




 文章讲述了小米汽车发布会上的智驾算法,重点介绍了BEV(鸟瞰视图)和Transformer在生成三维感知中的作用,以及特斯拉的占用网络技术。同时提及了小米汽车在芯片、算法、高精地图和传感器等方面的配置。
文章讲述了小米汽车发布会上的智驾算法,重点介绍了BEV(鸟瞰视图)和Transformer在生成三维感知中的作用,以及特斯拉的占用网络技术。同时提及了小米汽车在芯片、算法、高精地图和传感器等方面的配置。
大家好啊,我是董董灿。
昨天小米汽车开了发布会,一下子喜提十几个热搜。
就在人们纷纷猜测,小米汽车的定价会不会延续小米极致性价比风格时。
雷总的一句"电池成本都不下于十几万",瞬间把人们对于小米汽车定价的幻想拉高到了 30-40 万的数量级。
如此看来,小米 SU7 汽车,妥妥的中高端车型。
这篇文章,我们不去揣测小米汽车的价格,而是想简单聊一下,在发布会中雷总提到的 "transformer + BEV + 占用网络"的智驾算法。
1、什么是 BEV
相信不少小伙伴对 transformer 已经很熟悉了,现在很多大模型。比如chatGPT 都是基于 transformer 架构来设计的。
它的主要原理就是注意力机制。注意力机制可以很好的完成输入之间的特征关联和特征融合等操作,比如一句话中多个单词的关联,一张图片多个局部的关联等等。

除了 transformer 之外,雷总还提到了 BEV, 那什么是 BEV 呢?
BEV 的全称是 Bird’s Eye View,也就是鸟瞰图的意思。
目前很多智能汽车都会在中控屏上生成鸟瞰图,方便司机观察汽车周边的情况,也方便汽车对周围环境作出判断。

Photo by AI
对于汽车而言,这种鸟瞰图的生成过程大概是这样的。
汽车上会布置多个高清摄像头,用来采集汽车周边多个方位和角度的图像,然后采集到的图像会送给神经网络进行处理,比如进行多个图像的特征提取和融合。
假设汽车上布置了 6 个摄像头,那么这 6 路摄像头采集的图像会同时送给神经网络来提取特征,然后在特征空间中进行计算和特征融合。
有些时候还会辅助加入一些雷达采集的数据,最终将融合之后的数据生成一张鸟瞰图。
鸟瞰图可以比较直观的反映汽车周边的环境,像是给汽车开了一个上帝视角一样。
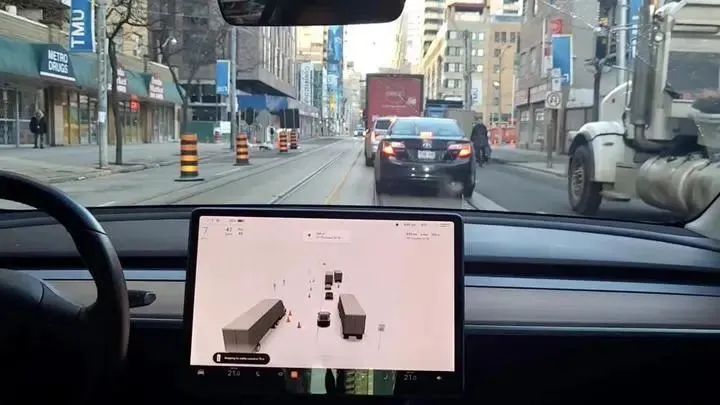
但是这种鸟瞰图是一种类似于二维的图片,而汽车本身却是一个三维的物体。
三维物体在二维平面上运动,始终会少一维的数据信息,比如汽车周边物体的高度信息。
这样就会导致很多的问题,比如说幽灵刹车。
有时候在鸟瞰图上可能什么也看不到,但是汽车会莫名其妙感知到前方有一个物体的存在而突然刹车。
出现这种现象有可能就是因为鸟瞰图丢失了数据信息而导致的,当然这不绝对。
2、占用网络
为了解决二维图像的问题,特斯拉在 2022 年的时候,发布一种全新的网络算法,叫做 Occupancy Networks,也就是占用网络。

并且特斯拉利用该算法改进了自己的 AI 模型 HydraNets,下图是在网上找到的特斯拉 HydraNets 的模型大体框架。
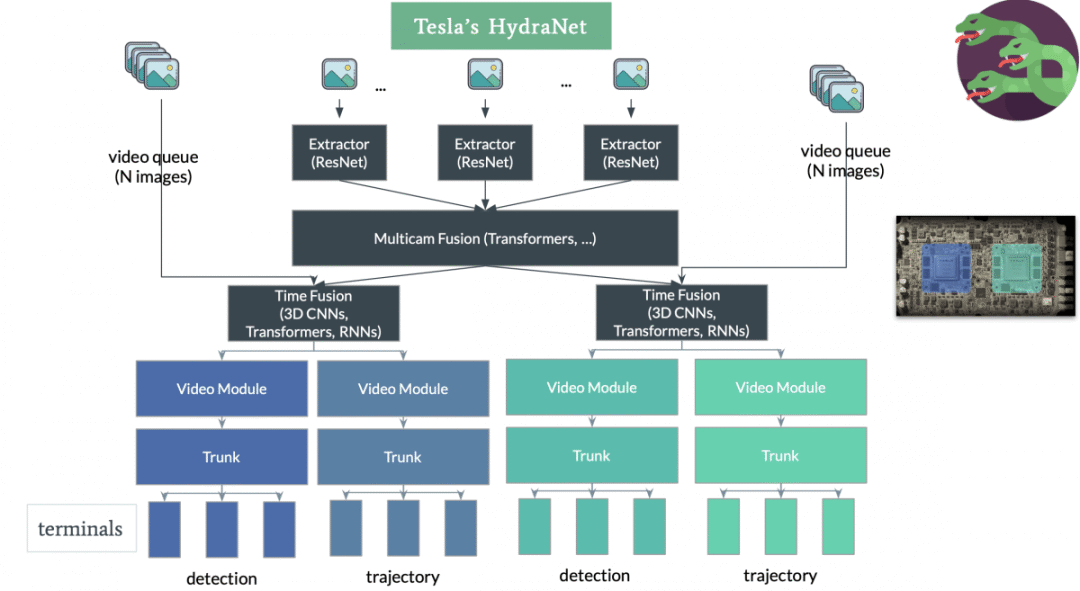
简单说明一下。
最上面的一张张图片可以看作汽车上的摄像头采集到的图片,图片经过以 Resnet 为 BackBone 的特征提取器(Extractor)之后,再经过基于 transformer 结构的多传感器特征融合层(Multicam Fusion),随后再经过视频处理模块,便可以完成一些复杂的任务,比如物体的检测、物体的3D重建等。
细节就不展开了,回到占用网络上来,说白了,占用网络可以将汽车对于周边环境的感知能力,由鸟瞰图的 2D 感知升级为 3D 感知。
小米汽车的占用网络,大抵也是如此。
这样的话将汽车放置在一个三维的环境中,它便能够感知到更多周边环境信息。
3、其他
去年7月的时候,我曾经写过一篇关于自动驾驶的文章:自动驾驶的"第三眼美女"什么时候才能出现?
当时对自动驾驶汽车未来的发展,给出来几个小结论,当然这也是很多人都知道的:
芯片和算法,是实现自动驾驶的大脑。
高精地图和传感器,是自动驾驶的五官。
操作系统是自动驾驶的肌肉。
整车机械底盘线控是自动驾驶的神经骨骼。
董董灿,公众号:董董灿是个攻城狮自动驾驶的"第三眼美女"什么时候才能出现?
结合小米汽车的发布会,几乎很好的印证了这几点:
在芯片方面,小米汽车采用了英伟达的 Orin X 芯片,算力达到了 500+Tops。
算法方面采用了本文提到的“Transfomer + BEV + 占用网络”。
高精地图方面,小米开发了小米道路大模型,可以实时生成道路拓扑,效果媲美高精地图。

传感器方面小米汽车用到了激光雷达、11 颗高清摄像头和 3 颗毫米波雷达,所以汽车智驾的解决方案也是基于雷达+视觉来实现的。
操作系统方面采用了小米自己的澎湃 OS,他们还还自研了底盘控制算法等等。
总的来说,此次发布会算是小米造车交出的第一份答卷,至于汽车是否真的如发布会所说那样,还要经过时间的检验。
注: 本文非小米汽车广告,以上文字仅代表个人观点,欢迎留言讨论。



















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











