




 本文详细探讨了数据结构和算法,包括递归、排序算法(如快速排序、桶排序、计数排序、基数排序)、二分查找、深度优先与广度优先算法、贪心算法、分治算法、回溯算法、动态规划。还介绍了字符串匹配算法(如BF、RK、BM、KMP算法)以及多模式串匹配的Trie树和AC自动机。同时涉及了拓扑排序、最短路径算法、爬虫中的布隆过滤器、垃圾短信过滤的朴素贝叶斯算法、音乐推荐的多维空间向量距离、游戏自动寻路的A*算法、索引结构(如B+树、红黑树、跳表)以及并行算法。此外,文章涵盖了数据结构,如数组、链表、栈、队列、跳表、哈希表、树(包括红黑树、堆、Trie树、B+树)和图。实战部分讲解了Redis的使用以及数据结构在搜索引擎、短链系统中的应用。
本文详细探讨了数据结构和算法,包括递归、排序算法(如快速排序、桶排序、计数排序、基数排序)、二分查找、深度优先与广度优先算法、贪心算法、分治算法、回溯算法、动态规划。还介绍了字符串匹配算法(如BF、RK、BM、KMP算法)以及多模式串匹配的Trie树和AC自动机。同时涉及了拓扑排序、最短路径算法、爬虫中的布隆过滤器、垃圾短信过滤的朴素贝叶斯算法、音乐推荐的多维空间向量距离、游戏自动寻路的A*算法、索引结构(如B+树、红黑树、跳表)以及并行算法。此外,文章涵盖了数据结构,如数组、链表、栈、队列、跳表、哈希表、树(包括红黑树、堆、Trie树、B+树)和图。实战部分讲解了Redis的使用以及数据结构在搜索引擎、短链系统中的应用。
2. 算法
2.1 递归
找规律和终止条件
要注意重复计算和堆栈溢出
应用
2.2 排序

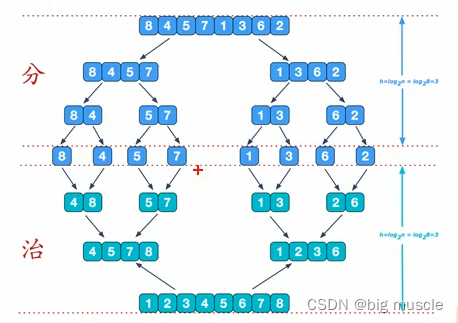
归并
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
插入排序比冒泡排序快,因为代码赋值操作比较少
原地排序算法,就是特指空间复杂度是O(1)的排序算法
排序算法的稳定性:如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
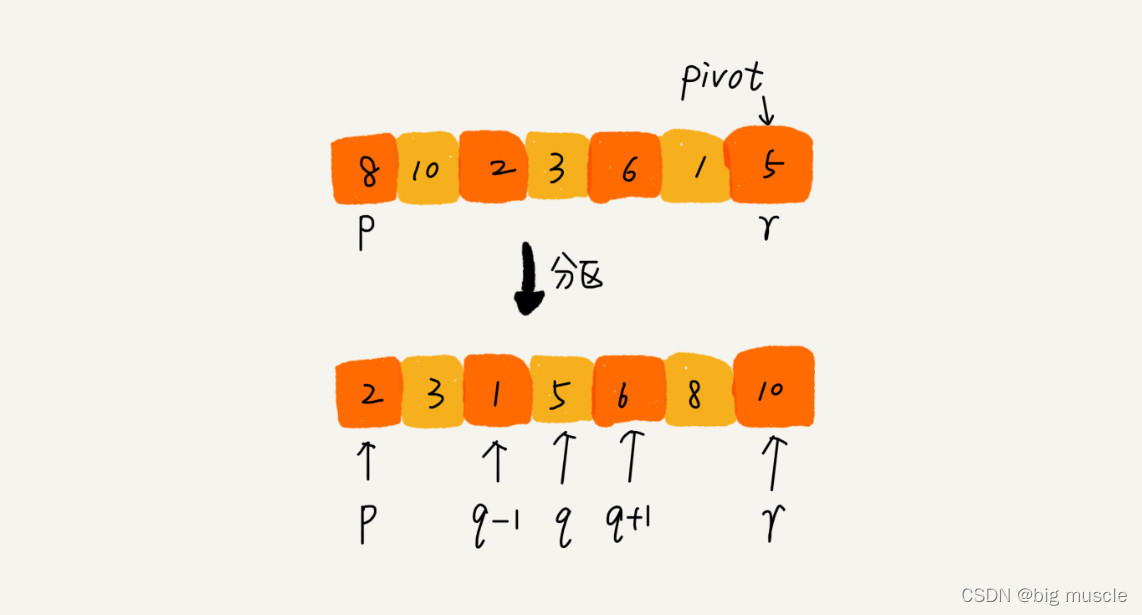
快速排序
桶排序
桶排序对要排序数据的要求是非常苛刻的。
首先,要排序的数据需要很容易就能划分成m个桶(范围不能太大),并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。(桶内的元素使用快排)
其次,数据在各个桶之间的分布是比较均匀的
例子
根据年龄给100万用户数据排序
计数排序
桶排序的个例,每个筒内的数据相同,当要排序的n个数据,所处的范围并不大的时候使用,省掉了桶内排序的时间
例子
高考考生分数排序(满分750分,750个桶,每个桶中学生分数相同,计算每个桶中个数和,然后计算排名)
基数排序( 对数据的每一位从后往前进行排序(每一位用桶排序或计数排序,要是稳定性的))
例子
手机号的排序
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果a数据的高位比b数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到O(n)了
2.3 二分查找
数据必须是有序的,依赖数组(基于下边访问元素)
凡是用二分查找能解决的,绝大部分我们更倾向于用散列表或者二叉查找树,二分查找更适合用在“近似”查找问题,如:查找第一个值(最后一个值)等于给定值的元素、查找第一个大于等于给定值的元素、查找最后一个小于等于给定值的元素等
2.4 深度优先算法( 中序遍历(用递归))
例子
- 验证二叉搜索树
- 树最小最大深度
private static int area;
private static int m = 0, n = 0;
private static int[][] dirs = {
{
-1, 0}, {
0, -1}, {
1, 0}, {
0, 1}, {
-1, -1}, {
1, -1}, {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 12万+
12万+




 到【灌水乐园】发言
到【灌水乐园】发言







