码安装
git clone https://github.com/modelscope/evalscope.git
cd evalscope/
pip install omegaconf
pip install -e .
# 额外选项
pip install -e '.[opencompass]' pip install -e '.[vlmeval]' pip install -e '.[rag]'
pip install -e '.[perf]'
pip install -e '.[app]'
pip install -e '.[all]' VLMEvalKit, RAGEval)
evalscope界面化展示
evalscope app

# 样例代码
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='/root/autodl-tmp/Qwen3-4B-Instruct-2507',
api_url='http://127.0.0.1:8000/v1/chat/completions',
eval_type='openai_api', # 修改:从 'service' 改为 'openai_api'
datasets=[
'data_collection',
],
dataset_args={
'data_collection': {
'dataset_id': 'modelscope/EvalScope-Qwen3-Test',
'filters': {'remove_until': '</think>'} # 过滤掉思考的内容
}
},
eval_batch_size=128,
generation_config={
'max_tokens': 30000, # 最大生成token数
'temperature': 0.6, # 采样温度 (qwen 报告推荐值)
'top_p': 0.95, # top-p采样 (qwen 报告推荐值)
'top_k': 20, # top-k采样 (qwen 报告推荐值)
'n': 1, # 每个请求产生的回复数量
'timeout': 60000, # 修改:将timeout移到generation_config内
'stream': True, # 修改:将stream移到generation_config内
},
limit=200, # 设置为2000条数据进行测试
)
run_task(task_cfg=task_cfg)
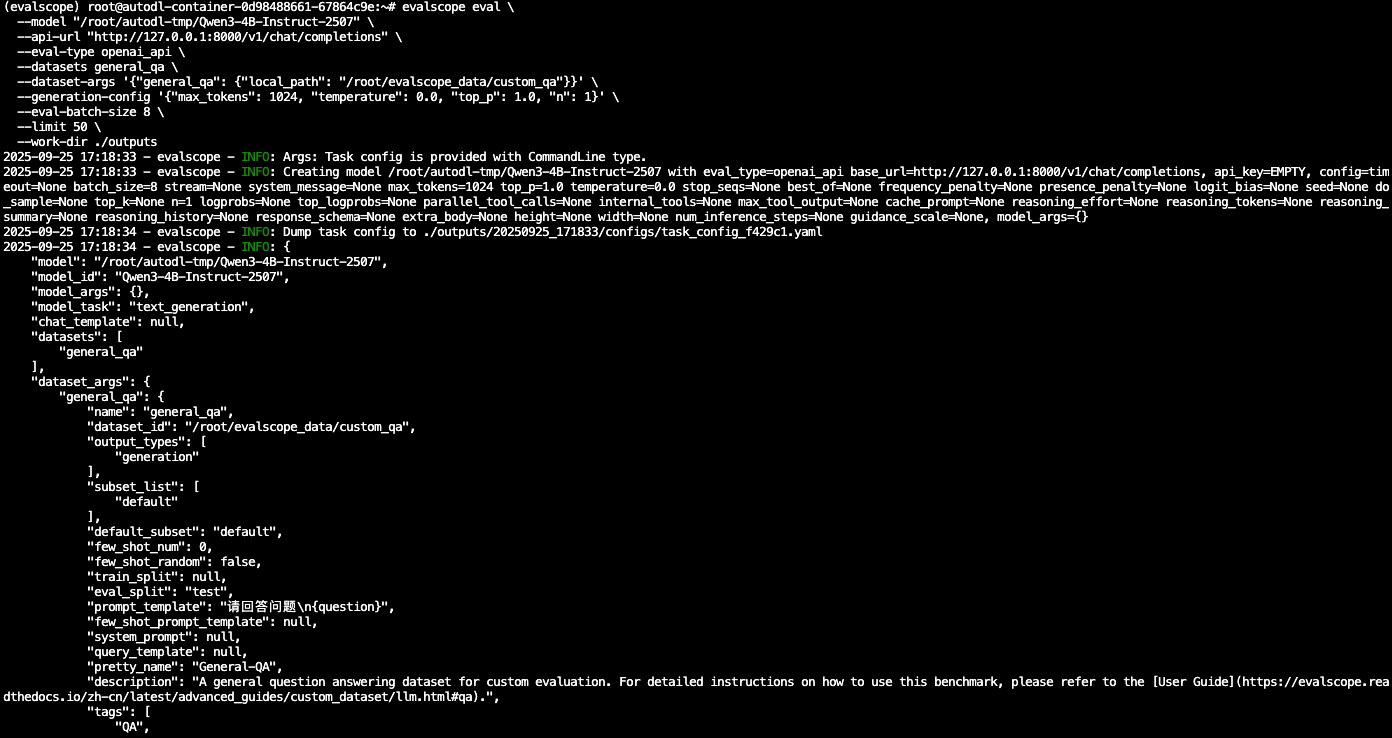
evalscope本地文件模型校验
#不使用默认名称
--dataset-args '{"general_qa": {"local_path": "/root/evalscope_data/custom_qa", "subset_list": ["qqdefault"]}}' \
evalscope eval \
--model "/root/autodl-tmp/Qwen3-4B-Instruct-2507" \
--api-url "http://127.0.0.1:8000/v1/chat/completions" \
--eval-type openai_api \
--datasets general_qa \
--dataset-args '{"general_qa": {"local_path": "/root/evalscope_data/custom_qa"}}' \
--generation-config '{"max_tokens": 1024, "temperature": 0.0, "top_p": 1.0, "n": 1}' \
--eval-batch-size 8 \
--limit 50 \
--work-dir ./outputs
当前命令逐项解析
# 样例命令
evalscope eval \
--model "/root/autodl-tmp/Qwen3-4B-Instruct-2507" \
--api-url "http://127.0.0.1:8000/v1/chat/completions" \
--eval-type openai_api \
--datasets general_qa \
--dataset-args '{"general_qa": {"local_path": "/root/evalscope_data/custom_qa", "subset_list": ["qqdefault"]}}' \
--generation-config '{"max_tokens": 1024, "temperature": 0.0, "top_p": 1.0, "n": 1}' \
--eval-batch-size 8 \
--limit 5 \
--work-dir ./outputs
--model "/root/autodl-tmp/Qwen3-4B-Instruct-2507"
-
作用:指定要评估的模型路径。
-
注意:这里是本地模型路径,或者可以用 HuggingFace 模型名(如果 evalscope 支持远程加载)。
-
坑点:
- 路径不对或模型文件不完整会报错加载失败。
- 对大模型,如果没有足够显存或 API 连接不稳定,也会报错。
--api-url "http://127.0.0.1:8000/v1/chat/completions"
-
作用:指定模型接口,如果你用的是本地 API 服务(例如 Qwen 或者 OpenAI API 兼容接口)。
-
注意:
- 如果接口不可达,会报连接错误。
- URL 必须是完整可访问的 endpoint。
--eval-type openai_api
-
作用:告诉 evalscope 使用 OpenAI 风格的接口进行调用。
-
常见选项:
openai_api→ 使用 OpenAI API 风格调用。hf_api→ 使用 HuggingFace Inference API。
-
坑点:
- 类型不对可能导致参数解析错误。
- 如果使用本地 API 但选了
openai_api,需要保证接口兼容。
--datasets general_qa
-
作用:指定要评估的任务类型或数据集名称。
-
坑点:
- 这个名称要和
dataset-args中的 key 一致。 - 如果目录里没有对应的 jsonl 文件或者 subset 不匹配,会报
No samples found。
- 这个名称要和
--dataset-args '{"general_qa": {"local_path": "/root/evalscope_data/custom_qa", "subset_list": ["qqdefault"]}}'
-
作用:告诉 evalscope 数据集的具体路径和子集。
local_path→ 本地存放 jsonl 数据文件夹。subset_list→ 指定要加载的子集文件名(不带.jsonl后缀)。
-
重点注意:
-
默认子集是
"default"- 如果你不写
subset_list,evalscope 会自动去找default.jsonl。 - 这就是为什么你把文件改名为别的就报错。
- 如果你不写
-
文件名必须完全对应 subset 名字,否则报:
No samples found in subset: default AssertionError: No scores to generate report from.
-
--generation-config '{"max_tokens": 1024, "temperature": 0.0, "top_p": 1.0, "n": 1}'
-
作用:生成配置,控制模型输出:
max_tokens→ 最大生成长度temperature→ 温度,0.0 意味着最确定性输出top_p→ 核采样n→ 每条输入生成多少个候选答案
-
坑点:
max_tokens太小可能导致答案截断。- temperature 太高可能导致评估不稳定。
7. --eval-batch-size 8
-
作用:一次发送给模型的样本数量(批量处理)。
-
坑点:
- 批量太大可能显存不足或接口超时。
8. --limit 5
- 作用:只评估前 N 个样本,便于测试。
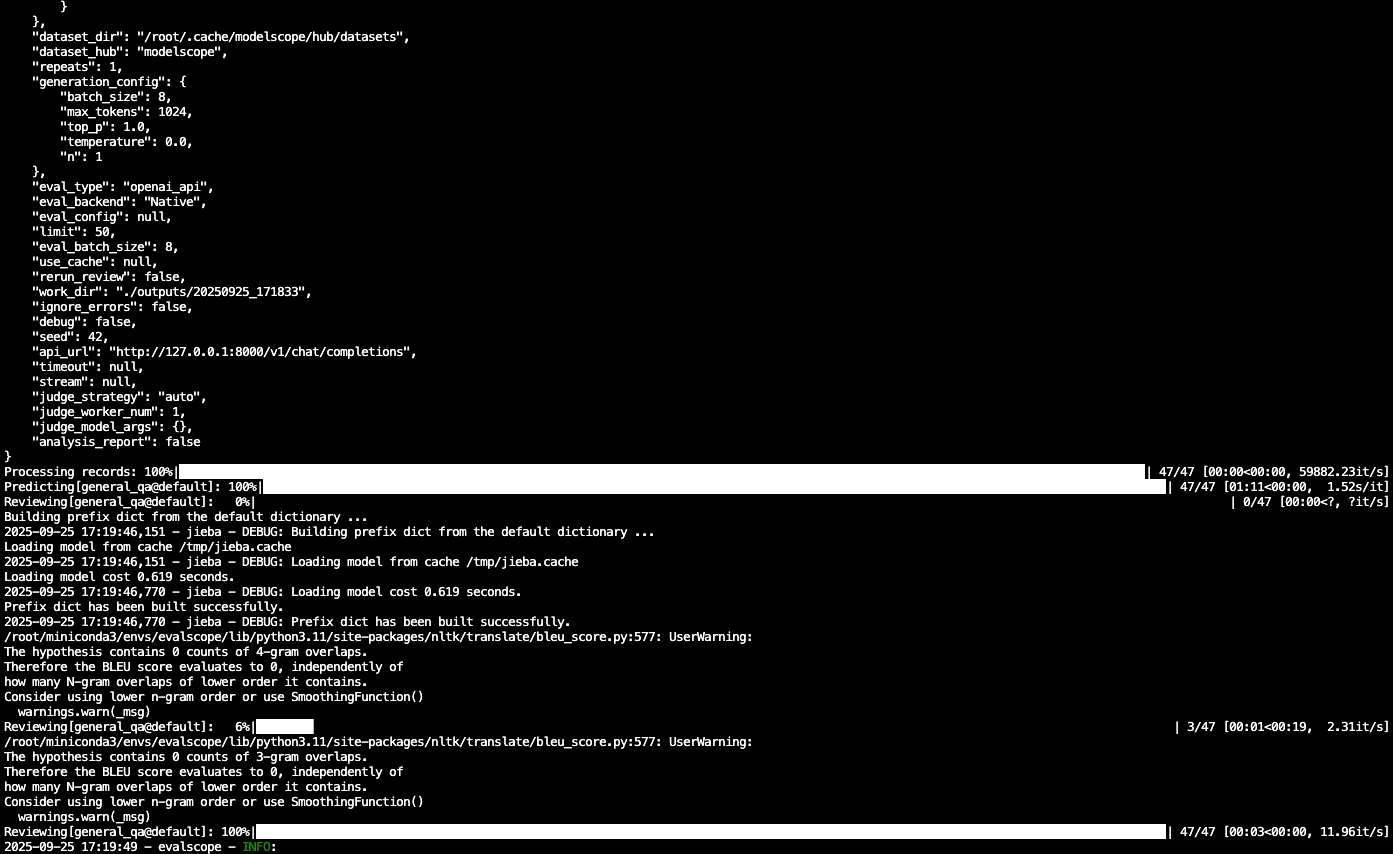
9. --work-dir ./outputs
- 作用:存放评估输出结果的目录,包括 JSON 报告和日志。
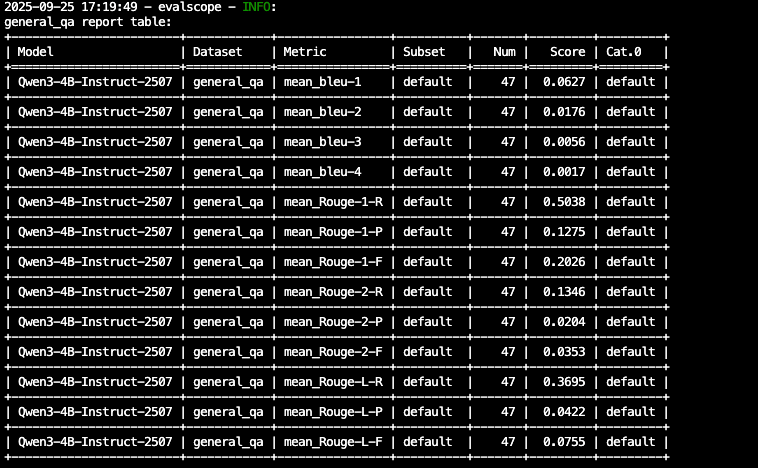
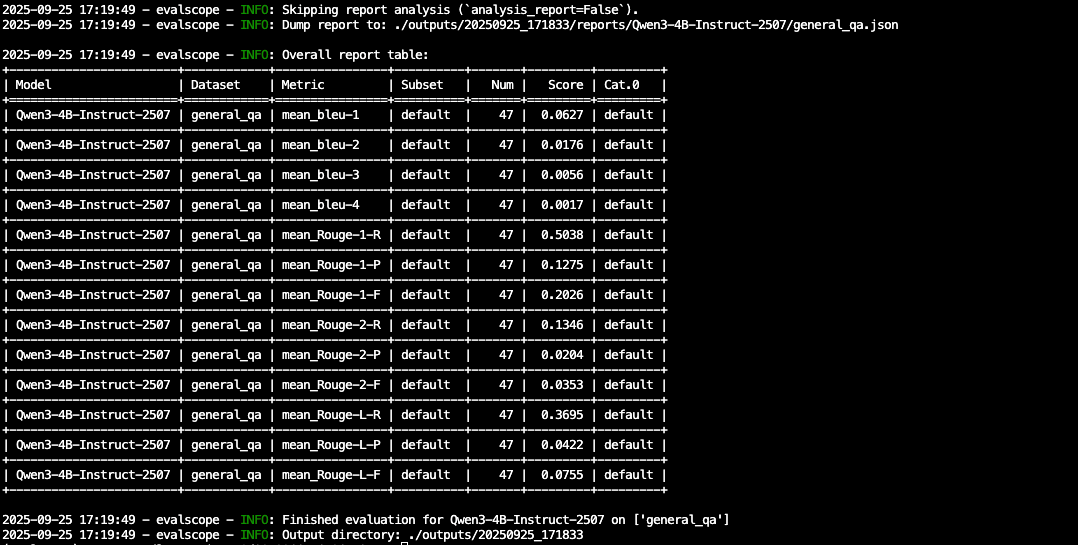
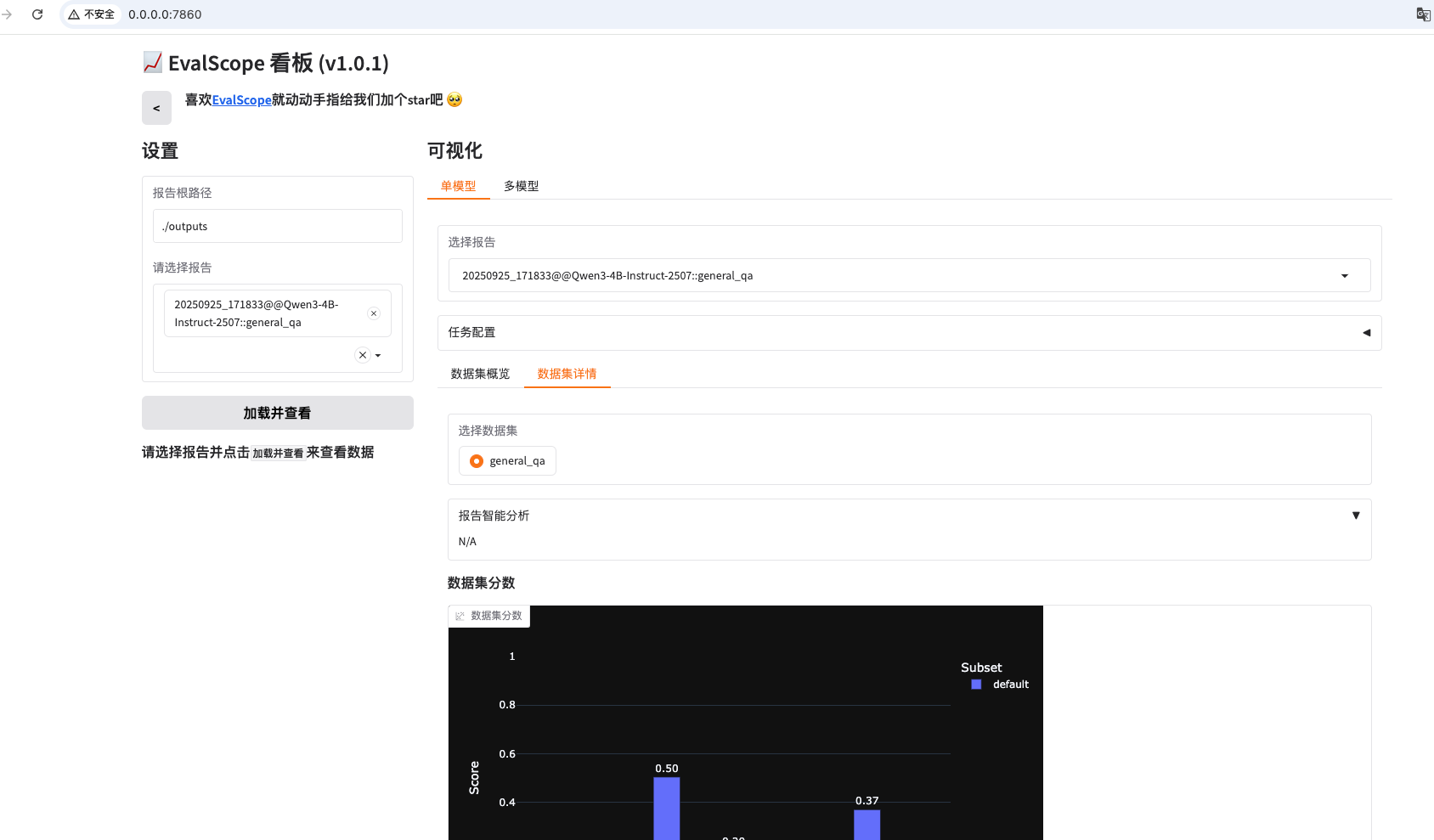
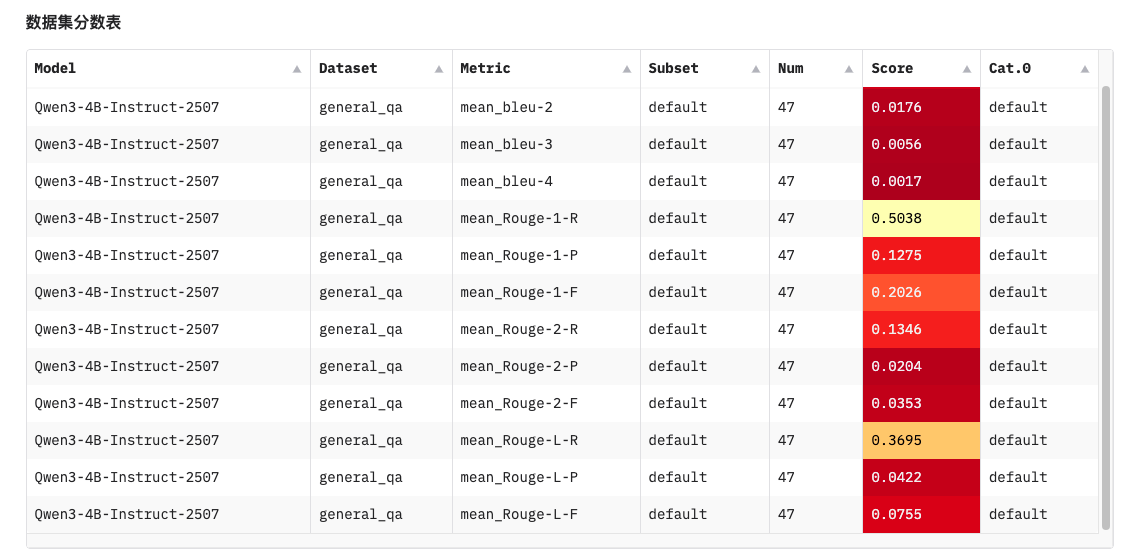
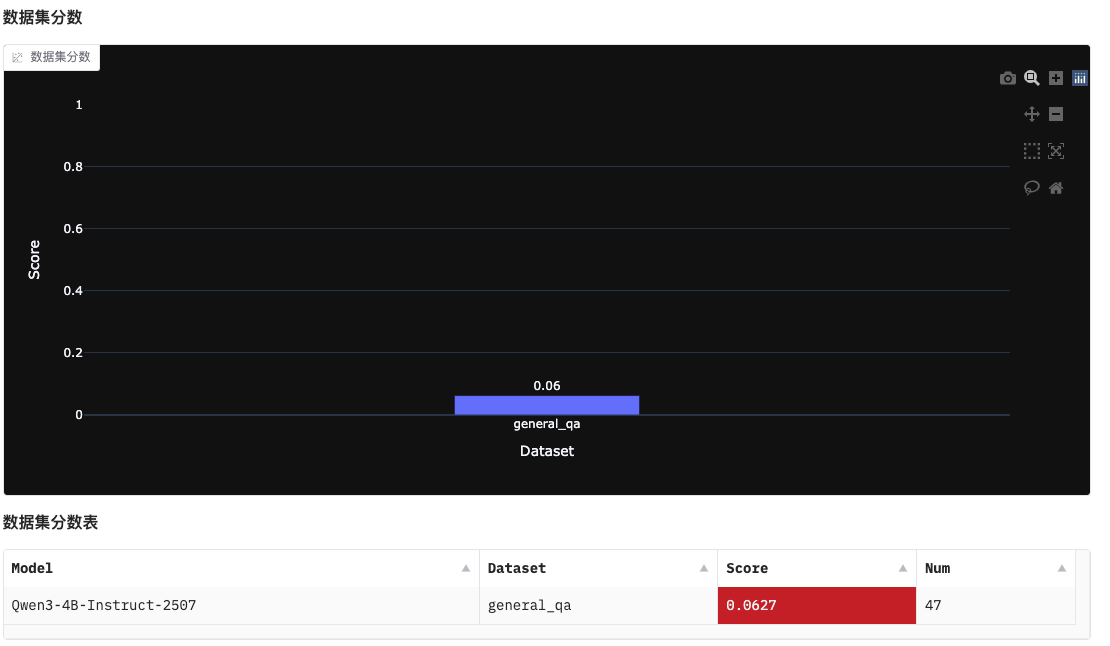
EvalScope不是什么高深的技术,就是一个实用的工具。
核心价值很简单:让模型评估这件事变得靠谱一些,不用再靠拍脑袋做决定。
特别是现在大模型应用越来越多,有个标准化的评估流程还是很有必要的。
加入 赋范空间 我们提供大厂级的技术竞争力塑造
-
掌握目前头部企业高级开发工程师的核心技术栈(如模型蒸馏、高效微调等降本增效技术)
-
构建可验证的实战项目组合:10+套完整实战项目,覆盖主流应用场景,用户按需选择学习,锻造自己的实战能力,提供源码、完整复现可内化迁移赋能简历
-
超300w+技术内容观看量,大量学员自发推荐的高价值社区
-
与各行业的顶尖开发者社群内实时互动,打破你的技术信息差
-
共享优质干货技术学习资源库:大模型全栈体系学习公益社区

















 2687
2687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









