 深度学习目标检测中的困难样本挖掘与在线优化
深度学习目标检测中的困难样本挖掘与在线优化





 本文探讨了计算机视觉中目标检测的挑战,特别是数据不平衡问题和困难样本挖掘。Fast R-CNN的训练策略通过困难负样本挖掘提高性能,但面临在线学习的困难。为解决此问题,提出了在线困难样本挖掘(OHEM)算法,它在每个SGD迭代中根据损失选择困难样本,消除了对启发式方法和超参数的需求,提高了检测精度。实验表明,OHEM在PASCALVOC数据集上显著提升了检测性能。
本文探讨了计算机视觉中目标检测的挑战,特别是数据不平衡问题和困难样本挖掘。Fast R-CNN的训练策略通过困难负样本挖掘提高性能,但面临在线学习的困难。为解决此问题,提出了在线困难样本挖掘(OHEM)算法,它在每个SGD迭代中根据损失选择困难样本,消除了对启发式方法和超参数的需求,提高了检测精度。实验表明,OHEM在PASCALVOC数据集上显著提升了检测性能。
方法的由来 还是要看论文了解下的 https://arxiv.org/pdf/1604.03540.pdf
1 数据不均衡
图像分类和目标检测是计算机视觉的两个基本任务。目标检测器通常通过将目标检测转化为图像分类问题的简化来训练。这种减少带来了自然图像分类任务中没有的新挑战:训练集的特点是标注对象的数量与背景示例(不属于任何感兴趣的对象类别的图像区域)的数量之间存在很大的不平衡。
- 在滑动窗口对象检测器的情况下,这种不平衡可能极端到每一个对象的100000个背景示例。
- 最近的基于对象建议的探测器趋势[15,32]在一定程度上缓解了这一问题,但不平衡率可能仍然很高(例如70:1)。
2 困难样本挖掘
传统的方法:最初被称为bootstrapping(现在通常被称为hard negative mining,困难负样本挖掘)。
困难样本挖掘算法的交替步骤:
- 1)拿出所有的正样本和一小部分负样本(构成初始active training set)先训练一个分类器;
- 2)训练好的分类器在剩下部分的负样本里面找false positive,加入到active training set;一次图片的数据量通常为10~100
- 3)利用active training set训练分类器,之后回到2);
这个过程会重复,直到活动训练集包含所有支持向量
3 Fast RCNN 中的 ConvNet
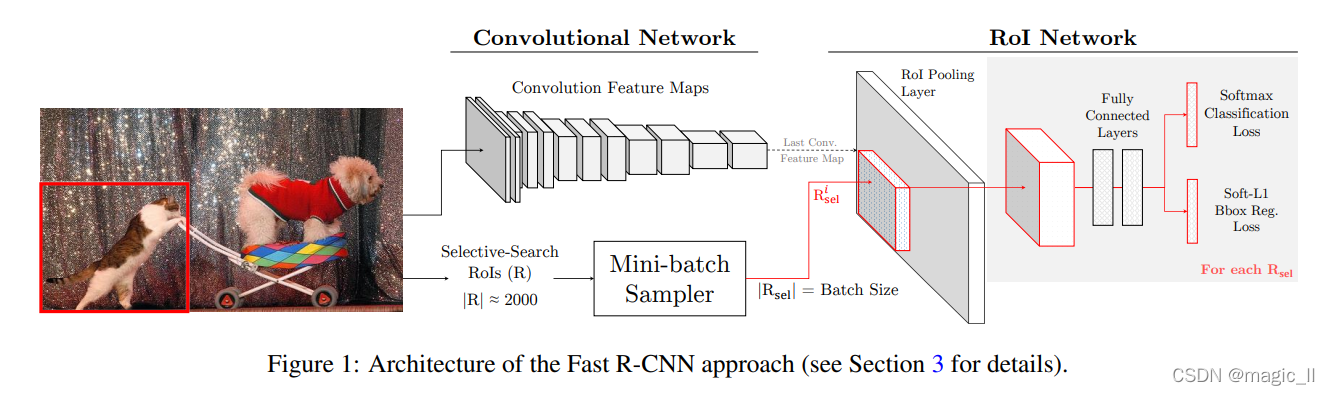
【Fast R-CNN 的结构】
OverFeat基于滑动窗口检测方法,这可能是最直观、最古老的检测搜索方法。
相比之下,R-CNN使用区域建议 有了更好的效果。
自R-CNN以来,基于区域的ConvNet 取得了快速的进展,本论文的工作就是在这些基础上进行的。
先总结下Fast R-CNN[14](FRCN)框架。FRCN网络本身可分为两个连续的部分:
- 具有多个卷积和最大池层的卷积(conv)网络 (图1,“卷积网络”);
- 一个RoI(对象建议感兴趣区域)网络,其中包含一个RoI池化层、几个全连接层和两个损失层 (图1,“RoI网络”)。
在推理过程中:
- 将conv网络应用于给定图像以生成conv特征映射,其大小取决于输入图像的尺寸。
- 对于每个对象提案,RoI池层将提案投影到conv特征图上,并提取固定长度的特征向量。每个特征向量被输入到fc层,fc层最终给出两个输出:1) 对象类和背景上的softmax概率分布;2) 用于边界框重新定位的回归坐标。
【Fast R-CNN 的设置】
FRCN使用 SGD 进行训练。每个样本RoI的损失是分类log损失(鼓励预测正确的对象(或背景)标签)和定位损失(鼓励预测准确的边界框)的总和。为了在ROI之间共享conv网络计算,需要分层创建SGD小批量。对于每个小批量,首先从数据集中采样N个图像,然后从每个图像中采样B/N ROI。设置N=2和B=128在实践中效果良好。
RoI采样过程使用了几种启发式方法,我们将在下面简要介绍。本文的一个贡献是消除了一些启发式算法及其超参数。
- 前景RoIs。标记为前景 (fg) 的RoI,与真实边界框的iou 应至少为0.5。
这是一个相当标准的设计选择,部分灵感来自PASCAL VOC目标检测基准的评估协议。在R-CNN、SPPnet和MR-CNN的SVM困难样本挖掘过程中使用了相同的标准。我们使用相同的设置。- 背景RoIs。如果一个区域的最大IoU与地面真值在[bg_lo, 0.5]区间内,则该区域被标记为背景 (bg) 。FRCN和SPPnet都使用了bg_lo=0.1的较低阈值,并在[14]中进行了假设,以粗略地近困难负挖掘。
实验中我们发现这是训练FRCN的一个重要设计决策。删除该比率(即随机采样ROI)或增加该比率,会使精度降低∼3点mAP。利用我们提出的方法,我们可以在没有不良影响的情况下去除这个比率超参数。
虽然这种启发式方法有助于收敛和检测精度,但由于它忽略了一些不常见但重要的困难背景区域,因此不太理想。我们的方法去除了bg_lo阈值。- 平衡fg bg ROI。为了处理第1节中描述的数据不平衡,[14]设计了启发式算法,通过随机欠采样背景样本,将每个小批量中的前景:背景比率 平衡到1:3的目标,从而确保小批量中25%是fg
【困难样本挖掘在 Fast R-CNN 的问题】
Fast R-CNN及其后代不使用bootstrapping,根本原因是其在向纯在线学习算法的转变带来的技术困难,特别是在使用随机梯度下降(SGD)对数百万个示例进行训练的深层网络的情况下。
使用SGD训练deep ConvNet探测器通常需要数十万个SGD步骤,几次迭代后就将模型固定都会大大降低进度,在从10或100张图像中选择样本时,不会进行模型更新。所以我们需要的是一种纯粹的在线形式的困难样本选择。
4 在线困难样本挖掘
4.1 好处
在本文中提出 在线困难样本挖掘(OHEM),用于训练基于深度网络的最先进的检测模型。该算法是对SGD的一个简单修改,其中训练样本根据非均匀、非平稳分布进行采样,该分布取决于所考虑的每个样本的当前损失。
该方法利用了特定于检测的问题结构,其中每个SGD小批量只包含一个或两个图像,但有数千个候选示例。梯度计算(反向传播)仍然是有效的,因为它只使用所有候选对象的一小部分。我们将OHEM应用于标准的快速R-CNN检测方法,与基线训练算法相比,它有三个优点:
- 它消除了对基于区域的convnet中常用的几种heuristics和超参数的需求。
- 它在平均精度方面产生了一致且显著的提升
- MS COCO数据集的结果表明,随着训练集变得更大、更困难,它的有效性也会增加。
结合该领域的互补性进展,OHEM在PASCAL VOC 2007年和2012年的最新结果分别为78.9%和76.3%。
4.2 思想
我们的目的是,如何将【困难样本挖掘的交替步骤】与【FRCN使用SGD在线训练】相结合。
关键点是,尽管每个SGD迭代只对少量图像进行采样,但每个图像包含数千个示例ROI,我们可以从中选择困难样子,而不是启发式采样 (heuristically sampled subset)的子集。该策略通过仅“冻结”一个小批量的模型,将替代模板与SGD相匹配。因此,模型的更新频率与基线SGD方法相同,因此学习不会延迟。
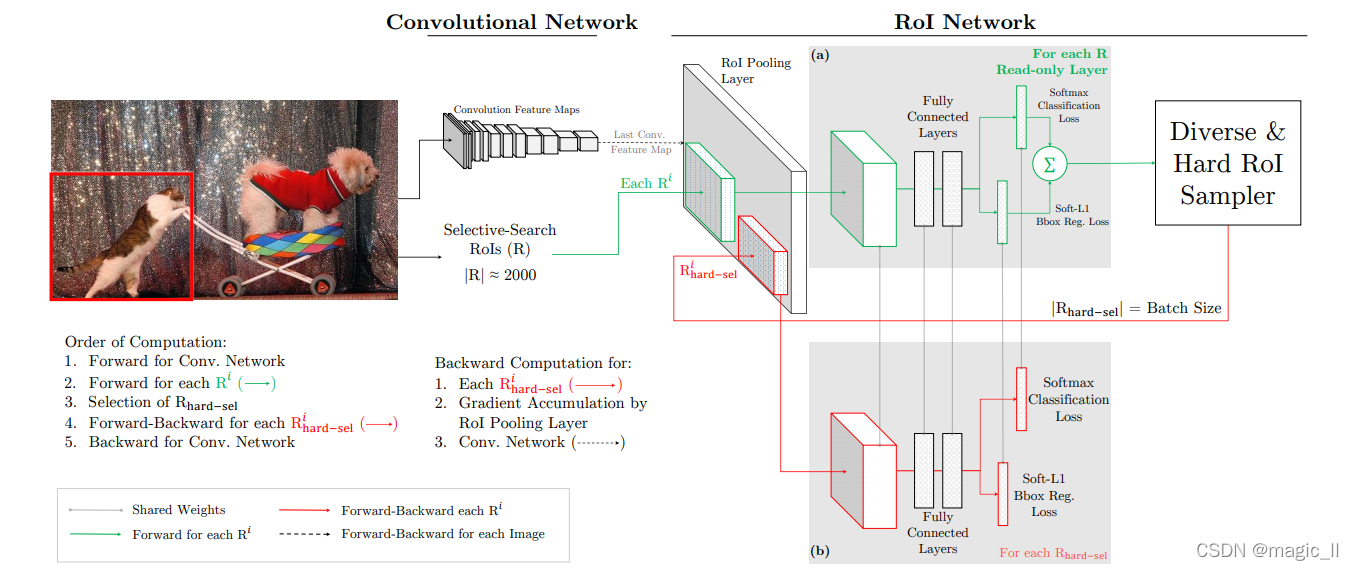
在线硬示例挖掘算法(OHEM)如下所示。
- 计算feature map:迭代t的输入图像进行前向传播,我们首先使用conv网络计算conv特征映射。
- 计算所有RoI 的 loss:RoI网络使用该特征图和所有输入RoI 进行正向传递,注意不是采样的小批量。回想一下,这一步只涉及RoI池、几个fc层和每个RoI的损失计算。损失代表当前网络在每个RoI上的表现。
- 按损失对输入ROI进行排序,使用NMS 来消除重复的样本,然后选取当前网络表现最差的B/N样本为困难样本。其中NMS阈值选用0.7的宽松IoU阈值来仅抑制高度重叠的ROI。(注意不消除重复样本会导致损失重复计算)
- 选取损失最大的前一部分Region当做输入再次输入分类回归网络。这一步可以屏蔽loss非常低的Region proposal,对于训练多次loss还较高的我们可以认为其是困难样本。在线困难样本挖掘,就是将【计算loss→loss阈值筛选→得到困难负样本】和【训练网络模型】同步起来
上述过程不需要fg bg比率来进行数据平衡。如果忽略任何类别,其损失将增加,直到其被抽样的概率很高。可能存在fg ROI容易显示的图像(例如汽车的标准视图),因此网络可以自由地在小批量中仅使用bg区域;反之,当bg不重要时(例如天空、草地等),小批量可以完全是fg区域。
4.3 具体实施
在FRCN检测器中实现OHEM的方法有多种。
- 修改损失层以进行困难样本选择。损失层可以计算所有ROI的损失,根据该损失对它们进行排序以选择困难ROI,最后将所有非困难的ROI的损耗设置为0。
虽然简单 但效率很低,因为RoI网络仍然为所有RoI分配内存并执行反向传递,即使大多数RoI没有损失,没有梯度更新。- 为了克服这个问题,我们提出了图2所示的体系结构。我们的实现维护了RoI网络的两个副本,其中一个是只读的,另一个是可读写的标准网络。这意味着只读RoI网络 (图2(a)) 只为所有RoI的前向传递分配内存,而标准RoI网络为前向传递和后向传递分配内存。
- 对于SGD迭代,给定conv特征图,只读RoI网络执行前向传递,并计算所有输入RoI 的损失(绿色箭头)。
- 困难RoI采样模块 前一小节描述的流程,然后将其输入常规RoI网络 (图(b),红色箭头)。
- 该网络仅为困难样本计算向前和向后传递,累积梯度并将其传递给conv网络。在实践中,我们使用所有N个图像的所有RoI作为R,因此只读RoI网络的有效批量大小为| R |,而常规RoI网络的有效批量大小为128。
5 实验
5.1 基本设置
- 使用两种标准的ConvNet架构进行实验:来自[5]的VGG_CNN_M_1024(简称VGGM,它是AlexNet[19]的更广泛版本)以及VGG16。
- 实验均在PASCAL VOC07数据集上进行。训练在trainval集合上进行,测试在测试集合上进行。除非另有规定,否则将使用FRCN[14]中的默认设置。
- 作者使用Caffe框架实现上述两个选项。实现使用梯度累加,对单个图像小批量进行N次向前向后的传递。在FRCN[14]之后,我们使用N=2(这导致| R |≈ 4000)和B=128。在这些设置下,方法二与方法一具有相似的内存占用,但速度大于2倍。除非另有规定,本文将使用方法二和这种设置。
- 用SGD对所有方法进行80k小批量迭代训练,初始学习率为0.001,每30k次迭代我们将学习率衰减0.1。表1(第1-2行)中报告的基线数字是使用我们的训练计划重现的。
5.2 实验结果
- OHEM与启发式抽样
表1(第1-2行)中报告的标准FRCN :使用bg lo=0.1作为困难样本挖掘的方法;为了测试这种方式的重要性,我们使用了bg_lo=0的FRCN。表1(第3− 4行) 显示VGGM的mAP下降了2.4个点,而VGG16的mAP大致保持不变。
现在将其与OHEM培训FRCN(第11− 13行)进行比较: OHEM将mAP提高了2.4个点,相比于使用bg_lo=0.1启发式的VGGM-FRCN;提高了4.8个点,相比于不使用启发式的。
这个结果证明了这些启发式算法的次优性和我们的困难样本挖掘方法的有效性。- 鲁棒梯度估计
每批仅使用N=2个图像的一个问题是,它可能会导致不稳定的梯度和缓慢的收敛,因为图像的ROI可能高度相关[31]。FRCN[14]报告称,这对他们的训练来说不是一个重要的问题。但这一细节可能会引起我们对训练过程的担忧,因为我们使用的是同一张图片中损失较大的示例,因此它们可能具有更高的相关性。
为了解决这个问题,我们用N=1进行实验,以增加相关性,试图打破我们的方法。如表1(第5− 6、11行)所示,当N=1时,原FRCN的性能下降了约0.01,但使用我们的训练程序时,mAP保持大致相同。这表明OHEM在每批需要较少图像以减少GPU内存使用的情况下是健壮的。- 既然你能用所有的东西,为什么只举一些难的例子呢?
在线困难样本挖掘是基于假设在图像中考虑所有ROI是重要的,然后选择用于训练的困难样本。但是如果我们和所有的ROI一起训练,而不仅仅是那些困难的ROI呢?简单的样本损失小,对梯度影响不大;样本将自动集中在困难样本上。
为了比较这个选项,我们使用bg_lo=0,N∈ {1, 2},以B=2048的小批量 和其他固定的超参数,运行标准的FRCN训练。因为这个实验使用了一个大的小批量,所以调整学习速度以适应这种变化很重要。通过将VGG16和VGM分别增加到0.003和0.004,我们发现了最佳结果。结果见表1(第7− 10行)。
使用这些设置,VGG16和VGMM的映射都增加了约0.01与B=128相比,但与使用所有ROI相比,我们的方法仍提高了0.01。此外,因为我们使用较小的小批量计算梯度,所以训练速度更快。


















 5201
5201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









