







该系列文章与qwe、Dorothea一同创作,喜欢的话不妨点个赞。
接上面的文章,目光聚焦回在main.cpp中。create_core、update后,基本上内存开辟、内存赋值、预计算等前期准备工作都准备的差不多了。
后续是输入数据的加载和预处理。
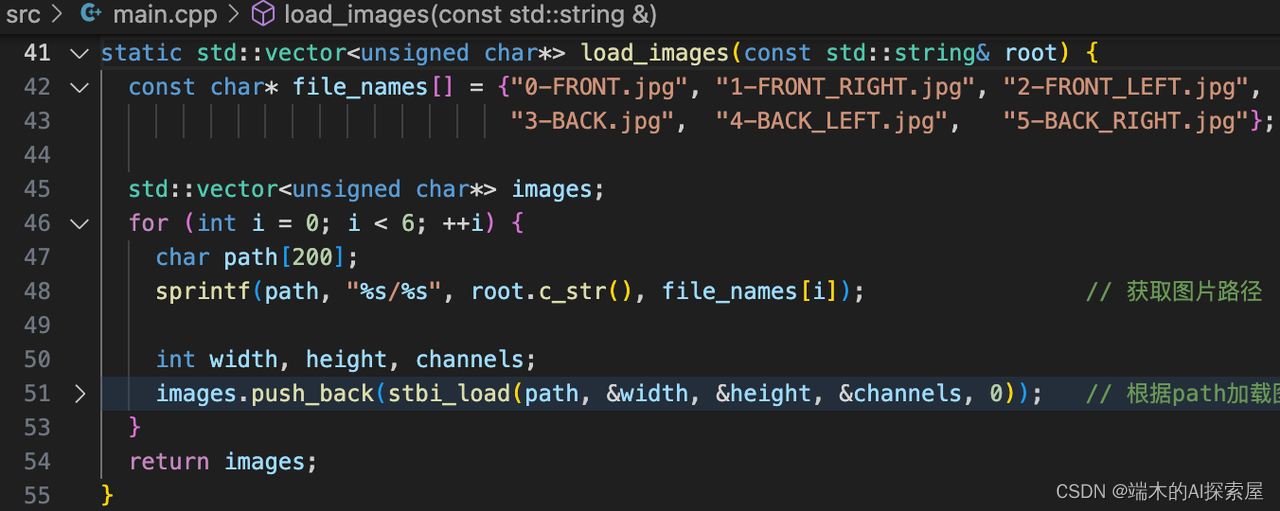
加载图像数据
255行加载图片,data是准备好的6张图片数据数据。通过stbi_load加载图片。把六张图片存储到vector容器中。

加载点云数据
点云数据的加载使用了nvidia提供在common文件夹下的nv::Tensor中加载。

模型推理并计时
预热操作
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.35738 ms
[⏰ [NoSt] ImageNrom]: 2.46902 ms
[⏰ Lidar Backbone]: 5.27267 ms
[⏰ Camera Depth]: 0.03472 ms
[⏰ Camera Backbone]: 88.00665 ms
[⏰ Camera Bevpool]: 0.33485 ms
[⏰ VTransform]: 9.40954 ms
[⏰ Transfusion]: 15.54534 ms
[⏰ Head BoundingBox]: 6.94374 ms
Total: 125.548 ms
=============================================
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.35331 ms
[⏰ [NoSt] ImageNrom]: 2.57843 ms
[⏰ Lidar Backbone]: 2.65114 ms
[⏰ Camera Depth]: 0.04096 ms
[⏰ Camera Backbone]: 2.36442 ms
[⏰ Camera Bevpool]: 0.31027 ms
[⏰ VTransform]: 0.55091 ms
[⏰ Transfusion]: 1.48685 ms
[⏰ Head BoundingBox]: 3.26451 ms
Total: 10.669 ms
=============================================
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.31674 ms
[⏰ [NoSt] ImageNrom]: 2.36669 ms
[⏰ Lidar Backbone]: 2.64192 ms
[⏰ Camera Depth]: 0.02867 ms
[⏰ Camera Backbone]: 2.35008 ms
[⏰ Camera Bevpool]: 0.30925 ms
[⏰ VTransform]: 0.55398 ms
[⏰ Transfusion]: 1.48275 ms
[⏰ Head BoundingBox]: 3.26848 ms
Total: 10.635 ms
======================================= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2259
2259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









