




 博客介绍了loss的公式为误差加正则,列举了多种Loss Term,如0 - 1 loss、Hinge、Log、Squared loss、Exponential loss等,还介绍了top1 loss这种启发式组合损失函数,由两部分组成,以及BPR loss,其目标是使正样本与负样本之差尽可能最大。
博客介绍了loss的公式为误差加正则,列举了多种Loss Term,如0 - 1 loss、Hinge、Log、Squared loss、Exponential loss等,还介绍了top1 loss这种启发式组合损失函数,由两部分组成,以及BPR loss,其目标是使正样本与负样本之差尽可能最大。

loss=误差+正则
http://www.cnblogs.com/rocketfan/p/4083821.html
1.1 Loss Term
- Gold Standard (ideal case):0-1 loss, 记录分类错误的次数
- Hinge (SVM, soft margin)
- Log (logistic regression, cross entropy error)
- Squared loss (linear regression)
- Exponential loss (Boosting)
top1 loss:
这是一种启发式的组合损失函数,由两个部分组成:第一部分旨在将目标分数提升到样本分数以上,而第二部分则将负样本的分数降低到零。第二部分其实就是一个正则项,但是并没有直接约束权重,它惩罚了负样本的得分。因为所有的物品都有可能作为某一个用户的负样本。具体公式如下
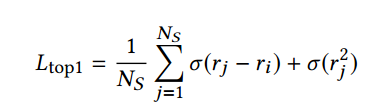
这里j对应负样本(未观测到的),i对应正样本
BPR loss:使正样本与负样本之差尽可能最大


















 4213
4213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









