



背景介绍
在A3超节点512die上,基于某企业的自研框架Xtuner训练Qwen3 235B MOE。本文对FSDP2下,如何使能GroupedMatMul NZ特性进行了深入展开,最终取得整网2+%的性能收益。9月8日Xtuner V1开源后,某企业在H800上进一步优化了性能(TGS 2000=>2100+),我们也需要在昇腾上一直摸高,才能维持住A3超节点的竞争力。
1. 训练中的GMM NZ 技术选型
1.1 矩阵乘相关特殊格式:NZ格式
FRACTAL_NZ是物理内存排布的分形格式,tensor数据格式为NW1H1H0W0,即:整个矩阵被分为(H1W1)个分形,按照column major排布,形状如N字形;每个分形内部有(H0W0)个元素,按照row major排布,形状如z字形。考虑到数据排布格式,将NW1H1H0W0数据格式称为NZ格式。更为常见的是ND数据格式,ND格式tensor可通过Pad、拆分以及转置等操作转换为NZ格式。
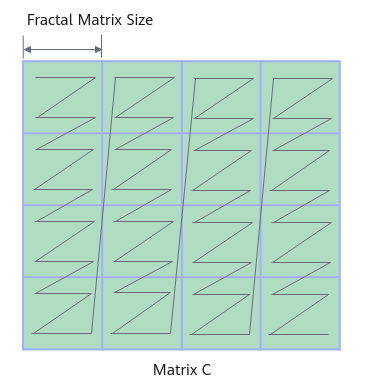
NPU矩阵运算会在MTE2搬运过程中,将ND格式输入随路转换成较为亲和的NZ数据格式来参与后续运算,随路数据格式转换会损失一部搬运效率。如果算子接受到的本身就是NZ数据格式,则可以将这部分随路转换的过程给省略掉,从而提高搬运效率,提升性能。
在推理实践中,GroupedMatmul算子接受NZ格式的权重,输出ND格式的激活值,性能优于ND格式权重输入的情形。由于推理只涉及网络前向运算,仅需一次性加载权重并转为NZ格式,在后续的多次推理中,复用NZ格式的权重进行运算即可取得性能增益,无需考虑ND转NZ本身带来的性能开销。
训练包括使用权重参与前向计算和反向更新权重,可能涉及多次ND和NZ格式转换,需要权衡GMM使能NZ的成本和收益。在xtuner框架下Qwen 235B MoE训练中,进入GMM算子运算前,手动将权重转NZ,代码实现如下。
weight = weight + 0
weight = torch_npu.npu_format_cast(weight,29)
out = NpuGMMOp.apply(weight, x, tokens_per_expert)
显然,小算子实现额外增加ND转NZ的transdata算子耗时,结果证明对于给定shape的weight,转NZ带来的性能开销完全抵消使能GroupedMatmul NZ的性能收益,以致性能劣化。
GMM中weight.shape=(128,4096,3072)时, 转NZ的数据搬运量为2sizeof(BF16)12840963072 Bytes,昇腾A3的标称带宽为1.6TB/s,在集群训练带宽利用率达到80%的情况下,耗时为4.578 ms,完全可覆盖GMM NZ的性能收益(参考3.4节中profiling,同shape下GMM NZ耗时从约22ms下降至约20ms)。
1.2 FSDP2框架下的NZ使能方案和收益分析
在FSDP2框架下,MOE权重依次经过内存初始化和分片 --> 各卡加载权重 -->每一层计算前 all gather这一层的所有权重 --> copy_out --> 参与GMM的计算。All gather集合各卡的权重分片,并将完整的权重参数保存在HCCL_BUFFER的临时内存中,随后通过torch::split_sizes_with_copy将完整权重参数copy out至device侧参与运算。ND到NZ格式的权重转换本质上也涉及HBM至device侧的数据搬运,因此融合slice和转NZ操作能避免增加HBM访问压力、减少转NZ耗时。
从计算过程看:
1.每张卡保存的分片内存为ND格式;
2.每一层allgather后,GMM的权重在copyout的过程中转为NZ格式,进行正、反向计算。
3.反向计算完梯度,输出格式为ND,并通过reducescatter操作,将梯度reduce后scatter到各自分片参数所在的卡上。最后,优化器计算阶段,每张卡上的ND参数分片与梯度、优化器一起完成参数更新。 本文的优化过程仅涉及第2步,第1、3步为FSDP2原有流程。
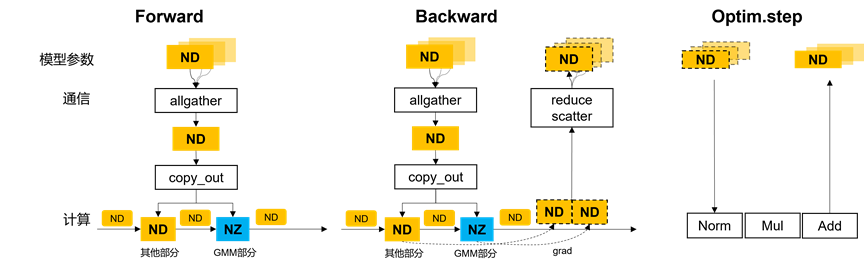
反向梯度的计算过程,如下图所示,假设输出Y,输入激活X,权重W。只有算激活梯度的GMM,会用到参数权重W,可以通过NZ使能进行加速优化。参数梯度的GMM反向计算,性能是没有收益的。
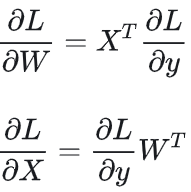
在其他主流框架如megatron中,把权重切分(TP/PP/EP)到每张卡上分别进行前向运算,**没有FSDP2的all gather过程及正反向计算过程的权重和参数更新过程的分片为两块独立内存的情况。**若megatron将本地持有的权重转换为NZ格式保存,需要打通很多计算步骤,例如:
• 需要PTA支持显式ND、NZ格式权重的GMM计算;
• 需要PTA支持NZ格式的内存申请和释放;
• 反向GMM参数梯度输出为ND格式,需要支持ND格式梯度和NZ格式参数的更新。
我们对NZ格式的权重训练做了初步的探索,证明确实此路难通。最后我们依托于FSDP2训练框架,将训练过程中正反向计算用到权重的地方,借助copyout申请的临时内存,将GMM权重转换为了NZ格式并不引入额外的HBM搬入搬出开销;同时还不影响优化器更新、权重加载等原有流程。
2. PTA拦截NZ格式
PTA框架会对NZ这一私有格式进行拦截。为使能GMM NZ,我们有如下尝试,均以失败告终。具体行动及其结果如下:
(1)模型初始化时,为MM/GMM初始化NZ格式的内存。结果:释放内存的时候,NZ格式报错。 (2)加载模型权重后,转为NZ格式。结果:GMM实际入参权重为ND格式。
(3)在all gather后copy out同时,显式转NZ,随后进入GMM前向运算。结果:采集profiling观察到slice算子输出转为能被PTA识别到的FRACTAL_NZ格式,但GMM入参权重依旧保持ND格式;而slice算子与GMM前向运算之前未历经任何运算算子。
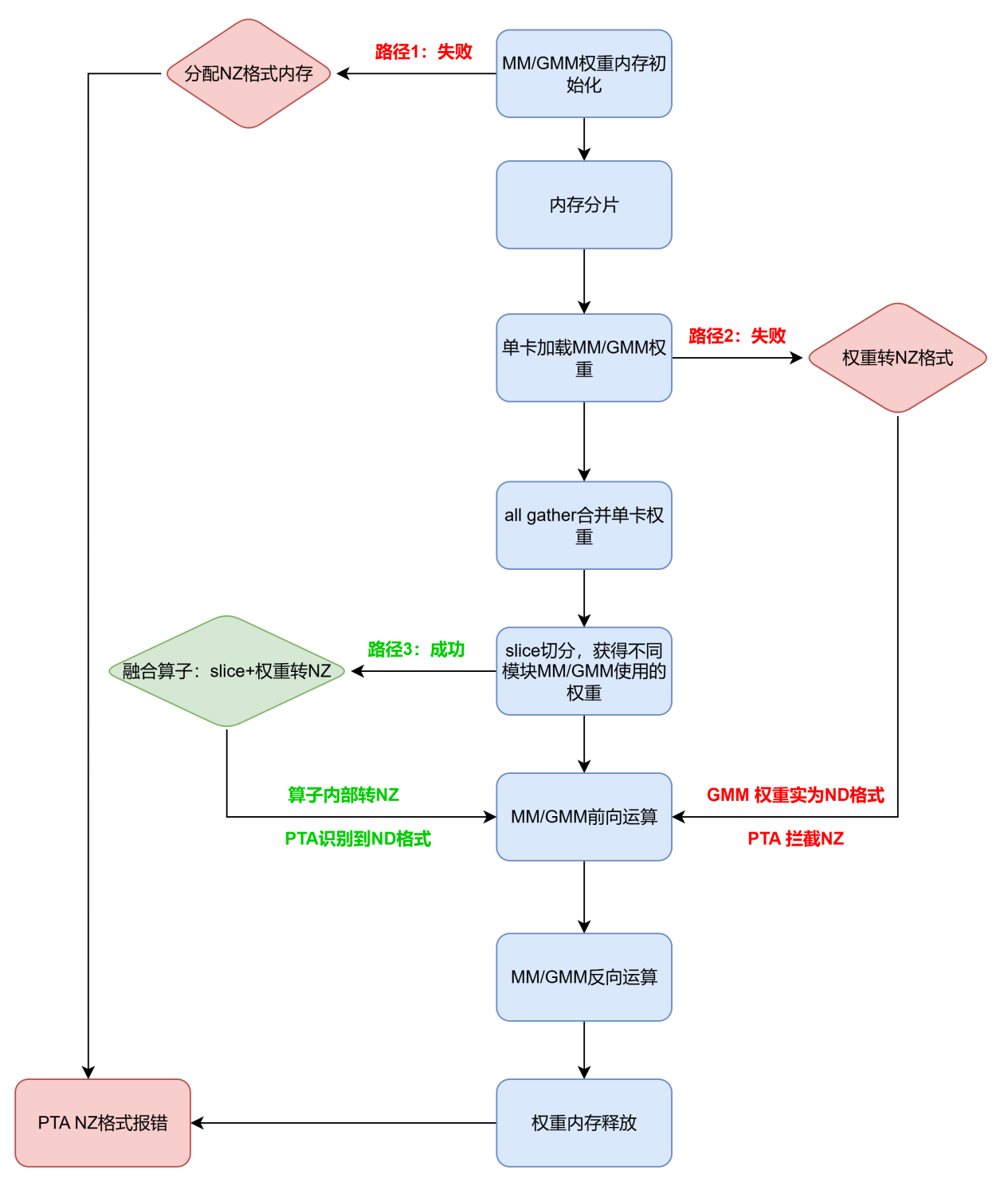
2.1 绕过PTA使能NZ
为规避PTA框架的拦截,令sliceNZ算子的输出实质保持NZ格式,但被PTA框架识别为ND格式。
PTA框架对于私有格式把控较为严格,无法显式修改tensor的数据排布格式。只能通过调用数据格式转换算子(transdata)来进行数据格式转换,而调用额外算子又会带来额外的性能损耗。
分析CANN算子,我们发现aclnn_grouped_matmul_weight_nz 这样一个aclnn接口,接受ND格式的权重输入,但是实际将权重视为NZ格式。如果我们可以调用这类NZ算子,就可以绕过框架使能NZ数据格式,这正是我们想要的。
我们将上述需求拆解为两部分
(1)获取实际数据排布为NZ的权重
(2)适配PTA直接调用aclnn_grouped_matmul_weight_nz算子
如上所述,我们在copy_out 的同时,将GMM的权重转换为NZ格式,即调用一个算子(sliceNZ)将权重slice,并转换为NZ格式排布,框架侧使用ND格式的tensor接受权重,再通过调用aclnn_grouped_matmul_weight_nz来使能NZ。
2.2 效果验证
应用如下单算子测试验证权重输出的格式,其中torch_npu.npu_special_slice为sliceNZ融合算子的PTA接口。torch_npu.get_npu_format(b)返回结果为ND,表明该输出成功被PTA框架识别为ND格式。
import torch,torch_npu
end = 8*3072*4096
torch_npu.npu.config.allow_internal_format = True
a = torch.randn((16,end),dtype=torch.bfloat16).npu()
b = torch.empty((128,3072,4096),dtype=torch.bfloat16).npu()
torch_npu.npu_special_slice(a, 1, 0, end, b)
print(torch_npu.get_npu_format(b)) # 结果为ND
采集profiling,发现输出成功转为NZ格式。
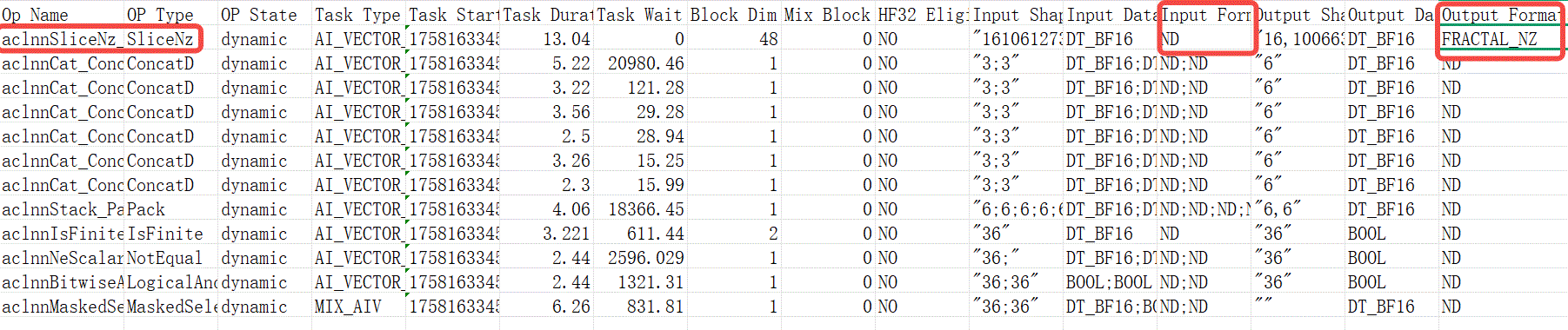
整网同样成功使能NZ。 
3. sliceNZ算子适配
3.1 算子原型
PTA框架中的copy_out(slice)算子直接调用torch::split_with_sizes_copy接口。对于all gather后的完整权重all_gather_output,FSDP2框架对其dim维度进行切分,all_gather_input_split_sizes指明了切分后的各tensor长度。该函数的输出Listout中,末尾两个tensor对应MoE中gate_proj、up_proj和down_proj模块权重,其中gate_proj和up_proj在out轴做合并,shape为[num_expert,hidden_size,dim*2];down_proj的shape为[num_expert,dim,hidden_size]。
@torch.library.impl(lib, "split_with_sizes_copy", "PrivateUse1")
def split_with_sizes_copy(
all_gather_output: torch.Tensor,
all_gather_input_split_sizes: List[int],
dim: int,
out: List[torch.Tensor],
) -> None:
torch.split_with_sizes_copy(
all_gather_output, all_gather_input_split_sizes, dim=dim, out=out
)
sliceNZ算子原型如下,函数签名类似slice算子本身,但由按照长度切分改为按照入参tensor self在dim维的开始start和结束end切分索引。该算子还接受入参output,通常是3D tensor(output.shape = [num_expert, n, k]);当专家数为1时,可以是2D tensor。output是一块预分配的内存,将sliceNZ算子切分并转为NZ格式的输出写入output中。output将充当后续GroupedMatmul前向计算的权重。
aclnnSliceNzGetWorkspaceSize(const aclTensor *self, unit64_t dim, unit64_t start, unit64_t end, aclTensor *output)
3.2 PTA接口绑定
基于op-plugin官仓,可为自定义算子绑定PTA接口。
(1)结构化适配
在op_plugin_functions.yaml文件中自定义算子custom字段下添加上述aclnn算子的接口调用,(a!)代表原地修改:
- func: npu_special_slice(Tensor self, int dim, int start, int end, Tensor(a!) output) -> ()
op_api: [v2.1, newest]
gen_opapi:
exec: aclnnSliceNz, self, dim, start, end, output
(2)PTA编包
首先,确定编译使用的PTA分支,此处所需的GroupedMatmul切K轴特性已合并到主线,即v2.6.0及后续版本。其次,依据PTA包中的dockerfile搭建编包容器。最后,执行编译命令,获得.whl格式的PTA安装包。
(3)修改原始slice算子实现
安装上述PTA包后(同时安装包含该aclnn算子的CANN包,CANN包编译安装和应用环境保持一致),即可通过torch_npu.npu_special_slice调用sliceNZ算子。 为了在FSDP2框架中使能sliceNZ,我们的修改逻辑是: •在slice的输出中,找到为GMM weight预分配的内存,从而确定slice切分的索引 •将预分配内存view shape由2D([num_rank, n*k])修改为3D([num_expert, out_feature, in_feature]) •GMM weight调用sliceNZ,其他weight仍用slice算子
@torch.library.impl(lib, "split_with_sizes_copy", "PrivateUse1")
def split_with_sizes_copy(
all_gather_output: torch.Tensor,
all_gather_input_split_sizes: List[int],
dim: int,
out: List[torch.Tensor],
) -> None:
# out为切分后的预分配内存 List<Tensor>,长度为6。前四个tensor将用于MatMul,后两个tensor将用于GroupedMatmul
# 其他算子可能经过slice,通过out[-1]的shape进行筛选
if len(all_gather_input_split_sizes) > 1 and out[-1].shape[0] * out[-1].shape[1] >= 128 * 4096*1536:
from special_op import npu_special_slice
num_rank = out[0].shape[0]
total_size = sum(all_gather_input_split_sizes)
weight_1_size = out[-1].shape[1]
weight_2_size = out[-2].shape[1]
weight_1_start = total_size - weight_1_size
weight_2_start = weight_1_start - weight_2_size
num_exp = 128
in_dim1, out_dim1 = 1536,4096 # down_proj
in_dim2, out_dim2 = 4096,3072 # torch.cat((gate_proj,up_proj),dim=1)
out[-1].resize_(num_exp,out_dim1,in_dim1)
out[-2].resize_(num_exp,out_dim2,in_dim2)
npu_special_slice(all_gather_output, dim, weight_1_start, total_size, out[-1])
npu_special_slice(all_gather_output, dim, weight_2_start, weight_1_start, out[-2])
other_tensors = all_gather_output[:, :weight_2_start].view(num_rank, -1)
torch.split_with_sizes_copy(
other_tensors, all_gather_input_split_sizes[:-2], dim=dim, out=out[:-2]
)
return
3.3 512对齐的性能影响
昇腾A2和A3系列芯片上一个cacheLine是512B,通过遍历各个cacheLine的方式读取数据。如果不做对齐,读取512B数据需要访问2个cacheLine,这会直接导致 sliceNZ的性能劣化约30%。
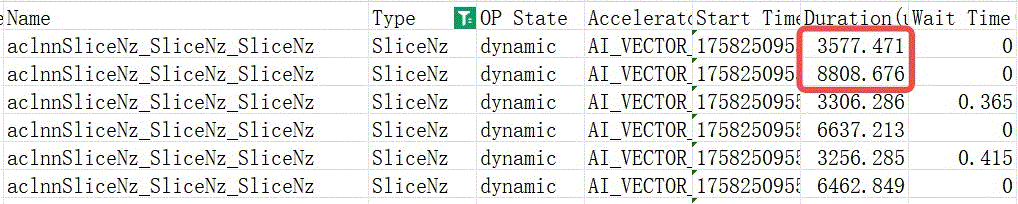
 Qwen 235B模型单层的FSDPParamGroup中gate_param和norm_param 切分后,group通信参数量不易被512整除。解决方案为修改fully_shard切分策略,只切分参数量512对齐的linear模块。
Qwen 235B模型单层的FSDPParamGroup中gate_param和norm_param 切分后,group通信参数量不易被512整除。解决方案为修改fully_shard切分策略,只切分参数量512对齐的linear模块。
3.4 性能收益分析
在Qwen3 235B MoE模型训练中,对于两种shape(参考5.1节)的GMM weight,sliceNZ单算子性能耗时分别在2.7ms和5.2ms左右。 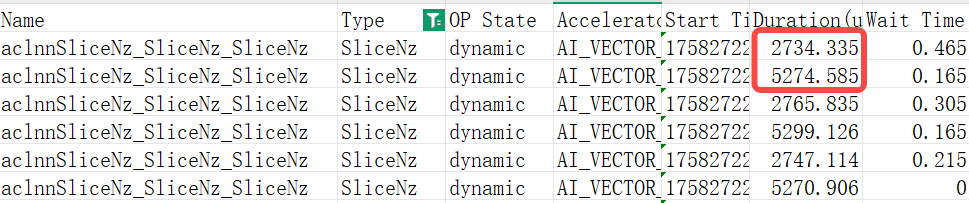 应用sliceNZ前后,slice算子总耗时由1.68s增加至约2.36s,即单步slice NZ转换的性能开销为0.68s。
应用sliceNZ前后,slice算子总耗时由1.68s增加至约2.36s,即单步slice NZ转换的性能开销为0.68s。 
 单步整网共经历750个GMM算子,NZ格式下GMM算子性能提升约7%:总耗时由12.75s下降至11.98s。
单步整网共经历750个GMM算子,NZ格式下GMM算子性能提升约7%:总耗时由12.75s下降至11.98s。 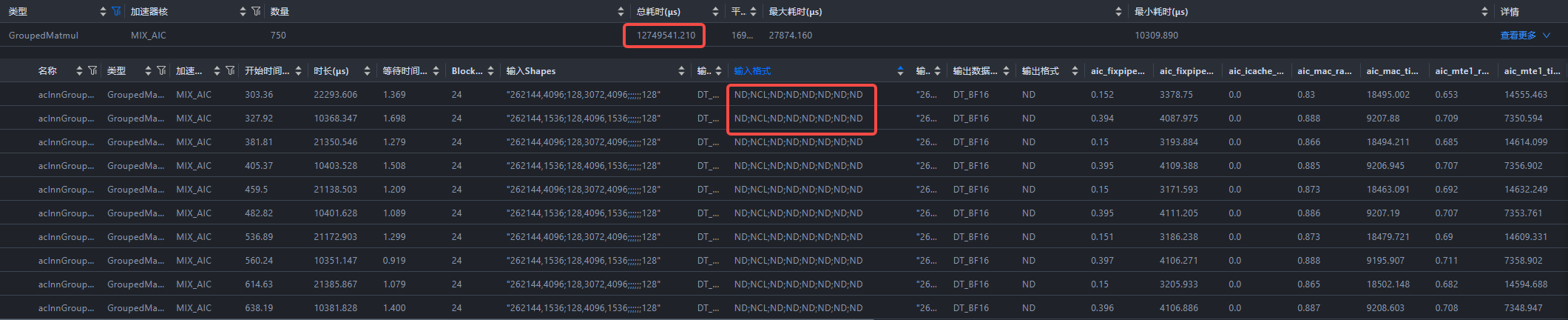
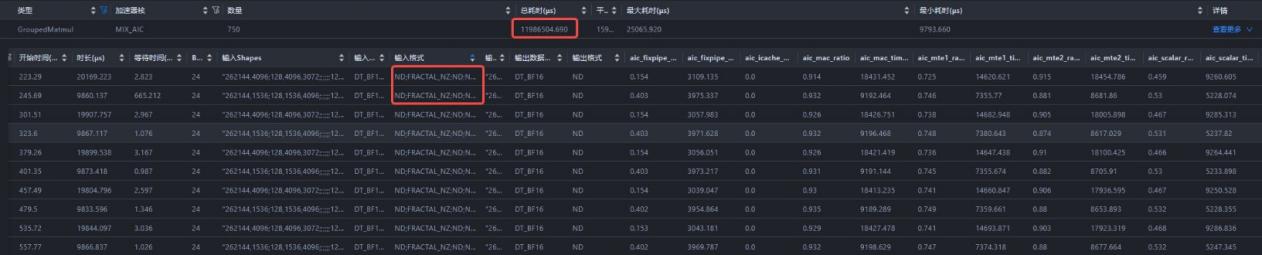
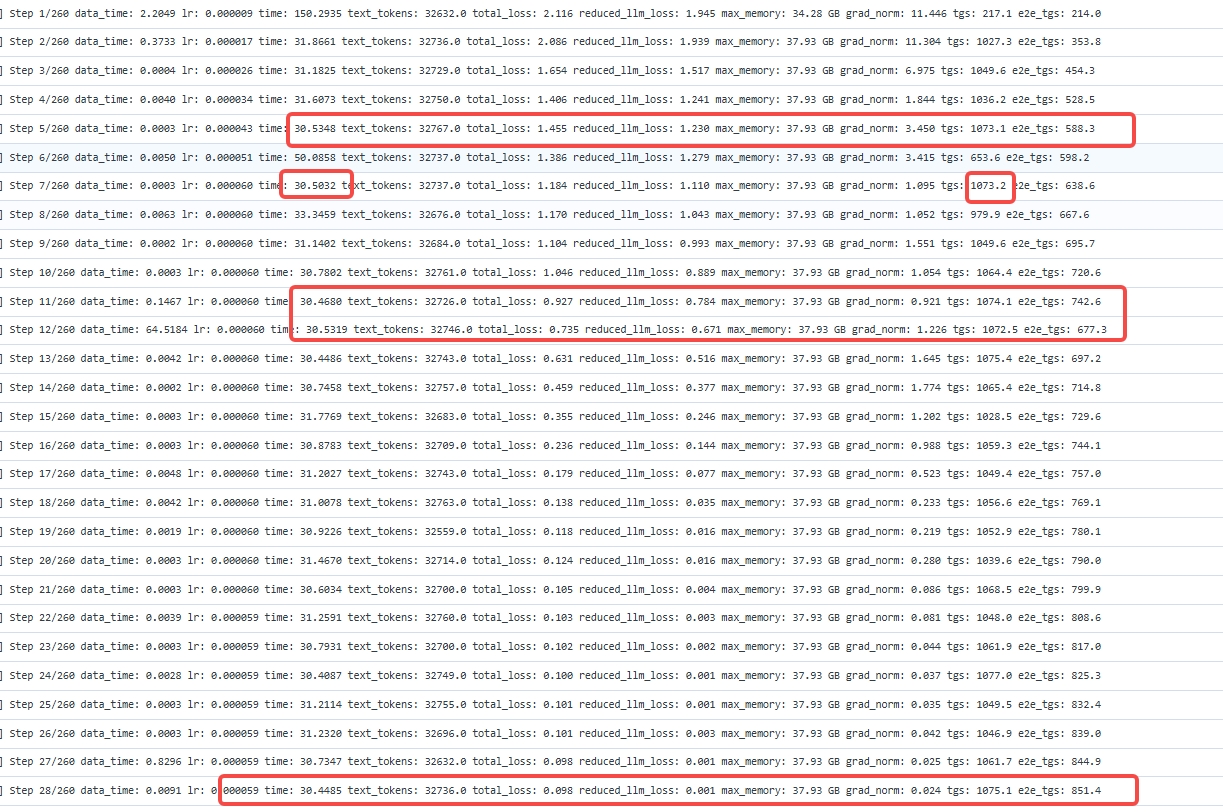
94层整网性能从2100tgs提升至2148tgs,即GMM NZ的性能收益提升约2+%。 GMM ND方案整网训练日志(单die): 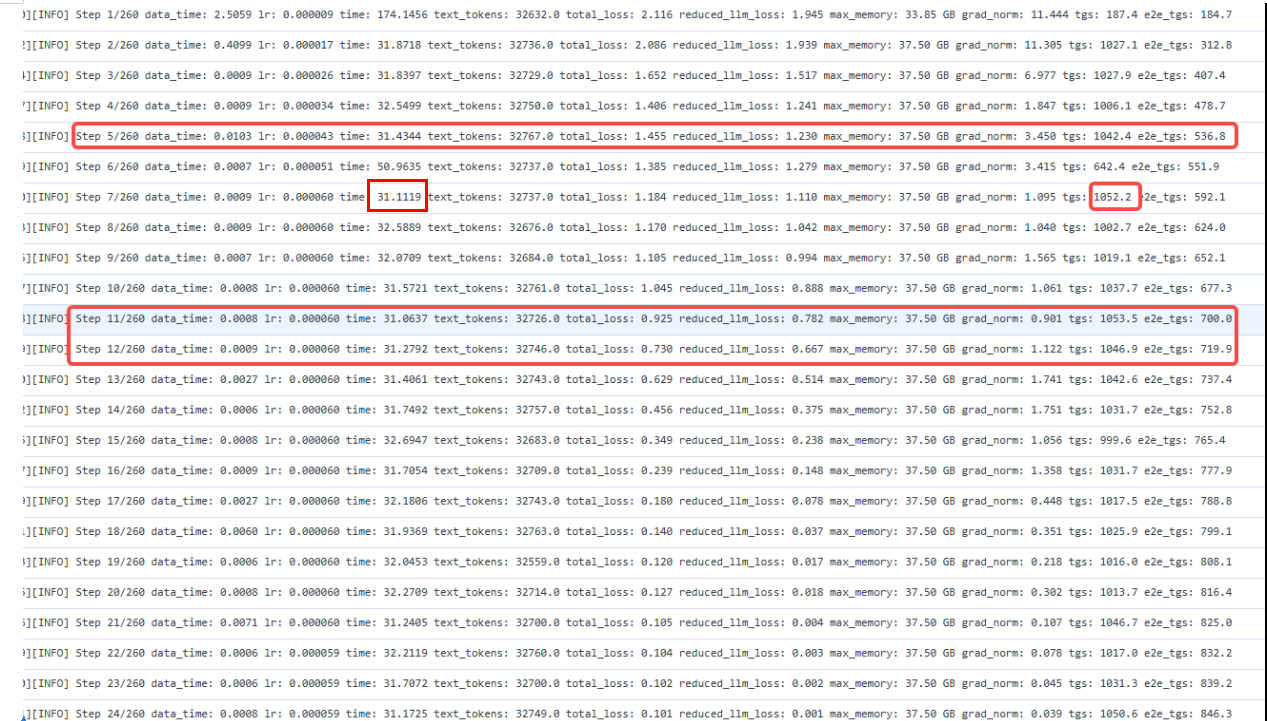
GMM NZ方案整网训练日志(单die):
4. GMM NZ 前反向使能
PTA中的GMM算子torch_npu.npu_grouped_matmul支持接受NZ格式的权重输入,但没有绑定反向代码实现。GMM的反向也是GMM,前向中对m轴进行切分,反向实现需要支持k轴切分,该特性已合并至PTA的v2.6.0主线分支。
4.1 GMM算子原型
非量化、无偏置场景下,计算公式为
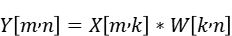
实际x.shape = [m,k],weight.shape = [num_expert,k,n]。
outs = torch_npu.npu_grouped_matmul([x], [weight], group_list = tokens_per_expert, group_type = 0, group_list_type = 1, split_item = 2)[0]
上述代码实际执行的操作,是把X按照m轴切分num_expert个,分别作为单个专家的Matmul输入;按专家进行Matmul。
对于输入
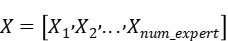
其中第i个分片
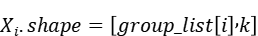
与之对应的权重分片为
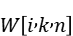
二者进行matmul的输出为
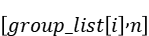
GroupedMatMul的输出为
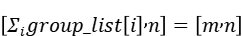
4.2 前反向适配
由于torch_npu.npu_grouped_matmul算子不支持反向,需要手动适配GMM反向;而GMM的反向也能通过GroupedMatMul实现,公式推导如下:
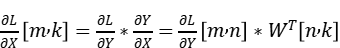
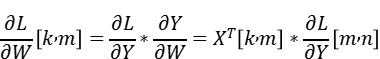
在前向重计算时,我们保存了前向权重weight.shape=[num_expert,k,n],和激活值x.shape=[m,k];并接受入参
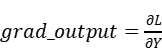
反向计算激活值梯度和权重梯度的代码实现如下。
# 激活值的梯度
grad_input = torch_npu.npu_grouped_matmul([grad_output], [weight.transpose(1,2)], group_list = tokens_per_expert, group_type = 0, group_list_type = 1, split_item=2)[0]
# 权重的梯度
grad_weight = torch_npu.npu_grouped_matmul([input_tensor.T], [grad_output], bias=None,group_list = tokens_per_expert,split_item=3, group_type=2, group_list_type=1)[0]
显然在计算权重梯度时,要对转置后的X实际切分第二维,即切k轴。 在GMM算子前反向适配中,我们在上下文中保存前向的激活值和梯度,反向入参为
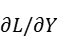
from torch.autograd import Function
import torch_npu
from torch_npu import transfer_to_npu
class NpuGMMOp(Function):
@staticmethod
def forward(ctx, weight, x, tokens_per_expert):
# 假设weight.shape=[k,n],x.shape=[m,k]
# tokens_per_expert.shape=[num_expert],且torch.sum(tokens_per_expert)=m
ctx.save_for_backward(weight,x,tokens_per_expert)
outs = torch_npu.npu_grouped_matmul([x], [weight], group_list = tokens_per_expert, group_type = 0, group_list_type = 1, split_item = 2)[0]
return outs
@staticmethod
def backward(ctx, grad_output):
weight,input_tensor,tokens_per_expert = ctx.saved_tensors
grad_input = torch_npu.npu_grouped_matmul([grad_output], [weight.transpose(1,2)], group_list = tokens_per_expert, group_type = 0, group_list_type = 1, split_item=2)[0]
grad_weight = torch_npu.npu_grouped_matmul([input_tensor.T], [grad_output], bias=None, group_list = tokens_per_expert, split_item=3, group_type=2, group_list_type=1)[0]
return grad_weight, grad_input, None
if __name__ == "__main__":
# 假设此处已有符合条件的GroupedMatmul入参:weight, x和tokens_per_expert
out = NpuGMMOp.apply(weight, x, tokens_per_expert)
5. GMM冗余Transpose的消除
使能sliceNZ后,发现总体性能未有明显增益。排查profiling后发现,手动适配PTA前反向过程中,冗余的transpose显著增加性能开销,完全覆盖了GMM NZ的性能提升。接入GMM NZ后,单步训练的transpose算子总耗时从约0.05s上升至1.2s,总耗时占比达2%。 
5.1 MoE结构分析
MoE结构包含多个结构相同、权重不共享的前馈网络(专家),第i个专家的输出可以表示为
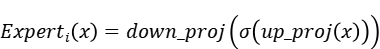
其中up_proj = nn.Linear(d_model, d_ff),down_proj = nn.Linear(d_ff, d_model)。门控网络gate_proj的shape与up_proj一致,为每个token选择top_k个专家(并将top_k个专家权重归一化)。为充分利用并行矩阵乘的运算效率,将gate_proj和up_proj在d_ff(即out_feature)维度合并。 
对于Qwen3 235B MoE模型,专家数num_expert = 128,隐藏层大小d_model = 4096,前馈网络的尺寸为d_ff = 1536。前向训练中历经两次GMM运算,输入权重分别为Concat([gate_proj.weight, up_proj.weight]).shape = (num_experts, d_model, d_ff * 2) = (128, 4096, 3072) 和 down_proj.weight.shape = (num_experts, d_ff, d_model) = (128, 1536, 4096);up_proj和down_proj接收的激活值分别为,X1.shape = (batch_size * seq_len, d_model) ,X2.shape = (batch_size * seq_len, d_ff)。 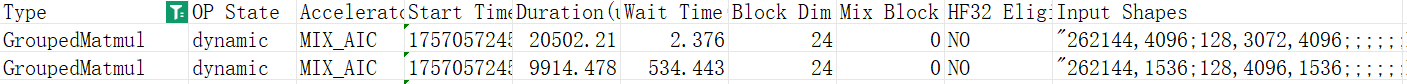
xtuner框架中对于gmm weight的初始化遵循类似nn.Linear的实现,即对于in_feature-->out_feature的线性映射,入参weight.shape=(out_feature,in_feature),矩阵乘的底层逻辑为x@weightT。但对于torch_npu.npu_grouped_matmul来说(4.1节),第i个专家的实现为x_i@weight_i,因此入参weight.shape=(num_expert, in_feature,out_feature)。在xtuner框架中适配该GMM算子,必须对weight的in轴和out轴进行转置。为避免这一开销,我们选择调整权重初始化和加载逻辑。 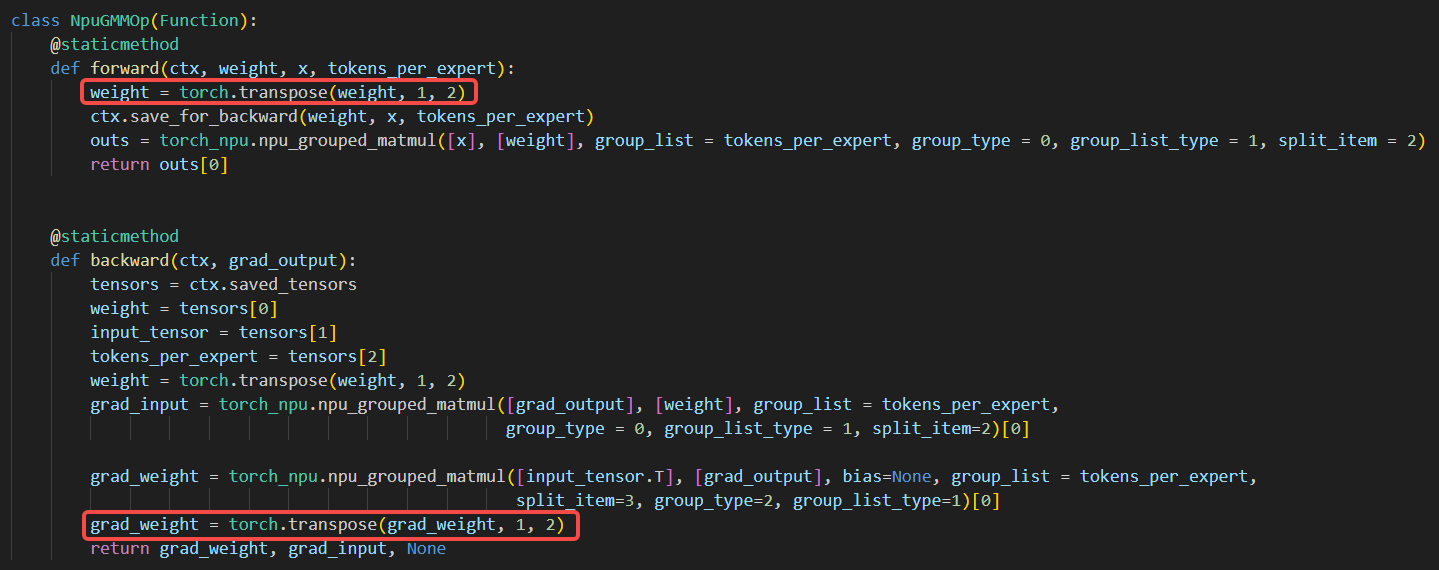
5.2 权重加载和切分逻辑修改
采用32机512die集群训练,FSDP2框架首先对专家进行切分,即4张卡共享一个专家。以四张卡为一组,xtuner框架的对于同一层、同一专家的MoE权重加载逻辑为:每张卡均加载down_proj权重;前两张卡仅加载gate_proj权重,后两张卡仅加载up_proj权重。随后四张卡对权重的out_feature均匀切分,如下,0和0’分别代表专家0的gate_proj和up_proj权重。 
all_gather时,对gate_proj和up_proj的out_feature进行合并,得到shape为(128,3072,4096)的weight参与GMM前向计算。即对权重的切分与合并均发生在out_feature。 为消除GMM前后的冗余transpose,我们在权重初始化过程中提前对out_feature和in_feature进行转置。 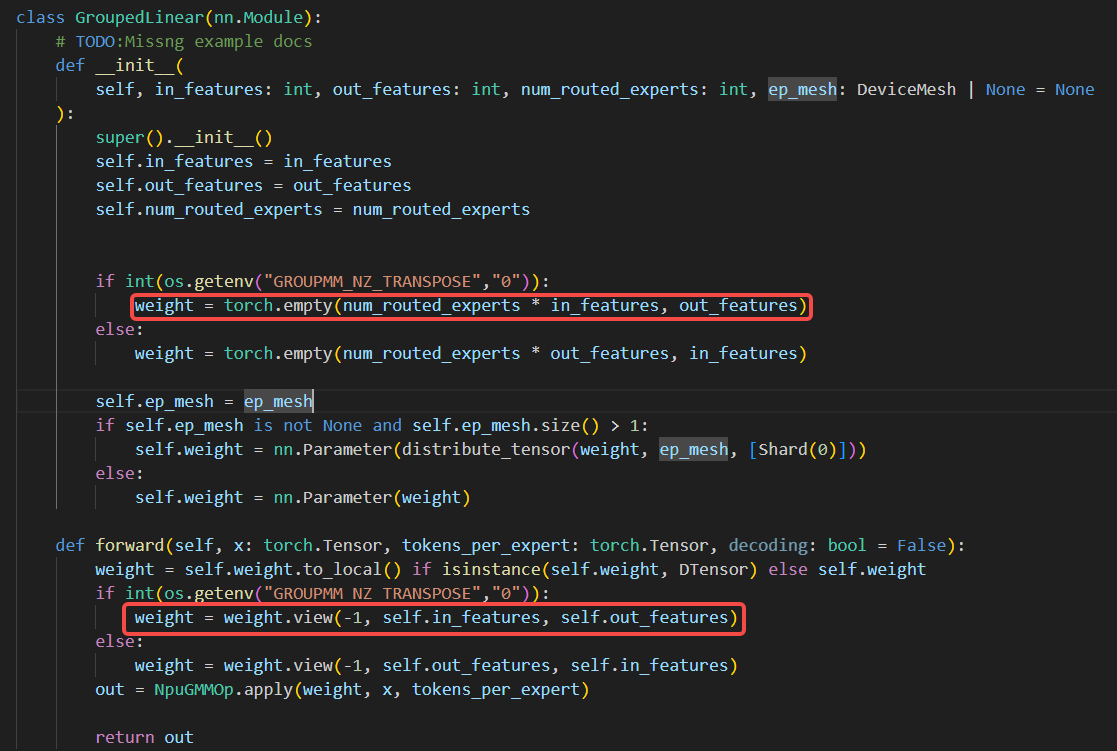
相应地,也需修改权重加载和切分逻辑,否则FSDP2框架将对gate_proj/up_proj的in_feature进行切分,而all_gather仍对gate_proj/up_proj的out_feature进行合并。结果如下,这一定会造成精度问题:
(1)单卡实际加载权重shape为(d_ff,d_model//4)=(1536,1024),和预分配内存shape(d_ff*2,d_model//4)=(3072,1024)不一致;
(2)0卡和1卡只加载gate_proj的in轴前1/4和1/4-1/2,2卡和3卡只加载out_proj的in轴1/2-3/4和最后1/4。即gate_proj和up_proj的权重各损失了一半。

因此,令同一专家组的四张卡均加载相同的gate_proj和up_proj权重,读取时即对out_feature进行合并,随后各卡按编号顺序切分in_feature,确保切分与all_gather 合并均发生在权重的in_feature。in_feature和out_feature转置视图下,修改后单卡加载结果如下。 
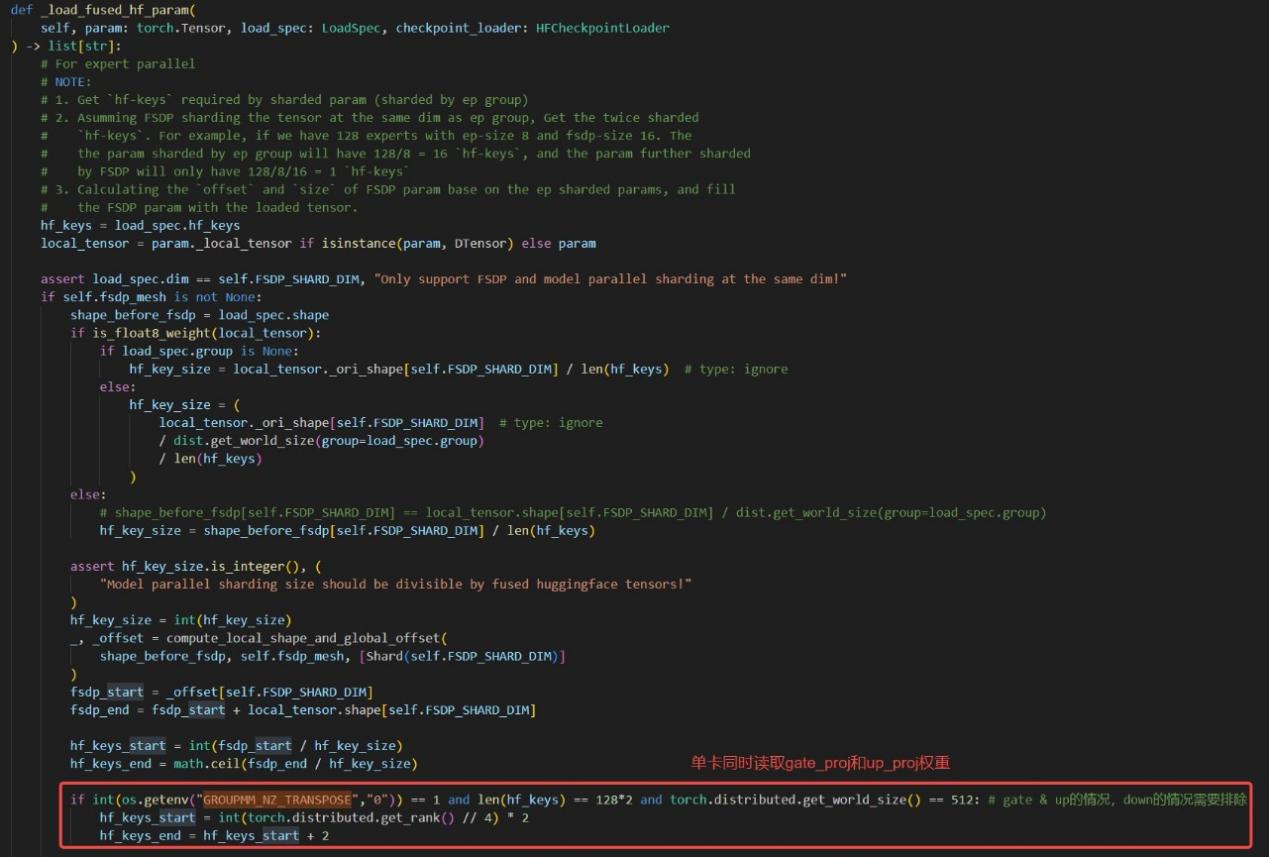
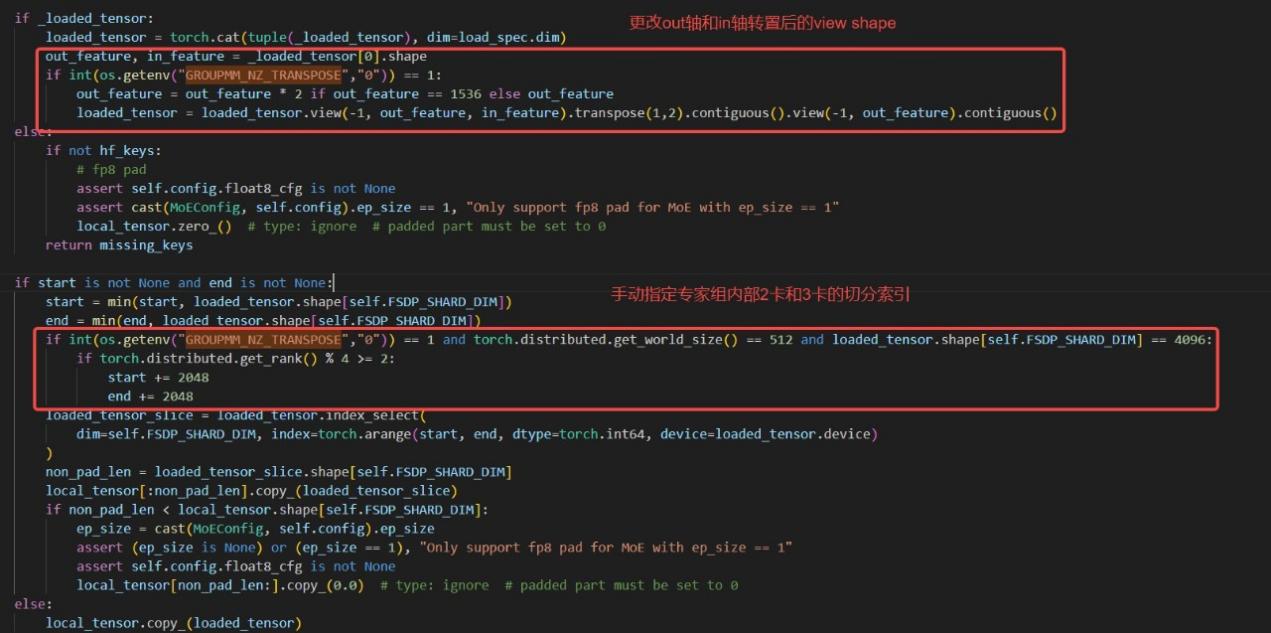
在xtuner框架的权重读取逻辑中,根据用户指定的FSDP shard参数确定每张卡从hf_keys中读取的MoE权重索引,其中hf_keys为单层所有专家的gate_proj和up_proj权重名List,形如 [...,"model.layer.0.mlp.experts.i.gate_proj.weight","model.layer.0.mlp.experts.i.up_proj.weight",...]。类似地,专家组内部的权重切分索引由start和end变量指定。
总结与展望
自Xtuner V1开源后,我们展开了进一步深入的工作,其中有意义的几件事:
1、通过sliceNZ和GMM NZ前反向使能,成功地在FSDP2上拿到了训练2%的性能收益,维持住了A3超节点相对H800的性能优势;
2、给出GMM NZ使能后消除transpose开销的办法:通过权重加载和切分逻辑适配;
3、走通了PTA接入自定义算子的流程。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









