







目录
该系列文章与qwe、Dorothea一同创作,喜欢的话不妨点个赞。
接下来,是bevfusion中,另一个非常重要的部分- - -update。
create_core 是配置参数,反序列化engine,为输出分配内存。
update就是在正式进行forward前,做好其余工作。包括以下几点:
- 为矩阵赋值,矩阵计算、矩阵的逆运算
- 预计算(认为视锥点与360 * 360 * 1的体素格子之间的映射关系,在模型推理前就能计算出来。)
更新 bevfusion::Core 中的变换矩阵数据并进行预计算
- 构建 core 时,很多数据在GPU开辟好了内存,但是没赋值。调用
update更新矩阵参数,进行拷贝。


更新图像变换矩阵 camera_depth_->update
上图的228行,主要内容见下图。update内部主要就是一个cuda的异步拷贝操作。将cpu上的增广矩阵、lidar2image矩阵数据,拷贝到GPU上。
将 图像增强矩阵 和 lidar2image 矩阵拷贝到在 device 上分配好的内存中。

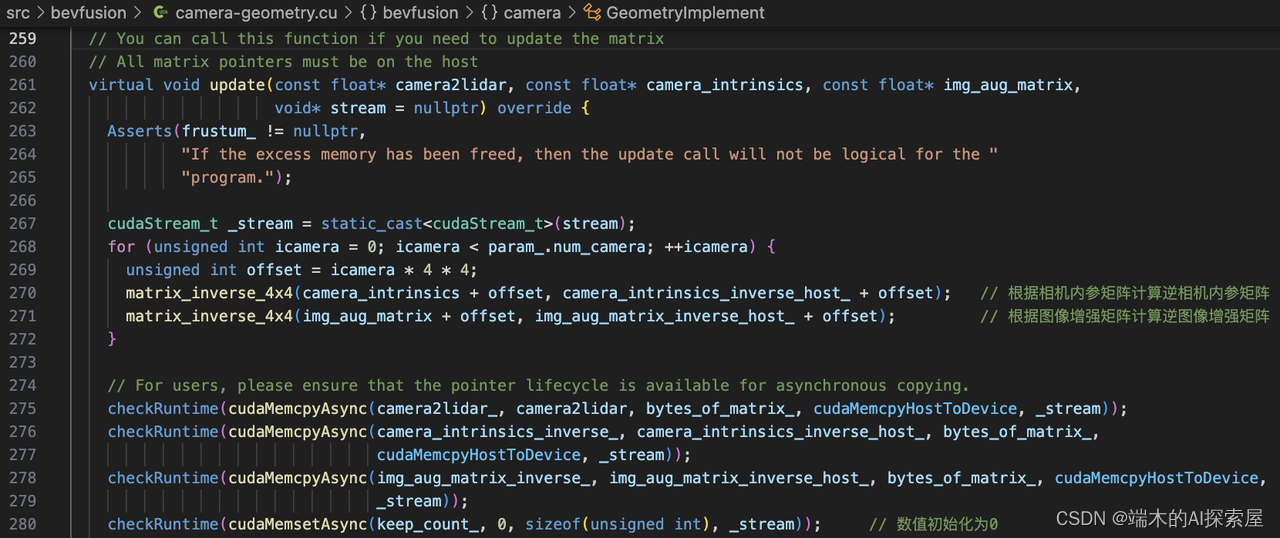
更新真实世界中几何空间(体素网格)的变换矩阵 camera_geometry_->update
上上图229行,具体内容如下。
270行,求6个视角的相机的内参矩阵的逆矩阵。
271行,求6个视角的相机的图像增广矩阵的逆矩阵。
275-279行,把6个视角相机的矩阵拷贝到GPU
280行,为GPU上,名字是keep_count_的用于计数的变量赋值
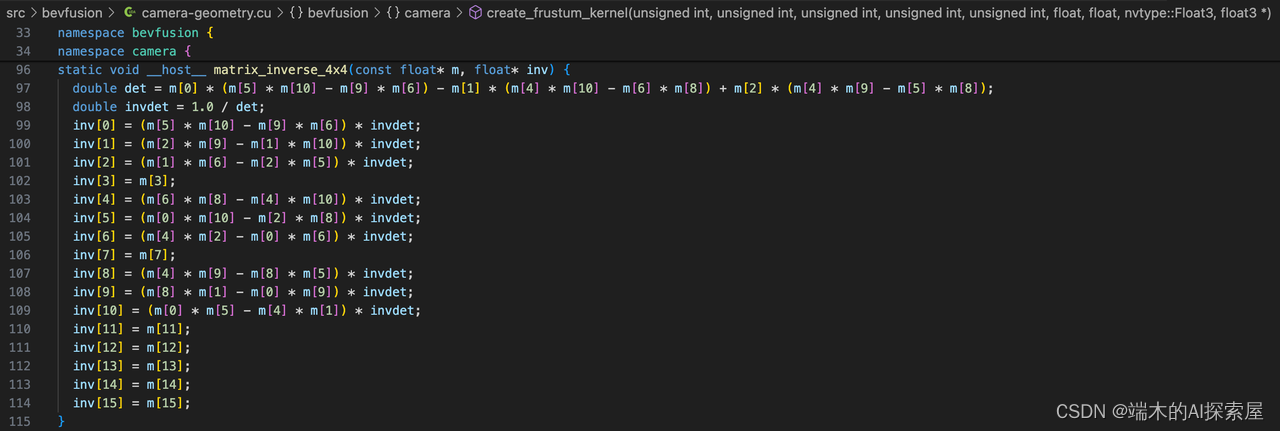
求矩阵的逆的方法实现。
-
计算
逆相机内参矩阵和逆图像增强矩阵,并将这两个矩阵和camera2lidar拷贝到在device上分配好的内 -
解释
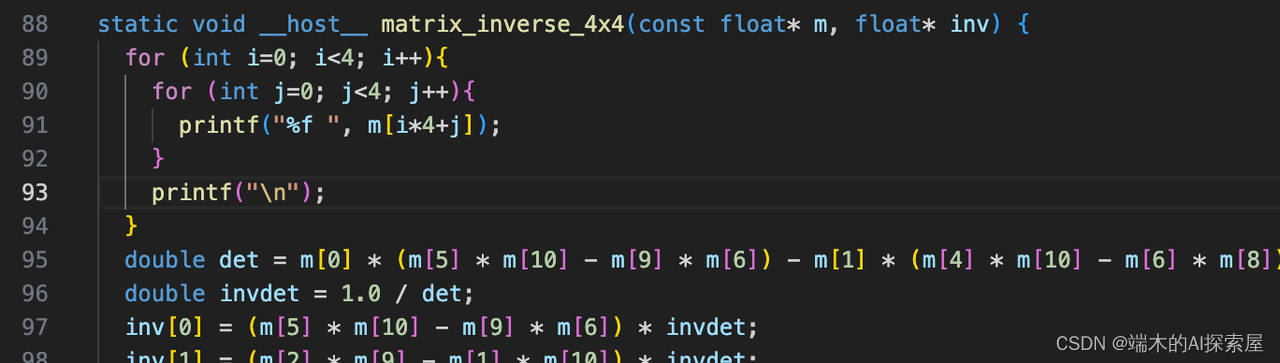
- 为了方便观看,上图 89 行处,增加下方代码调试。重新编译(
bash tools/run.sh)
- 为了方便观看,上图 89 行处,增加下方代码调试。重新编译(
for (int i=0; i<4; i++){
for (int j=0; j<4; j++){
printf("%f ", m[i*4+j]);
}
printf("\n");
}
- 调试结果(取一个矩阵)
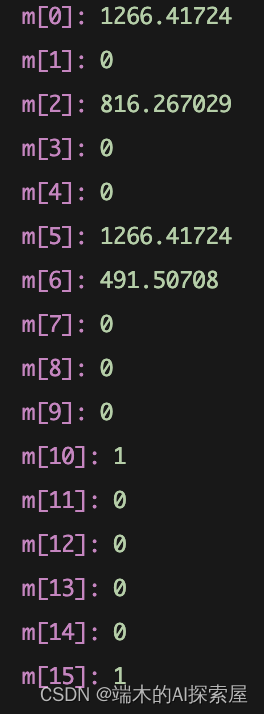

(0)1266.417236 (1)0.000000 (2)816.267029 (3)0.000000
(4)0.000000 (5)1266.417236 (6)491.507080 (7)0.000000
(8)0.000000 (9)0.000000 (10)1.000000 (11)0.000000
(12)0.000000 (13)0.000000 (14)0.000000 (15)1.000000
- 逆矩阵计算解释
-
- 第一步,求行列式
- 拉普拉斯展开
对于一个 4 × 4 4 \times 4 4×4 矩阵:
M = ( m [ 0 ] m [ 1 ] m [ 2 ] m [ 3 ] m [ 4 ] m [ 5 ] m [ 6 ] m [ 7 ] m [ 8 ] m [ 9 ] m [ 10 ] m [ 11 ] m [ 12 ] m [ 13 ] m [ 14 ] m [ 15 ] ) M=\left(\begin{array}{cccc} m[0] & m[1] & m[2] & m[3] \\ m[4] & m[5] & m[6] & m[7] \\ m[8] & m[9] & m[10] & m[11] \\ m[12] & m[13] & m[14] & m[15] \end{array}\right) M= m[0]m[4]m[8]m[12]m[1]m[5]m[9]m[13]
- 拉普拉斯展开
- 第一步,求行列式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









