



- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、 前期准备
1. 导入库
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
import os,PIL,random,pathlib
import torch.nn.functional as F
from PIL import Image
import matplotlib.pyplot as plt
#隐藏警告
import warnings
2.导入数据
data_dir = './data/4-data/'
data_dir = pathlib.Path(data_dir)
#print(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
#print(classeNames)
total_datadir = './data/4-data/'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
3.划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
二、模型设计
1. 神经网络的搭建
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*50*50, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
2.设置损失值等超参数
model = Network_bn()
#print(device)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
3. 设置训练函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
4. 设置测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
5. 创建导入本地图片预处理模块
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
# plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
6. 主函数
if __name__ == '__main__':
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
epochs_range = range(epochs)
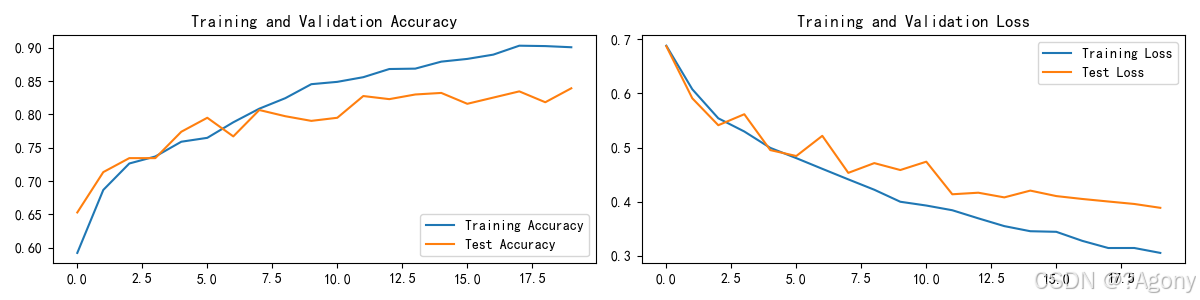
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
classes = list(total_data.class_to_idx)
predict_one_image(image_path='./data/4-data/Monkeypox/M01_01_00.jpg',
model=model,
transform=train_transforms,
classes=classes)
结果
Epoch: 1, Train_acc:59.2%, Train_loss:0.688, Test_acc:65.3%,Test_loss:0.687
Epoch: 2, Train_acc:68.7%, Train_loss:0.608, Test_acc:71.3%,Test_loss:0.591
Epoch: 3, Train_acc:72.6%, Train_loss:0.554, Test_acc:73.4%,Test_loss:0.541
Epoch: 4, Train_acc:73.7%, Train_loss:0.530, Test_acc:73.4%,Test_loss:0.562
Epoch: 5, Train_acc:75.9%, Train_loss:0.499, Test_acc:77.4%,Test_loss:0.495
Epoch: 6, Train_acc:76.5%, Train_loss:0.480, Test_acc:79.5%,Test_loss:0.484
Epoch: 7, Train_acc:78.8%, Train_loss:0.461, Test_acc:76.7%,Test_loss:0.522
Epoch: 8, Train_acc:80.9%, Train_loss:0.441, Test_acc:80.7%,Test_loss:0.453
Epoch: 9, Train_acc:82.4%, Train_loss:0.422, Test_acc:79.7%,Test_loss:0.471
Epoch:10, Train_acc:84.5%, Train_loss:0.400, Test_acc:79.0%,Test_loss:0.459
Epoch:11, Train_acc:84.9%, Train_loss:0.393, Test_acc:79.5%,Test_loss:0.474
Epoch:12, Train_acc:85.6%, Train_loss:0.384, Test_acc:82.8%,Test_loss:0.414
Epoch:13, Train_acc:86.8%, Train_loss:0.369, Test_acc:82.3%,Test_loss:0.417
Epoch:14, Train_acc:86.9%, Train_loss:0.355, Test_acc:83.0%,Test_loss:0.408
Epoch:15, Train_acc:87.9%, Train_loss:0.346, Test_acc:83.2%,Test_loss:0.421
Epoch:16, Train_acc:88.3%, Train_loss:0.344, Test_acc:81.6%,Test_loss:0.410
Epoch:17, Train_acc:89.0%, Train_loss:0.328, Test_acc:82.5%,Test_loss:0.405
Epoch:18, Train_acc:90.3%, Train_loss:0.315, Test_acc:83.4%,Test_loss:0.400
Epoch:19, Train_acc:90.3%, Train_loss:0.315, Test_acc:81.8%,Test_loss:0.396
Epoch:20, Train_acc:90.1%, Train_loss:0.305, Test_acc:83.9%,Test_loss:0.389
Done
- 传入的图片是:
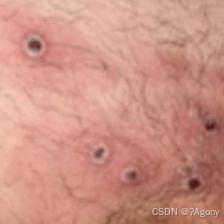
- 得到的预测结果:
预测结果是:Monkeypox
三、心得
经过本周的学习,主要掌握了如何保存训练好的模型和参数,得到的结果可以不用像上周一样每次要执行预测的图片还要把上面的代码重新运行一下了


















 3017
3017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









