






省流:
在源码上构建 AST, CFG, DFG,然后经过 Conformer 构建多维度特征 concat 起来,最后用一个 MLP 判定漏洞存在性。 通过多个维度,统一表示程序的结构信息和语义信息 (structural data) 和 (semantic data)。
- CNN + transformer 的多模态大模型做漏洞发现 (vulnerability identification)。
- 预训练 llm Unixcoder 做上下文词嵌入提取 CSE
author:
arxiv23,感觉是不是不发表了……
作者学校有点弱,通讯的 pub 也不太好,但是好在论文开源了。
Authors:
- 一作:Jin Wang,广东财经大学
- 通讯:肖银皓,广东财经大学
abstract:
传统漏洞检测方法耗时费力;基于机器学习的方法在复杂数据集上难以捕捉高维特征(?这是什么);基于深度学习的方法不能捕捉足够的特征信息(?);自注意力机制能处理长距离信息,但是没法捕捉结构信息(structural information?)。因此,本文提出 DefectHunter 工具,同时提取语义和结构。
DefectHunter 使用 Conformer 机制,将自注意力机制和 CNN 融合,用来同时捕获局部位置特征和基于内容的全局交互。此外,我们通过调整分母优化了自注意力机制,以减少过多注意力头引入的额外噪声。为探究DefectHunter如何理解漏洞,我们进行了案例研究,结果表明该模型能有效解析漏洞的底层机制。
我们使用六个工业级数据集和两个高复杂度数据集,将DefectHunter与十种基线方法进行对比评估。在QEMU数据集上,DefectHunter的准确率比Pongo-70B提高了20.62%;在CWE-754数据集上,其准确率提升了14.64%。
据说 Qemu 和 FFmpeg 数据集的洞更难识别一点。
1. Introduction
首先引入情景,计算机技术发展促进人类活动方式改变,存在安全漏洞问题很关键。
多年来的进展在漏洞发现方向取得了长足的进展。传统的发现方法包括静态分析和动态分析两种。其中静态分析可以使用诸如 FlawFinder 和 Findbugs 的工具,似乎不是本文重点没展开;动态分析方法难以检出复杂的漏洞,例如涉及到系统架构的洞。
传统静态分析工具例举:(不是 IR 框架)
- C/C++: FlawFinder, cppchecker
- ObjectiveC: clang
- Java/Android/C Family: Infer
随着机器学习的发展,学界提出了一些数据驱动的方法,如 VCCFinder(2015) ;近年来的深度学习工作在大规模数据集上表现的更好,如基于图的 FUNDED 和 Devign;基于语义的 Codebert 和 CodeT5。GPT4 的出现更是推高了基于语义方法的上限。
然而这些方法不能结合语义和程序结构信息,因此本文提出 DefectHunter,一个缝合了静态分析工具,预训练模型和 Conformer 机制(CNN augmented Transformer)的框架。其中,
- 从代码片段提取静态分析特征,并 tokenize,形成包含上下文语义的特征序列。
- Conformer[10] 结合了自注意力和卷积,同时捕捉局部特征和远距离的依赖。
- 文章微调了 Conformer 内部注意力机制的分母,以减小 softmax 引入的噪声[11]
作者可能是做实验发现 Conformer 比 Transformer 好使,既能建模复杂关系也能优化计算效率。
在 FFmpeg, QEMU, CWE 数据集上,和 10个对比方法跑实验。用 ACC 统计,好 10%-20%
2. Background
没讲相关方法,而是主要讲解相关技术的原理
2.A Graph
使用 cfg + dfg 两种图(还有 ast 但是没写)。图带来了很多好处,首先他们封装了代码的内在结构信息,帮助理解数据依赖性和控制流关系。其次,图省略了无关信息,减轻了分析复杂度。最后,基于图的方法天然和其他 ml 方法兼容。
2.B Self-Attention based Methods
基于自注意力的方法在计算效率和捕捉长距离依赖的能力间取得了良好的平衡。
- Transformer: 解决了 RNN 和 CNN 在长距离推理时面临的内生性问题。这使得它特别适合解释序列问题和结构化数据的场景
- Conformer: 对 Transformer 的改进。transformer 在处理长序列时是平方的,效率受限。Conformer 结合 CNN 和自注意力改善这一点。Conformer 通过前馈 CNN 模块来捕捉局部信息,并保留了自注意力机制来捕捉全局上下文。
2.C LLMs
LLM 凭借巨大的参数量捕捉复杂语言结构,并产生上下文相关的文本。
3. Design of DefectHunter
DefectHunter 包含三个主要部分。1. 结构化信息生成 2. 预训练模型 3. Conformer。具体来说
行文的小心思:不要在章节总起处直接说工具名字
- 使用开源工具 tree-sitter 生成 CFG, DFG 等结构化信息(AST)
- 使用 UniXCoder,一个代码理解 embedding 特化的 llm 提取语义特征矩阵(vector)。
- 使用 Conformer 机制,从 structual data 和 semantic data 两个方向蒸馏漏洞特征。
- 魔改 Conformer,减少多余的头产生的噪音。
- 用 MLP 做二分类,判定存在还是不存在。
3.A 结构化信息提取
使用 AST, CFG, DFG 有助于 llm 对程序结构逻辑和数据流的全面理解
- AST: 表示程序的抽象语法结构。节点表示语法结构,边表示层次关系
- CFG: 描述了可能的程序路径,节点表示程序结构,边表示转移关系。标识了 entry 和 exit
- DFG:捕捉操作之间数据和依赖关系的相互作用,标识变量的实例化,修改,和使用位置。节点表示变量或者操作(var/op),边表示数据依赖。
3.B Code Sequence Embedding (CSE)
使用 pretrained model 生成 word-embedding,称为上下文特征表示 (contextual token representation)。和传统 word-embedding 不同,传统方法刚需二次训练,CSE 直接用更泛化的预训练模型,避免过拟合。
P i = model ( x i ) P_i = \operatorname{model}(x_i) Pi=model(xi)
其中, x i x_i xi 是代码片段, P i P_i Pi 是嵌入表示
3.C Conformer
作者水了很多篇幅介绍 transformer 的各个部分,包括位置编码,注意力公式。甚至有点错误
Conformer 结合了 CNN 和 attention,CNN 负责提取局部复杂特征,attention 捕捉远距离依赖

一个 Conformer 块如上图,主要由一个 CNN 层,一层多头自注意力,两个前馈层组成。作者似乎真的是用的乘法来结合 PE 和前馈层……
作者提到,使用 softmax 导致注意力头倾向于更强的输出,适合做分类任务不适合做可选的标注任务,特别是当输出是总结性的时候,会引入额外的噪音。并且多个头也比单个头更容易产生噪音。作者参考[11] 在分母加了个 1 1 1,保证导数是正的并且输出收敛:
A t t e n t i o n ( Q i , K i , V i ) = Softmax ( Q i K i T 1 + d k ) V i Attention(Q_i, K_i, V_i) = \operatorname{Softmax}\left(\frac{Q_iK_i^T}{1 + \sqrt{d_k}}\right) V_i Attention(Qi,Ki,Vi)=Softmax(1+dkQiKiT)Vi
其他部分和正常 transformer block,CNN 一样。
4. Implementation

4.A 建图 AST, CFG, DFG
- 用 tree-sitter 建立 AST,然后转换为 Graphviz Dot format,最后提取其中的边转换为邻接矩阵
- CFG 和 DFG 基于 AST 构建
4.B CSE
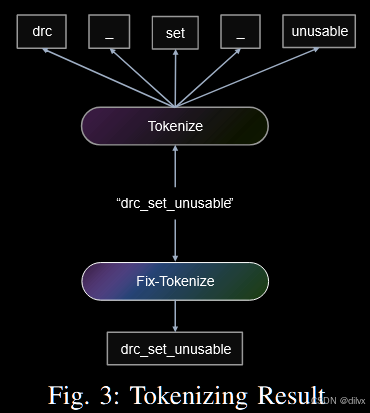
使用微软的预训练多模态模型 UniXcoder 提取语义特征。在实验中作者发现 tokenize 会有问题,如下图上半部分,函数名会被拆开导致不精确,为了解决该问题,作者使用 NTLK 库魔改 token,并创建了 special token 词表。 UniXcoder最多支持 768 个 token
作者用 keras 层实现该方法
5. 实验
先跳了。
case study
找了四个 case,写作时不是在分析工具如何判定漏洞,而是在讲这个漏洞的危害,最后一句话提 DH 能正确分别 patch 和没 patch 的程序。
6. 相关工作
写的是漏洞识别相关的工作。


















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









