



摘要
当前,千卡万卡大规模集群大模型训练逐步在各局点上线,随之而来的是,各局点,尤其是使用华为全家桶的局点,在大规模集群训练过程中逐渐出现了集群性能下降,性能抖动等问题。但是,传统的基于小模型和小规模集群(8卡或几十卡规模)的调试和性能问题解决方法无法满足大规模集群性能问题解决的需要,比如大规模集群的性能问题可能出现在计算,网络,存储等产品的软件或硬件任何一方,而传统的单机单卡或小规模集群性能问题往往主要聚焦于计算,尤其是算子优化等,因此双方的分析优化的侧重点不同;同时传统的profiling方式,经常需要停止正常训练业务才能采集分析,也无法满足希望不停止正常训练业务还能进行集群性能问题解决和优化分析的需要,因此有必要重新整理,积累和完善大规模训练集群性能问题调试和优化的方案,方法,工具和案例。 本文的目的就是试图为大规模训练集群性能问题调试和优化积累方案,方法,工具和案例。为各局点解决大规模集群性能问题的解决和优化提供参考。
1.1 背景与简介
当前,千卡万卡大规模集群大模型训练逐步在各局点上线,随之而来的是,各局点,尤其是使用华为全家桶的局点,在大规模集群训练过程中逐渐出现了集群性能下降,性能抖动等问题。但是,传统的基于小模型和小规模集群(8卡或几十卡规模)的调试和性能问题解决方法无法满足大规模集群性能问题解决的需要,比如大规模集群的性能问题可能出现在计算,网络,存储等产品的软件或硬件任何一方,而传统的单机单卡或小规模集群性能问题往往主要聚焦于计算,尤其是算子优化等,因此双方的分析优化的侧重点不同;同时传统的profiling方式,经常需要停止正常训练业务才能采集分析,也无法满足希望不停止正常训练业务还能进行集群性能问题解决和优化分析的需要,因此有必要重新整理,积累和完善大规模训练集群性能问题调试和优化的方案,方法,工具和案例。
本文的目的就是试图为大规模训练集群性能问题调试和优化积累方案,方法,工具和案例。为各局点大规模集群性能问题的解决和优化提供参考。
本文第二章分享了某局点8千卡/万卡训练集群性能下降和抖动的案例,第三章在这些案例基础上提炼了大规模训练集群性能问题解决方案,第四章总结了当前的不足和下一步展望。
1.2 大规模训练集群性能问题分享
通过近5个月的某局点2千卡,4千卡,8千卡,1.8万卡大模型接续训练过程统计,平均每个月有2.4起性能下降或抖动问题。本章我们选取近期出现的两起性能问题进行分享。
1.2.1 某万卡集群性能下降问题分享
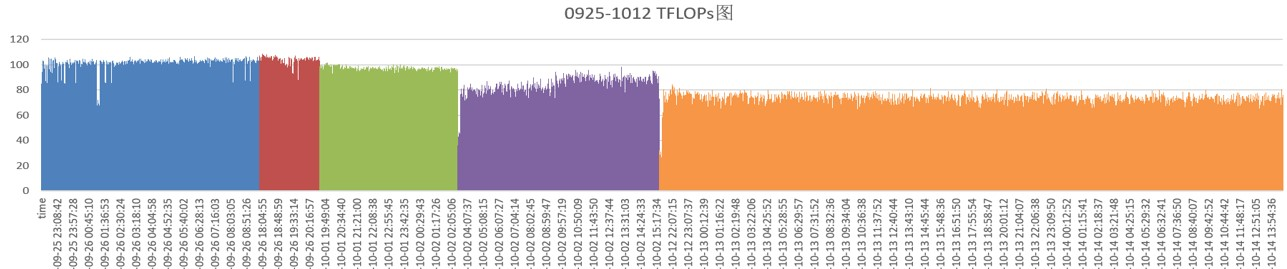
上图是某局点1.8万卡训练集群在9月25号到10月12号之间的性能变化图,图中每个颜色区域代表一次训练拉起到训练故障结束。从图中可以看到,整个集群的性能从100+TFLOPS在逐步下降并趋于稳定在60+TFLOPS(紫色块从性能从低到高,一般是由于刚拉起时性能不稳定,相对较低,之后逐步趋于稳定)。
万卡集群性能下降的根因可能出现在算存网等产品的软件或硬件任何一方,复杂度高,另外客户已经感知到该问题,可能会上升,压力山大,因此需要快速解决。面对该问题,驻场特战队基本采取两种方法来应对,1是看怎么能将集群性能优化上去,2是排查下降原因;
性能优化相关分析
首先我们先对集群分时段多轮采集动态profiling数据进行对比分析。动态profiling的原理如下:
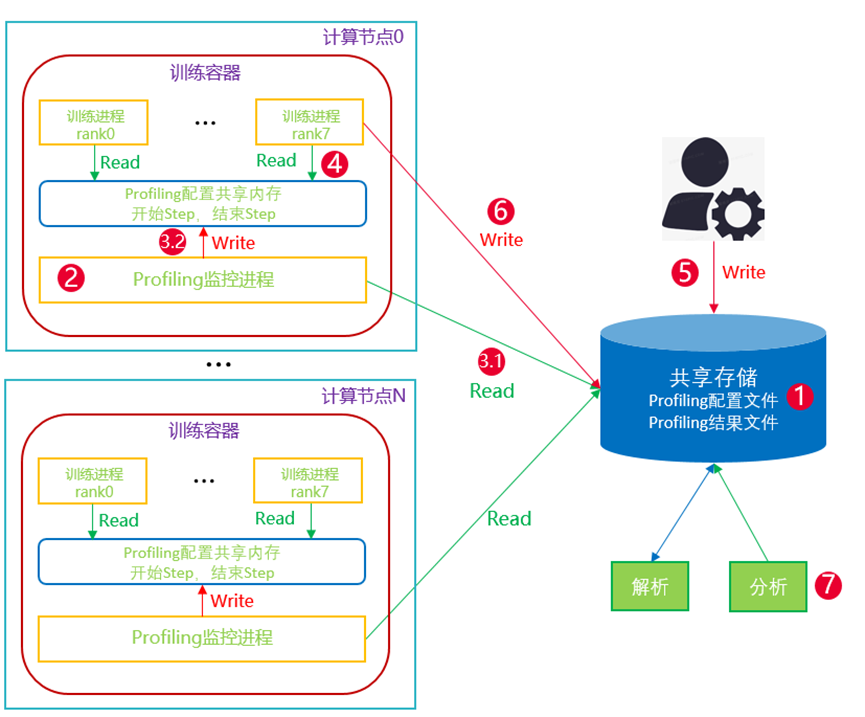
动态Profiling流程:
- 首先在共享存储中存储动态profiling配置文件:主要包含开始结束profiling的step,比如第500步开始,501步结束;
- 训练任务容器启动后,启动8个训练进程,其中1个训练进程会启动一个Profiling监控进程,并创建共享内存;
- Profiling监控进程会定期从共享存储中读取profiling配置信息并将其写入共享内存;
- 8个训练进程在单步训练结束后会从共享内存中读取profiling配置信息,并判断下个Step是否需要开启profiling,如果需要则开启,如果不需要则跳过;
- (动态)当需要profiling时,人工修改共享存储中的Profiling配置文件,比如第600步开始profiling,601步停止;
- Profiling监控进程将新的配置信息读入共享内存,各训练进程同步最新配置信息后判断开始profiling,并将profiling结果写入共享存储;
- 解析共享内存中profiling结果并汇总分析;
下面是在时间点T1,集群性能35TFLOPS时采集的动态profiling数据结果:
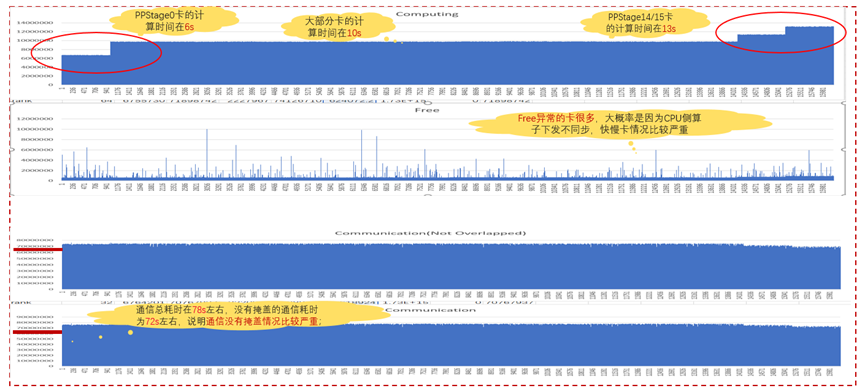
从图中可以看到:
- PPStage0的耗时在6s,PPStage14/15的在13s,PPStage负载不均衡,需要优化;
- 大部分卡的计算耗时在10s,通信耗时在78s,通算比为7.8:1,通算比太高,通信耗时太高是性能低的主要原因,因此优化的重点是通信耗时,但通信耗时包含通信同步耗时和通信实际耗时,具体是哪里耗时,还需要进一步分析。
- Free异常的卡很多,大概率是因为CPU侧算子下发不同步,导致的快慢卡情况比较严重;
- 通信总耗时在78s左右,没有掩盖的通信耗时为72s左右,说明通信没有掩盖情况比较严重,通信掩盖是另一个主要优化方向;
下面是在时间点T2,集群性能78TFLOPS时采集的动态profiling数据结果: 
从图中可以看到:
- 大部分卡的计算时间在10s,PPStage0和PPStage14/15负载不均衡,与T1时刻数据基本相同;
- Free异常的卡对比T1时刻减少,大概率还是因为CPU侧算子下发不同步,快慢卡情况相对好转;
- 通信总耗时在50s左右,没有掩盖的通信耗时为45s左右,说明通信没有掩盖情况仍然比较严重;
- 对比T1时刻数据,通信时长从78s降低到50s,通信时长包含通信同步耗时(Notify/Wait)和通信实际耗时(Send/Receive),网络通过排查没有太大区别,因此大概率还是快慢卡同步耗时过大的问题;
为了进一步验证是否是卡间不同步导致通信同步耗时,我们随机抽查了几张卡的TimeLine数据,如下: 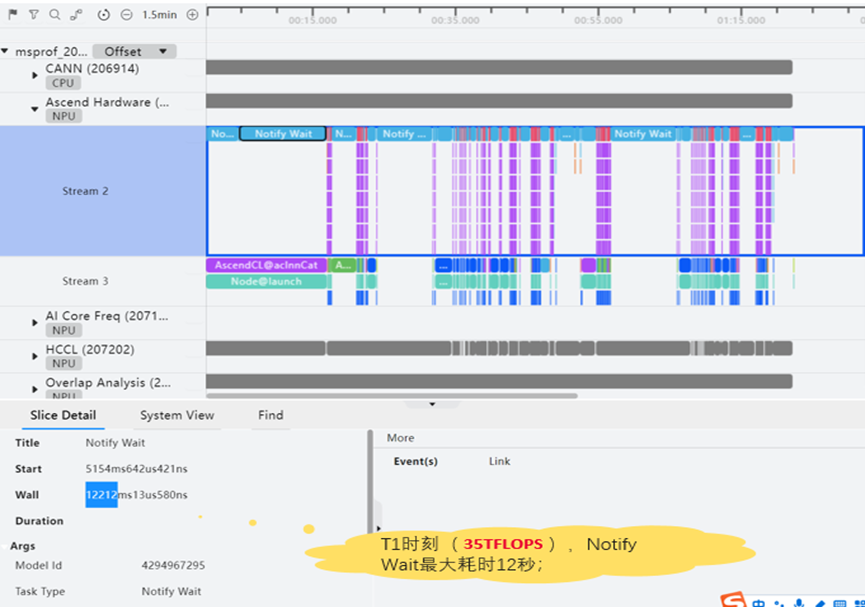
从图中可以看到,Notify Wait的耗时相当严重,对其中最大的Notify Wait来分析,发现其耗时达到了12s。结合T1和T2两个时刻的profiling数据对比分析,我们认为:
1.卡间不同步导致的通信同步耗时是性能低的主要原因。
2.PP Stage负载不均衡是性能低的另一个原因。
因此,我们主要从这两个方面开始优化:
- 卡间不同步优化:
通过以往案列和经验分析,通信同步耗时的根因是卡间不同步,而卡间不同步的根因往往又是CPU侧算子下发不同步,CPU侧算子下发不同步的根因又往往是CPU侧外界不同步或内部不同步导致;1)CPU侧外界不同步往往是CPU侧等待存储访问,比如写日志耗时差异导致的不同步等,或是其他进程比如监控进程的干扰等导致的不同步,需要IOWait和CPU利用率来判断;2) CPU侧内部不同步又往往是CPU侧执行了不同步的操作,比如垃圾回收触发时机和耗时不同导致的不同步等;
我们分别做了垃圾回收处理优化,但性能没有明显的提升,说明垃圾回收不同步不是本次卡间不同步的主要原因;那么剩下主要开始排查存储访问相关的不同步。正好在解决该问题期间,特战队在另一个8千卡集群上小模型的性能优化实验中发现,MindSpore对读取训练数据的优化(即减少不必要的数据读取),可以提高集群性能,因此将该优化应用到了本集群中。
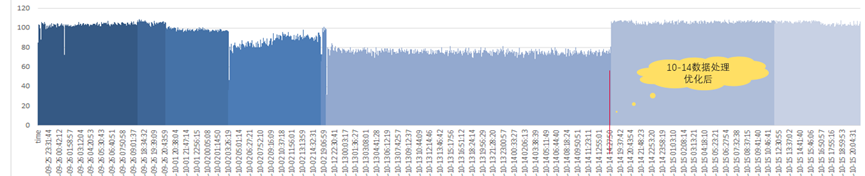
上图是数据处理优化上线后,性能对比图。从图中可以看到,通过数据处理优化后,集群性能从60+TFLOPs回升到了100+TFLOPs,已经达到性能下降前水平。
为了进一步验证卡间不同步情况,我们在数据处理优化后再次采集动态profiling,对比分析如下图:

对比T1、T2时刻数据,可以发现:
1.对比T1和T2时刻数据,通信耗时从78s-》50s-》20s,通信耗时包含通信同步耗时和通信实际耗时,网络通过排查没有太大区别,因此可以肯定CPU侧存储访问不同步导致的卡间不同步是性能差的根因;
2.Free异常的卡对比之前大量减少,CPU侧算子下发不同步情况好转,好转原因是CPU侧数据处理优化,大量减轻CPU负载;
3.大部分卡的计算时间在10s,PPStage0和PPStage14/15负载不均衡,与T1和T2数据基本相同;
4.通信总耗时在20s左右,没有掩盖的通信耗时为18s左右,说明通信没有掩盖情况比较严重;
为了进一步验证卡间同步情况,我们随机挑选了几张卡TimeLiness数据进行对比分析,如下:
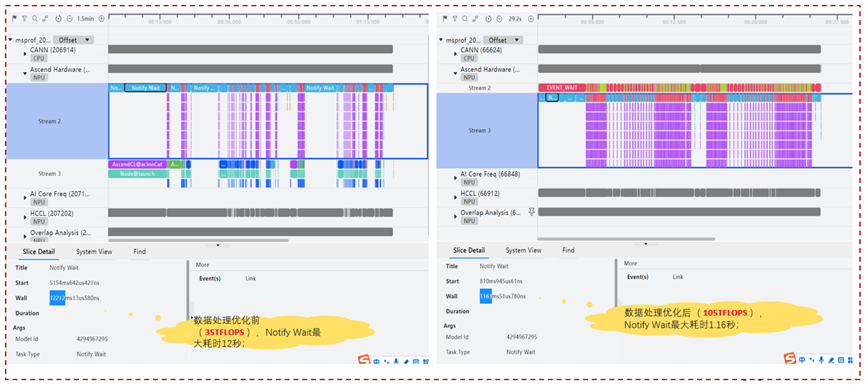
发现数据处理优化后,最大的Notify Wait耗时已经从之前的12秒下降到了1.16秒,进一步验证了CPU侧存储访问不同步导致的卡间不同步是性能差的根因。
为了进一步排查存储访问可能带来的卡间不同步问题,特战队排查了训练代码,并对多个场景下的数据进行了分析,发现:

- 存储的读写相互影响:上图左1下是除去写CKPT的步骤的TFLOPS图;左1上是单独抽取出所有写CKPT的步骤的TFLOPS图;从图中可以看出:集群层面存储读和写相互影响,减少存储读,会提高写CKPT的性能(原因可能是CPU侧利用率的变化,也可能是存储集群本身);
- 判断路径是否存在导致卡间不同步:数据处理优化后,卡间不同步被优化,但依然存在;因此对MindSpore的单步执行代码打开分析,发现step_end中的“_make_directory”函数各卡耗时在0.6~5.5秒之间;“_make_directory”的目的是判断远程存储上CKPT的路径是否存在,如果不存在则创建,判断该路径是否存在会访问远程存储,而1.6万卡的并发访问导致各卡该函数执行时长差距很大,是卡间不同步的一个主要原因;结论:尽量减少远程存储的直接访问,多卡高并发下对远程存储的访问会导致卡间不同步加剧;
- Profiling写本地解决性能膨胀问题:Profiling 在采集时会一边记录数据一边写远程存储。写远程共享存储导致写时延增大,进一步导致了性能膨胀和数据失真问题;使用 level 0 采集和先让 Profiling 数据保存在本地,然后再让每个节点将本地数据搬运到远程共享存储可以有效减小性能膨胀。
- 日志写本地提升性能:某局点日志写远程存储,MindSpore拉起实验耗时90分钟;改为日志写本地磁盘后,拉起实验耗时降低到57分钟;
结论:尽量减少远程存储的直接访问,尽量先本地再转储至远程存储,多卡高并发下对远程存储的任何直接访问都可能会导致卡间不同步加剧;
同时,我们对PPStage负载均衡也进行了优化,最终所有优化加持后,性能总图如下:
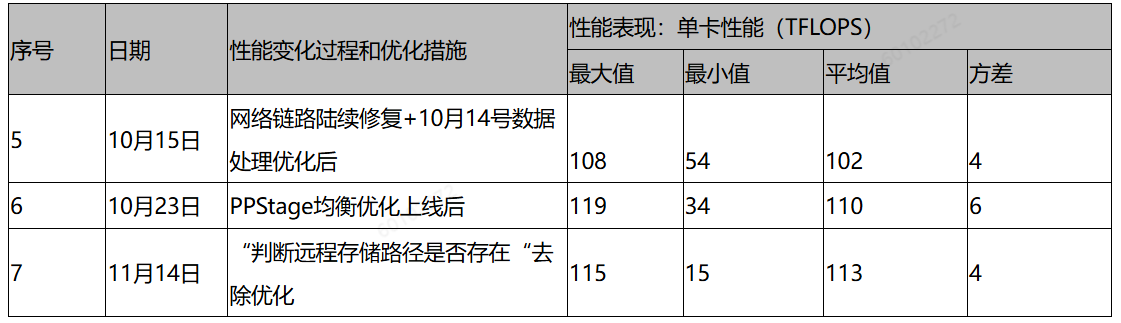
性能下降相关排查
其次我们对集群性能下降也进行了排查。
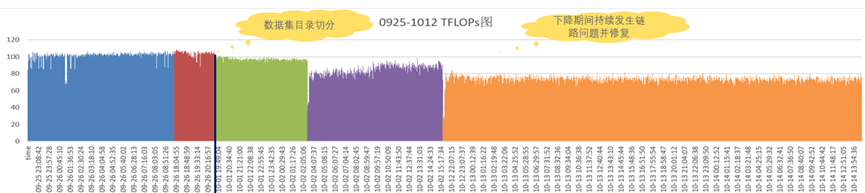

上图是相关排查结果,9月28号,解决性能抖动问题,性能最终稳定在101TFLOPS左右,9月29号数据集目录切分后,性能开始下降,下降到94TFLOPS左右,之后10月2号~14号期间:1)隔离了29台端口闪断或硬件故障计算节点;2)链路问题累积48起(脏污链路:20条,故障链路:28条);截止14号修复37条;截止17号修复8条,18号还有剩余3条未修复;
整个集群经过排查,除了上述2个变更外,没有其他变更,因此结合以往经验分析,性能下降的根因初步怀疑是数据集目录切分和网络链路问题。但由于客户训练任务不能被中断或影响,又加上通过上面优化手段后集群性能已经达到110+TFLOPS以上,已经达到了客户预期,因此当我们提出回退消融实验验证数据集目录切分是否是根因实验和链路根因实验后,客户不同意停止训练做实验,因此无法定位更具体根因;
1.2.2 某万卡集群性能抖动问题分享
某局点1.8万卡集群交付后,客户的千亿大模型基于该万卡集群首次上线,上线初期单卡平均性能在10~107TFLOPS之间剧烈抖动。
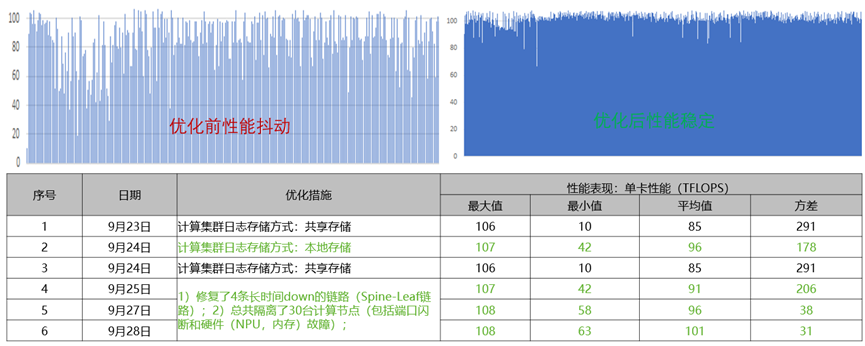
万卡集群性能抖动的根因可能出现在算存网等产品的软件或硬件任何一方,复杂度高,客户比较关注该问题,并且以此可能会怀疑华为万卡集群的能力,因此现场压力很大,需要快速解决。面对该问题,驻场特战队按照以往经验,仍然采取两种方法来应对,1是看怎么能将集群性能优化上去,2是排查下降原因;
首先简单通过日志存本地存储,即日志先写计算节点本地磁盘,再转储到远程存储,通过该优化,发现平均性能从85TFLOPS提升到96TFLOPS,但抖动方差从291下降到178,但抖动仍然很剧烈。
其次通过CCAE告警发现,有4条长时间down的Spine-Leaf的链路,同时有大量的端口闪断和硬件告警。因此主要思路转换到解决这些链路和硬件问题上。从9月25号到9月28号期间,1)修复了4条长时间down的链路(Spine-Leaf链路);2)总共隔离了30台计算节点(包括端口闪断和硬件(NPU,内存)故障);之后发现集群性能均值提升到100+TFLOPS,另外方差降低到了31,抖动幅度降低到正常水平,解决了性能抖动问题,达到了客户预期。
1.3 大规模训练集群性能问题解决方案
1.3.1 大规模训练集群性能问题特点与挑战
通过对多个局点多起训练集群性能问题的梳理和分析,我们发现大规模训练集群性能问题的特点和挑战如下:
- 大规模集群性能问题涉及面广,定位难度高:当大规模集群性能异常时(抖动或下降),涉及面广,很难定位问题根因(根因可能出现在配置变更,计算,网络,存储的软硬件任何地方);
- 大规模集群性能问题持续发生:某局点第一次性能下降慢卡排除恢复一周后,性能再次下降,两次下降原因不同;性能问题持续发生,平均每月2.4起集群性能问题;
- 当前的profiling工具不完善,还不足以支撑解决所有集群性能问题:当前的profiling工具沿用之前的小模型profiling工具,在集群层面统计的可用数据太少(只有计算,通信和Free)不足以支持定位所有问题,只能指出方向;
- 缺乏算存网统一分析工具:另外大规模集群的性能问题根因往往不在NPU,而在存储,网络,和CPU侧进程干扰,目前没有算存网统一分析工具,同时这些也是当前profiling工具覆盖较少或无法覆盖的部分;
- 部分性能定位或调试经常需要停止正常训练业务:性能定位实验或调试部分需要中断客户正常训练任务,影响范围和时长较大,配合意愿低。
1.3.2 大规模训练集群常见性能问题根因分析
通过对所有训练性能问题的梳理,我们发现,要想彻底解决集群性能问题,必须先从大规模训练集群中算存网之间的训练流程和原理进行梳理,才能彻底分析清楚各个性能问题的根因。
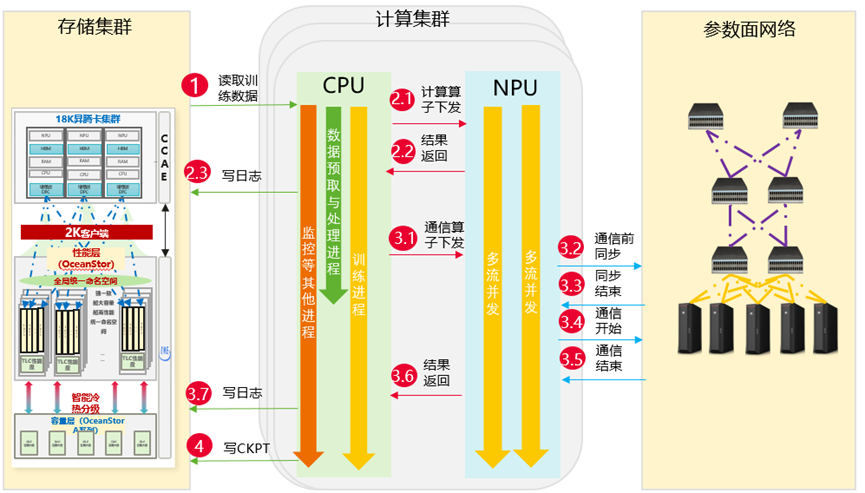
上图是训练集群算存网之间的主要训练流程(为了突出性能根因简化描述):
-
CPU侧读取训练数据:当前MindSpore是每2步异步读取下一个2步所需要的训练数据,经过数据处理后,搬移到NPU侧;
-
CPU侧计算算子下发:按单算子方式开始下发计算算子(为了简化描述,先将计算与通信算子分开讨论)
-
NPU侧执行计算算子:NPU侧多流并发执行计算算子,并返回执行结果;
-
CPU侧获取执行结果后写日志:为了简化描述,先假设算子执行后写日志,真实写日志时间依赖于具体的算子实现。
-
CPU侧下发通信算子;
-
NPU侧执行通信算子:
i. NPU侧执行通信同步操作:执行Notify Wait等同步所有卡;
ii. NPU侧执行通信实际操作:执行Send、Receive等操作;
7.CPU侧获取执行结果后写日志
8.固定步数后CPU侧写CKPT;
结合上述训练流程,通过梳理已知所有性能问题,我们总结了下面的已知常见集群性能问题根因:
存储侧:
① 读取训练数据:训练数据并发读取,影响训练进程的因素有2个:1)读取了不必要的数据,同时执行了不必要的数据处理,导致CPU侧与训练进程资源竞争,导致CPU侧算子下发不同步,持续发生则导致性能下降,忽快忽慢则导致性能抖动;2)读取加数据预处理总时长超过单步正反向计算总时长,导致训练进程等待数据处理进程,导致CPU侧算子下发延迟,性能下降,如果忽快忽慢,则导致性能抖动;此种情况,在训练小模型时更容易发生,因为小模型单步耗时绝对值比大模型小很多。
② 写日志:各卡写日志到远程存储的时延不一致,导致CPU侧算子下发不一致,各卡NPU侧通信同步耗时增大;如果写日志时延忽快忽慢则会导致抖动;
③ 写CKPT:默认客户承认其对性能的影响,但其优化方向为降低异步CKPT写对CPU侧资源的消耗,减少对训练进程的资源竞争影响;
④ 其他存储访问:比如判断远程存储路径是否存在等远程存储访问会导致卡间不同步加剧;
⑤ 目前实际案例表明,1.6万卡级别,各卡判断远程存储路径是否存在的耗时在0.6~5.5秒之间,其说明在大规模集群环境下,对存储集群的任何直接访问都可能导致访问时延差异大,进而导致各卡不同步加剧,因此优化方向为尽量减少远程存储的直接访问,直接访问改间接访问(即先本地再远程,多级存储)是比较好的优化方向;
CPU侧:
① 存储:卡间远程存储访问时延不同导致的卡间不同步;
② 监控等其他进程:监控等其他进程出现问题或采集频率很高时会抢占训练进程CPU,H2D/D2H带宽等资源,导致训练进程算子下发抖动或性能下降;
③ 其他不同步操作:卡间垃圾回收时机不一致,耗时不一致导致的卡间不同步等
NPU侧:
① 常见NPU出现亚健康状态,导致计算慢卡;
② 通信在网络正常情况下,卡间同步耗时异常;其原因往往是CPU侧问题,导致算子下发不同步;
③ Free异常其原因往往也是CPU侧问题,导致算子下发不同步,NPU卡空等增加;
网络侧:
① 不同类型端口闪断和链路故障导致实际通信时延不同程度增大,对训练影响程度不同;持续影响则导致性能下降,不定时影响则导致抖动等;
配置变更:
① 数据集/算存网超参/软硬件变化(升级,替换)等可能导致性能问题;经验告诉我们必须记录大集群的任何变更,否则某些性能下降或抖动问题无法快速定位。
1.3.3 大规模训练集群性能问题解决流程
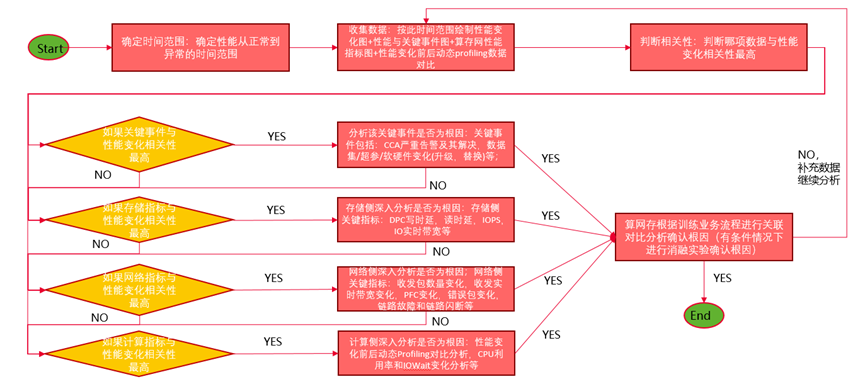
根据上面根因分析,以及通过对已知所有训练性能问题及其解决案例的梳理,我们整理了下面这张大规模训练集群性能问题解决流程图。
解决流程说明:
-
确定时间范围:确定性能从正常到异常的时间范围。只有确定变化范围,根据变化前后数据对比分析才能搞清楚性能问题的根因;
-
收集数据:按此时间范围绘制性能变化图+性能与关键事件图+算存网性能指标变化图+性能变化前后动态profiling数据对比分析;
-
判断相关性:判断哪项数据与性能变化相关性最高;
i. 如果关键事件与性能变化相关性最高:则需要分析该关键事件是否为根因。关键事件包括:CCA严重告警及其解决,数据集/超参/软硬件变化(升级,替换)等;某局点二级ITR案例中,前后对比最终发现更换不同远程存储导致性能抖动,最终查出导致性能抖动的原因为小IO聚合参数配置问题。
ii. 如果存储指标与性能变化相关性最高:则需要存储侧深入分析是否为根因。存储侧关键指标包括:DPC写时延,读时延,IOPS,IO实时带宽等;目前发现有多起案例与存储DPC写时延异常相关;
iii. 如果网络指标与性能变化相关性最高:则需要网络侧深入分析是否为根因。网络侧关键指标包括:收发包数量变化,收发实时带宽变化,PFC变化,错误包变化,链路故障和端口闪断等;目前已经明确计算侧的端口闪断是性能抖动的一个根因;
-
最后算网存根据训练业务流程进行关联对比分析确认根因,如果有条件情况下可以进行消融实验进一步确认根因;
-
如果根因已确定,则结束,如果未确定,则需要跳转到步骤2,继续收集数据,继续分析;
当然现场解决集群性能问题的流程中也伴随着集群性能优化,通过性能优化和性能根因查找解决两种方式来快速解决现场问题。集群性能优化与集群性能根因查找解决还是有不少不同的地方,作者将在另一篇文章中详细说明大规模集群性能优化的解决方案。
1.3.4 典型案例举例
我们通过下面两个典型案例来说明上面大规模训练集群性能问题解决流程。
1.3.4.1 典型案例1:某万卡集群另一起性能下降典型案例讲解
下面是某万卡集群另一起性能下降案例,该案例比较典型。可以通过下图看到11月7号04:30附近,整个集群有大幅的性能下降,大约持续3个小时后,集群性能又逐渐恢复。
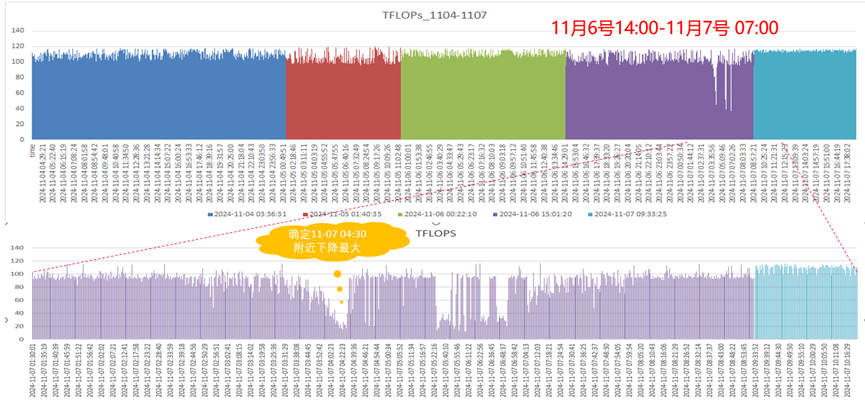
为了搞清楚集群性能下降和恢复的原因,我们按照上述解决流程图,围绕11-07 04:30排查算网存关键指标和关键事件。
通过对网络指标的分析(如下图),我们在11-07 04:30附近没有发现与性能下降高相关性的数据;
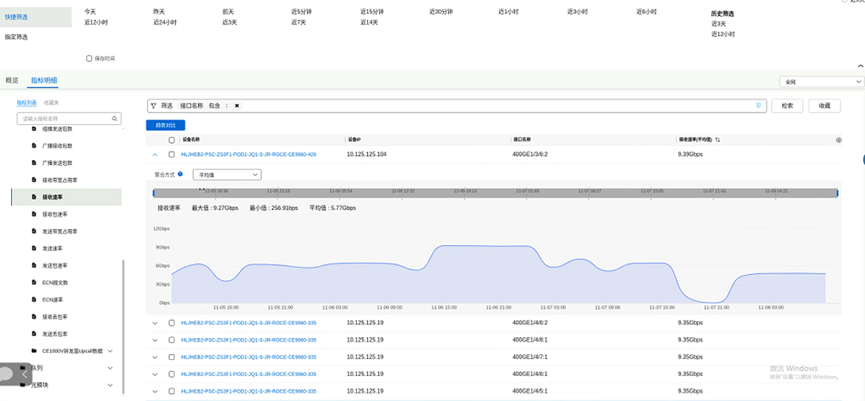
随机抽查多个计算节点在11-07 04:30时的CPU利用率和IOWait数据时,发现多个计算节点在11-07 04:30时都存在CPU用户使用率低,同时IOWait高的现象,如下图所示:
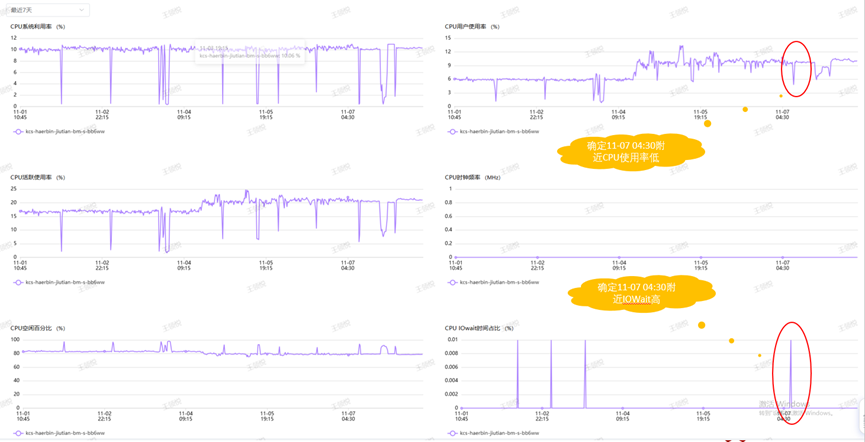
通过整个训练流程分析,CPU侧训练进程相关IO的访问主要是远程存储的读训练数据,写日志和写CKPT,除此外没有其他IO操作,因此大概率怀疑是该时刻存储集群可能有异常。同时,计算侧也排查了11-07 04:30附近的AI Core利用率,发现该时刻附近,AI Core利用率低,如下图所示。经过分析,AI Core利用率低的原因大概率是该时段CPU侧等待IO,导致算子下发慢,算子下发间隔大,导致AI Core空转,导致AICore利用率低。
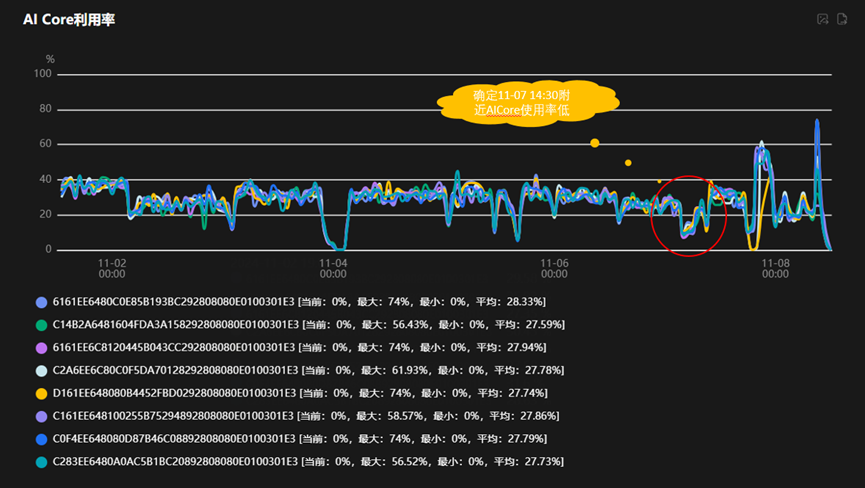
至此,分析重点开始倾向于存储侧。通过对存储集群管理系统DME中DPC客户端实时写时延数据的分析,如下图,我们发现11-07 04:30附近连续出现了多个DPC写时延尖刺,并且其与整个集群的性能下降时间和范围高度吻合。
DPC写时延的统计方式是每T长时间内(粒度有10秒,30秒…),所有DPC客户端(每个计算节点一个DPC客户端,1.6万卡,2千计算节点,则有2千个DPC客户端)的写时延的平均值,也就是在时间维度(T长时间)和DPC客户端维度双向取平均(目前没有最大,最小,方差,分位数统计),平均值尖刺则代表着最大值可能更大,而训练集群的特点是整个集群单步运算中的最慢节点决定了整个集群的性能,因此经过算存网三方关键指标数据统一分析,我们认为存储DPC实时写时延尖刺问题大概率是本次集群性能下降的原因。
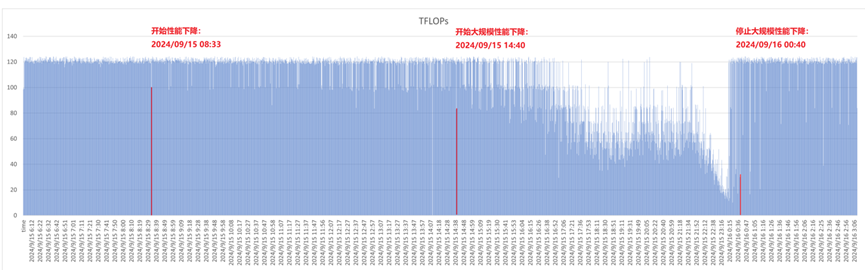
1.3.4.2 典型案例2:某8千卡集群性能下降10小时后恢复典型案例讲解
下面是某8千卡集群性能下降10小时后又恢复的案例,该案例也比较典型。可以通过下图看到9月15号14:40开始下降,9月16号00:00附近下降到最低谷后又突然恢复,整个下降大约持续了3个小时左右。
按照性能问题排查流程,我们开始收集算存网关键性能指标,开始排查。首先看网络指标,网络上端口闪断、链路故障、PFC反压,丢包,错包数据中都没有明显异常,但在接收包数和发送包数中,随机抽查了7台交换机,都存在类似下面的图形,其与性能缓慢下降的波形非常吻合。
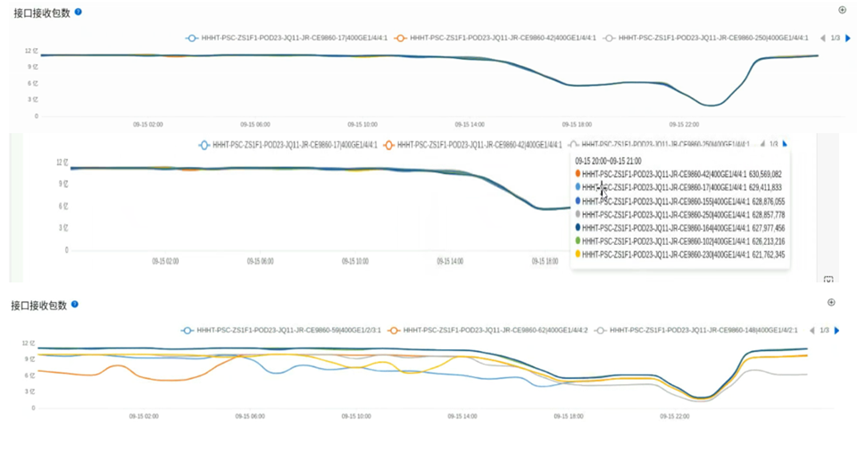
具体来看:
-
随机抽查的7台交换机在性能下降期间均存在发送、接收包数变少的现象,持续的时间大约在09/15 14:00 – 09/16 00:00左右,与性能下降时间段吻合,且均无丢包计数。可以确认性能下降期间交换机没有故障,且 NPU 普遍存在向交换机发送数据量变少的现象。
-
NPU发送数据量变少的一个可能性就是CPU侧算子下发变慢,需要进一步排查CPU性能指标;
-
另外,可以看出,导致性能下降的问题很可能是一个集群共性问题,如果是单点故障,则不太可能随机抽查的7台交换机的波形都相同。
再次排查计算侧数据,具体如下: 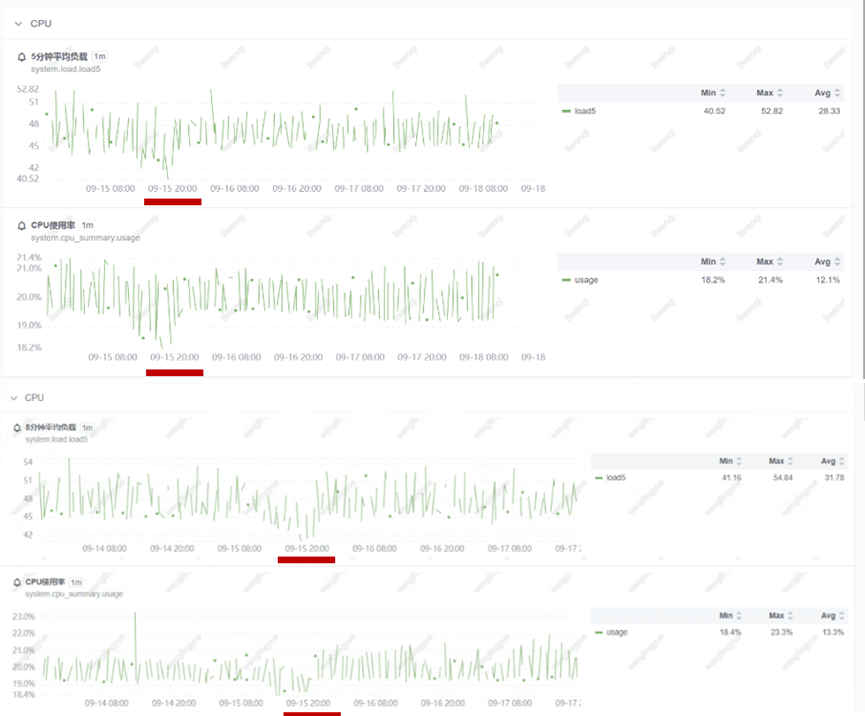
- 随机抽查了4台计算节点的CPU利用率,其在性能下降期间均有一定程度下降,说明不是其他进程抢占训练进程导致,大概率还是CPU在等IO导致CPU利用率低,导致下发算子慢。
- CPU侧等IO目前基本上就是在等存储IO,因此下一步还是重点排查DPC客户端和存储集群。
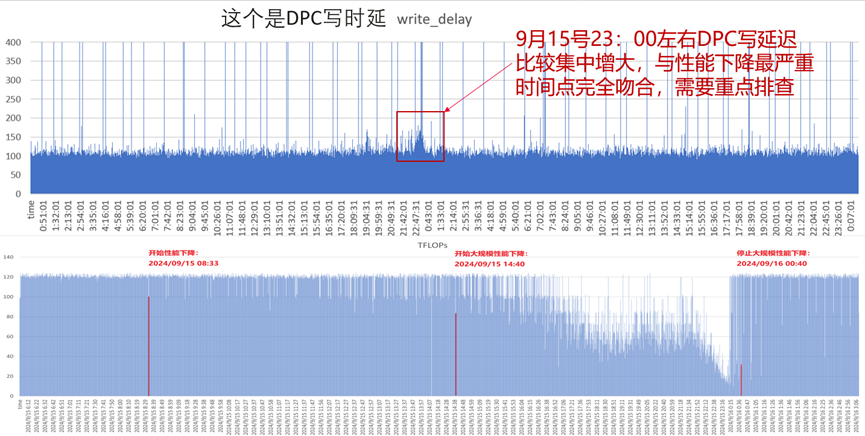
随机抽查几台计算节点DPC客户端数据分析,如下图,发现在集群性能下降期间的DPC的IOPS数据降低,同时对应的写时延增大的密度比较高。
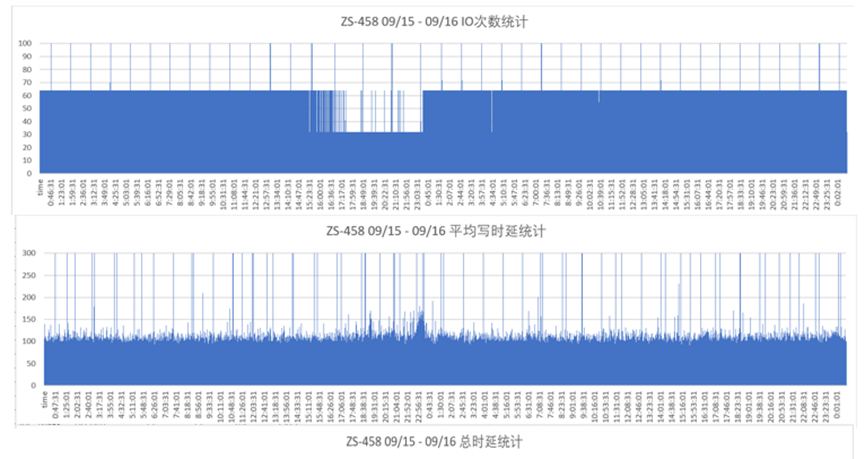
通过对训练流程分析,如果写日志到远程存储时,写时延增大,则导致单位时间内写的次数减少,与该现象比较符合。对比写时延数据与性能下降最严重的时间点,发现两种完全吻合。
1.3.5 常见大规模集群性能问题根因与解决方法总结
结合已知集群性能问题案例,我们总结了下面的集群性能常见根因及其解决方法:
1.存储侧:
a) 根因1:各卡CPU侧进程并发读训练数据+数据处理耗时高或差异大,导致性能下降或抖动;解决方法:优化数据处理代码,减少不必要的训练数据读取+数据处理;
b) 根因2:各卡CPU侧进程写日志耗时高或差异大,导致性能下降或抖动;解决方法:日志先写本地,再手动或定时转储到远程存储;
c) 根因3:各卡CPU侧进程其他远程存储访问,比如判断远程存储CKPT路径是否存在等会导致各卡耗时差异大,导致性能下降或抖动;解决方法:优化不必要的路径判断,路径访问等操作,尽量减少对远程存储的读写访问;
2.网络侧:
a) 根因1:秒级以上端口闪断或链路故障,经验为离计算侧越近的端口闪断或链路故障,对训练集群性能影响越大;有案例经验需要注意,虽然我们经常看到NPU侧参数面网络PFC反压很大,但其根因往往仍然是卡间不同步导致的,当把卡间不同步优化后,PFC反压正常。
3.计算侧:
a)根因1:NPU卡中通信同步耗时长导致性能下降,卡间同步忽快忽慢则导致性能抖动;解决方法:动态profiling通过Notify Wait对比可以检测出,具体根因一般是卡间不同步导致,而卡间不同步的原因又往往是CPU侧外界不同步或内部不同步导致;一)CPU侧外界不同步往往是CPU侧等待存储访问,比如判断远程路径是否存在的耗时差异导致的不同步,训练数据读取与数据处理耗时差异导致的不同步等,或是其他进程比如监控进程的干扰等导致的不同步,需要IOWait和CPU利用率来判断;二) CPU侧内部不同步又往往是CPU侧执行了不同步的操作,比如垃圾回收触发时机和耗时不同导致的不同步等;
b)根因2:NPU亚健康导致的计算慢卡;解决方法:检测出后隔离。动态profiling可以检测出,隔离压测后查看硬件根因。
c)根因3:NPU通信实际耗时长导致性能下降,卡间通信忽快忽慢则导致性能抖动;解决方法:动态profiling通过通信异常对比可以检测出,通过网络侧端口闪断,链路故障,PFC,错误包等数据也可以推测出慢链路;
d)根因4:CPU侧卡间垃圾回收时机不一致,耗时差异大,导致卡间不同步。耗时差异大则导致性能抖动。解决方法:垃圾回收定时执行或固定步骤执行减少卡间不同步;
e)常见问题:各计算节点时钟不同步导致的分析困难,目前log和profiling强依赖时钟同步,如果有计算节点时钟不同步,则会导致profiling数据结果失真,误导分析;解决方法:配置ntpd时钟同步服务。
4.配置变更:
a)根因1:数据集/算存网超参/软硬件变化(升级,替换)等可能导致性能问题(比如数据集目录变更,存储小IO参数配置等);解决方法:记录配置变更关键事件,绘制性能与关键事件图确定相关性,按训练流程分析,回退或对比实验验证是否为根因
1.4 当前不足与下一步展望
现网万卡集群性能问题的解决是个痛苦的过程,复杂性高,实现中又有各种不足,下面就对当前的一些不足进行总结:
1.缺少算存网自动化数据收集与统一分析工具:理想中,该工具能够按相同时间范围,相同时间粒度,绘制性能变化图+性能与关键事件图+算存网性能关键指标图,同时能够结合性能变化前后动态profiling数据自动对比分析,统一分析。现实中,当前都是人肉方式收集数据并分析。
2.算存网关键性能数据维度和时间粒度不同,统一分析困难:1)存储只能给出单个DPC的性能数据,DME给出的综合的DPC的数据粒度太大(其是T时间粒度内所有DPC客户端的读写时延按客户端和时间两个维度综合合并的平均值),缺失客户端时延最大最小方差等关键信息、;2)网络只能给出某个端口的PFC,收发包,错误包数据,无法给出综合信息,比如综合起来所有端口的PFC,收发包,错误包数据的最大最小平均方差等数据;3)计算侧只能单个节点分析CPU利用率IOWait等,很难获取全局信息;4)动态Profiling可以获取全局信息,但只是瞬时信息,缺乏连续时间数据。
3.算存网紧耦合,缺失接口指标:计算侧需要重新定义算存网接口指标,根据接口指标可以判断是哪方面问题;当前无算存,算网接口指标,存储的DPC指标都是经过OS拆分后的,很难作为接口指标。参数面网络,当前缺失通信同步耗时和通信实际耗时的区别,因此当前无法判断实际通信耗时,无法区分是参数面网络问题还是计算问题;
4.数据渠道不统一,难以收集:1)关键事件来源于现场输入和CCAE告警;2)网络数据来源于NCE(最近时间段累积量),而不是CCAE(CCAE当前是历史上累积量,无法使用,预计下个版本修改),3)存储数据来源于DME和计算节点中DPC客户端数据(CCAE中只是免登陆跳转到DME),4)计算数据来源于客户监控平台(客户没给CCAE采集带内数据权限)和动态profiling工具;
下一步希望算存网能够合力设计出算存网统一的集群性能分析工具,能够自动化分析,高效解决万卡乃至未来超万卡集群的性能问题,同时希望提高算存,算网协同,解决现网常见性能问题,提高公司万卡、超万卡集群竞争力。
1.5 总结
本文分享了某局点千卡万卡训练集群性能问题的部分解决案例,并在所有已知案例基础上提炼了大规模训练集群性能问题的解决方案,同时总结了当前集群性能问题解决中的不足和下一步方案展望。目的是为其他局点解决大规模集群性能问题提供参考,并为公司万卡、超万卡训练集群竞争力提升提供一份力量。


















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









