









搭建一个能够调用cublas函数的环境中编译运行:
//#include "device_launch_parameters.h"
#include <cublas_v2.h>
#include <cuda_runtime.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int printMatrix(char* matrixName, int m, int n, float* a_matrix, int lda) {
printf("\n%s =\n", matrixName);
for (int i = 0; i < m; i++) {
printf("\n");
for (int j = 0; j < n; j++) {
printf(" %8.5f ", a_matrix[i + j * lda]);
}
}
printf("\n");
return 0;
}
void printVector(const char* log, int* Vector, int size) {
printf("\n%s\n",log);
for (int i = 0; i < size; i++) {
printf(" %d ", Vector[i]);
}
printf("\n");
}
void initMatrix(float* A, int dim, int seed) {
srand(2022 + seed);
printf("Starting Init Matrix ...\n");
for (int i = 0; i < dim * dim; i++) {
A[i] = (float)((rand() % 100) - 50) / 100.0 + 1.0;
//LL:: printf("A[%d]=%f ",i,A[i]);
}
printf("Init is OK.\n");
}
void do_dgemm(int M, int N, int K, float* A, int lda, float* B, int ldb, float* C, int ldc) {
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
C[i + j * ldc] = 0.0; //C(i,j)=0.0;
for (int k = 0; k < K; k++) {
//C(i,j) = ΣA(i,k)B(k,j) k=0,1, ... ,K-1
C[i + j * ldc] += A[i + k * lda] * B[k + j * ldb];
}
}
}
}
float* d_Get3DInv(float* A, int n, int batchedSize)
{
cublasHandle_t cu_cublasHandle;
cublasCreate(&cu_cublasHandle);
float** AarrayDev;
float** CarrayDev;
float** AarrayHost=NULL;
AarrayHost = (float**)malloc(batchedSize * sizeof(float*));
float** CarrayHost = NULL;
CarrayHost = (float**)malloc(batchedSize * sizeof(float*));
float* A_data_dev;
float* C_data_dev;
int* LUPivots_dev;
int* LUInfo_dev;
size_t size_data_A = batchedSize * n * n * sizeof(float);
cudaMalloc(&AarrayDev, batchedSize * sizeof(float*));
cudaMalloc(&CarrayDev, batchedSize * sizeof(float*));
//cudaMalloc(&adC, sizeof(float*));
cudaMalloc(&A_data_dev, size_data_A);
for (int i = 0; i < batchedSize; i++) {
AarrayHost[i] = A_data_dev + i * n * n;
}
cudaMalloc(&C_data_dev, size_data_A);
for (int i = 0; i < batchedSize; i++) {
CarrayHost[i] = C_data_dev + i * n * n;
}
cudaMalloc(&LUPivots_dev, batchedSize * n * sizeof(int));
cudaMalloc(&LUInfo_dev, batchedSize * sizeof(int));
cudaMemcpy(A_data_dev, A, size_data_A, cudaMemcpyHostToDevice);
cudaMemcpy(AarrayDev, AarrayHost, batchedSize*sizeof(float*), cudaMemcpyHostToDevice);
cudaMemcpy(CarrayDev, CarrayHost, batchedSize*sizeof(float*), cudaMemcpyHostToDevice);
cublasSgetrfBatched(cu_cublasHandle, n, AarrayDev, n, LUPivots_dev, LUInfo_dev, batchedSize);
cudaDeviceSynchronize();
float* resGETRF = (float*)malloc(size_data_A);
cudaMemcpy(resGETRF, A_data_dev, size_data_A, cudaMemcpyDeviceToHost);
int* pivot = (int*)malloc(n * batchedSize*sizeof(int));
cudaMemcpy(pivot, LUPivots_dev, n * batchedSize*sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < batchedSize; i++) {
printVector("Pivot",pivot+i*n,n);
}
for (int i = 0; i < batchedSize; i++) {
printMatrix("Matrix A_LU", n, n, resGETRF+i*n*n, n);
}
cublasSgetriBatched(cu_cublasHandle, n, (const float**)AarrayDev, n, LUPivots_dev, CarrayDev, n, LUInfo_dev, batchedSize);
cudaDeviceSynchronize();
float* res = (float*)malloc(size_data_A);
cudaMemcpy(res, C_data_dev, size_data_A, cudaMemcpyDeviceToHost);
cudaFree(LUInfo_dev);
cudaFree(LUPivots_dev);
cudaFree(C_data_dev);
cudaFree(A_data_dev);
cudaFree(CarrayDev);
cudaFree(AarrayDev);
cublasDestroy(cu_cublasHandle);
free(AarrayHost);
free(CarrayHost);
return res;
}
int main(int argc, char* argv[]) {
int n = 5;
int batchedSize = 2;
int J = 1;
float* A = (float*)malloc(batchedSize * n * n * sizeof(float));
for (int i = 0; i < batchedSize; i++) {
initMatrix(A + i * n * n, n, i);
}
for (int i = 0; i < batchedSize; i++) {
printMatrix("Matrix A", n, n, A + i*n*n, n);
}
float* inv = d_Get3DInv(A, n, batchedSize);
for (int i = 0; i < batchedSize; i++) {
printMatrix("Matrix A'", n, n, inv+i*n*n, n);
}
float* C_gemm = (float*)malloc(n * n * sizeof(float));
for (int i = 0; i < batchedSize; i++) {
do_dgemm(n, n, n, A+i*n*n, n, inv+i*n*n, n, C_gemm, n);
printMatrix("Matrix A*A'", n, n, C_gemm, n);
}
free(C_gemm);
if (inv != NULL) {
free(inv);
inv = NULL;
}
free(A);
return 0;
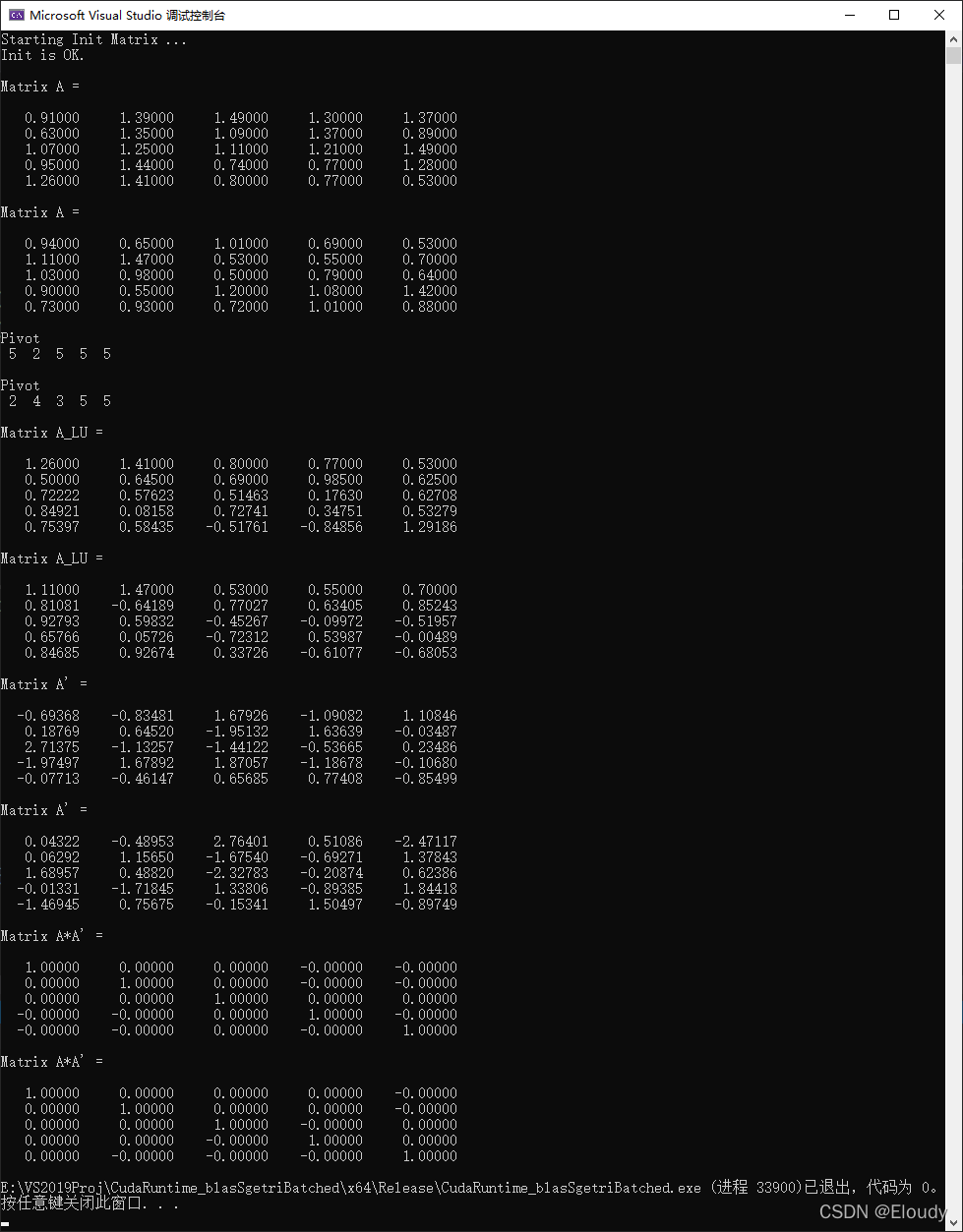
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









