



1.介绍
25年1月开始,我们在某企业现场迁移RLHF-PPO特性。作为昇腾第一个支持RLHF后训练的项目,在开发和测试过程中遇到了不少问题。本文档总结相关经验和维测设计,以指导后续RLHF的精度定位和问题分析。
本文档第一章节介绍PPO算法的原理,第二章节介绍需求和开发,第三章节介绍PPO精度验证结果,第四章对交付过程中遇到的问题和定位思路进行了总结,并在第五章提出PPO相关的DFX维测设计和分析。
1.1 NLP的RL学习
对NLP任务做强化学习(RLHF)的目的:我们希望给模型一个prompt,让模型能生成符合人类喜好的response。
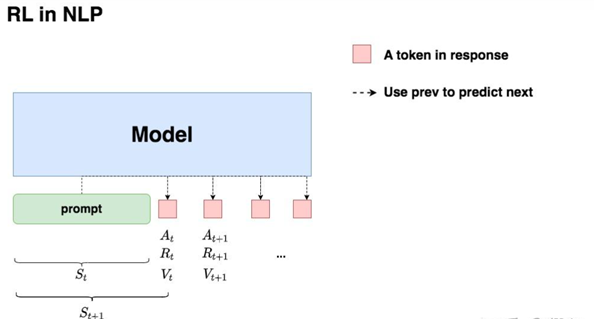
• 我们先喂给模型一个prompt,在 t 时刻,模型根据上文,产出一个token,这个token即对应着强化学习中的动作,我们记为At 。因此在NLP语境下,强化学习任务的动作空间就对应着词表。
• 在 t 时刻,模型产出token At对应着的即时收益为Rt,总收益为Vt(Vt 蕴含着“即时收益”与“未来收益”两个内容)。这个收益可以理解为“对人类喜好的衡量”。此刻,模型的状态从St变为St+1,也就是从“上文”变成“上文 + 新产出的token”。
1.2 PPO
在RLHF-PPO阶段,一共有四个主要模型,分别是:
• Actor Model:演员模型,这就是我们想要训练的目标语言模型
• Critic Model:评论家模型,预估总收益 Vt
• Reward Model:奖励模型,计算即时收益 Rt
• Reference Model:参考模型,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型探索的距离越来越远,效果不可控制
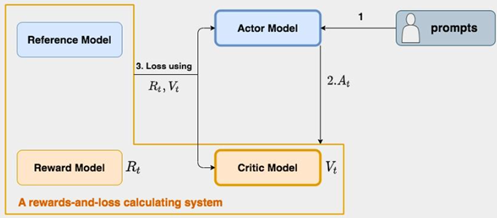
上图中:
• Actor/Critic Model在RLHF阶段是需要训练的(图中给这两个模型加了粗边,就是表示这个含义);而Reward/Reference Model是参数冻结的。
• Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系,综合它们的结果计算loss,用于更新Actor和Critic Model。
• 初始化:通常Actor和reference从同一个模型初始化,critic从reward模型初始化。
• PPO的训练可以分三个阶段:
- 阶段一生成:采样一批指令集(Prompt),生成推理结果(Prompts+Responses);
- 阶段二推理:将Prompts+Responses输入到四个模型一起计算后续模型训练需要的输入;
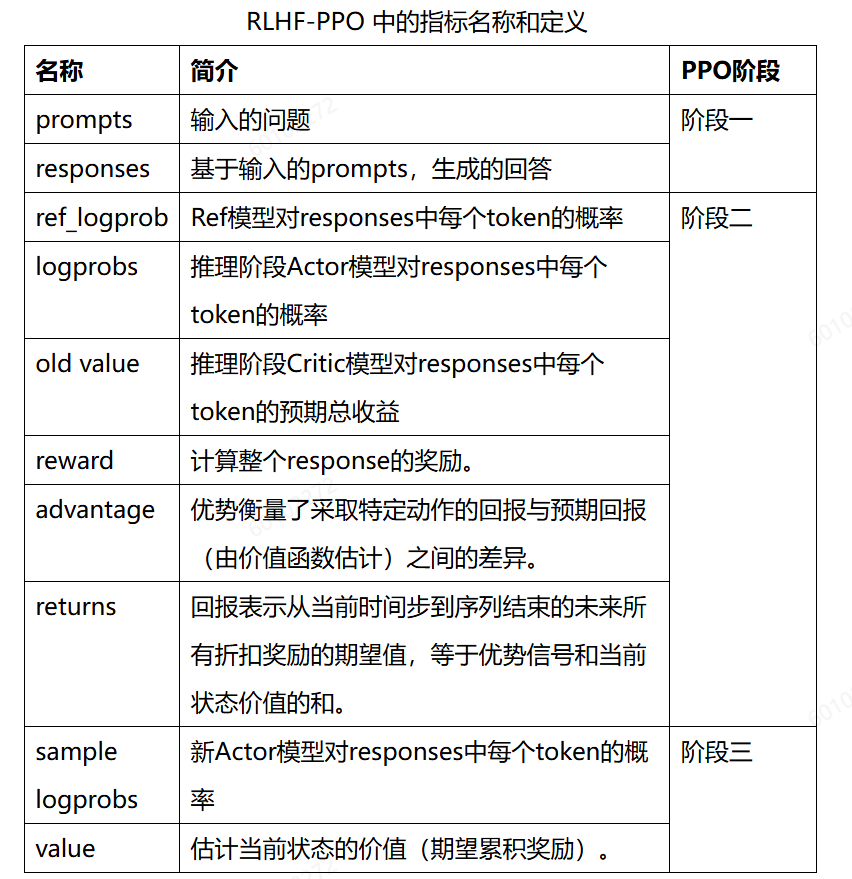
- 阶段三训练:训练 Actor Model 和 Critic Model。阶段一生成的数据,根据超参配置,阶段三可以通过训练update参数多次。训练过程中,涉及的指标名称以及定义,如下所示:
2.需求分析和软件设计
2.1 需求分析
该企业在GPU上基于megatron开发了训推共卡的PPO框架,训练和推理引擎都是自研。而该企业对昇腾的RLHF框架需求是采样阶段使用vllm生成。由于该企业GPU版本代码训推框架基于megatron,在接入vLLM引擎后无法直接复用原有方案,因此需要在该企业GPU版本代码基础上,开发基于Megatron训练+vLLM推理的PPO训推共卡方案。本次PPO的模型调用流程如下图串行顺序所示: 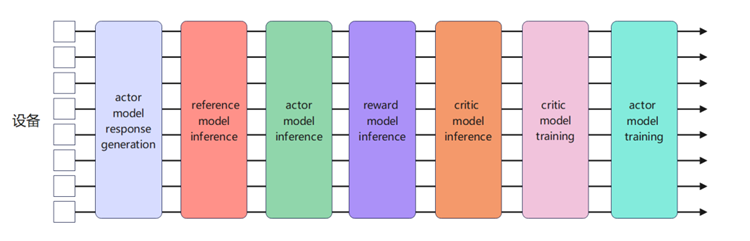
训推共卡方案相比于分离式部署可以显著提升设备的资源利用率。训推共卡方案需求:
- 生成阶段使用vLLM推理引擎,推理和训练阶段使用Megatron框架;
- Actor模型训练和推理共享显存资源,且可以灵活的切换;
- 支持训练和推理使用不同的PDT并行切分策略:由于训练需要保存权重、优化器、梯度、激活值等,显存占用较大;而推理仅需要存储权重,相比训练所需显存少很多。因此本方案当前支持Actor模型训练的TP、PP切分,推理时与训练同TP,但将训练的PP转换为DP。举例来说,模型训练使用TP2 PP4的,而推理可以使用TP2 DP4。
Actor模型训推共卡方案下的状态转换流程如下图所示: 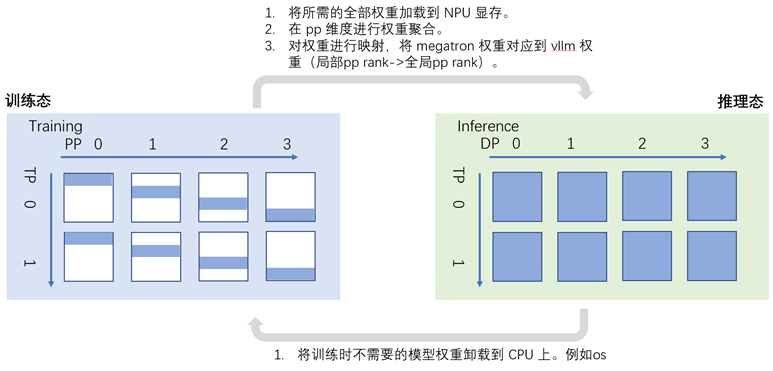
当Actor模型训练时,TP域内每张卡上存储1/PP的模型权重,同时维护相应的优化器状态、梯度、激活等。而当Actor模型推理时,在TP域内每张卡都有完整的权重信息。因此:
- RL启动时的初始化:每张卡上为Actor模型按照PP的切分初始化权重,同时为属于当前PP stage的权重初始化相应的优化器和梯度信息。
- 当Actor模型从推理状态转到训练状态时,将属于当前PP stage权重的优化器和梯度信息加载到显存中,剩余PP stage的模型权重暂时offload到CPU上放置。
- 当Actor模型从训练状态转到推理状态时,需要将其余PP stage的模型权重从CPU上backload到NPU显存中,再将参与训练更新的PP stage参数同步广播到TP域其他卡上,每张卡在PP维度进行聚合得到一个完整的模型权重后,加载或者映射到推理引擎上。
2.2 开发功能
以上需求分解,对应的开发功能和实现流程如下图所示: 
我们在历史交付中,已经支持了某企业的130B大模型在昇腾接入vllm+torch。本次RLHF迁移支持的模型为20B,具体推理适配工作本文不再详述。
1)vllm_adapter适配层
由于vLLM框架仅支持HuggingFace格式的权重,不支持动态加载Megatron格式的权重,因此需要对vLLM进行开发适配,实现vLLM对Megatron格式权重的动态加载功能。
其中最核心的模块是vLLM对不同切分配置下megatron类型权重的加载,即vllm_megatron_weight_loader模块。这个模块的基本原理为:Megatron 与 vLLM 虽然上层接口定义不同,但对于同一个模型,底层存储权重格式和数据类型是相同的。因此可以让 Megatron和vLLM底层共享同一份权重存储,实现vLLM直接映射Megatron权重的格式到huggingFace格式。 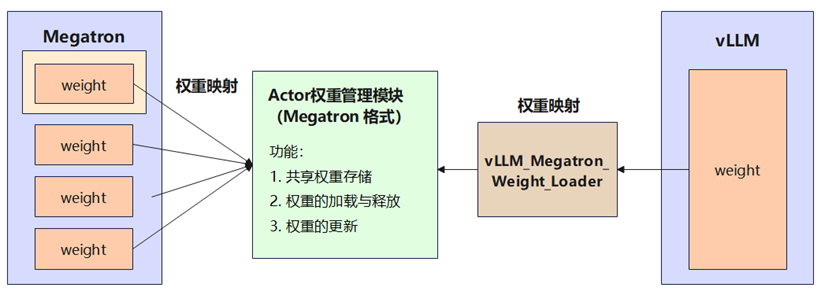
vllm_megatron_weight_loader模块对vLLM的模型加载入口进行patch修改,将原先只能读入HF格式权重的路径修改为可以加载dict格式的megatron parameters,根据模型的megaton权重key值和vllm权重key值的对应关系构建定制的mapping映射关系,这一点与HF与Megatron的权重转换的功能类似。如下图所示,以llama模型为例, 可以构建出一个权重key值的mapping。
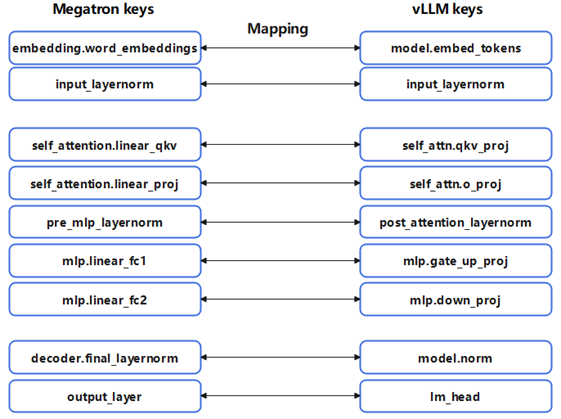
这里需要注意megatron与HF的权重格式在attenton_linear_qkv处存在不一致的情况。下图左边为Megatron格式的QKV权重的排列顺序,其中绿色、蓝色和红色分别对应Q、K和V的权重,可以看到Megatron中QKV的权重是按照每个attention group的方式拼接的, QKV穿插着存放。而vLLM的格式是按照QKV的顺序存放的,因此需要对QKV权重进行reshape的转化后再加载到vLLM中。 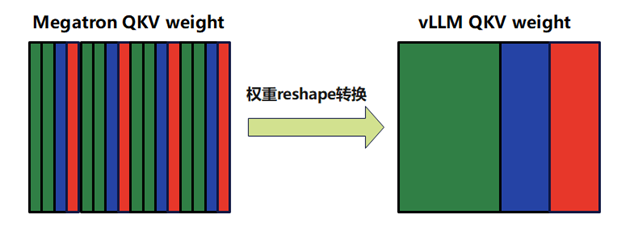
2)Actor模型训推权重管理模块
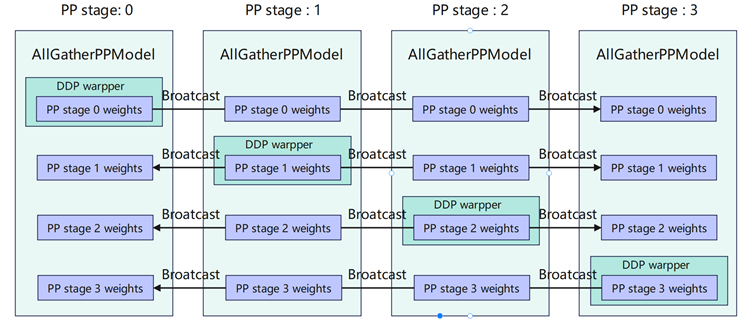
在整个PPO流程中Actor模型需要在训练态和推理态间持续切换,导致权重会在CPU和NPU上来回搬运,因此需要设计开发Actor模型的权重管理模块(AllGatherPPModel),该模块功能包括:
- Actor模型训练权重及推理权重的初始化;
- 权重memory buffer的构建和绑定;
- 合并pp切分下的完整模型参数;
- 获取全部pp stage合并后的模型参数;
- Actor模型参数在CPU和NPU间的搬运等;
AllGatherPPModel首先使用Megatron 格式进行全量权重的初始化;然后对于当前 PP rank的权重,额外初始化优化器参数用于训练;最后每个 PP stage 的权重被整合放置在一个大的连续 Memory Buffer 中,从而加速 Host 与 Device 之间的权重搬运。
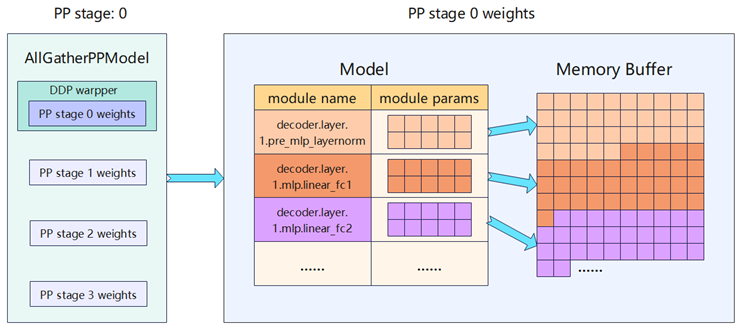 图:Memory Buffer的构建及Actor模型权重绑定
图:Memory Buffer的构建及Actor模型权重绑定
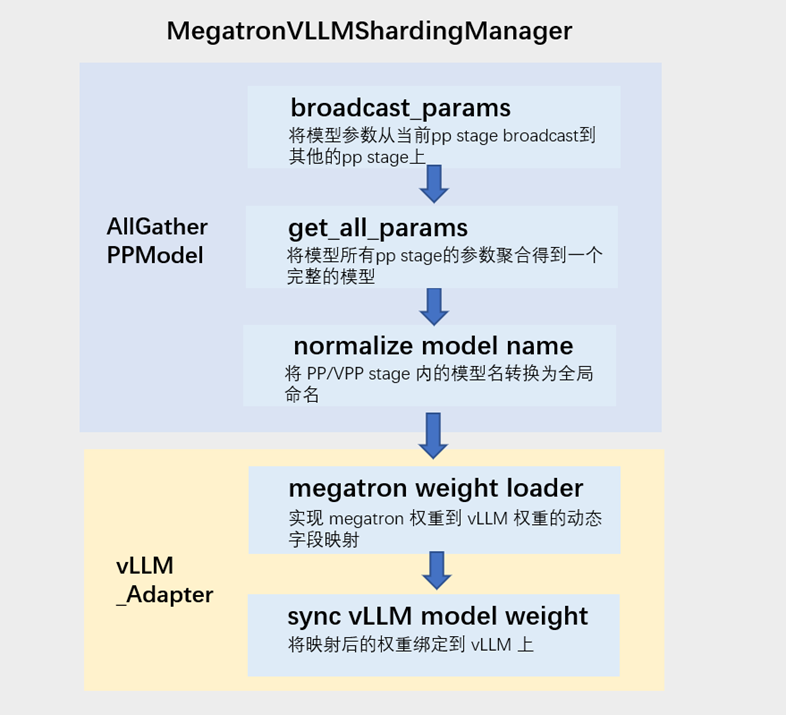
AllGatherPPModel为了实现训练PP和推理DP间的转换,权重管理模块需要支持以下几个功能点:
- 将每张卡对应pp stage训练后的模型权重同步到其他的卡上;
- 单卡上将收到的全部pp stage权重聚合得到一个完整的模型;
- 通过一个模型权重的名称转换函数,将局部pp stage里的参数名称转换为全局参数名称。
3)megatron分块权重动态管理模块
MegatronVLLMShardingManager模块,会调用AllGatherPPModel及vLLM,以实现actor权重的管理和使用。
3.PPO测试结果
RLHF的训练结果评价指标主要看reward,reward曲线可以用来评估模型输出与人类期望之间的对齐程度。
reward曲线在训练过程中很容易不稳定,出现掉坑、不上升、震荡等现象。对于这种问题,通常可以通过 3 个指标来辅助分析:KL、Response Length、Perplexity。
3.1 NPU与GPU结果对比
本次试验的设置前80步是warm up,只有critic模型放开训练,actor模型权重不更新。80步后Actor模型开始训练。从NPU与GPU的多次试验可以看出,actor开始训练之后reward曲线都有相同的上升趋势且震荡范围基本相同。
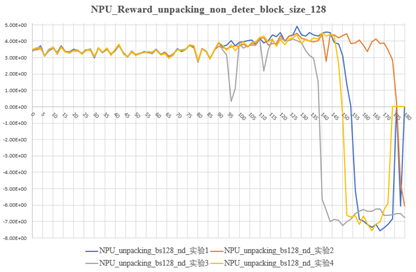
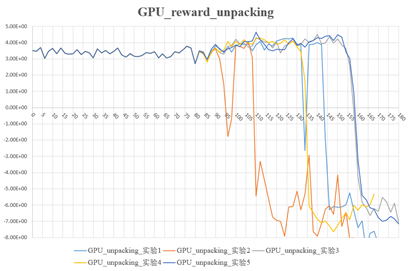
NPU与GPU在80到123步reward均值、最大值、最大值(去除掉坑的曲线)
3.2 NPU的PPO结果
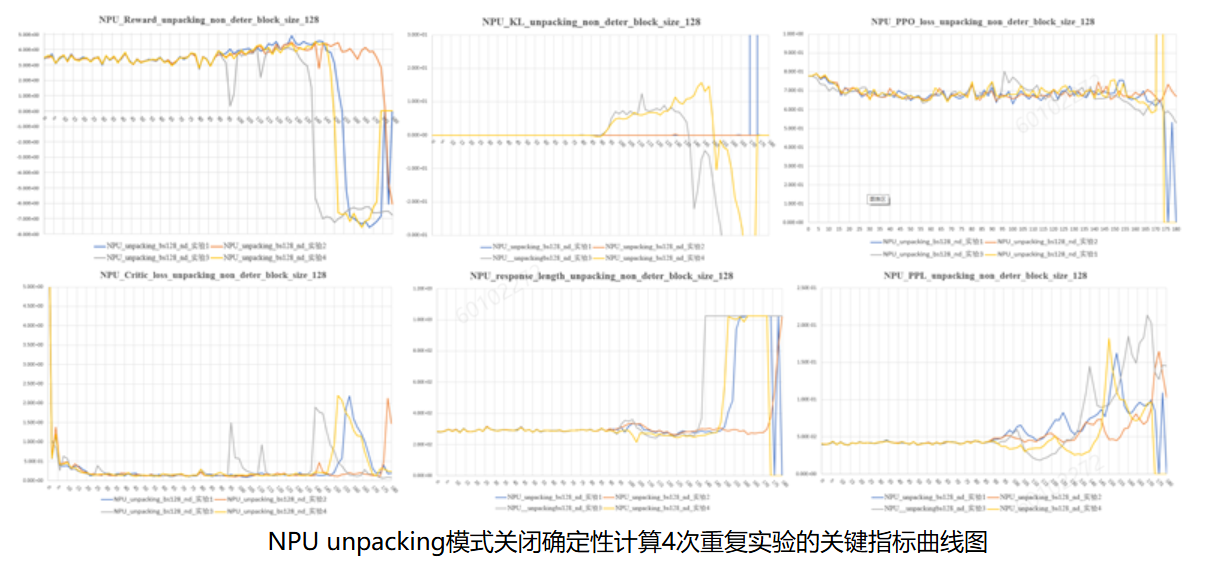
从上图可以总结出几种规律:
- Reward掉坑的时候会出现:KL散度增加;critic loss上升;response length和Perplexity激增;
- 多次实验(未开确定性)reward掉坑时刻有较大随机性;
3.3 GPU的PPO结果
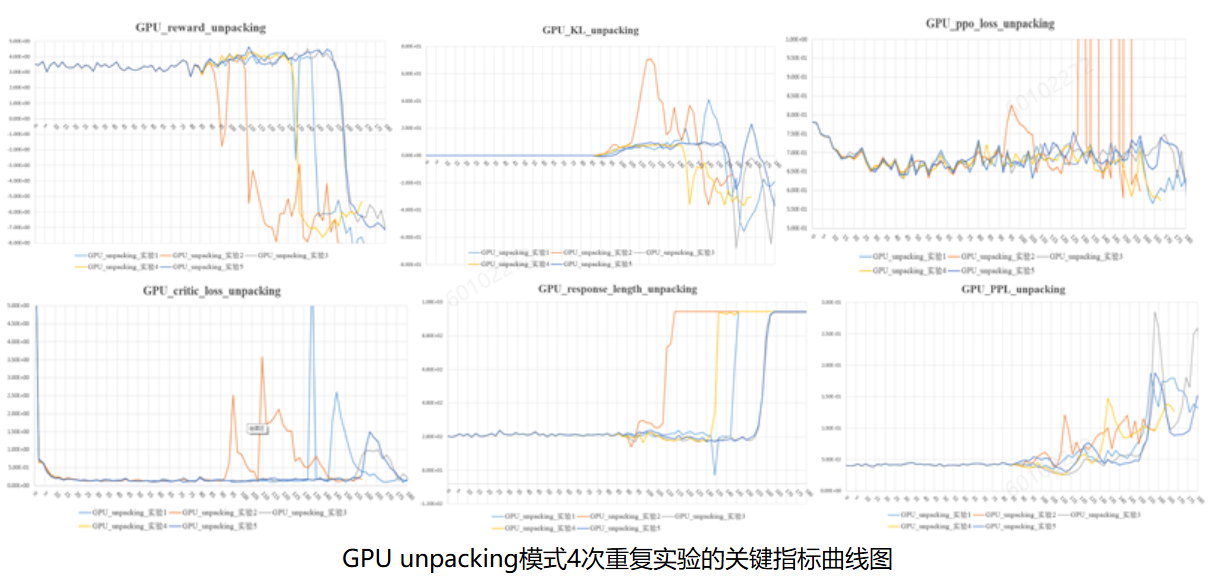
GPU与NPU的指标趋势,规律类似。
4.PPO精度问题总结
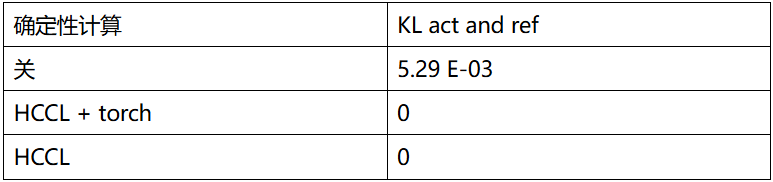
后训练相对于预训练/SFT,精度比对引入的增量部分在阶段一的生成和阶段二的推理。本章节提炼总结了PPO迁移和开发过程中遇到的一些问题,供后续在昇腾进行后训练精度比对时参考。 强化学习调试过程中,多次发现同样权重、同样prompt生成差异较大的情况。因此这里列出涉及到的所有确定性计算开关和关键的影响:
- HCCL确定性计算 export HCCL_DETERMINISTIC=True:HCCL确定性计算会影响megatron的训推精度无法固定;
- Torch确定性计算 torch.use_deterministic_algorithms(Trues):Torch确定性计算会影响megatron的训推精度无法固定;
- LCCL确定性计算 export LCCL_DETERMINISTIC=1:LCCL确定性计算会影响vLLM推理精度无法固定;
- 关闭MATMUL K轴偏移:export CLOSE_MATMUL_K_SHIFT=1:影响vllm推理精度无法固定;
4.1 阶段一:vllm生成
1)Alibi mask
现象: megatron调用vllm推理,和vllm单框架推理对比,相同prompt的生成结果不同。
定位过程: 挂hook发现第一次出现不一致的地方在fa。接着查看fa算子输入,发现alibi slopes不同。如下图所示,alibi slopes的 l1 norm 在不同框架下有0.2%的差异: 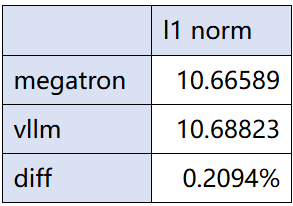
原因: megatron框架和vllm框架内,tensor创建的默认dtype不同,训练时默认float32,但是vllm框架下为bfloat16,因此在生成时会有细微差异。因此vllm框架内生成时需手动指定dtype为float32,再转为bfloat16储存。代码如下: 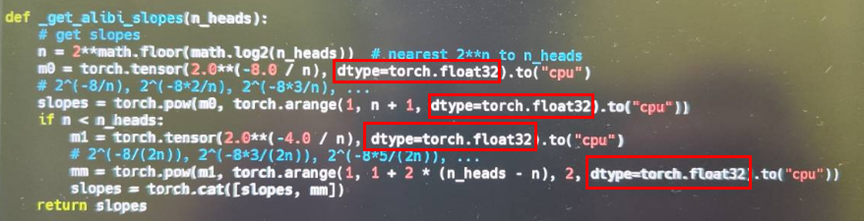
2)多batch精度问题
现象: 测试发现,同一个prompt在不同batch配置下,生成结果存在较大差异。下表给出了同一个prompt,在不同batch、不同kv block size、不同确定性开关配置下的生成结果差异。
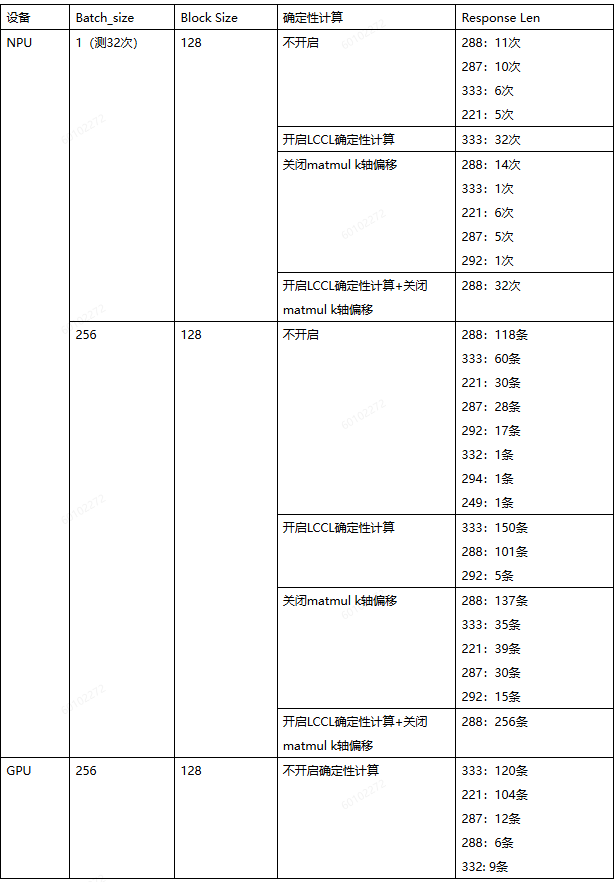
同一prompt不同生成结果示例: 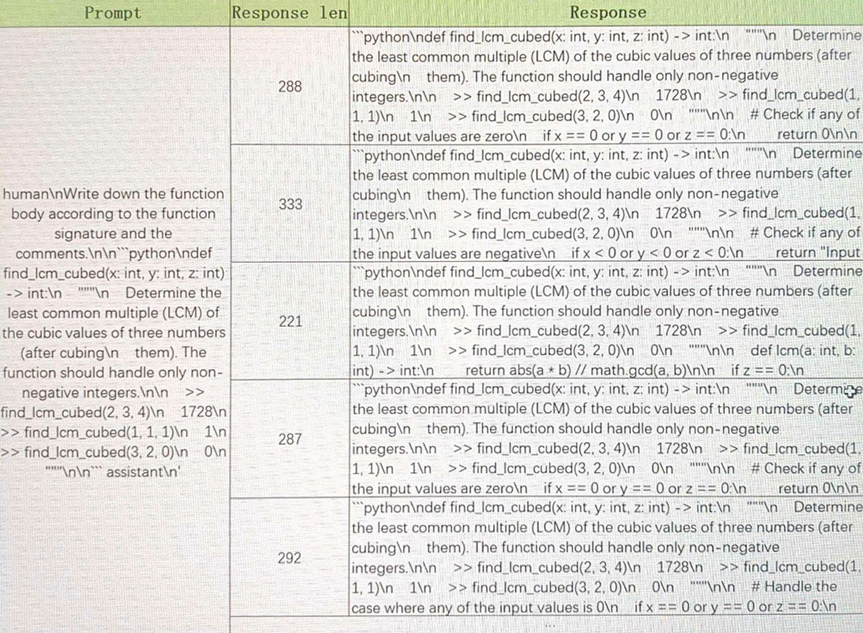 生成结果稳定性的规律总结:
生成结果稳定性的规律总结:
a) NPU生成:
- 开启LCCL确定性开关后,单batch生成结果可以固定住;
- 多batch生成结果固定住,需要同时打开LCCL确定性计算开关和关闭K轴偏移;
- K轴偏移开关对生成结果有影响;
- 同样prompt,在确定性计算打开时,单batch生成和多batch生成结果不一致;
b)GPU不开确定性计算,多batch输入同样存在不同行输出不一致的现象;
c)GPU和NPU生成结果比对,response len长度一样时,生成token完全一致;
3)不同FA算子对alibi位置编码的精度差异
现象:vllm推理生成精度比对过程中,发现GPU和NPU生成token对齐后,logp的L1norm和余弦相似度存在一定误差。经定位发现NPU本次vllm适配20B模型,接入的FA算子是torch npu PFA&IFA算子,对alibi位置编码未做过现场精度验证。本节对于两类FA算子,在alibi位置编码下的20B模型推理的精度差异做了测试验证。
实验数据:
-
整网token对齐情况:

bs256 全量推理, atb FA算子整网token对齐比例高于PFA&IFA算子。
-
生成token强制对齐后,观察NPU和GPU的logprob偏差

进行4个句子测试,以logprob为指标,计算NPU与GPU的相对L1距离和余弦相似度,结果证明PFA&IFA的误差要大于atb FA。后续在alibi位置编码的场景,推理还是推荐使用atb的FA算子。
4)lccl 确定性计算
为了验证确定性计算对生成精度的影响,在256batch场景做了如下实验:
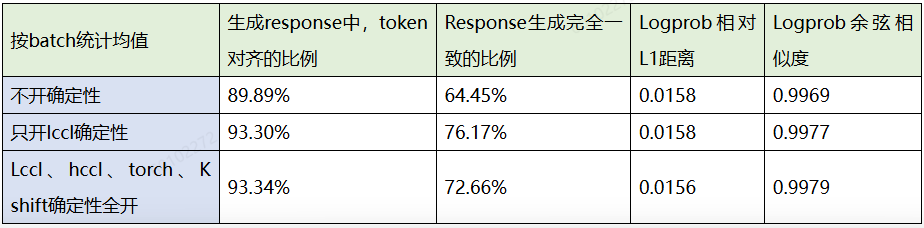
余弦相似度更加敏感一些。从测试结果可以看出,四个确定性计算开关中,对生成产生不稳定影响的主要是lccl确定性开关。
5)decoder的padding处理
现象:vllm测试256batch,部分句子出现乱码。
定位过程:测试单batch和多batch
- 测试四次,batch1,不同prompt,输出正常

- 测试batch4,每个batch prompt相同,输出正常

- 测试batch4,每个batch prompt长度不同,输出异常,怀疑变长padding处理问题
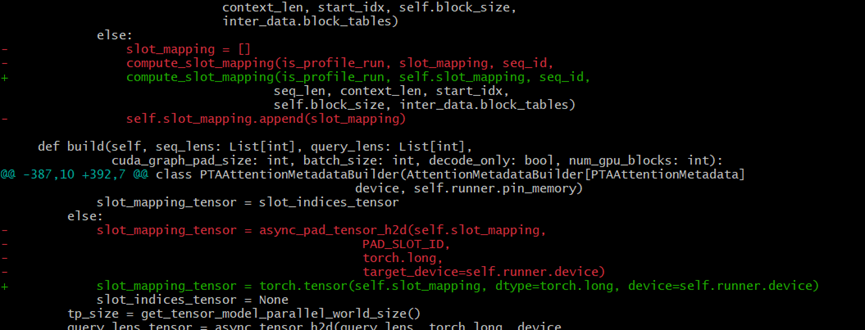
4个不同prompt组batch的case,第四条数据输出无逻辑且logprob偏差43454%。进一步dump数据发现prefill阶段输出正常,因此怀疑decode存在问题。通过走读代码定位到slot mapping (kv cache block的映射表) 的padding处理问题(下图要从红色部分改成绿色部分):
 修复后测试结果恢复正常:
修复后测试结果恢复正常:
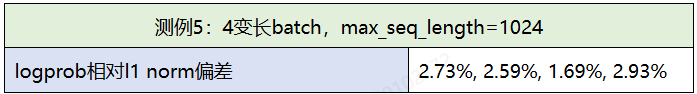
4.2 阶段二:megatron inference
1)Alibi mask
现象:比对GPU和NPU,megatron前向logits的l1norm发现存在4%的误差。

定位过程:
A. GPU和NPU逐层对比权重、输入、输出的l1 norm。定位到首次误差较大的位置在FA
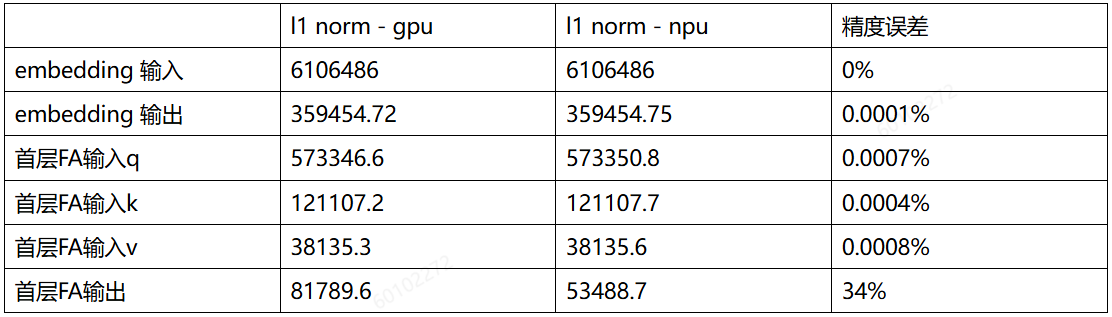
B. 正向检查代码发现alibi使用float32生成后未转回bf16,导致npu、gpu精度存在差异。修改后精度在0.19%

2)mc2确定性计算
现象:前80步warm up阶段,actor学习率配置为0,但测试发现NPU的act与ref的KL散度不为0,不符合预期。
定位过程:
A. 逐层比对act模型和ref模型权重、输入、输出的l1 norm。 定位到经过matmul-reduce_scatter后精度出现差异。 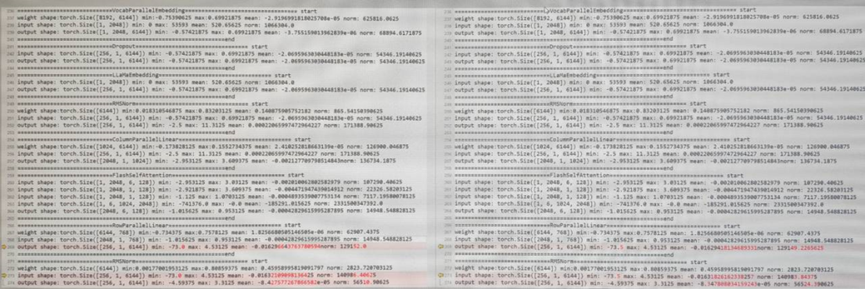
B.开启确定性计算后,actor和ref的KL变成0。 对比几个确定性计算开关,KL散度计算误差主要是由于HCCL确定性的影响。
3)critic value精度误差
现象:NPU和GPU对比,首步critic loss误差0.13%,value误差0.59%。随着长跑,critic loss误差越来越大。
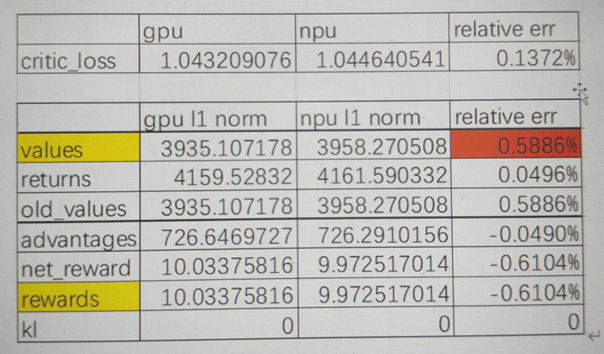
为了控制critic loss跟GPU的偏差放大程度,我们还是对首步的L1 norm误差放大情况做了深入分析。进一步拆解后发现critic模型增加的最后一层matmul输入误差万分位,输出误差千分位。
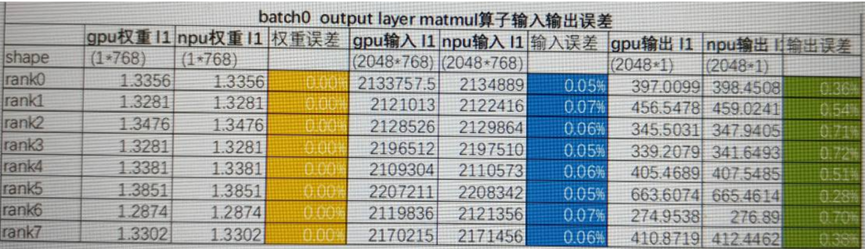
为了隔离是值域影响还是matmul算子的精度问题,我们做了如下两组实验。
A.实验一:交换输入,比较输出,排查是否存在算子精度问题 结果:使用相同输入下,比较gpu、npu、cpu的输出l1 norm误差为0%,无算子精度误差。
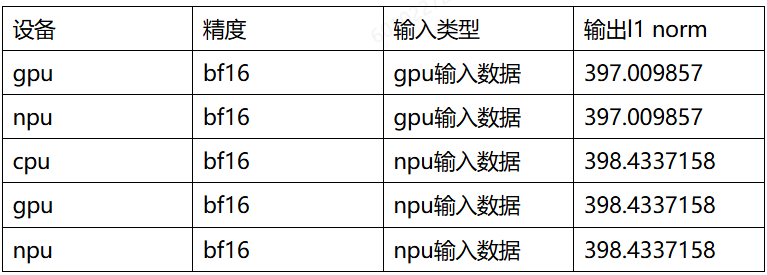
B.实验二:计算精度从bf16升到fp32,看输出误差是否会减小 结果:升精度后,fp32和bf16在同样输入下输出基本一致。非bf16导致的累积精度误差。
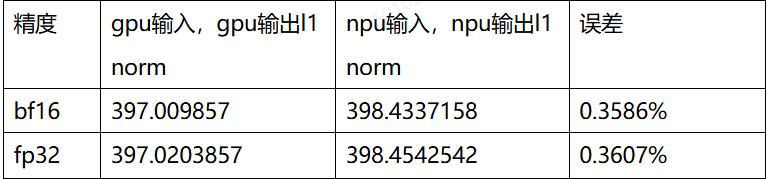
最终结论:matmul的计算在当前权重下,输出误差相对输入误差放大属于正常现象。
4.3 RLHF全流程
1)不同数据集的reward稳定性测试
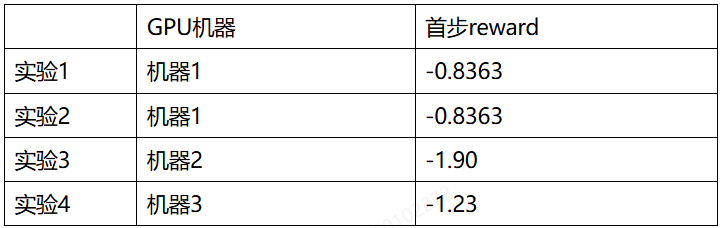
在本次迁移开始时,基于客户提供的数据集,reward在90-160步之间会概率性训崩,reward从4+跌落至-7左右,无法比较500步reward精度差异。因此客户提供了新的数据集。但基于新数据集,发现NPU无法复现GPU首步reward。跟客户沟通,客户自己测试也发现,不同GPU机器的首步reward差异较大:
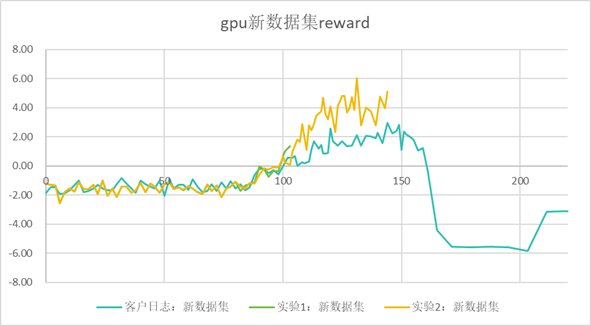
同一台GPU机器,不同长跑的reward曲线差异较大,也无法复现某企业提供的日志:
GPU上长跑出现了因为生成过短,触发提前结束的情况:

新数据集明显比旧数据集的RLHF训练更不稳定。为了提炼特征指标,表征数据生成的困惑度,从而进一步表征对reward曲线训练不稳定性的影响,我们设计了Ambiguity Count指标,用于表示整体response中模型觉得困惑的token个数,该指标的具体定义参考5.4节。
如下图,我们统计了不同数据集下,Ambiguity Count个数。在0-80时,actor未开始训练,新数据集的Ambiguity Count平均有292个,而旧数据集上为231个。而在80-130步,训练开始,新数据集上actor生成的困惑度明显上升,老数据集上反而有下降趋势。
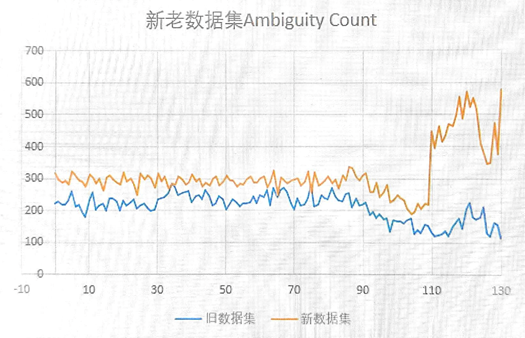
最终我们决定切回老数据集,做后续的精度验证工作。
2)数据配置对齐
在RLHF首步的精度比对过程中发现,需要保证GPU和NPU训练batch的每个prompt顺序完全对齐,才能进行中间过程输入和输出数据的对比分析。因此主要涉及到shuffle模式、DP数据分发及是否packing等配置的修改。
A. 固定数据shuffle模式 在模型的训练过程中,通常会在训练数据的读取和构造过程中进行随机的shuffle,因此首先需要确认Gpu和Npu上是否使用相同seed下的数据shuffle,保证每个batch输入的数据顺序一致。
B. DP域下的训练数据负载均衡排序 DP会对generation阶段生成的数据进行分发,由于不同prompt生成数据通常长短不一,直接分发可能会导致不同DP域上数据长度差异较大,影响训练效率。为了实现DP域负载均衡,可以对全部rollout数据按长度进行排序,然后均匀地分发给不同的DP域。
在进行NPU与GPU的首步actor训练前向对比时,由于生成阶段的不确定性,可能导致每个batch的数据及顺序在DP域负载均衡排序后无法对齐,因此需要关闭排序功能。
C.packing模式 packing模式将多个训练样本合并成一个样本,以提高训练效率。RLHF在数据生成完成后,对prompt和response拼接的数据进行packing。由于生成长度的不同,每个batch内可以packing的句子数量是动态变化的。需要注意packing模式是否带有drop操作:当packing后的batch数量不是设定好的训练gbs的整数倍时,会向下取整,并drop掉多余的样本。最终我们采用unpacking的模式进行精度对比验证。
3)推理容器vllm版本
现象: Unpacking模式、开启确定性计算下,gpu与npu首步ppo loss对不齐:
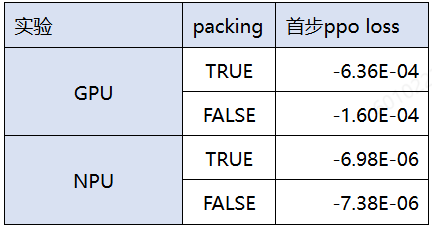
如图,GPU值域在E-04数据量级,而NPU值域在E-06值域范围。排查下来发现,NPU容器内安装的vllm版本有问题,用的还是PFA/IFA算子推理。
4)Kv block size配置影响
vllm框架使用不同blocksize(分别是16和128)的reward曲线如下图所示: 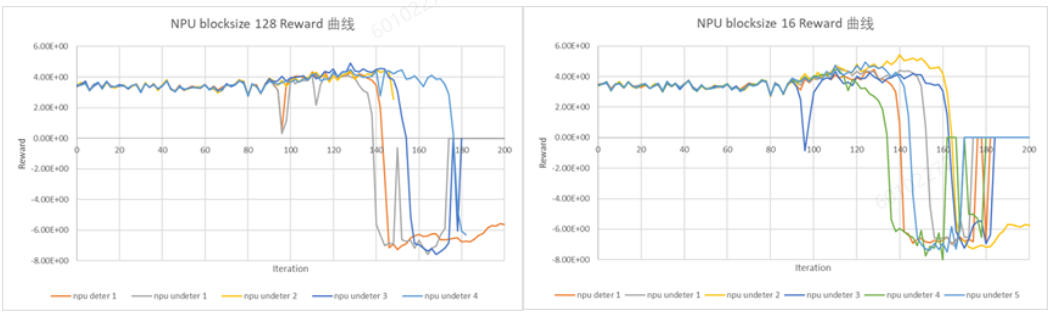
整体来看,blocksize128下的reward曲线更稳定,波动范围更小。 第一步reward差异约3.3%:
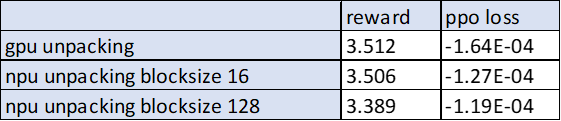
对不同blocksize配置下,reward误差的进一步打开分析: A. dump 句子粒度reward数据,并找到reward打分差异较大的句子: 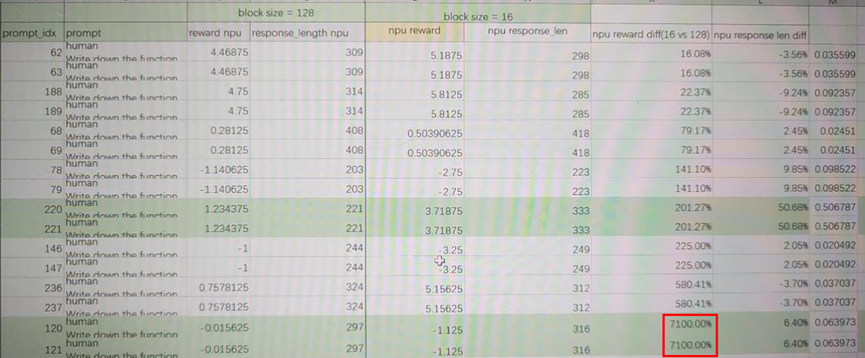
如图,在block size128和16下,prompt idx120,reward差异为7100%
B. 使用该prompt进行单独的generation实验并观察输出结果:
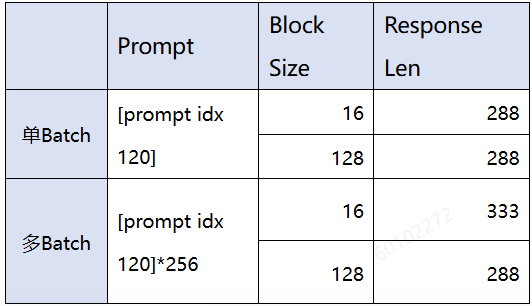
可以发现单batch下blocksize16和blocksize128的输出一致。多batch时,blocksize16和blocksize128 的输出有较大差异,长度分别为333和288。
由于blocksize仅与kv cache和page attention算子相关,因此怀疑kv cache处理部分或page attention算子精度问题,下一步进行dump数据分析。
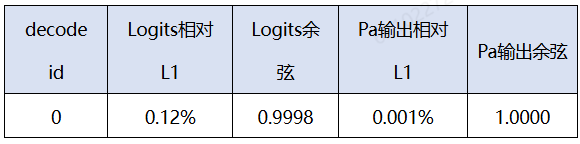
C.多batch,不同blocksize下,decode阶段,dump pa的输入输出和logits并分析: 比较不同block size下第一个decoder的logits、Pa输出,不管是相对L1距离还是余弦相似度都符合精度标准。
对prompt idx 120,找到decoder生成的分叉点第154个token,dump数据进行分析: 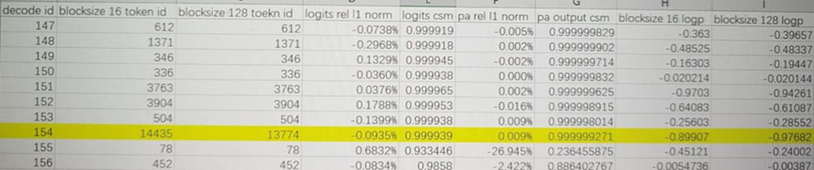
如图,不同block size配置下,response分叉的token位置在第154个decoder。虽然两组配置最终选择了不同的token生成,但logits的l1相对误差为0.0935%, 余弦相似度0.9999,首层pa输出的l1相对误差0.009%, 余弦相似>0.9999,精度符合预期。两组生成的logp值为-0.89907, -0.97682,对应的概率值大约在0.37。因此微小的累积计算误差可能在模型困惑度较高时,导致token选取发生差异。
5)确定性计算
- 确定性对精度的影响: 计算对性能和精度的影响需要进一步评估。
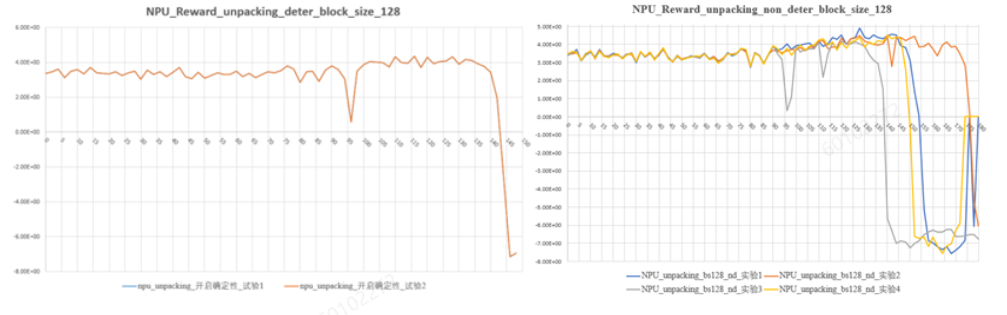
确定性计算,多次长跑reward曲线完全一致;非确定性计算,每次长跑,reward曲线在过了warmup阶段后波动较大。总体来看,确定性计算的reward曲线,处于非确定性计算的4条reward曲线值域空间内。
- 确定性对reward打分的影响:对前100步的6400个prompt,每个prompt生成2次,计算相同prompt两次生成后reward打分相同的比例:
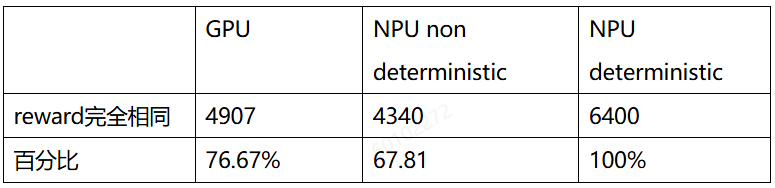
NPU确定性计算打开后,两次生成的结果打分一致性达到了100%;不开确定性,GPU和NPU的生成结果差异基本都在70%左右。
- 确定性对耗时的影响(gbs:128)
开启四个确定性计算开关后,端到端性能劣化约5.6%。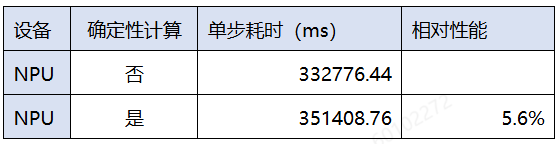
第五章内容详见:RLHF-PPO 昇腾训推共卡方案案例总结(下)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









