



- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
使用InceptionV3实现天气识别
一、模型结构
Inception v3是Google团队在2015年提出的第三代Inception模型,属于卷积神经网络(CNN)的经典架构之一,主要用于图像分类任务。它在Inception v1(即GoogLeNet)的基础上进行了多项优化,显著提升了模型性能和计算效率。以下是Inception v3的核心特点及其与v1的主要区别:
Inception v3的核心改进
-
卷积核分解与优化
- 对称分解:将大卷积核(如5×5)分解为多个小卷积核(如两个3×3),减少参数量的同时保持感受野范围。例如,5×5卷积分解为两个3×3卷积,参数量减少约28%。
- 非对称分解:进一步将3×3卷积分解为1×3和3×1的串联结构,减少计算成本(例如,3×3卷积分解后计算量降低33%)。这种设计不仅节约参数,还能捕获更丰富的空间特征。
-
高效的网格尺寸缩减(Grid Size Reduction)
- 通过结合步长为2的卷积层和池化层,并行处理特征图后再拼接,避免信息丢失。例如,使用3×3卷积(步长2)和3×3最大池化(步长2)并行,扩大特征图通道数同时缩小尺寸。
-
正则化与训练策略
- 标签平滑(Label Smoothing):通过软化标签(如将正确标签从1改为0.9,其他类别均分0.1),减少模型过拟合,提升泛化能力。
- 批量归一化(Batch Normalization):广泛用于卷积层后,加速训练收敛并提高稳定性。
- 优化器改进:采用RMSProp替代传统SGD,自适应调整学习率,提升训练效率。
-
模块化设计
- Inception v3包含三种不同结构的Inception模块(35×35、17×17、8×8网格),分别用于处理不同尺度的特征图。模块内部进一步引入分支中的分支(如1×3和3×1卷积的组合),形成更复杂的非线性表达。
Inception v3与v1的主要区别
| 特性 | Inception v1 | Inception v3 |
|---|---|---|
| 卷积核分解 | 无 | 引入对称与非对称分解(如3×3→1×3+3×1) |
| 网络深度 | 22层(含9个Inception模块) | 46层(含11个Inception模块) |
| 正则化技术 | 无批量归一化,使用辅助分类器缓解梯度消失 | 批量归一化 + 标签平滑 + 辅助分类器正则化 |
| 计算效率 | 5×5卷积计算成本高 | 通过分解卷积核降低计算量,参数量减少约30% |
| 错误率(ImageNet) | Top-5错误率6.67% | Top-5错误率3.5% |
| 模块设计 | 基础Inception模块(含1×1、3×3、5×5卷积) | 复杂模块(如非对称卷积、多分支组合) |
关键改进的意义
- 性能提升:通过卷积分解和模块优化,v3在保持较低计算成本的同时,显著降低了分类错误率(较v1提升近50%)。
- 灵活性增强:非对称卷积和模块化设计使模型能更灵活地捕捉多尺度特征,适应不同输入尺寸。
- 训练稳定性:批量归一化和标签平滑等技术有效缓解了过拟合,加速了模型收敛。
程序结构图
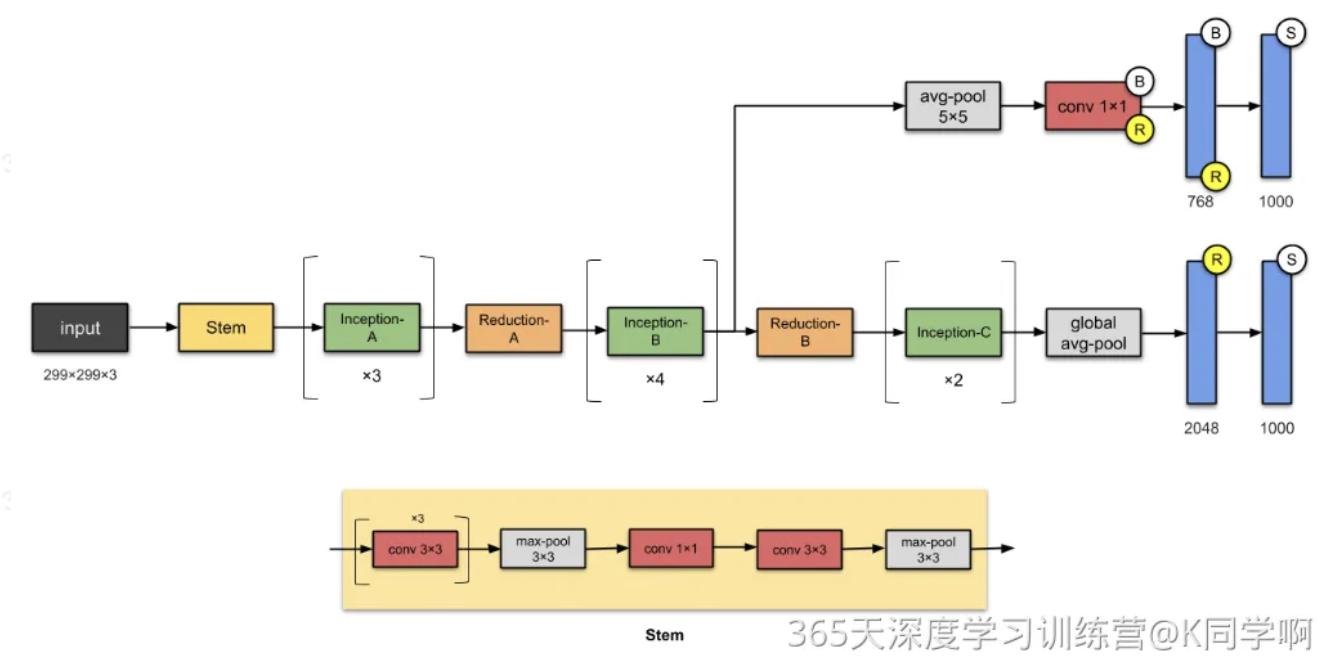
二、 前期准备
1. 导入库
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
import os,PIL,random,pathlib
import torch.nn.functional as F
from PIL import Image
import matplotlib.pyplot as plt
#隐藏警告
import warnings
2.导入数据
data_dir = './data/4-data/'
data_dir = pathlib.Path(data_dir)
#print(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
#print(classeNames)
total_datadir = './data/4-data/'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
3.划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
三、模型设计
1. 神经网络的搭建
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features):
super(InceptionA, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1) # 1
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionB(nn.Module):
def __init__(self, in_channels, channels_7x7):
super(InceptionB, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionC(nn.Module):
def __init__(self, in_channels):
super(InceptionC, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 320, kernel_size=1)
self.branch3x3_1 = BasicConv2d(in_channels, 384, kernel_size=1)
self.branch3x3_2a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = BasicConv2d(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class ReductionA(nn.Module):
def __init__(self, in_channels):
super(ReductionA, self).__init__()
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class ReductionB(nn.Module):
def __init__(self, in_channels):
super(ReductionB, self).__init__()
self.branch3x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch3x3_2 = BasicConv2d(192, 320, kernel_size=3, stride=2)
self.branch7x7x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch7x7x3_2 = BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7x3_3 = BasicConv2d(192, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7x3_4 = BasicConv2d(192, 192, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch7x7x3 = self.branch7x7x3_1(x)
branch7x7x3 = self.branch7x7x3_2(branch7x7x3)
branch7x7x3 = self.branch7x7x3_3(branch7x7x3)
branch7x7x3 = self.branch7x7x3_4(branch7x7x3)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch7x7x3, branch_pool]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.conv0 = BasicConv2d(in_channels, 128, kernel_size=1)
self.conv1 = BasicConv2d(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001
def forward(self, x):
# 17 x 17 x 768
x = F.avg_pool2d(x, kernel_size=5, stride=3)
# 5 x 5 x 768
x = self.conv0(x)
# 5 x 5 x 128
x = self.conv1(x)
# 1 x 1 x 768
x = x.view(x.size(0), -1)
# 768
x = self.fc(x)
# 1000
return x
import torch.nn.functional as F
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class InceptionV3(nn.Module):
def __init__(self, num_classes=1000, aux_logits=False, transform_input=False):
super(InceptionV3, self).__init__()
self.aux_logits = aux_logits
self.transform_input = transform_input
self.Conv2d_1a_3x3 = BasicConv2d(3, 32, kernel_size=3, stride=2)
self.Conv2d_2a_3x3 = BasicConv2d(32, 32, kernel_size=3)
self.Conv2d_2b_3x3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
self.Conv2d_3b_1x1 = BasicConv2d(64, 80, kernel_size=1)
self.Conv2d_4a_3x3 = BasicConv2d(80, 192, kernel_size=3)
self.Mixed_5b = InceptionA(192, pool_features=32)
self.Mixed_5c = InceptionA(256, pool_features=64)
self.Mixed_5d = InceptionA(288, pool_features=64)
self.Mixed_6a = ReductionA(288)
self.Mixed_6b = InceptionB(768, channels_7x7=128)
self.Mixed_6c = InceptionB(768, channels_7x7=160)
self.Mixed_6d = InceptionB(768, channels_7x7=160)
self.Mixed_6e = InceptionB(768, channels_7x7=192)
if aux_logits:
self.AuxLogits = InceptionAux(768, num_classes)
self.Mixed_7a = ReductionB(768)
self.Mixed_7b = InceptionC(1280)
self.Mixed_7c = InceptionC(2048)
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
if self.transform_input: # 1
x = x.clone()
x[:, 0] = x[:, 0] * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x[:, 1] = x[:, 1] * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x[:, 2] = x[:, 2] * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
# 299 x 299 x 3
x = self.Conv2d_1a_3x3(x)
# 149 x 149 x 32
x = self.Conv2d_2a_3x3(x)
# 147 x 147 x 32
x = self.Conv2d_2b_3x3(x)
# 147 x 147 x 64
x = F.max_pool2d(x, kernel_size=3, stride=2)
# 73 x 73 x 64
x = self.Conv2d_3b_1x1(x)
# 73 x 73 x 80
x = self.Conv2d_4a_3x3(x)
# 71 x 71 x 192
x = F.max_pool2d(x, kernel_size=3, stride=2)
# 35 x 35 x 192
x = self.Mixed_5b(x)
# 35 x 35 x 256
x = self.Mixed_5c(x)
# 35 x 35 x 288
x = self.Mixed_5d(x)
# 35 x 35 x 288
x = self.Mixed_6a(x)
# 17 x 17 x 768
x = self.Mixed_6b(x)
# 17 x 17 x 768
x = self.Mixed_6c(x)
# 17 x 17 x 768
x = self.Mixed_6d(x)
# 17 x 17 x 768
x = self.Mixed_6e(x)
# 17 x 17 x 768
if self.training and self.aux_logits:
aux = self.AuxLogits(x)
# 17 x 17 x 768
x = self.Mixed_7a(x)
# 8 x 8 x 1280
x = self.Mixed_7b(x)
# 8 x 8 x 2048
x = self.Mixed_7c(x)
# 8 x 8 x 2048
x = F.avg_pool2d(x, kernel_size=8)
# 1 x 1 x 2048
x = F.dropout(x, training=self.training)
# 1 x 1 x 2048
x = x.view(x.size(0), -1)
# 2048
x = self.fc(x)
# 1000 (num_classes)
if self.training and self.aux_logits:
return x, aux
return x
#model = InceptionV3().to(device)
2.设置损失值等超参数
# 修改3: 初始化InceptionV3模型
model = InceptionV3(
num_classes=len(classeNames), # 适配数据集类别数
aux_logits=False, # 禁用辅助分类器
transform_input=False # 禁用内置输入转换
).to(device)
print(summary.summary(model, (3, 299, 299)))
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-4
# 修改4: 推荐使用Adam优化器
opt = torch.optim.Adam(model.parameters(), lr=learn_rate, weight_decay=1e-4)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 149, 149] 864
BatchNorm2d-2 [-1, 32, 149, 149] 64
BasicConv2d-3 [-1, 32, 149, 149] 0
Conv2d-4 [-1, 32, 147, 147] 9,216
BatchNorm2d-5 [-1, 32, 147, 147] 64
BasicConv2d-6 [-1, 32, 147, 147] 0
Conv2d-7 [-1, 64, 147, 147] 18,432
BatchNorm2d-8 [-1, 64, 147, 147] 128
BasicConv2d-9 [-1, 64, 147, 147] 0
.... .....
BatchNorm2d-288 [-1, 384, 8, 8] 768
BasicConv2d-289 [-1, 384, 8, 8] 0
Conv2d-290 [-1, 192, 8, 8] 393,216
BatchNorm2d-291 [-1, 192, 8, 8] 384
BasicConv2d-292 [-1, 192, 8, 8] 0
InceptionC-293 [-1, 2048, 8, 8] 0
Linear-294 [-1, 4] 8,196
================================================================
Total params: 21,793,764
Trainable params: 21,793,764
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 1.02
Forward/backward pass size (MB): 224.12
Params size (MB): 83.14
Estimated Total Size (MB): 308.28
----------------------------------------------------------------
3. 设置训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train()
total_loss, correct = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
return correct / len(dataloader.dataset), total_loss / len(dataloader)
4. 设置测试函数
def test(dataloader, model, loss_fn):
model.eval()
total_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
total_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
return correct / len(dataloader.dataset), total_loss / len(dataloader)
5. 创建导入本地图片预处理模块
def preprocess_image(image_path):
transform = transforms.Compose([
transforms.Resize([299, 299]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = Image.open(image_path).convert('RGB') # 确保RGB格式
return transform(image).unsqueeze(0).to(device)
6. 主函数
if __name__ == '__main__':
epochs = 10
train_acc, train_loss = [], []
test_acc, test_loss = [], []
for epoch in range(epochs):
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 记录指标
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 打印进度
print(f"Epoch {epoch + 1}/{epochs}")
print(f"Train Acc: {epoch_train_acc * 100:.2f}% | Test Acc: {epoch_test_acc * 100:.2f}%")
print(f"Train Loss: {epoch_train_loss:.4f} | Test Loss: {epoch_test_loss:.4f}\n")
# 保存模型
torch.save(model.state_dict(), "inceptionv3_weather.pth")
# 示例预测
test_image = preprocess_image('./data/img.jpg')
with torch.no_grad():
output = model(test_image)
prediction = classeNames[output.argmax().item()]
print(f"\nFinal Prediction: {prediction}")
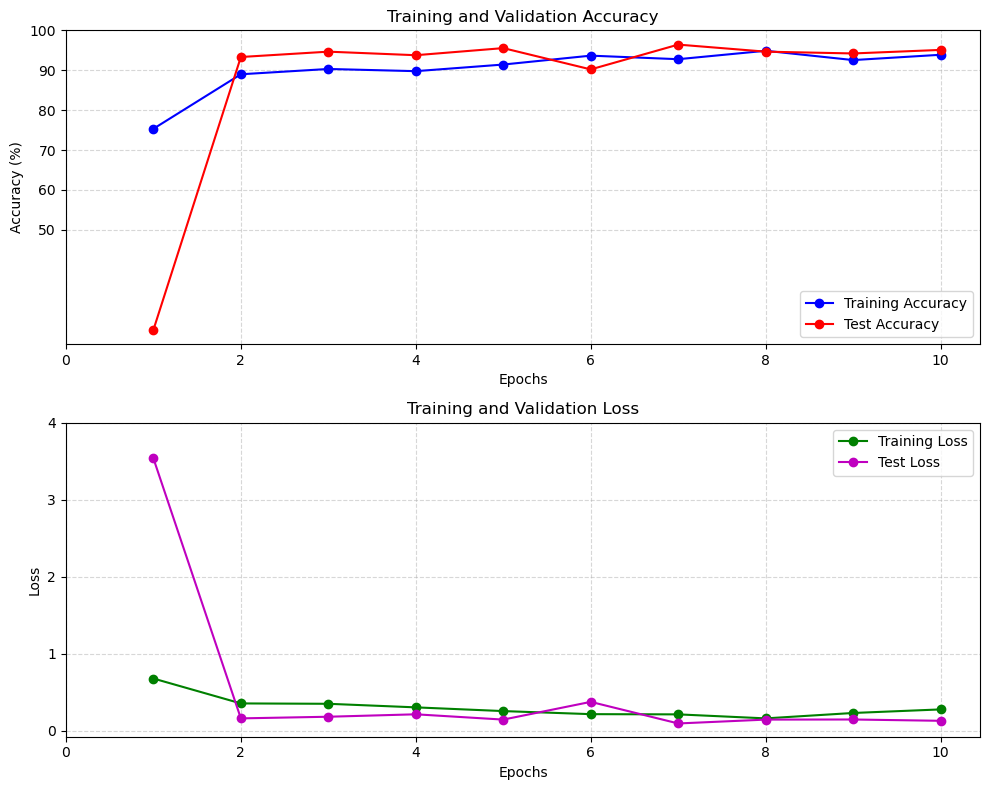
结果
Epoch 1/10
Train Acc: 75.33% | Test Acc: 24.89%
Train Loss: 0.6807 | Test Loss: 3.5399
Epoch 2/10
Train Acc: 89.00% | Test Acc: 93.33%
Train Loss: 0.3573 | Test Loss: 0.1631
Epoch 3/10
Train Acc: 90.33% | Test Acc: 94.67%
Train Loss: 0.3525 | Test Loss: 0.1844
Epoch 4/10
Train Acc: 89.78% | Test Acc: 93.78%
Train Loss: 0.3061 | Test Loss: 0.2160
Epoch 5/10
Train Acc: 91.44% | Test Acc: 95.56%
Train Loss: 0.2578 | Test Loss: 0.1473
Epoch 6/10
Train Acc: 93.67% | Test Acc: 90.22%
Train Loss: 0.2180 | Test Loss: 0.3774
Epoch 7/10
Train Acc: 92.78% | Test Acc: 96.44%
Train Loss: 0.2151 | Test Loss: 0.0971
Epoch 8/10
Train Acc: 94.89% | Test Acc: 94.67%
Train Loss: 0.1631 | Test Loss: 0.1472
Epoch 9/10
Train Acc: 92.56% | Test Acc: 94.22%
Train Loss: 0.2332 | Test Loss: 0.1486
Epoch 10/10
Train Acc: 93.89% | Test Acc: 95.11%
Train Loss: 0.2795 | Test Loss: 0.1317

















 2997
2997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









