



5. 强化学习的可视化和维测设计
RL 是一门非常复杂的算法,而精度维测是深入理解的第一步。突击队结合ICT解决方案的系统DFX设计经验,对PPO流程进行了分层分级(step级、response级、token级三层)的全面打点,使能GPU和NPU的数据比对。同时,我们对接和修改了RL Logging Board(一个将RLHF的训练过程进行可视化的开源工具),方便维测数据的可视化分析。
另外,考虑到生成稳定性对RLHF的训练效果至关重要,我们专门针对生成质量开展了维测设计分析工作。
5.1 step级指标
我们在训练过程中每步迭代增加了全量的维测指标,来监控训练每一步的正常与否。全量指标如下:
- 总体维测指标:rewards/critic loss/ppo loss
- 生成阶段维测指标:response len/total len/ppl/kl散度
- Critic训练维测指标:return/values/critic loss clip/critic learning rate
- Actor训练维测指标:kl sample and ref/net reward/advantages/actor ratio/actor learning rate 如下图所示,工具可以通过上方tab页切换不同step级指标,从而绘制step级曲线。
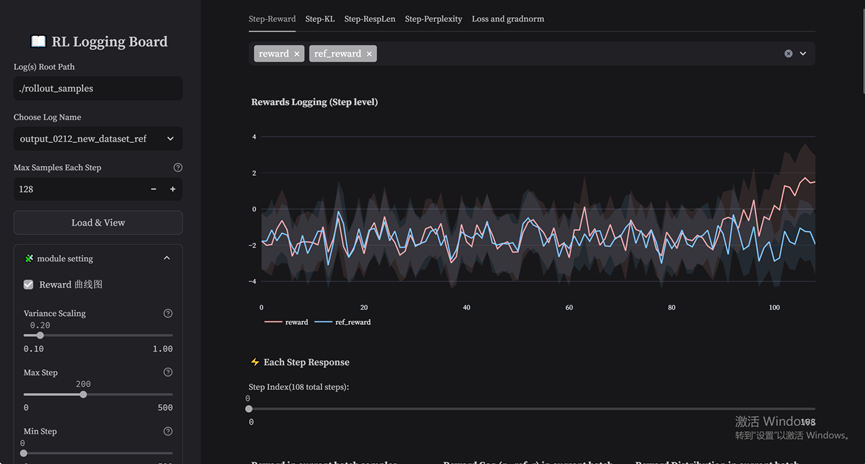
工具原始指标包含:Reward、Ref_reward、KL散度、Response Length四种step级指标。突击队在此基础上添加了:Net_Reward、 Perplexity、Ref_perplexity、Advantage、Return、Actor Loss、PPO Loss、Actor Abs PPO 、Critic Loss、Critic Gradnorm、Actor Ratio等各项指标;同时还在左侧工具栏增加了Min Step和Max Step的滑动轴,用于调节曲线的数据范围,可以在指定step范围内生成曲线数据进行更细致的对比。
5.2 句子级的指标
工具可以指定具体step,打开分析内部不同response的reward差异。下图以step0为例,比较Reference和Actor生成response的reward,给出reward差异和分布可视化图。 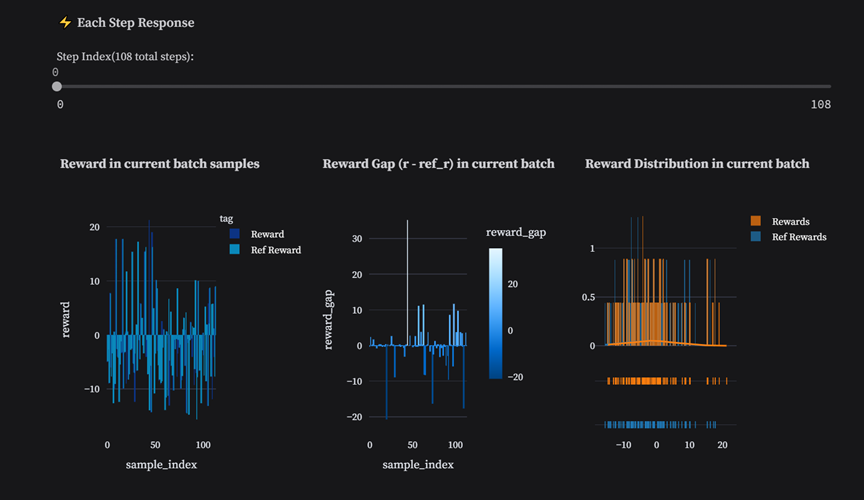
工具可以选择任意步数,展示response级的指标,其中包含prompt文本、response文本、reward、log_ratio、kl散度、perplexity等。 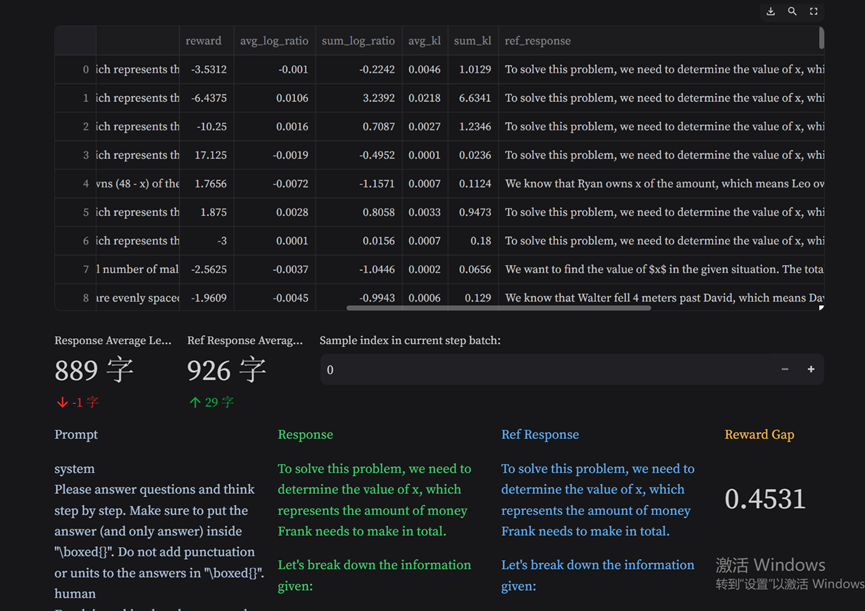
5.3 token级指标和热力图
PPO loss和Critic loss需要重点关注,对这两个参数进行重点拆解: 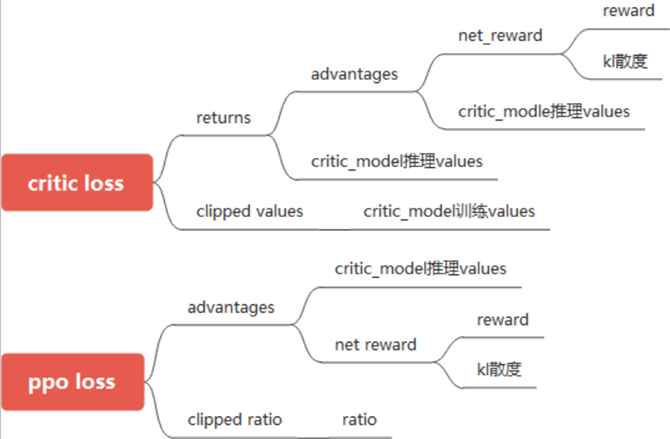
token级别的维测包含:advantages, ratio, returns, values, train_values,net_reward, reward, kl sample_and_ref, ppo_loss, critic_loss, logprobs,ref_logprobs, clip_ratio, clip_values等。 工具可以指定任意句子,展示token级别的数据,并绘制相关热力图。 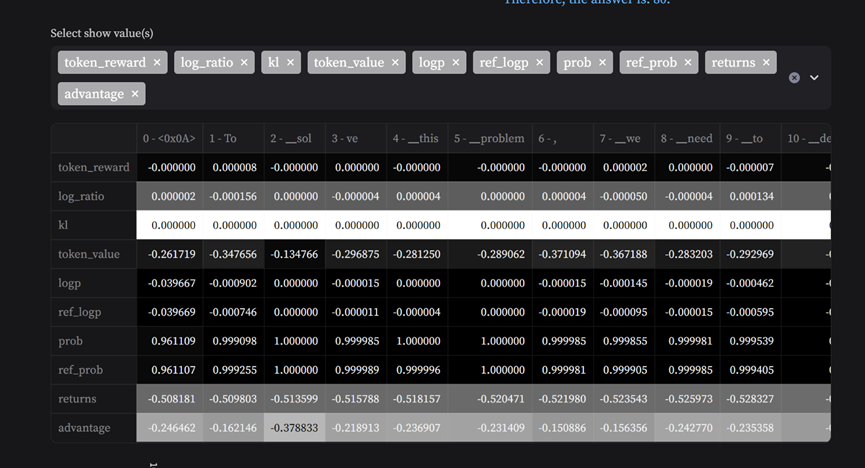

5.4 生成质量分析
RLHF中,response生成质量的度量非常重要。通常看以下两个指标:
- 困惑度perplexity
- response的长度
- RL过程中生成长度与困惑度、reward的关联分析 下面的图分析了随着response生成长度差异,reward和perplexity的变化趋势:
- 当生成长度小于200时,困惑度较高;
- 当生成长度超过800以后,reward打分都是负的;
- 大量的生成长度区间分布在200到600以内,这个区间内reward跟生成长度没有明显的相关性。
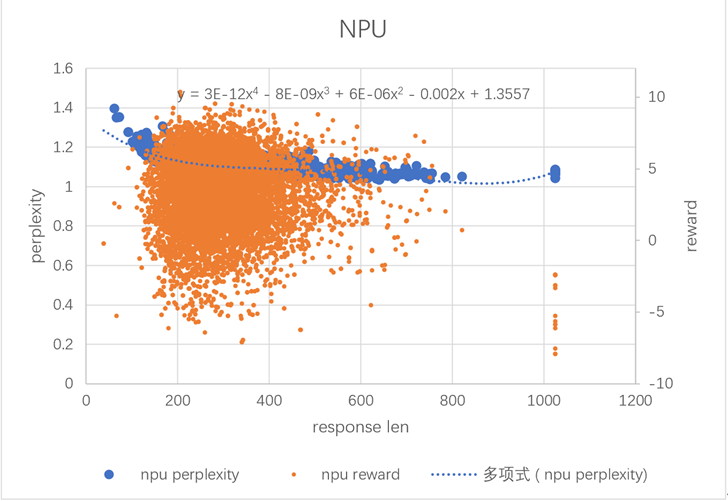 从上图可以看出,生成长度对困惑度和reward打分是有一定影响的。我们希望对每个response,进一步设计指标,分析生成的token困惑程度和困惑个数。
从上图可以看出,生成长度对困惑度和reward打分是有一定影响的。我们希望对每个response,进一步设计指标,分析生成的token困惑程度和困惑个数。
2.Response中每token的top3 prob分析
我们对首步的128个prompt生成结果进行分析,每个prompt生成2次,捞出生成结果不一致的prompt,并统计首次生成不一致的token位置,打印出该位置的top3 prob。 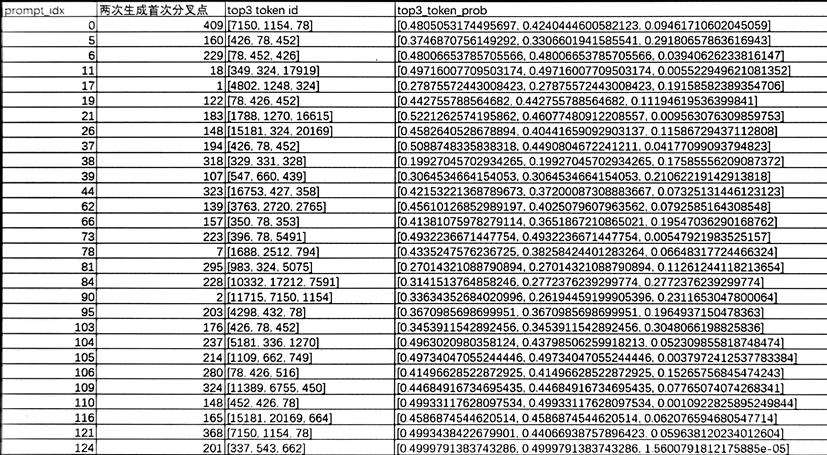 从上图可以看出,生成结果初始分叉位置现象比较统一:top1 prob基本低于0.5,并且top2 prob与top1 prob近似相当。
从上图可以看出,生成结果初始分叉位置现象比较统一:top1 prob基本低于0.5,并且top2 prob与top1 prob近似相当。
3.生成token困惑度指征:Ambiguity Count 根据上文分析规律,新设计一个监控指标Ambiguity Count (AC):统计单次生成步骤(step)中同时满足 低置信度 和 竞争性分布 条件的 token 绝对数量,反映策略在可配置阈值下的模糊决策强度。 计算公式:

参数说明:
α:Top-1 概率阈值,控制低置信度判定严格性(默认 0.5)
β:Top-2/Top-1 概率比值阈值,控制竞争性分布判定严格性(默认 0.88)
T:当前 step 生成的总 token 数
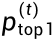 :第t个token的Top-1的概率
:第t个token的Top-1的概率
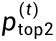 :第t个token的Top-2的概率
:第t个token的Top-2的概率
对每个生成token,需同时满足以下两条件:
- 低置性条件:top-1概率
- 竞争分布条件:top-2与top-1概率比值
针对该企业场景设置α=0.5,β=0.88,阈值α、β需通过验证集调优(如网格搜索或贝叶斯优化),不同任务场景需动态调整。
相对于传统的perplexity指标,AC指标的优点:
- 可解释性:AC的物理意义更为明确,表示的是generation阶段token选择存在疑义的token数量,AC值越大表示这个step中可能出现分歧的token数越多。
- 灵活性:AC有α、β两个参数可以调节,适配不同风险容忍度和任务需求
- 可观测性:当NPU和GPU之间、或者NPU多次训练的生成结果有差异时,可以查看分叉点是否满足上述AC统计指标。若满足,则可认为这个分叉是在模型比较困惑的情况下,微小累积误差导致的正常现象。
下图呈现的是step级别下reward与AC指标的对比情况。可以明显观察到, reward急剧下降时,AC值会迅速上升。 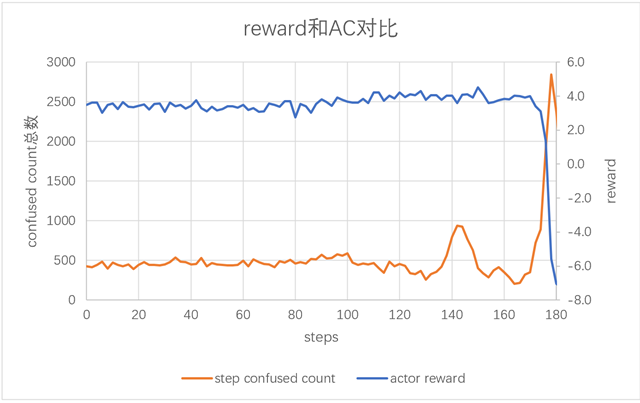
与之形成对照的是,reference model的AC值波动范围比较平稳: 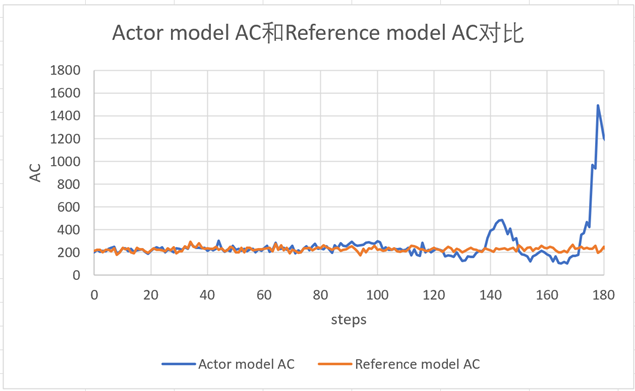
5.5 维测指标分析示例
分层的维测打点,可以从异常现象触发层层深入,先从step级别维测中找到异常的reward步数范围,再对该范围查看response级别维测找到异常的prompt id,最后到该prompt id的token级别维测去分析找出异常token。 以确定性reward曲线为例,在94~96步突然掉坑: 
以确定性掉坑的数据为异常基线,从不开确定性的实验中找出一组90~96不掉坑的为正常基线,对比正常和异常数据下的step级维测。从下图可以看出,异常基线96步reward明显下降,伴随着critic模型的loss上升和value clip count的指标上升。另外,从96步的上一步step94维测指标,可以观测到ppo的clip count异常上升。 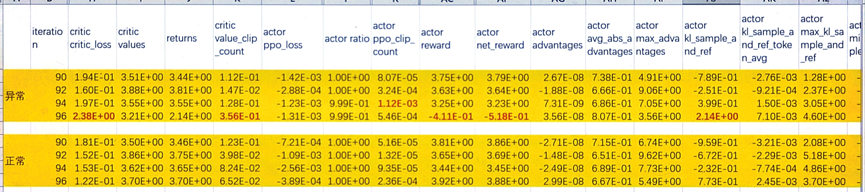
对96步掉坑的数据打开response级别维测,对齐正常和异常配置下的prompt id,找到reward下降最严重的prompt id:114。 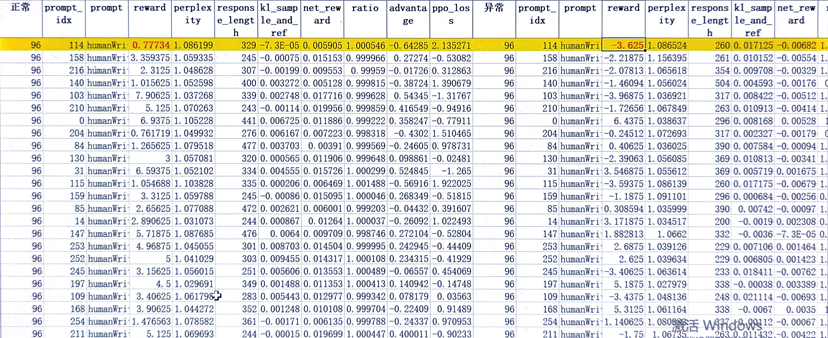
对prompt id 114 token级维测打开分析,在正常、异常配置下,对比每个token的概率,与reference模型生成的差异。下图可以明显看出,正常的reward曲线生成概率与refprobs距离较近;异常的reward曲线生成概率与refprobs距离较远。 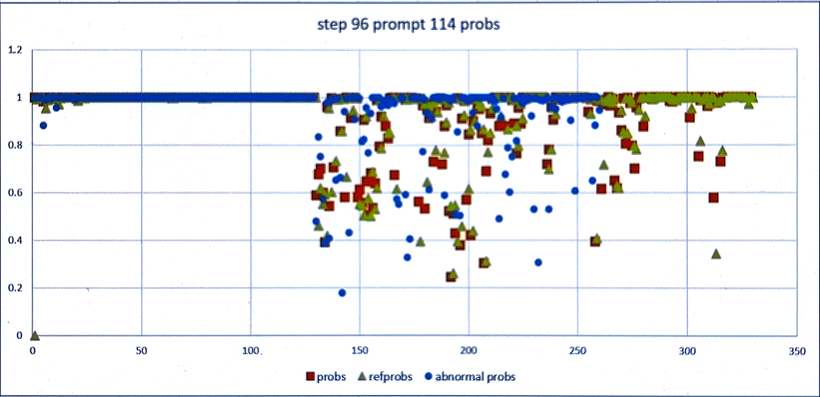

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









