



多关系文献网络中的社区检测
1 背景与动机
本工作的主要目标是通过对多关系书目数据中不同关系的分析,从书目数据中提取出新兴的学术社区结构。尽管在异构网络表示和高效拓扑算法设计方面已有较多研究关注,但对于异构组织架构的探索以及社区检测这一更为基础的问题,尚未得到妥善解决。事实上,文献中已提出了大量用于异构网络中社区检测的方法。然而,这些方法主要集中于网络的拓扑属性,忽略了嵌入其中的语义信息。为了克服这一局限性,近年来形式概念分析(FCA)技术被用于概念聚类。使用FCA旨在提取能够保留每个社区内共享知识的社区。在基于FCA的方法中,输入为二分图,输出为伽罗瓦层次结构,该结构以各社区共享的知识或共同属性来语义化地揭示社区。顶点被设计为格的外延,边则由格的内涵(即共享知识)标记。然而,伽罗瓦层次结构并非令人满意的方案,因为它可能产生指数数量的社区。因此,需要引入约简方法。事实上,目前仅有极少数研究真正关注了这一难题[4]。文献[5]中的作者使用了冰山法以及稳定性方法作为格理论约简方法。作者在[3]通过设定阈值识别具有频繁内涵的概念。此方法的主要限制在于,可能会忽略一些重要的概念。
Brandes等人[1]结合了冰山法和稳定性方法,据称该方法在基于概念提取相关社区方面取得了良好效果。正如Planti和Crampes所开展的调查中所述[4], 基于FCA技术发现社区是最精确的方法,因为它利用精确的语义来提取社区。然而,它们未能提供简单且实用的结果。因此,一个新的研究挑战在于从异构多关系网络中检测社区。为了发现具有明确定义属性集的社区,我们首先需要从多种现有关系中提取相应的关联。本文提出一种基于RCA技术的查询导航方法[6]该方法设计用于多个学术数据库中以检测隐藏关系(或链接)。这将产生重大影响,有助于促进新的协作团队形成、支持专长发现,并在长期推动研究团队重组,使其与协作模式保持一致。
本文组织如下。在下一节中,我们描述了我们的社区检测方法。第3节展示了我们的实验结果,而第4节总结了我们的贡献。
2 提出的社区检测方法
在本节中,我们提出了旨在从多关系文献数据中建模并提取学术社区结构的社区检测方法。为了实现这些目标,所提出的方法依赖于两个主要阶段:多关系书目超图建模阶段;以及社区发现的查询导航阶段。我们首先介绍本方案的初步概念。
A. 初步概念
-
形式背景 :是一个三元组 K=(O,A,I),其中 O 表示一个有限对象集,A 是一个有限项目集(或属性)且 I是一个二元(关联)关系(即 I ⊆ O × A)。每一对 (o, a) ∈ I 表示对象 o ∈ O包含项目 a ∈A。O称为单值上下文。在项目集 A和对象集 O[2]对应的幂集 P(A) 和 P(O) 之间存在一个感兴趣的关联。
-
形式概念 :一对相互对应的子集 c=(O, A) ∈ O × A,即 O= ψ(A)和 A= φ(O),被称为一个形式概念,其中 O称为 c的外延,而 A称为其内涵。
-
偏序 :关于形式概念,w.r.t.集合包含 [2], 定义为: ∀c1=(O1, A1) 和 c2=(O2, A2) 两个形式概念, c1 ≤ c2 如果 O2 ⊆ O1,或等价地 A1 ⊆ A2。
-
伽罗瓦概念格 :给定一个上下文 K,形式概念的集合 C 在考虑概念内涵 ( 或外延 [2]之间的集合包含关系时,构成一个完备格 LC=(C, ≤),称为 伽罗瓦(概念)格。
-
关系上下文族(RCF) :是一个二元组 (K, R),其中 K={Ki}i=1,…,n 是一组(对象‐属性)上下文 Ki=(Oi, Ai, Ii),而 {rj,l}j,l∈{1,…,n} 是一组关系(对象‐对象)上下文 rj,l ⊆ Oj × Ol,其中 Oj (称为 rj,l 的域)和 Ol(称为 rj,l 的范围)分别是上下文 Kj 和 Kl 的对象集。 Oj 称为 rj,l 的域 (dom(rj,l)),Ol 称为 rj,l 的范围 (ran(rj,l)) [6]。
函数rel与一个RCF相关联,该RCF将上下文 K=(O,A,I)∈ K映射到其对象集 K开始的所有关系 r ∈ R的集合:rel(K) ={r∈ R,其中dom(r) = O}。因此,给定一个关系 r和在集合 F={∀, ∃, ∀∃, ≥, ≥f, ≤, ≤f}中选择的一个量词 f。 k将ran(r)中的对象集映射到dom(r)中的对象集,即 k: F× R×∪i=1,…,n P(Oi) → ∪i=1,…,n P(Oi) [6]。沿某个关系缩放上下文是指通过使用缩放算子将该关系以单值属性的形式集成到上下文中。通过对上下文起源的所有相关关系进行扩充,从而在K上增加所有生成的关系属性,实现上下文的缩放。因此,一个对象是否拥有某个属性取决于其链接集与概念外延之间的关系,即关系r的实例,例如 rk(oi, oj),其中 oi ∈ Oi和 oj ∈ Oj,被称为链接。输入RCF中每个上下文 Ki ∈ K的演化产生一个序列 Kp i,其零成员 K0 i=(Op i, Ap i, Ip i)即为输入上下文Ki本身。此后,每一个后续成员都是前一个成员在rel(Ki)中的关系上的完全关系扩展。这产生了一个上下文集的全局序列 Kp以及相应的格集序列,称为概念格族(CLF)。因此,概念格族是与形式上下文相对应的一组格,在用关系属性丰富这些上下文之后得到。
在本研究中,我们考虑存在缩放。因此,设 rij ⊆ Oi × O j为一个关系上下文。存在缩放关系 r∃ ij 定义为 r∃ ij ⊆ Oi ×B(Oj , A, I),使得对于对象 oi和概念c:(oi, c) ∈ r∃ ij ⇔ ∃x, x ∈o ′ i ∩ Extent(c)。
B. 多关系文献超图模型
我们的模型涉及三个概念:对象上下文、关系上下文和概念格族。如图1所示,一组作者{a1, a2,…, an}位于给定国家{cr1, cr2,…, cr p} 内,在不同的主题{t1, t2,…, tk};其中一些共享科学贡献(在一组会议{c1, c2,…, cl}内的贡献{ar1, ar2,…, arm})。为了总体描述此类协作数据,我们将对象上下文定义为同一类型的对象或实体的集合,e.g.,作者上下文是一组作者,并将关系上下文定义为对象上下文之间的交互,e.g.,(作者, 主题)关系、(国家, 会议)关系等。我们使用关系概念族来描述关系上下文和对象从多关系文献超图构建的上下文。图1描绘了所处理的多关系文献超图的数据模式。关系概念族由5个对象上下文: KAuthors,KCountries, KConferences, KT opics, KContributions;以及5个关系上下文:rLocates, rHolds, rHas, rDiscusses和 rAddressed−By组成。我们在图2(上)中展示了这5个对象上下文,在图2(下)中展示了相应的5个关系上下文。

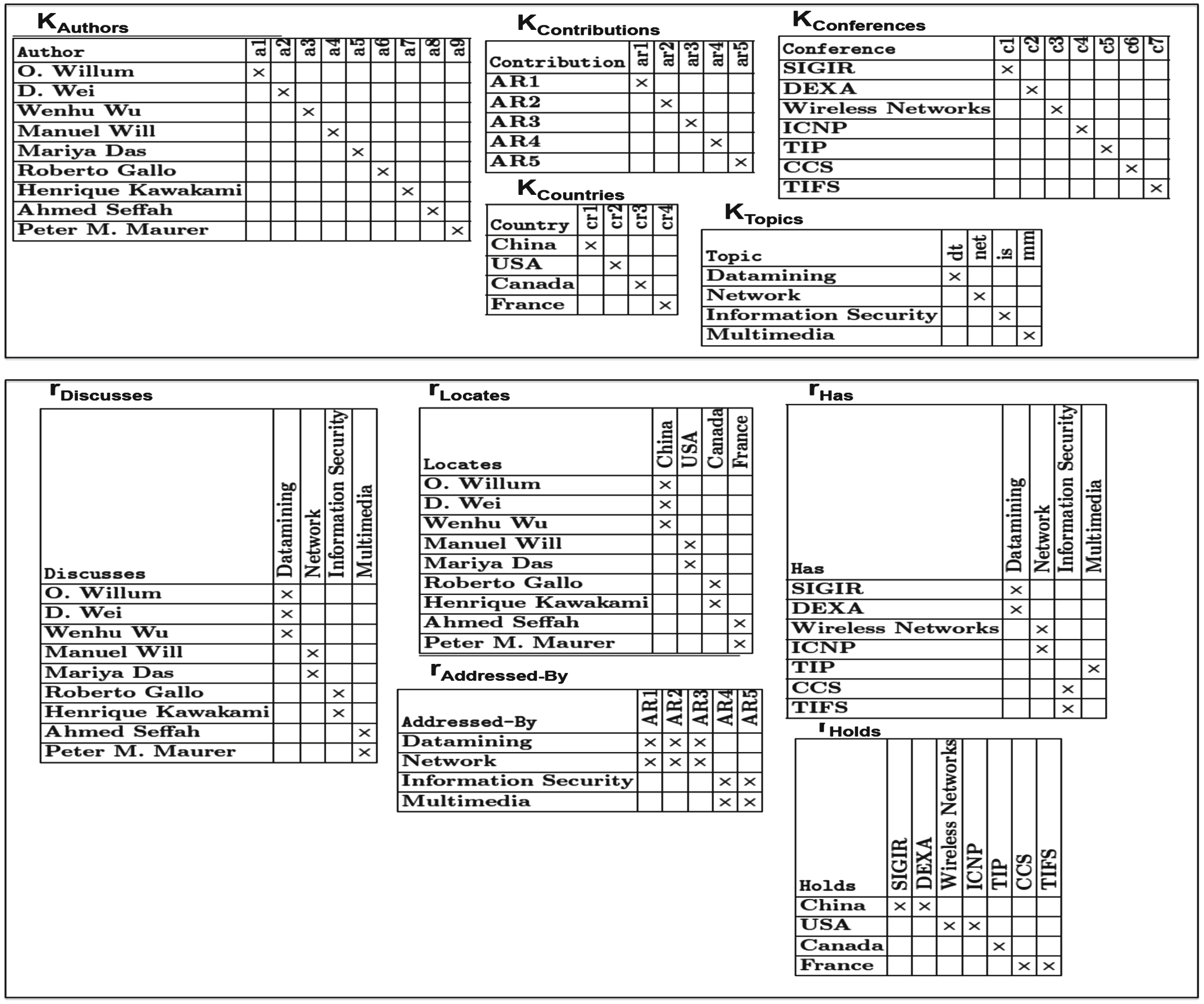
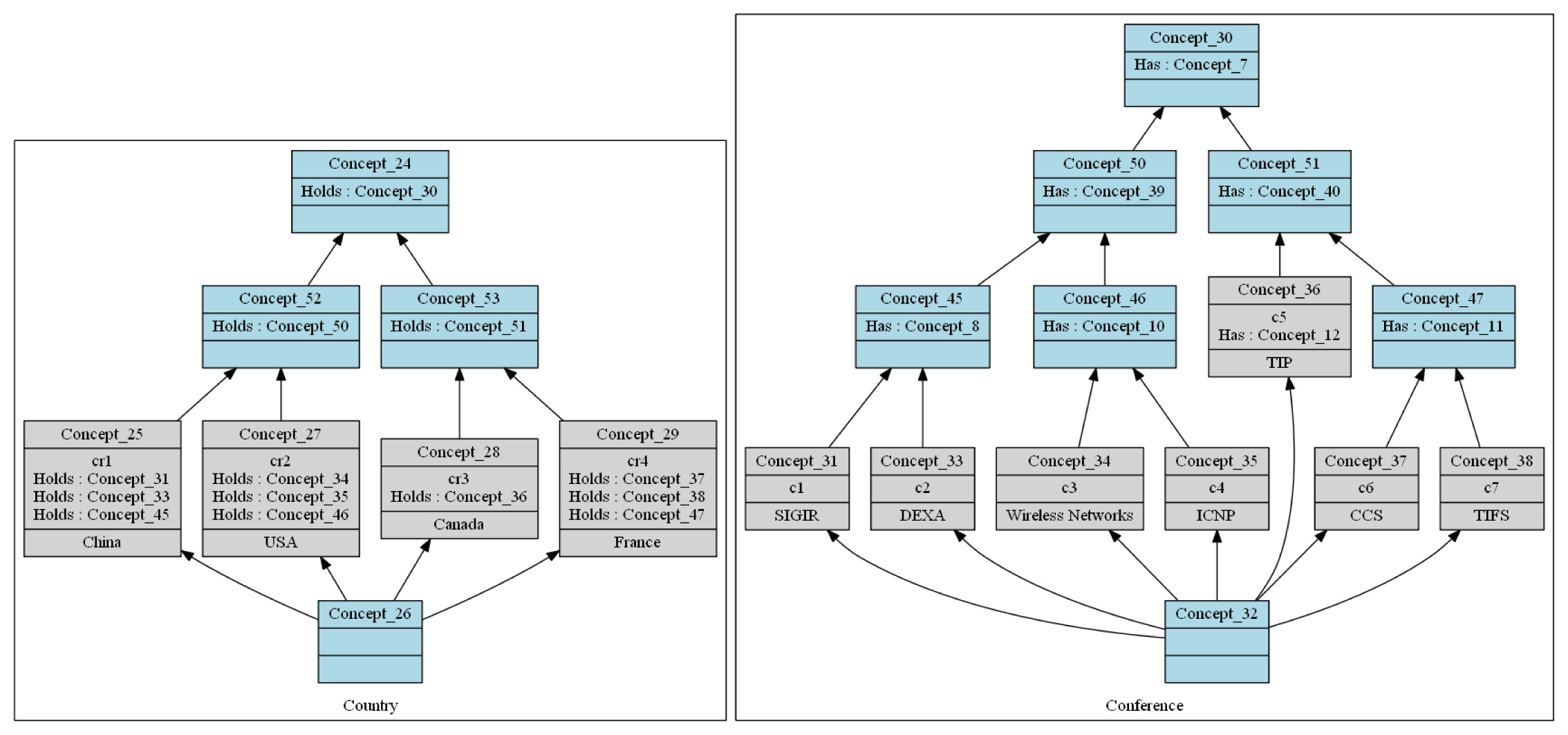
RCA的整体流程遵循一种多FCA方法[6],该方法能够构建一组称为概念格族(CLF)的格。这是一个迭代过程,在每一步生成一组概念格。首先,该过程仅使用对象上下文来构建概念格。然后,在后续步骤中,通过存在性缩放算子将对象上下文与关系上下文进行拼接,从而生成缩放后的关系。因此,存在的缩放后关系将对象之间的链接转化为传统FCA属性,并提取出一组概念之间通过关系相连的格。图3展示了生成的国家与会议格的示例,属于CLF。
社区发现的查询导航
所提出方法的第二阶段旨在通过执行以下三个步骤来提取一组学术社区:
- 步骤1:用户关系查询提交 :此步骤的目的是将提交的用户查询转换为一个由多个简单查询(SQ)组成的关系查询 RQ。因此,对于上下文K =(A,O,I),一个记作 SQ={oq}的简单查询是满足该查询(或答案集)的一组对象,且 oq ⊂ O。
定义1(关系查询) 。在关系上下文族(K,R)上的关系查询 RQ={rq0, rq1,…, rqm}是一个三元组 RQ=(q′ s, rst, q′ t),其中:‐ q′ s和 q′ t分别为源查询和目标查询,是 SQ的集合。‐ rst是 q′ s和 q′ t之间的关系,它在 q′ s和 q′ t之间建立一对一映射。
- 步骤2:概念格族探索 :为了探索概念格族,我们必须构建一条查询路径 QP,以了解需要遵循的路径,并指定源格和目标格。
定义2(查询路径) 。设QP ={qp0, qp1,…, qpn}和 qpi是一个对((qs, Ls),(qt, Lt)),其中 Ls和 Lt ⊂ CLF分别为源格和目标格。查询路径 QP是关系查询的逆序。这意味着 qp0= rqm和 qpn= rq0;其中 qs0= q ′ tm和 qt0= q ′ sm
- 步骤3:社区检测 :为了检测学术社区,我们提出了一种新方法,称为 Query Navigation该方法基于提取的查询路径引导在伽罗瓦格之间的导航 QP。它以查询路径QP= qpk 其中qp=((qps, Ls),(qpt, Lt))作为输入,并输出识别出的社区作为对用户查询Q的回答。 Query Navigation通过处理源格中的所有概念开始 C,以提取初始查询路径的相应概念( Ls) Ci。在第二阶段中,通过识别格中的概念外延,然后提取包含与查询相关的外延的概念。 qp0初始阶段的结果是一组响应查询的概念 Query Navigation。 Ls的第二阶段包括迭代生成一组包含初始阶段提取的概念集( qps)的概念。该过程涉及处理格中相应的概念内涵,以提取包含 Ci的概念集( qps)。如果没有更多需要探索的查询路径,则 Query Navigation提取最后选定概念的外延 (Ci)。该组Lt外延表示构成返回给用户的学术社区的个体集合。
3 实验评估
我们从两个书目数据库中收集数据。我们使用著名的DBLP数据库,并访问 AMiner数据库以获取关键词、机构和研究主题,从而完善我们的概念超图模型。我们仅保留四个研究主题(数据挖掘、计算机网络、人工智能、人机交互、计算机图形学),并为这五个领域选取少量代表性会议(共11个会议)。构建的数据集包含自2010年以来的914项贡献和336位作者。 Query Navigation算法采用JAVA开发,在配备Intel核心i5 2.4 GHz处理器和8GB内存的 Windows 7系统上进行测试。
基线模型
: 为了提高我们方法的有效性,我们选择了最流行的基线社区结构,该结构将社区定义为具有相同隶属关系的一组作者。为了开展实验,我们考虑了两个简单查询(Q3 和 Q4)以及两个关系查询(Q1 和 Q2)。我们研究了我们的方法是否能够捕捉作者之间的隐藏关系,以及是否能够响应不同类型的查询:
Q1: 4个实体,即,作者、国家、会议和主题;以及3种关系,即,位于、举办和拥有。
Q2: 3个实体,即,作者、国家和会议;以及2种关系,即,位于和举办。
Q3: 2个实体,即,作者和国家;以及1种关系,即,位于。
Q4: 2个实体,即,作者和主题;以及1种关系,即,讨论。
此外,我们考虑两种不同的真实基准 [8]。第一个真实基准GT1:数据集中每个明确的作者主题是一个真实基准社区,它包含具有相同主题的作者节点。第二个真实基准GT2:每个明确的作者会议是一个真实基准社区,它包含参与同一会议的作者节点。
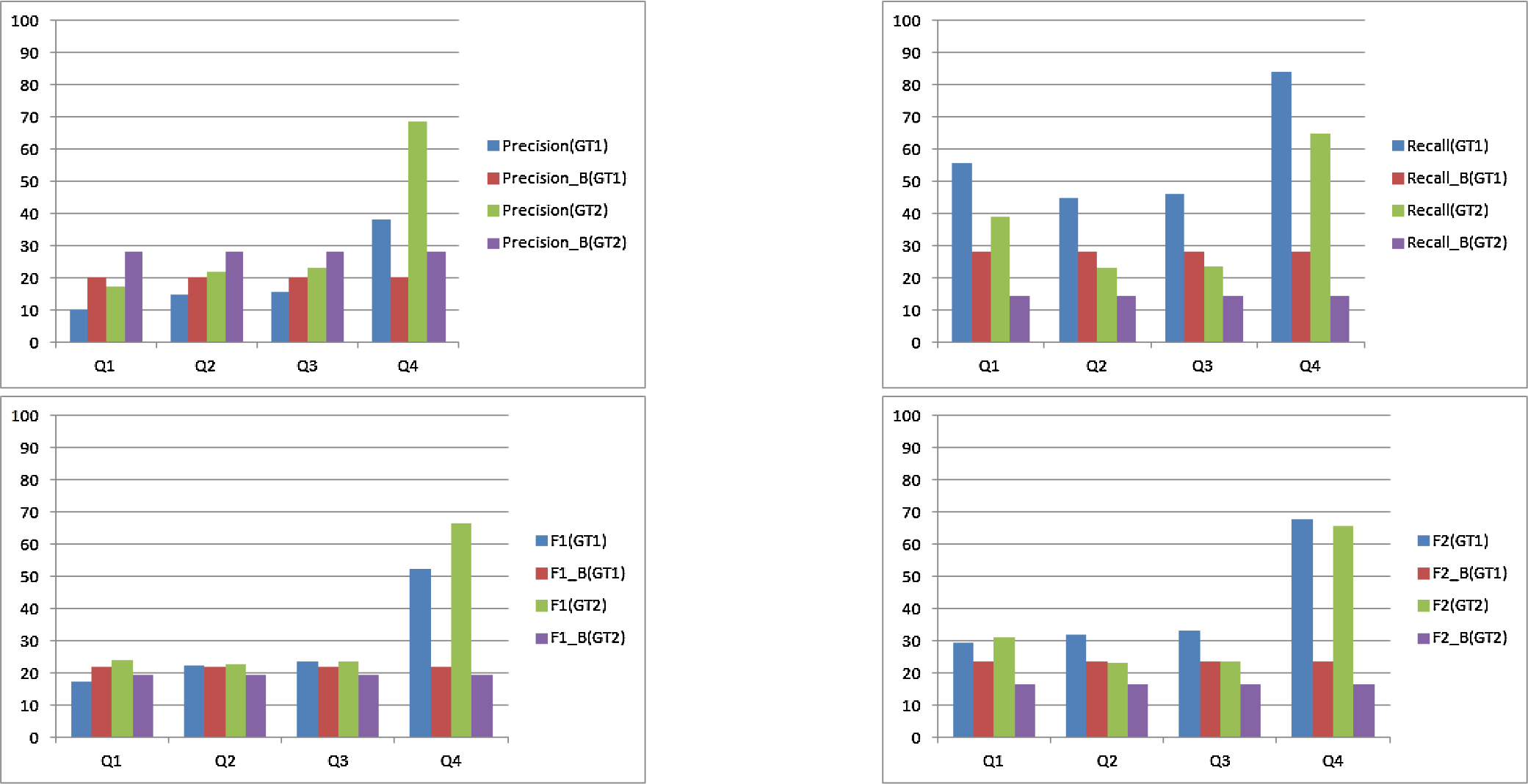 在精确率、召回率、F1度量和F2度量上的平均得分比较 vs.)
在精确率、召回率、F1度量和F2度量上的平均得分比较 vs.)
我们的方法的有效性:通过召回率、精确率和Fβ值在所有顶点上进行度量来评估性能。[7]这些度量试图估计预测顶点属于同一社区的准确性。给定一组算法社区C和真实社区S,精确率表示实际在同一真实社区中的顶点数量(Precision=$\frac{|T∩S|}{|T|}$)。召回率表示在一个被检索到的社区中被预测为属于同一社区的顶点数量(Recall =$\frac{|T∩S|}{|S|}$),而Fβ值是精确率和召回率的调和平均数(Fβ值 =$ \frac{β × Precision×Recall}{Precision+Recall}$其中 β ∈{1,2})。
因此,根据图4中粗略绘制的直方图,我们可以指出,我们的方法优于基线。事实上,正如预期的那样,在两个真实基准(GT1和 GT2)中,基线的召回率值远低于我们的方法所达到的值。如我们所示,平均召回率达到83.87%和 65.02%,而基线的召回率分别为28.31%和14.58%,在查询 Q4上相对于两个真实基准分别超出约55.5%和50.4%。实际上,在F2度量方面,我们的方法 (67.61%,65.7%)相较于基线(23.44%,16.5%)在查询Q4上显著优于 GT1和GT2,因此在这种情况下,我们可以说基线仅有少量社区被较为准确地检测到,且检测出的许多社区并未反映真实基准中的社区。
然而,根据 Q1, Q2和 Q3,基线的精确率百分比略高于我们的方法。而对于 Q4,我们的方法平均为68.57%,相比基线下降了28.31%,但超出基线约 40.2%。一个重要的观察结果表明,该关系查询 Q1在召回率(55.68%)上优于简单查询 Q3和关系查询 Q2 (44.85 %)。我们可以得出结论,关系查询改善了社区结构,并有助于提取相关社区。因此,在考虑四种不同查询的情况下,我们的方法在召回率、F1度量和F2度量方面均优于基线,尤其在召回率得分上优势显著。
4 结论
本文提出了一种从异构多关系书目网络中发现学术社区的新方法。该方法考虑了书目超图中表达的不同实体和关系。事实上,我们利用RCA技术并通过一种新提出的方法 Query Navigation来建模和探索异构多关系文献网络,以实现学术社区检测。作为未来工作的一部分,我们计划通过引入其他量词(如 ∀量词)来处理更多样化的查询。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









