








前言
具体的开源时间是6月30日,GitCode上可以直接看到开源的模型列表,开源意味着就可以直接使用了,对于我们个人开发者来说是一件非常好的事情,又多了一种可以免费使用的开源大模型,但是具体是否好用就得实际测试一下了,我今天主要是针对【ERNIE-4.5-21B-A3B-Base-Paddle】这个模型来测试,21B是我们个人开发者基本能跑的极限了,不可能所有人都有非常好的本地环境来跑300B以上的模型,所以说21B就是最合适的,所以我来具体的测评一下。
一起来轻松玩转文心大模型吧👉一文心大模型免费下载地址: https://ai.gitcode.com/theme/1939325484087291906
目录
为什么选择ERNIE-4.5-21B-A3B-Base作对比
ERNIE-4.5-21B-A3B-Base-Paddle与DeepSeek-V3返回数据对比
baidu/ERNIE-4.5-21B-A3B-Base-Paddle消耗时间与返回结果
文心4.5开源的价值
官话说一句:文心一言 4.5 于 gitCode 首发开源,这一举措在技术发展、产业应用和生态构建等多个维度都具有重要意义,为人工智能领域的进步注入了强劲动力。
自己的理解:文心一言 4.5 把自家大模型的代码和技术公开了,就像把做菜的秘方分享出来。那么我们能干嘛呢?比如搞开发的人可以拿这些代码改改,做出更贴合咱们生活的 AI 工具 —— 像智能客服能更懂方言,写文案的工具能模仿咱说话的语气;企业用它不用从头开发,省时间省钱,比如小超市用它做个扫码查货的小程序;学生和研究者能研究里面的技术,琢磨怎么让 AI 更聪明。而且开源后大家都能挑毛病、优化,就像一群人一起修路,越走越顺,以后咱们用的 AI 功能也会越来越接地气。
开源与闭源对模型的影响
我觉得最大的影响就能免费使用后大家都会在其中找bug,这样对文心5.0就会有很多的理论上的提升方案了。
| 维度 | 开源大模型(文心 4.5) | 闭源大模型(如部分商业模型) |
|---|---|---|
| 开发门槛 | 提供现成代码和工具,开发者能直接用,省时间省钱。 | 得自己从头开发或买授权,成本高,中小团队难用上。 |
| 应用灵活性 | 可以根据需求修改模型,比如让 AI 懂方言、做小众功能。 | 功能固定,想改得找官方,灵活性差,难适配个性化需求。 |
| 生态活力 | 开发者一起优化,像开源社区里大家互帮互助,功能更新快。 | 依赖官方团队,更新慢,用户只能等官方加功能。 |
| 安全性 | 漏洞容易被发现和修复(众人挑错),但代码公开也可能被恶意利用。 | 漏洞难发现(只有官方知道),一旦被攻击后果可能更严重。 |
| 普及速度 | 企业和个人都能用,加速 AI 在生活、工作中的落地(如小商店用 AI 理货)。 | 主要被大企业买走,普通人和小团队用不上,普及慢。 |
项目目标——暖男聊天黑科技
请求逻辑,我是针对于少男来写的提示词,很明显能从4个方向上感觉出来。
你是一位情话专家,专门帮助男性解决聊天对话的问题,回复的内容都很有诗意,并且很有趣,返回的信息永远让对方有话可接,不会让聊天尬场。
1、理解聊天信息,给出对方的目的;
2、根据对方的目的,给出诗意的回复;
3、根据对方的目的,给出有趣的回复;
4、根据对方的目的,给出调侃的回复;
5、根据对方的目的,给出生活的回复;
6、返回的信息格式为json;
7、json格式为:{"Aim":"xxx","data":{"shi":"xxx","qu":"xxx","tiao":"xxx","sheng":"xxx"}}
8、不要返回多余的内容,如果json格式不正确则重新生成。
此次聊天问题是用户输入的问题。
请求代码:
import requests
import json
import time
from statistics import mean
def send_request():
"""发送单次请求并返回响应时间和结果"""
# 设置API端点
url = "http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "baidu/ERNIE-4.5-0.3B-PT",
"messages": [
{
"role": "user",
"content": """
你是一位情话专家,专门帮助男性解决聊天对话的问题,回复的内容都很有诗意,并且很有趣,返回的信息永远让对方有话可接,不会让聊天尬场。
1、理解聊天信息,给出对方的目的;
2、根据对方的目的,给出诗意的回复;
3、根据对方的目的,给出有趣的回复;
4、根据对方的目的,给出调侃的回复;
5、根据对方的目的,给出生活的回复;
6、返回的信息格式为json;
7、json格式为:{"Aim":"xxx","data":{"shi":"xxx","qu":"xxx","tiao":"xxx","sheng":"xxx"}}
8、不要返回多余的内容,如果json格式不正确则重新生成。
此次聊天问题是用户输入的问题。
"""
}
]
}
try:
# 记录开始时间
start_time = time.time()
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 计算响应时间(秒)
response_time = time.time() - start_time
# 获取token数量
completion_tokens = result.get('usage', {}).get('completion_tokens', 0)
prompt_tokens = result.get('usage', {}).get('prompt_tokens', 0)
total_tokens = result.get('usage', {}).get('total_tokens', 0)
# 计算每秒token数量
tokens_per_second = total_tokens / response_time if response_time > 0 else 0
return {
"success": True,
"response_time": response_time,
"status_code": response.status_code,
"result": result,
"completion_tokens": completion_tokens,
"prompt_tokens": prompt_tokens,
"total_tokens": total_tokens,
"tokens_per_second": tokens_per_second
}
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
return {"success": False, "error": str(e)}
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
return {"success": False, "error": f"JSON解析错误: {str(e)}"}
except Exception as e:
print(f"发生错误: {e}")
return {"success": False, "error": str(e)}
def main():
# 请求次数
request_count = 1
# 存储统计数据
response_times = []
tokens_per_second_list = []
completion_tokens_list = []
prompt_tokens_list = []
total_tokens_list = []
# 存储成功请求数
success_count = 0
print(f"开始执行 {request_count} 次请求...\n")
# 执行多次请求
for i in range(request_count):
print(f"请求 {i+1}/{request_count} 执行中...")
# 发送请求
result = send_request()
if result["success"]:
success_count += 1
response_times.append(result["response_time"])
tokens_per_second_list.append(result["tokens_per_second"])
completion_tokens_list.append(result["completion_tokens"])
prompt_tokens_list.append(result["prompt_tokens"])
total_tokens_list.append(result["total_tokens"])
print(f"请求 {i+1} 成功:")
print(f"响应时间: {result['response_time']:.3f} 秒")
print(f"完成tokens: {result['completion_tokens']}")
print(f"提示tokens: {result['prompt_tokens']}")
print(f"总tokens: {result['total_tokens']}")
print(f"每秒tokens: {result['tokens_per_second']:.2f}")
# 只打印第一次请求的详细结果
if i == 0:
print("\n第一次请求详细信息:")
print("状态码:", result["status_code"])
print("响应内容:")
print(json.dumps(result["result"], indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result["result"] and len(result["result"]["choices"]) > 0:
ai_message = result["result"]["choices"][0]["message"]["content"]
print("\nAI回复:")
print(ai_message)
else:
print(f"请求 {i+1} 失败: {result.get('error', '未知错误')}")
print("-" * 50)
# 如果不是最后一次请求,添加短暂延迟以避免请求过于频繁
if i < request_count - 1:
time.sleep(0.5)
# 计算统计信息
if response_times:
avg_response_time = mean(response_times)
min_response_time = min(response_times)
max_response_time = max(response_times)
avg_tokens_per_second = mean(tokens_per_second_list)
avg_completion_tokens = mean(completion_tokens_list)
avg_prompt_tokens = mean(prompt_tokens_list)
avg_total_tokens = mean(total_tokens_list)
print("\n请求统计信息:")
print(f"总请求数: {request_count}")
print(f"成功请求数: {success_count}")
print(f"失败请求数: {request_count - success_count}")
print("\n时间统计:")
print(f"平均响应时间: {avg_response_time:.3f} 秒")
print(f"最小响应时间: {min_response_time:.3f} 秒")
print(f"最大响应时间: {max_response_time:.3f} 秒")
print("\nToken统计:")
print(f"平均完成tokens: {avg_completion_tokens:.1f}")
print(f"平均提示tokens: {avg_prompt_tokens:.1f}")
print(f"平均总tokens: {avg_total_tokens:.1f}")
print(f"平均每秒tokens: {avg_tokens_per_second:.2f}")
else:
print("\n所有请求均失败,无法计算统计信息。")
if __name__ == "__main__":
main()返回结果中可以看到,诗意,趣味,调侃,生活的方式回答的语句还是不错的。

对比目标——Deepseek-V3
代码部分其中能看到使用的是Deepseek-V3版本,因为这个版本没有think部分。
# coding=utf-8
import requests
import json
import re
import datetime # 添加datetime模块
if __name__ == '__main__':
# 记录请求时间
request_time = datetime.datetime.now()
request_time_str = request_time.strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "PRABeszTlQ_h0SR4Hjs8OkQHJmwRUihQ8I0JPP8kh-eNN2ORnqn189CVSh8f3910oIlhm_EqZEEWL50SG_tCKw" # 把yourApiKey替换成已获取的API Key
# Send request.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model":"DeepSeek-V3", # 模型名称
"messages": [
{"role": "system", "content": """你是一位情话专家,专门帮助男性解决聊天对话的问题,回复的内容都很有诗意,并且很有趣,返回的信息永远让对方有话可接,不会让聊天尬场。
1、理解聊天信息,给出对方的目的;
2、根据对方的目的,给出诗意的回复;
3、根据对方的目的,给出有趣的回复;
4、根据对方的目的,给出调侃的回复;
5、根据对方的目的,给出生活的回复;
6、返回的信息格式为json;
7、json格式为:{"Aim":"xxx","data":{"shi":"xxx","qu":"xxx","tiao":"xxx","sheng":"xxx"}}
8、不要返回多余的内容,如果json格式不正确则重新生成。
此次聊天问题是用户输入的问题。"""},
{"role": "user", "content": "我想你了。"}
],
# 是否开启流式推理, 默认为False, 表示不开启流式推理
"stream": False,
# 在流式输出时是否展示使用的token数目。只有当stream为True时改参数才会生效。
# "stream_options": { "include_usage": True },
# 控制采样随机性的浮点数,值较低时模型更具确定性,值较高时模型更具创造性。"0"表示贪婪取样。默认为0.6。
"temperature": 0.6
}
# 打印请求时间
print(f"请求时间: {request_time_str}")
response = requests.post(url, headers=headers, data=json.dumps(data), verify=False)
# 记录响应时间
response_time = datetime.datetime.now()
response_time_str = response_time.strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
json_str = response.json()['choices'][0]['message']['content']
# 返回效果:
aim = re.search(r'"Aim":\s*"([^"]+)"', json_str).group(1)
shi = re.search(r'"shi":\s*"([^"]+)"', json_str).group(1)
qu = re.search(r'"qu":\s*"([^"]+)"', json_str).group(1)
tiao = re.search(r'"tiao":\s*"([^"]+)"', json_str).group(1)
sheng = re.search(r'"sheng":\s*"([^"]+)"', json_str).group(1)
# 打印响应时间和耗时
print(f"响应时间: {response_time_str}")
print(f"请求耗时: {(response_time - request_time).total_seconds():.3f} 秒")
print("-" * 50)
print(aim)
print(shi)
print(qu)
print(tiao)
print(sheng)访问效果:
为什么选择ERNIE-4.5-21B-A3B-Base作对比
官方给出的信息是:ERNIE-4.5-21B-A3B-Base 是一个文本 MoE 基础模型,总参数量为 21B,每个令牌激活参数量为 3B。
模型信息:
| 关键字 | 值 |
|---|---|
| 模态 | 文本 |
| 训练阶段 | 预训练 |
| 参数量(总/激活) | 21B / 3B |
| 层数 | 28 |
| 头数(Q/KV) | 20 / 4 |
| 文本专家(总/激活) | 64 / 6 |
| 视觉专家(总/激活) | 64 / 6 |
| 共享专家 | 2 |
| 上下文长度 | 131072 |
这个参数对于我们生活中是完全可以正常使用的,如果是0.3B的就话就有些小了。
ERNIE-4.5-21B-A3B-Base-Paddle与DeepSeek-V3返回数据对比
根据两者返回的结果还有具体的请求时间来做个对比。
baidu/ERNIE-4.5-21B-A3B-Base-Paddle消耗时间与返回结果
消耗时间:
3.848 秒
返回结果:
```json
{
"Aim": "表达思念之情",
"data": {
"shi": "相思如梦夜阑珊,明月清风伴我眠。",
"qu": "你可知道,我的思念如潮水般涌来,淹没了心田。",
"tiao": "哎呀,你这突然的想念,可让我这颗心啊,七上八下的,跟坐过山车似的。",
"sheng": "每次听到你这么说,我都觉得,这世界上的美好,都因为你而更加绚烂。"
}
}
```
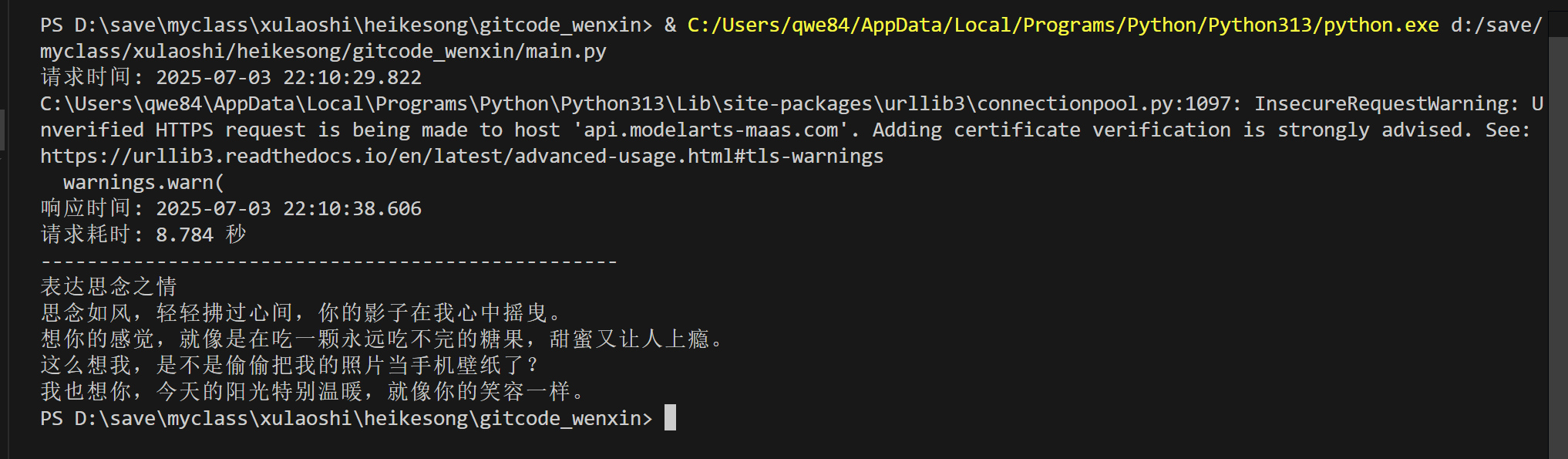
DeepSeek-V3消耗时间与返回结果
消耗时间:
8.784 秒
返回结果:
表达思念之情
思念如风,轻轻拂过心间,你的影子在我心中摇曳。
想你的感觉,就像是在吃一颗永远吃不完的糖果,甜蜜又让人上瘾。
这么想我,是不是偷偷把我的照片当手机壁纸了?
我也想你,今天的阳光特别温暖,就像你的笑容一样。
看着差不多,但是具体哪个好还是要分一个高下的,我们这里用豆包做一个评分者吧。
公平对比
这里我们用的是豆包做的对比,问题是:
对比一下两个模型的结果,哪个更好,给我返回一个md的表格,最终给出哪个更优秀。
返回md:
| 模型名称 | 消耗时间 | 返回结果 |
|---|---|---|
| baidu/ERNIE-4.5-21B-A3B-Base-Paddle | 3.848 秒 | 以 JSON 格式呈现,结构清晰,诗词形式的表达富有文采,语言风格多样,涵盖较为正式和口语化表述 |
| DeepSeek-V3 | 8.784 秒 | 文本形式,语言较为平实、亲切,情感表达直白 |
返回结果:
在时间效率上,baidu/ERNIE-4.5-21B-A3B-Base-Paddle 明显更优,耗时仅为 DeepSeek-V3 的约 43.8% 。在结果呈现方面,baidu/ERNIE-4.5-21B-A3B-Base-Paddle 以 JSON 结构化输出,更便于程序解析和后续处理,且内容富有文采;DeepSeek-V3 表述亲切自然,但形式上相对简单。综合来看,baidu/ERNIE-4.5-21B-A3B-Base-Paddle 在此次对比中表现更优秀。
实图证明:

总结
我们用豆包来做最后的评委,我觉得还是很公平的,毕竟是第三方评判,证明了ERNIE-4.5-21B-A3B-Base-Paddle在这场暖男聊天黑科技中的表现非常的亮眼,我宣布,本次测评开源的ERNIE-4.5-21B-A3B-Base-Paddle获得胜利。
最后,我他为我们这些还相信爱的人们【为爱情写一首现代文。】
爱情,是一种最美好、最纯粹的情感,是人类文明发展历程中不可或缺的一部分。在这个快节奏、高压的社会里,爱情更是显得尤为珍贵。
爱情是两个人之间的情感交流,是一种相互扶持、相互理解的默契。它像一股清泉,能够洗涤人心中的疲惫和烦恼,让人感到温暖和幸福。
爱情是生命中最美好的礼物,它能够让人感到快乐、幸福和满足。在爱情的世界里,我们可以放下一切顾虑,尽情地享受生命的美好。
爱情需要付出和包容,需要相互理解和支持。只有当两个人相互信任、相互扶持,才能够共同走过人生的每一个阶段。
爱情是生命中最珍贵的财富,它能够让我们感受到生命的意义和价值。在爱情的世界里,我们可以找到自己的归宿,找到生命的意义和价值。
因此,让我们珍惜爱情,用心去感受它的美好,让它成为我们生命中最美好的回忆。



















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











