









语义分割中常用交叉熵损失CE,在应用中通常添加OHEM以获取更好的收敛(经验阈值是0.7),这里OHEM思想的来源是topk loss,其介绍参考【论文-损失函数】Learning with Average Top-k Loss_there2belief的博客-优快云博客
这种添加OHEM的损失叫OhemCELoss(Online hard example mining cross-entropy loss),其中 Online hard example mining 的意思是,在训练过程中关注 hard example ,对其施加更高权重的一种训练策略。cross-entropy loss 就是普通的交叉熵损失函数。下面具体看下如何添加。
cross-entropy loss
首先回顾一下多分类问题的 cross-entropy loss 的公式:
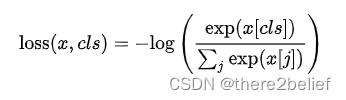
其中 为预测值, 为真实类别,大括号里面计算了样本在真实类别上的概率,这个概率越大(越接近 1),其负对数就越接近 0;反之,这个概率越小,其负对数就越接近正无穷。
pytorch 下的接口为:
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
weight(Tensor, optional) 表示每个类别设置的权重,用在类别不平衡的数据集上size_average(bool, optional) ,True 计算整个 batch 上的平均值作为 loss,False 计算batch loss 之和。ignore_index(int, optional) 某个 ground truth 值被忽略,即当 ground truth 为它时,损失直接设为 0。reduce(bool, optional) 默认情况下,计算的 loss 为一个 batch 中每个元素的 loss 之和或者平均,设置为 False 后,返回每个元素的 loss。reduction(string, optional) 设置不同的输出格式,可以设为'none' | 'mean' | 'sum',由于它的存在,size_average和reduce将被淘汰(size_average=True相当于 'mean',size_average=False相当于 'sum',reduce=False相当于 'none')。
代码示例如下:
loss = nn.CrossEntropyLoss()
x = torch.randn(3, 5)
label = torch.empty(3, dtype=torch.long).random_(5)
out = loss(x, label)
为了深入理解原理,也可以自己实现:
x = torch.randn(3, 5)
label = torch.empty(3, dtype=torch.long).random_(5)
exp_x = torch.exp(x)
prob_x = exp_x/exp_x.sum(dim=1, keepdim=True)
prob_x = torch.gather(prob_x, dim=1, index=label.unsqueeze(1))
# reduction = 'none'
print(-torch.log(prob_x))
# reduction = 'sum'
print(-torch.log(prob_x).sum())
# reduction = 'mean'
print(-torch.log(prob_x).mean())
OhemCELoss
先贴代码
class OhemCELoss(nn.Module):
def __init__(self, thresh, n_min, ignore_lb=255, *args, **kwargs):
super(OhemCELoss, self).__init__()
self.thresh = -torch.log(torch.tensor(thresh, dtype=torch.float)).cuda()
self.n_min = n_min
self.ignore_lb = ignore_lb
self.criteria = nn.CrossEntropyLoss(ignore_index=ignore_lb, reduction='none')
def forward(self, logits, labels):
N, C, H, W = logits.size()
# OHEM here
loss = self.criteria(logits, labels).view(-1) # to 1-D
loss, _ = torch.sort(loss, descending=True) # sort
if loss[self.n_min] > self.thresh:
loss = loss[loss>self.thresh]
else:
loss = loss[:self.n_min]
return torch.mean(loss)
该损失函数有几个超参数:thresh,n_min,其中 thresh 表示的是,损失函数大于多少的时候,会被用来做反向传播。n_min 表示的是,在一个 batch 中,最少需要考虑多少个样本。
需要注意一点,参数 thresh 是概率,即 小于这个概率的预测值会参与计算损失。
self.thresh = -torch.log(torch.tensor(thresh, dtype=torch.float))将概率转化为其对应的 loss 。- 代码中的
logits维度为 NCHW,labels维度为NHW 。 self.criteria = nn.CrossEntropyLoss(ignore_index=ignore_lb, reduction='none')设置 reduction 为 none,保留每个元素的损失,返回的维度为 NHW。loss = self.criteria(logits, labels).view(-1)将预测的损失拉平为一个长向量,每个元素为一个 pixel 的损失。loss, _ = torch.sort(loss, descending=True)将长向量中每个 pixel 的损失按从大到小排序。if loss[self.n_min] > self.thresh:最少考虑n_min个损失最大的 pixel,如果前n_min个损失中最小的那个的损失仍然大于设定的阈值,那么取实际所有大于该阈值的元素计算损失:loss=loss[loss>thresh]。- 否则,计算前
n_min个损失:loss = loss[:self.n_min]。 - 最后,求这些 hard example 的损失的均值作为最终损失:
torch.mean(loss)。
总结
在图像分割问题中,以每个 pixel 的损失为最小单元,而不是 batch 中每张图片。因此排序时需要把 batch 中所有 pixel 拉成一个长向量,再取其中大于阈值的 pixel 作为 hard example。同时,n_min 的设置保证了每个 batch 中都有至少 n_min 个pixel 参与训练,从而一定程度巩固了训练结果,让前向传播不至于空耗。
修改自:https://www.jianshu.com/p/24376b18e5c7

















 2788
2788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









