



自动驾驶的深度强化学习方法
摘要
本文描述了一种用于自动驾驶汽车的控制系统。该控制系统基于深度神经网络。由于无法预先形成高质量的训练样本,因此考虑使用强化学习。文中还描述了建模环境实现的可能方案。
自引动言驾
驶是近年来取得显著进展的热门研究领域,由于其在安全性和效率方面的提升,未来可能在交通系统中发挥重要作用。目前,具备一定程度自主性的先进控制系统已应用于消费级汽车中。该领域的一个关键挑战在于难以应对罕见且未曾见过的情况,因为这些情况遵循非常长尾的分布。相比之下,以端到端方式学习整个自动驾驶系统堆栈,为实现更高水平的自主性提供了一种更具可扩展性的途径。最近的研究已成功利用模仿学习通过模仿人类驾驶员的行为来训练智能体。尽管这种方法已被证明有效且易于训练,但它需要大量数据,并且在分布外情境下的泛化能力较差。配备自动驾驶模块的现代汽车是一种相当复杂的设备,包含多个组件 [1]。
问题的表述
一个典型的自动驾驶系统由用于感知与控制的不同模块组成。该驾驶系统还包含若干手工设计的逻辑规则,以分别应对可能遇到的各种情况。主要模块包括:
- 计算设备。通常,它是一台具有网络访问功能的相当强大的计算机。其主要任务是根据来自所有传感器的信息生成控制信号。
- 卫星导航系统。该子系统还具有高精度数字地图。该子系统提供物体在轨迹上的位置信息。
- 激光雷达用于提供车辆相对于周围物体的距离信息
- 视觉摄像头。它用于获取道路实时状况的信息。
- 执行装置。根据设计,该装置可以是向汽车车载计算机发送信号的独立电子单元,也可以是模拟真实人类动作的机械装置。

所有传感器可分为两类:产生适合分析的信息(激光雷达和卫星导航系统)和产生非结构化信息(视觉系统)。最近,神经网络在视频和图像分析方面表现最为有效。已经出现了能够解决各种问题的最先进的网络架构:图像中图像的识别、在视频流中跟踪物体、分析视频流以搜索异常 [2][3]。神经网络的主要特点是能够接收多种数据组合——如视频流与来自激光雷达和卫星系统的信息,并立即生成控制信号 [4]。
解决这类问题需要高质量的训练样本。训练样本是包含输入‐输出对的样本数组。这种方法对于自动驾驶并不理想。要创建涵盖道路上所有可能情况及其正确解决方案的大量数组是不可能的。特别是在汽车行驶过程中存在动态因素,使得这一问题更加复杂。因此,提出了强化学习方案 [4][5]。
训练方案:强化学习
强化学习包括训练机器学习模型以做出一系列决策。智能体在不确定且可能复杂的环境中学习实现目标。在强化学习中,人工智能面临一种类似游戏的情境。计算机通过试错来找出问题的解决方案。为了促使机器完成程序员期望的任务,人工智能会因其行为而获得奖励或惩罚。其目标是最大化总奖励。
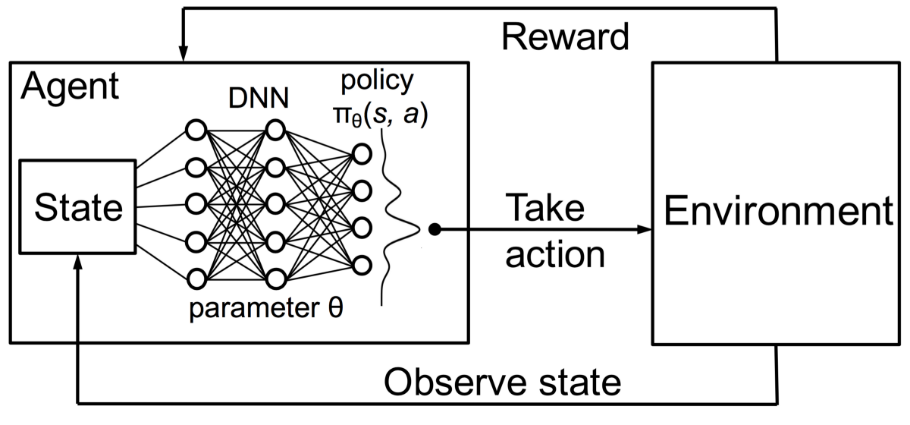
尽管他设定了奖励策略,也就是游戏规则,但他并未给模型提供任何关于如何解决游戏的提示或建议。模型必须自行找出完成任务以最大化奖励的方法,从完全随机的试验开始,最终发展出复杂战术和超人类技能。通过利用搜索能力和多次试验,强化学习目前是展现机器创造力的最有效方式。与人类不同,如果在足够强大的计算机基础设施上运行强化学习算法,人工智能可以从数千次并行的游戏过程中积累经验。
在数学中,我们有一个模型:
$ S_t = \text{Env}(S_{t-1}, u_t) $
其中 $\text{Env}$ — 环境的模型,
$ u_t $ — 控制信号
环境获得一个奖励:
$ R_t = R(S_t) $,$ R $ — 奖励的模型。
奖励是一个负的离散值,表示智能体的错误:绝对值越大,智能体犯下的危险错误越严重。该值由专家指定:例如,碰撞为 -100,超速为 -10,以此类推。
训练神经网络的目标是在经过足够多的迭代后最大化奖励:
$$
\arg\max \sum \gamma^i R_i \quad \text{其中} \quad \text{Env}, \text{NN}(\theta, y, u), \gamma^i \text{— 折扣,神经网络}(\theta)\text{,}\theta \text{— 神经网络(智能体)的模型}
$$
$ y_i $ — 可观测状态
在这种情况下,神经网络权重的修改发生在每次迭代结束时。实现算法如下:
初始神经网络 NN(θ, S)
当回合未结束时执行
对于 t=0..30 秒执行
获取奖励 R_{t-1} 和可观测状态 y_t
神经网络生成控制信号 u_t = NN(θ, y_t, R_{t-1})
为调优神经网络添加数组 {y_{t-1}, y_t, R_{t-1}, u_t}
调优神经网络
end
将奖励追加到日志数组中
end
环境的实现:强化学习的主要挑战
训练的关键在于准备模拟环境。当模型需要在国际象棋、围棋或雅达利游戏中达到超越人类的水平时,准备模拟环境相对简单。但当涉及创建能够驾驶自动驾驶汽车的模型时,在让汽车上路之前,构建一个真实感模拟器至关重要。模型必须在一个安全的环境中学会如何刹车或避免碰撞,即使在此过程中牺牲数千辆汽车,成本也是最低的。而将模型从训练环境转移到现实世界,才是最具挑战性的部分。[6]
在本研究中,我们使用CARLA(汽车学习行动)——一个用于城市驾驶的开放模拟器。CARLA从零开始开发,旨在支持自动驾驶模型的训练、原型设计和验证,涵盖感知与控制两方面。CARLA是一个开放平台。独特的是,CARLA提供的城市环境内容也是免费的。这些内容由专门为此雇佣的一支数字艺术家团队从头创作,包括城市布局、多种车辆模型、建筑物、行人、交通标志等。该仿真平台支持灵活配置传感器套件,并提供可用于训练驾驶策略的信号,例如GPS坐标、速度、加速度以及有关碰撞和其他违规行为的详细数据。可设置广泛的环境条件,包括天气和一天中的时间。[7]
智能体的实现
智能体基于卷积神经网络,由三个卷积层级联而成,每个卷积层均配有一个池化层,输出端为一个全连接层。每回合的网络训练需要20个训练轮次,500个回合足以训练一个智能体。
结论
使用强化学习,可以训练一个神经网络,利用整个数据集(包括视频流、激光雷达和卫星导航系统的坐标)来控制移动物体。通过开放标准,训练好的模型可以在全尺寸模型上进行测试,而无需担心设计阶段未预见的情况。同时,训练样本的构建和标注成本将降至最低。

















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









