







 本文详细介绍了Apache Flink的核心概念、特点、应用场景,包括流处理与批处理模型、技术选型、API使用、窗口机制和并行度设置,以及实战案例和体系结构剖析。适合Flink入门者和进阶者学习。
本文详细介绍了Apache Flink的核心概念、特点、应用场景,包括流处理与批处理模型、技术选型、API使用、窗口机制和并行度设置,以及实战案例和体系结构剖析。适合Flink入门者和进阶者学习。
文章目录
第一章:概述
第一节:什么是Flink?
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
第二节:Flink特点?
Flink 是一个开源的流处理框架,它具有以下特点
- 批流一体:统一批处理、流处理
- 分布式:Flink可以运行在多机器上
- 高性能:处理性能比较高
- 高可用:Flink支持高可用(HA)
- 准确:Flink可以保证数据处理的准确性
第三节:Flink应用场景?
Flink主要应用于流式数据分析场景
- 实时ETL(Extract Transform Load):集成流计算现有的诸多数据通道和SQL灵活的加工能力,对流式数据进行实时清晰、归并和结构化处理;同时,对离线数仓进行有效的补充和优化,并为数据实时传输提供可计算通道。
- 实时报表:实时化采集、加工流式数据存储;实时监控和展现业务、客户各类指标,让数据化运营实时化。
- 监控预警:对系统和用户行为进行实时监测和分析,以便及时发现危险行为
- 在线系统:实时计算各类数据指标,并利用实时结果及时调整在线系统的相关策略,在各类内容投放、智能推送领域有大量的应用
第四节:Flink核心组成
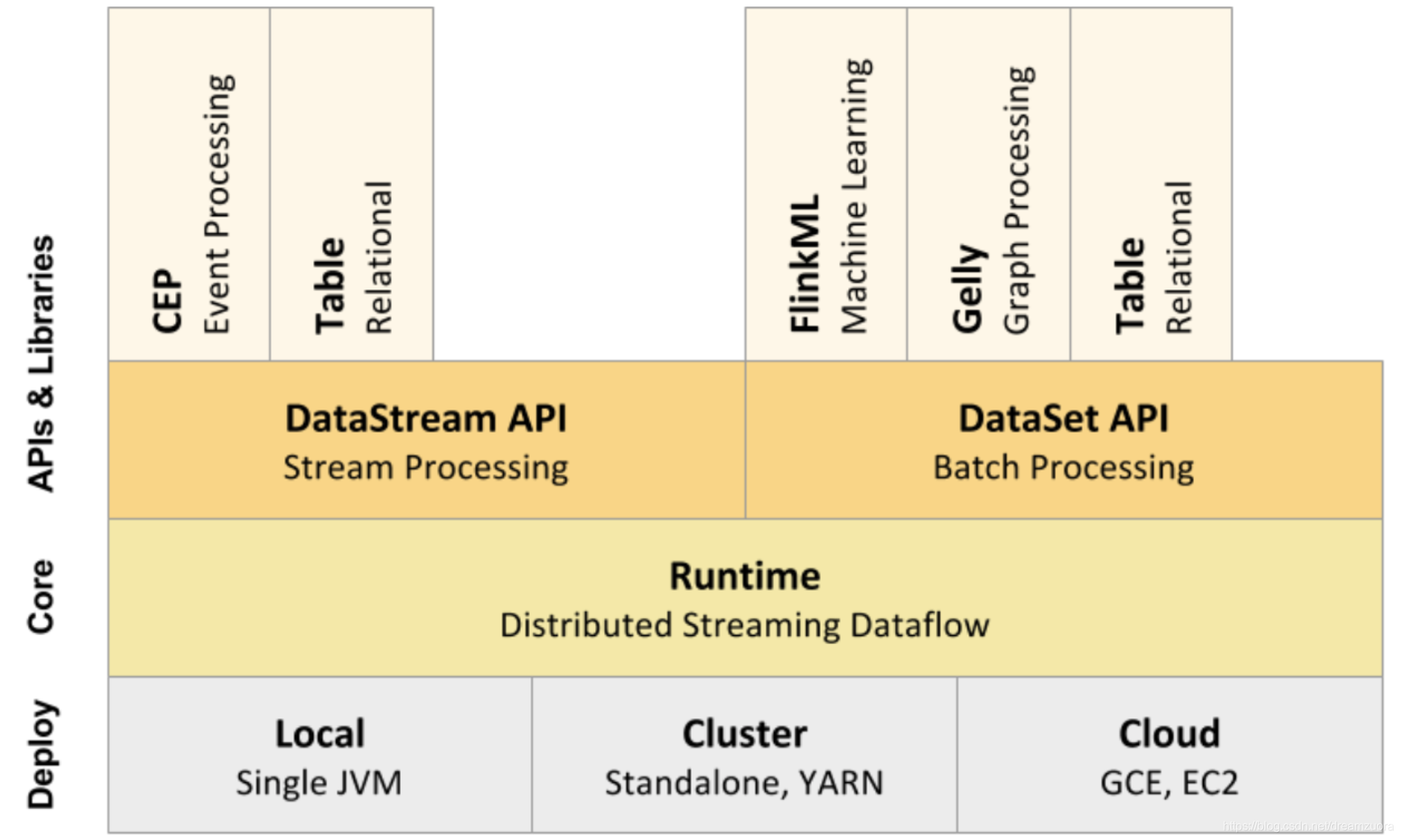
Deploy层:
- 可以启动单个JVM,让Flink以Local模式运行
- Flink也可以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到YARN上面运行
- Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)
Core层:在Runtime之上提供了两套核心的API,DataStream API(流处理)和DataSet API(批处理)
APIs & Libraries层:核心API之上又扩展了一些高阶的库和API
- CEP流处理
- Table API和SQL
- Flink ML机器学习库
- Gelly图计算
Flink生态发展
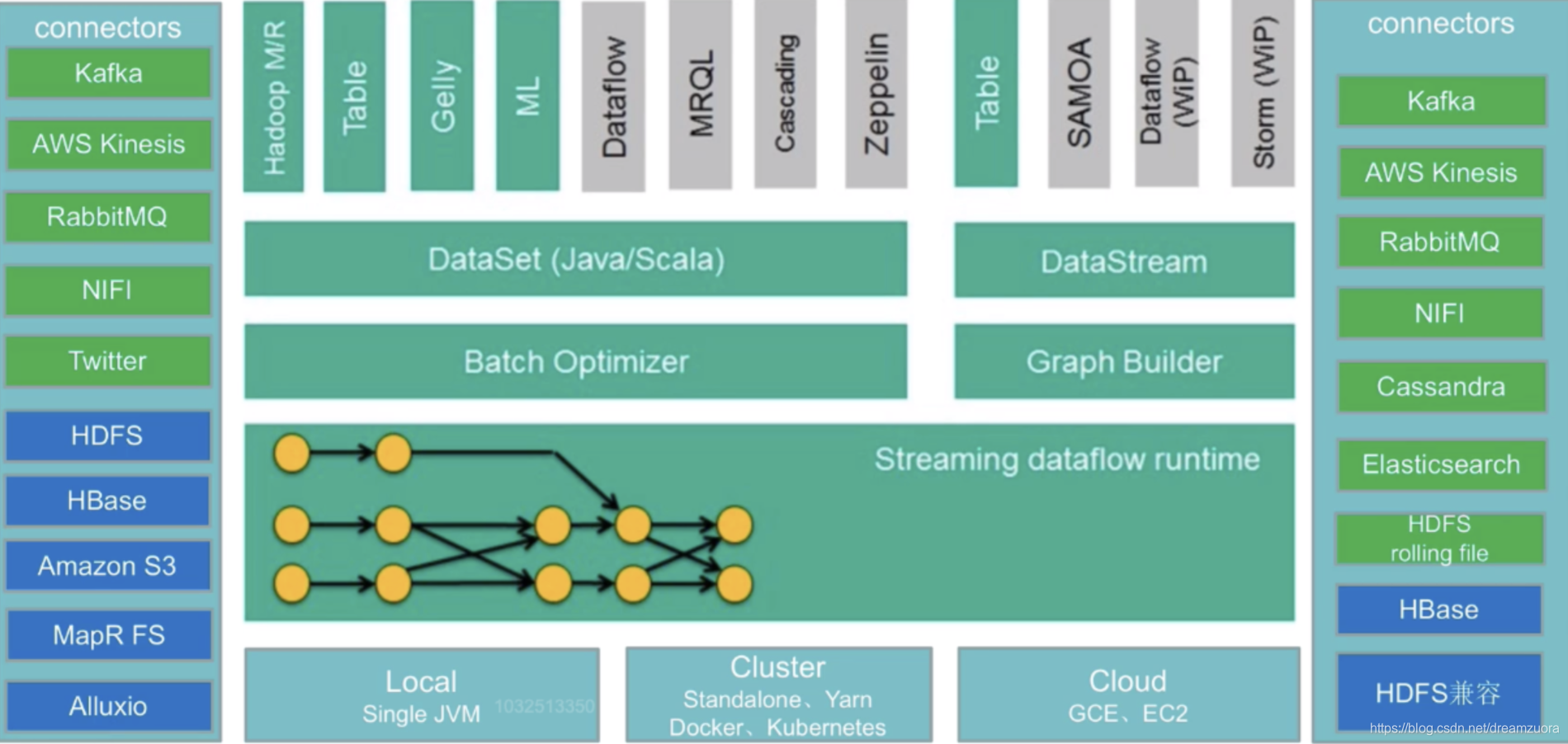
-
中间部分主要内容在上面Flink核心组成中已经提到
-
输入Connectors(左侧部分)
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队列)、NIFI(数据管道)、Twitter(API)批处理方式:包含HDFS(分布式文件系统)、HBase(分布式列式数据库)、Amazon S3(文件系统)、MapR FS(文件系统)、ALLuxio(基于内存分布式文件系统)
-
输出Connectors(右侧部分)
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队列)、NIFI(数据管道)、Cassandra(NOSQL数据库)、ElasticSearch(全文检索)、HDFS rolling file(滚动文件)批处理方式:包含HBase(分布式列式数据库)、HDFS(分布式文件系统)
第五节:Flink处理模型:流处理和批处理
Flink 专注于无限流处理,有限流处理是无限流处理的一种特殊情况
无限流处理:
- 输入的数据没有尽头,像水流一样源源不断
- 数据处理从当前或者过去的某一个时间 点开始,持续不停地进行
有限流处理:
从某一个时间点开始处理数据,然后在另一个时间点结束
- 输入数据可能本身是有限的(即输入数据集并不会随着时间增长),也可能出于分析的目的被人为地设定为有限集(即只分析某一个时间段内的事件)
- Flink封装了DataStream API进行流处理,封装了DataSet API进行批处理。
同时,Flink也是一个批流一体的处理引擎,提供了Table API / SQL统一了批处理和流处理
第六节:流处理引擎的技术选型
市面上的流处理引擎不止Flink一种,其他的比如Storm、SparkStreaming、Trident等,实际应用时如何进行选型,给大家一些建议参考
- 流数据要进行状态管理,选择使用Trident、Spark Streaming或者Flink
- 消息投递需要保证At-least-once(至少一次)或者Exactly-once(仅一次)不能选择Storm
- 对于小型独立项目,有低延迟要求,可以选择使用Storm,更简单
- 如果项目已经引入了大框架Spark,实时处理需求可以满足的话,建议直接使用Spark中的Spark Streaming
- 消息投递要满足Exactly-once(仅一次),数据量大、有高吞吐、低延迟要求,要进行状态管理或窗口统计,建议使用Flink
拓展:什么是最多一次、最少一次和仅一次(精确一次)?
背景:通常情况下,流式计算系统都会为用户提供指定数据处理的可靠模式功能,用来表明在实际生产运行中会对数据处理做哪些保障。一般来说,流处理引擎通常为用户的应用程序提供三种数据处理语义:最多一次、至少一次和精确一次。
- 最多一次(At-most-Once):这种语义理解起来很简单,用户的数据只会被处理一次,不管成功还是失败,不会重试也不会重发。
- 至少一次(At-least-Once):这种语义下,系统会保证数据或事件至少被处理一次。如果中间发生错误或者丢失,那么会从源头重新发送一条然后进入处理系统,所以同一个事件或者消息会被处理多次。
- 精确一次(Exactly-Once):表示每一条数据只会被精确地处理一次,不多也不少。
Exactly-Once 是 Flink、Spark 等流处理系统的核心特性之一,这种语义会保证每一条消息只被流处理系统处理一次。“精确一次” 语义是 Flink 1.4.0 版本引入的一个重要特性,而且,Flink 号称支持“端到端的精确一次”语义。
在这里我们解释一下“端到端(End to End)的精确一次”,它指的是 Flink 应用从 Source 端开始到 Sink 端结束,数据必须经过的起始点和结束点。Flink 自身是无法保证外部系统“精确一次”语义的,所以 Flink 若要实现所谓“端到端(End to End)的精确一次”的要求,那么外部系统必须支持“精确一次”语义;然后借助 Flink 提供的分布式快照和两阶段提交才能实现。
第二章:Flink快速应用
第一节:单词统计案例(批数据)
需求
统计一个文件中各个单词出现的次数,把统计结果输出到文件
依赖
<!--flink核心包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.2</version>
</dependency>
<!--flink流处理包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.7.2</version>
<scope>provided</scope>
</dependency>
代码
/**
* 单词统计(批数据处理)
*/
public class WordCount {
public static void main(String[] args) throws Exception {
// 输入路径和出入路径通过参数传入,约定第一个参数为输入路径,第二个参数为输出路径
String inPath = args[0];
String outPath = args[1];
// 获取Flink批处理执行环境
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
// 获取文件中内容
DataSet<String> text = executionEnvironment.readTextFile(inPath);
// 对数据进行处理
DataSet<Tuple2<String, Integer>> dataSet = text.flatMap(new LineSplitter()).groupBy(0).sum(1);
dataSet.writeAsCsv(outputFile,"\n","").setParallelism(1);
// 触发执行程序
executionEnvironment.execute("wordcount batch process");
}
static class LineSplitter implements FlatMapFunction<String, Tuple2<String,Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word:line.split(" ")) {
collector.collect(new Tuple2<>(word,1));
}
}
}
}
第二节:单词统计案例(流处理)
需求
Socket模拟实时发送单词,使用Flink实时接收数据,对指定时间窗口内(如5s)的数据进行聚合统计,每隔1s汇总计算一次,并且把时间窗口内计算结果打印出来。
代码
/**
1. Socket模拟实时发送单词,使用Flink实时接收数据,对指定时间窗口内(如5s)的数据进行聚合统计,每隔1s汇总计算一次,并且把时间窗口内计算结果打印出来。
teacher2 ip : 113.31.105.128
*/
public class WordCount {
public static void main(String[] args) throws Exception {
// 监听的ip和端口号,以main参数形式传入,约定第一个参数为ip,第二个参数为端口
String ip = args[0];
int port = Integer.parseInt(args[1]);
// 获取Flink流执行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取socket输入数据
DataStreamSource<String> textStream = streamExecutionEnvironment.socketTextStream(ip, port, "\n");
SingleOutputStreamOperator<Tuple2<String, Long>> tuple2SingleOutputStreamOperator = textStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] splits = s.split("\\s");
for (String word : splits) {
collector.collect(Tuple2.of(word, 1l));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Long>> word = tuple2SingleOutputStreamOperator.keyBy("word")
.timeWindow(Time.seconds(2), Time.seconds(1))
.sum(1);
// 打印数据
word.print();
// 触发任务执行
streamExecutionEnvironment.execute("wordcount stream process");
}
}
Flink程序开发的流程总结
- 获得执行环境
- 加载/初始化数据
- 指定数据操作的算子
- 指定结果集存放位置
- 调用execute()触发执行程序
注意:Flink程序是延迟计算的,只有最后调用execute()方法的时候才会真正触发执行程序
第三章:Flink体系结构
第一节:Flink的重要角色
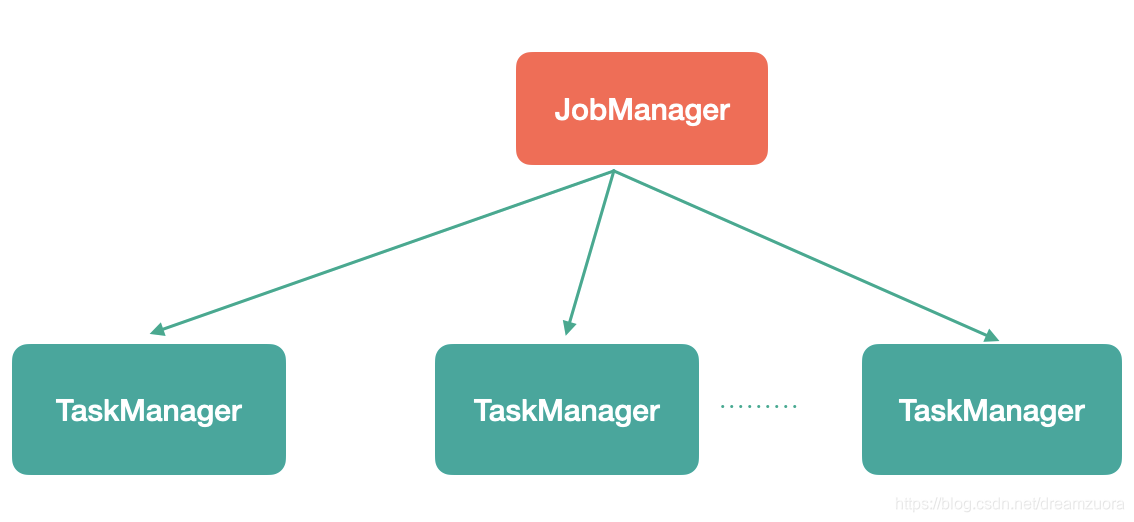
Flink是非常经典的Master/Slave结构实现,JobManager是Master,TaskManager是Slave。

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









