



用 Verl 让强化学习飞起来:单卡直冲 80% 数学推理(保姆级流程)
只改几行配置,训练速度直接快 4-5 倍;1.5B 模型在 GSM8K 上从 49% 拉到 80%。这篇带你 打通VeRL 从 “环境配置->训练->评估” 的完整闭环,配图齐全、代码精简、上手即用。
项目完整教程及源码加入 赋范空间 免费领取,还有更多模型微调和agent课程等你来拿
为什么是 Verl?
- 针对大模型强化学习的生产级框架:训练用 PyTorch,推理用 vLLM,Ray 统一调度。
- 直接解决四大痛点:推理慢、显存紧、调度复杂、奖励设计难。无需自行造轮子。
Verl 的核心对比
- 传统方案把训练和推理都压在 PyTorch 上,推理占 70% 时间却不够快;Verl 把推理交给 vLLM,整体提速 4-6 倍。
整体架构与数据流
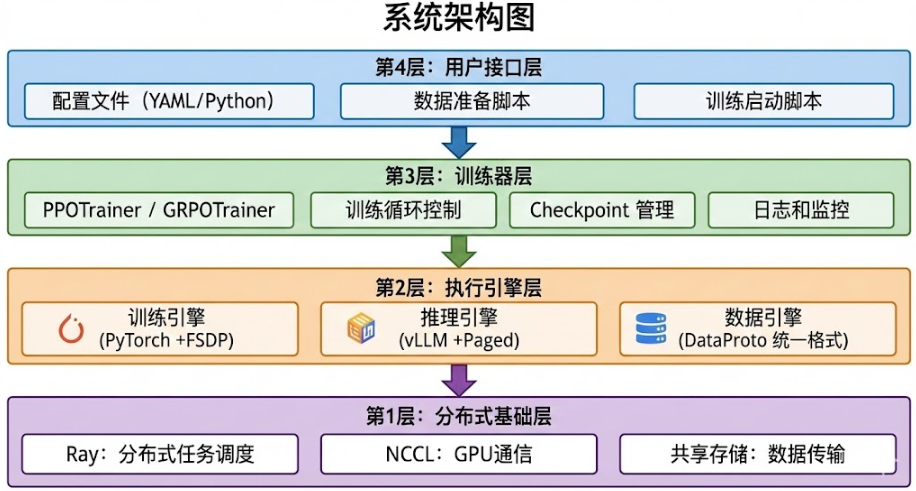
- 四层架构:数据引擎 → 推理引擎(vLLM) → 训练引擎(PyTorch) → 分布式协调(Ray)
- 简化数据流:读取 → 生成多回答 → 规则/模型打分 → 更新策略 → 评估保存
第1步:读取数据(Parquet)
第2步:推理节点生成回答(vLLM 4-6倍加速)
第3步:Reward 打分(规则或模型)
第4步:训练节点更新参数(PyTorch + FSDP)
第5步:验证评估与保存 Checkpoint
GRPO 是怎么把显存省出来的?
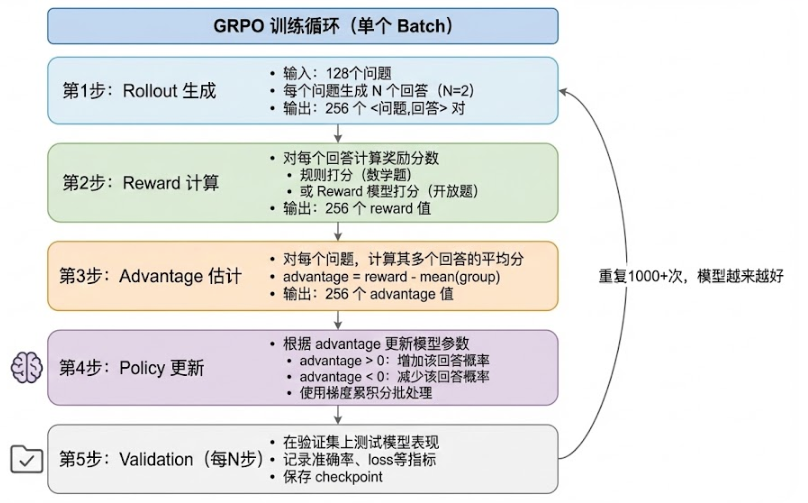
- 核心思想:同一问题生成多条回答,直接用“群体平均”替代 Critic 估值 → 少一个模型,省 30-40% 显存。
- 训练五步:Rollout → Reward → Advantage → Policy Update → Validation。
# 精简版 GRPO 损失(PPO 的简化)
def compute_grpo_loss(new_logprobs, old_logprobs, advantages):
ratio = torch.exp(new_logprobs - old_logprobs)
return (-ratio * advantages).mean()
# 奖励提取(GSM8K:#### 后是最终数字)
import re
def extract_solution(text):
m = re.search(r"#### (\-?[0-9\.\,]+)", text)
return m.group(1).replace(",", "") if m else None
三模型协作:为什么更快更稳?
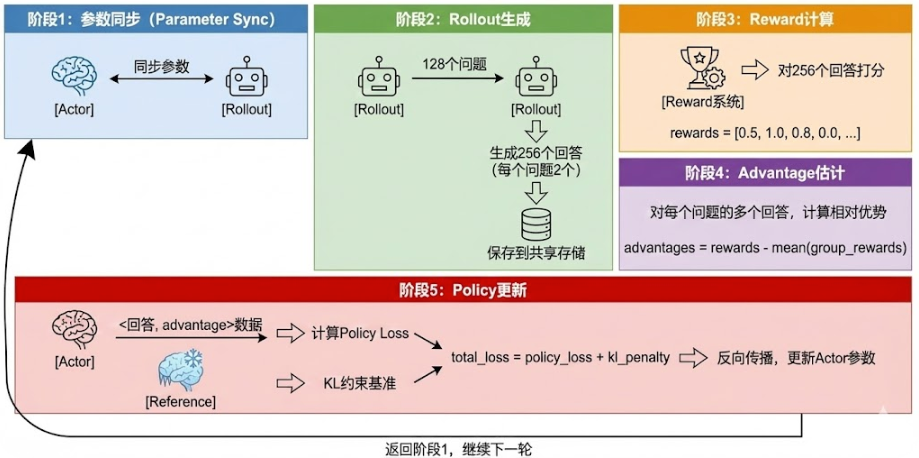
- Actor(训练):唯一更新的模型,负责学习策略。
- Rollout(推理):定期从 Actor 同步参数,用 vLLM 快速批量生成。
- Reference(守门):保持初始参数不变,提供 KL 约束,防跑偏。
环境与安装
这里仅为关键点,项目完整教程加入 赋范空间 免费领取,还有更多模型微调和agent课程等你来拿
- Conda 与 pip 使用国内镜像,创建
python=3.11独立环境。 - 一键脚本安装 vLLM、SGLang、Megatron、FlashAttention 等依赖;
pip install -e .安装 verl 本体。 - 验证:
import verl, torch, vllm输出版本与 GPU 信息。
conda create -n verl python=3.11 -y \
-c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main \
--override-channels
conda activate verl
git clone https://github.com/volcengine/verl.git && cd verl
bash scripts/install_vllm_sglang_mcore.sh
pip install -e .
数据准备(从 HF 到 Verl)
- 把
question/answer转为 ChatML,强制加指令:Let's think step by step and output the final answer after "####". - 从
answer中提取ground_truth(纯数字)用于规则打分。
# 切换算法只需一行,整体训练循环统一
from verl.trainer import GRPOTrainer, PPOTrainer
trainer = GRPOTrainer(config=config, actor_model=actor, rollout_model=rollout, ref_model=reference)
# trainer = PPOTrainer(...) # 若需要 PPO
trainer.fit(train_data)
训练参数与启动(单卡 A800 示例)
- 批配置:
BATCH_SIZE=128,ROLLOUT_N=2→ 每步 256 样本。 - 累积:
MINI_BATCH=32,MICRO_BATCH=8→ 共 32 次累积,显存稳。 - 学习率:
LR=5e-6,每 50 步验证与保存。
bash train_simple.sh
# vLLM 推理 256 回答仅需 2-3 分钟;PyTorch 原生要 10-12 分钟
验证评估(准确率差 20-30% 的“隐藏大坑”)
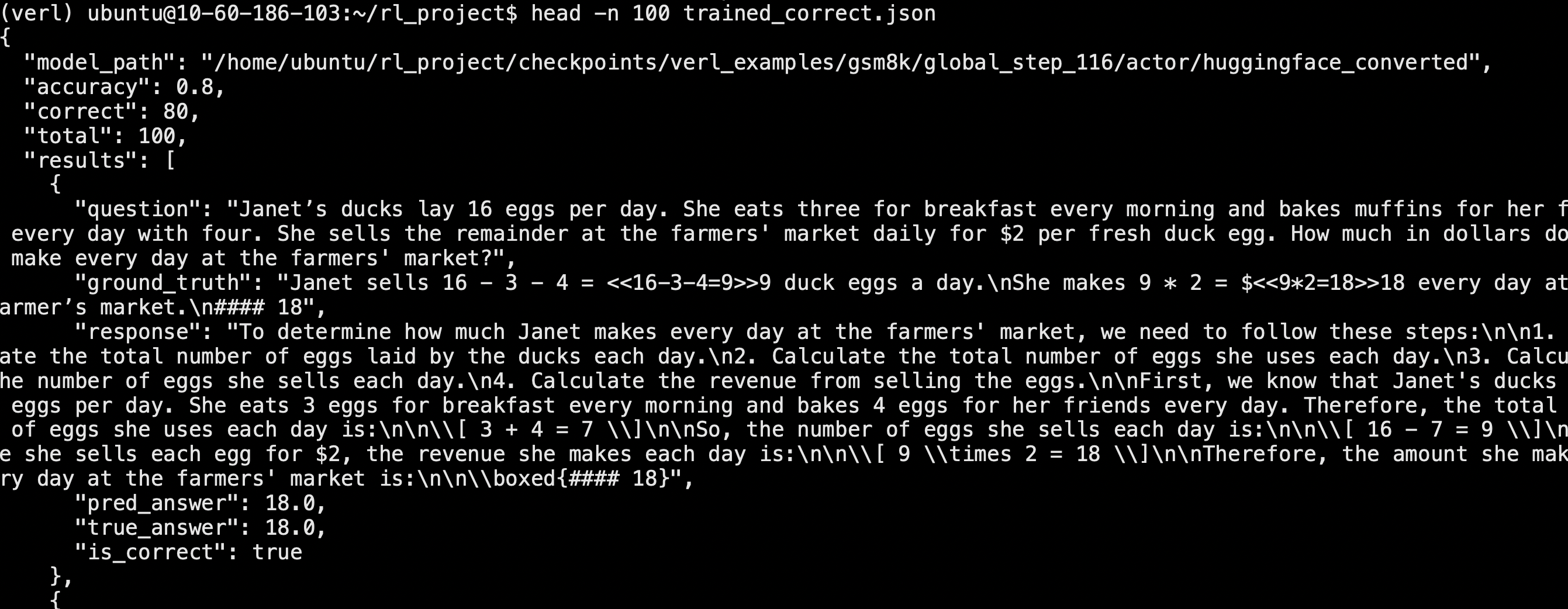
- 训练时是“问题 + 指令 + #### 输出”,验证也必须用同样的 Prompt;否则准确率直接掉到 50% 左右。
- 批量验证更快:
batch=32把 26 分钟压到 8 分钟。
# 验证核心:严格复用 test.parquet 里的 prompt
def evaluate_model(model_path, test_data_path):
tok = AutoTokenizer.from_pretrained(model_path)
mdl = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16, device_map="auto")
df = pd.read_parquet(test_data_path)
correct = 0
for _, row in df.iterrows():
prompt = row['prompt'][0]['content']
gt = row['reward_model']['ground_truth']
resp = mdl.generate(**tok(prompt, return_tensors="pt").to(mdl.device), max_new_tokens=512)
pred = extract_solution(tok.decode(resp[0], skip_special_tokens=True))
correct += int(pred == gt)
return correct / len(df)
Checkpoint 转换与部署
- Verl 保存为 FSDP 分片,需转换到 HuggingFace 格式后再加载推理:
python convert_checkpoint.py \
--input_dir ./outputs/checkpoints/step_50 \
--output_dir ./outputs/converted/step_50 \
--model_type qwen2
常见坑与快速优化
- OOM:减小
BATCH_SIZE,提高累积层次,GPU_MEM=0.2给 Actor 更多显存。 - Loss 不降:学习率从
5e-6微调到1e-5/1e-6,检查 Reward 是否全 0。 - 训练慢:确认 vLLM 生效;降低
TEST_FREQ;必要时开启 FlashAttention。 - Prompt 不一致:这是命中率暴跌的首因,务必复用训练时模板与提取规则。
结语与获取方式
- 如果你想把 1.5B 模型在数学推理上从“会答”练到“会推理”,Verl 的混合架构与 GRPO 会是最省心的上车路径。
项目完整教程及源码加入 赋范空间 免费领取,还有更多模型微调和agent课程等你来拿

















 4553
4553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









