



一、痛点和机遇
DeepSeek R1满血版(671B)模型在FP16精度下,权重大小达1.3TB,W8A8量化后的权重大小仍为700G+,300I DUO单机显存(384G)无法装载,若要加载FP16精度的模型权重至少需4台服务器。
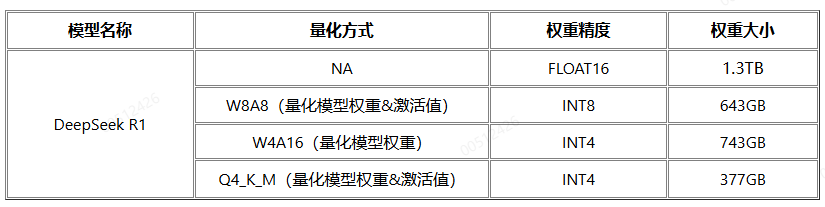
然而若使用多台300I DUO的服务器采用多机分布式的部署方式,如下图所示,由于300I DUO无物理网卡,跨节点通信需绕路CPU,性能和带宽瓶颈导致通讯受阻,实测仅700MB/s的带宽。
因此,如何在单机有限的显存资源下部署并运行满血版的DeepSeek-R1大模型成为挑战和机遇。清华大学的KTransformers开源项目,基于单机4090(24G VRAM)运行DeepSeek-R1 满血版,单路推理速度达14tokens/s,该项目通过CPU Offload,将部分GPU运算转移到CPU和DRAM进行计算,实现CPU/GPU异构推理,用内存代替显存,用INT8/INT4量化减少内存资源需求,为我们提供了不错的借鉴思路。以下实践我们基于KTransformers在300I DUO单机加载满血版DeepSeek-R1权重(HBM+DRAM),实现CPU+NPU的混合推理。
二、环境准备
2.1 NPU驱动:24.1.RC3
2.2 CANN版本:8.1.RC1

2.3 KTransformers版本:0.2.1

2.4 模型权重
FP16类型的原始权重文件需要1.3TB,需提前申请和挂载数据盘或大磁盘,我们采用W8A8的方式将其量化,量化后的模型权重大小约为643G。由于开源KTransformers推理框架使用的模型权重为GGUF格式,所以首先需要在框架代码中扩展Safetensor格式模型权重的加载方式。
三、适配和编译
由于开源KTransformers对ARM架构的支持度不高,社区发布的Release版本中的whl包也只有X86架构的,且社区源码面向的是NVIDIA的CUDA生态,因此需要在我们的鲲鹏和昇腾硬件上进行额外的代码修改和适配,包括编译脚本中增加GCC的ARM编译选项、删除ARM不支持的cpufeature三方库、CPU算子的适配、移除CUDA相关的依赖、Torch替换为Torch_NPU等,最终成功在我们的服务器(KunPeng + 300I DUO)上编译并安装完成。
四、推理服务启动
4.1 模型配置
修改model_path对应路径下的config.json文件配置(以下配置仅供参考):
{
"architectures": [
"DeepseekV3ForCausalLM"
],
"first_k_dense_replace": 3,
"hidden_act": "silu",
"hidden_size": 7168,
"intermediate_size": 18432,
"kv_lora_rank": 512,
"model_type": "deepseek_v3",
"moe_intermediate_size": 2048,
"moe_layer_freq": 1,
"n_group": 8,
"n_routed_experts": 256,
"n_shared_experts": 1,
"norm_topk_prob": true,
"num_attention_heads": 128,
"num_experts_per_tok": 8,
"num_hidden_layers": 61,
"num_key_value_heads": 128,
"num_nextn_predict_layers": 1,
"q_lora_rank": 1536,
"qk_nope_head_dim": 128,
"qk_rope_head_dim": 64,
"scoring_func": "sigmoid",
"topk_group": 4,
"topk_method": "noaux_tc",
"torch_dtype": "float16",
"transformers_version": "4.46.3",
"use_cache": true,
"v_head_dim": 128,
"vocab_size": 129280,
"...": ...
}
4.2 推理框架配置
KTransformers 最主要的设计目标是实现一套易用的基于模板规则的注入框架,允许开发人员很方便得用优化后的变体替换原始的Torch模块,我们修改optimize_rule_path对应目录下的注入规则配置(仅供参考):
- match:
class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding
replace:
class: ktransformers.operators.RoPE.YarnRotaryEmbeddingV3
kwargs:
generate_device: "npu"
prefill_device: "npu"
- match:
name: "^model\\.layers\\.(?!.*self_attn\\.kv_b_proj).*$" # regular expression
class: torch.nn.Linear # only match modules matching name and class simultaneously
replace:
class: ktransformers.operators.linear.KTransformersLinear # optimized Kernel on quantized data types
kwargs:
generate_device: "npu"
prefill_device: "npu"
generate_op: "KLinearTorch"
prefill_op: "KLinearTorch"
- match:
name: "^model\\.layers\\..*\\.mlp$"
class: ktransformers.models.modeling_deepseek_v3.DeepseekV3MoE
replace:
class: ktransformers.operators.experts.KDeepseekV3MoE # mlp module with custom forward function
kwargs:
generate_device: "npu"
prefill_device: "npu"
- match:
class: ktransformers.models.modeling_deepseek_v3.MoEGate
replace:
class: ktransformers.operators.gate.KMoEGate
kwargs:
generate_device: "npu:0"
prefill_device: "npu:0"
- match:
name: "^model\\.layers\\..*\\.mlp\\.experts$"
replace:
class: ktransformers.operators.experts.KTransformersExperts # custom MoE Kernel with expert paralleism
kwargs:
prefill_device: "cpu"
prefill_op: "KExpertsCPU"
generate_device: "cpu"
generate_op: "KExpertsCPU"
out_device: "npu"
recursive: False # don't recursively inject submodules of this module
- match:
name: "^model\\.layers\\..*\\.self_attn$"
replace:
class: ktransformers.operators.attention.KDeepseekV2Attention # optimized MLA implementation
kwargs:
generate_device: "npu"
prefill_device: "npu"
- match:
name: "^model$"
replace:
class: "ktransformers.operators.models.KDeepseekV2Model"
kwargs:
per_layer_prefill_intput_threshold: 0 # 0 is close layer wise prefill
- match:
name: "^model.embed_tokens"
replace:
class: "default"
kwargs:
generate_device: "cpu"
prefill_device: "cpu"
4.3 启动推理服务
设置CANN的环境变量,并启动KTransformers推理服务:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
python -m ktransformers.local_chat --model_path xxx --gguf_path xxx --optimize_rule_path xxx --max_new_tokens xxx --cpu_infer xxx
4.4 推理服务验证
以local chat的模式启动KTransformers,权重加载完成后,在终端会出现交互式的Chat界面,下图是推理请求的验证结果:

五、性能调优
在300I DUO单机上完成满血版DeepSeek的部署与启动之后,初始验证时在256输入和256输出,单并发的情况下,推理吞吐量只有0.1 tokens/s,该性能指标基本处于不可用的状态。为了进一步提升单机300I DUO上满血版DeepSeek-R1的推理性能,我们采取了一系列的性能优化手段,下面进行简单的方向性介绍。
5.1 CPU算子加速
KTransformers采用了高效的内核级优化技术,对模型中的关键操作进行优化,例如通过Intel AMX指令集优化以及引入cpufeature三方依赖,能实现更快的推理速度,但英特尔目前是唯一支持AMX 类似指令的CPU 供应商,且cpufeature仅支持X86架构,因此迫切需要在鲲鹏上实现CPU算子的加速。
我们对KTransformers中的llamafile算子进行了ARM上的扩展,基于鲲鹏的SVE指令集对GEMV(矩阵向量乘)以及GEMM(通用矩阵乘)实现了优化,配合鲲鹏CPU的多核优势使得卸载到CPU的MoE路由专家的计算速度较之前提升了50%+。
5.2 并行优化
KTransformers开源社区当前并未实现分布式并行策略,因此前文中提及的0.1 tokens/s的推理性能也是单芯上的测试结果。为了充分发挥我们服务器上4 * 300I DUO的算力,我们实现了张量并行(Tensor Parallelism, TP)的策略,在权重加载过程中根据TP_SIZE将权重切分到不同的Device,中间的计算结果通过torch.distributed的all_reduce、all_gather等集合通信算子进行规约或聚合,我们通过4卡8芯完成8TP的切分,推理的吞吐量也较之前有了较大幅度的提升。
5.3 算子下发优化
我们采用PyTorch Profiling接口对当前的性能瓶颈进行了采样和分析,通过MindStdio Insight可视化结果如下图所示:
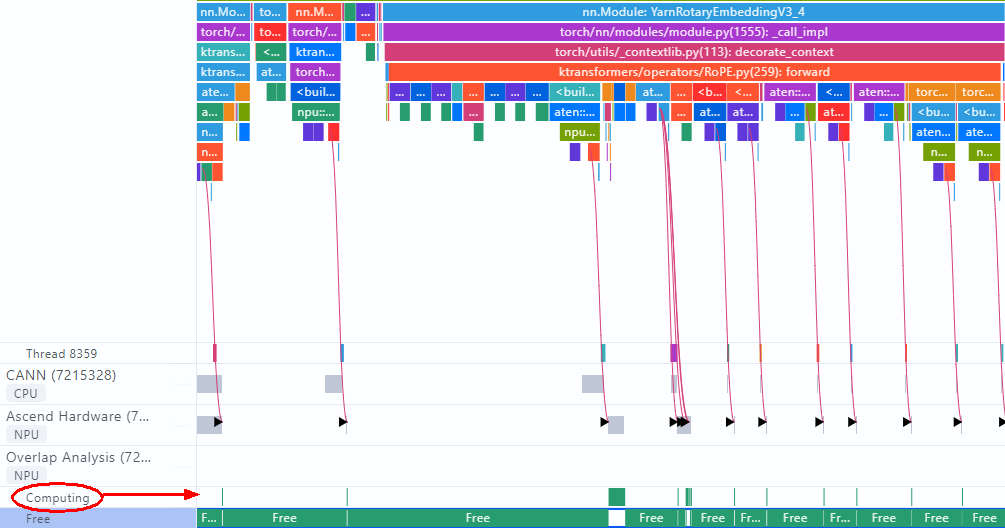
从采样结果看,Host侧和Device侧执行算子之间的连线为竖线,表示下发即计算,且Device为Computing状态的周期占比极低,Device空转周期长,这是非常典型的Host Bound现象,Host侧算子下发速度慢,其在模型单层的运行过程中耗时占比高。由于KTransformers中算子的调度和执行采用的是单算子模式,因此,我们采取了以下方式进行了算子下发时长的优化:
- 基于毕昇编译器LTO和PGO反馈编译、大页内存等技术,降低Cache Miss,提升Torch+TorchNPU的性能
- 根据算子任务的处理器亲和性,识别核心任务线程绑定在NUMA节点的固定CPU核心,减少核间切换的开销
- 使能task_queue算子下发队列优化,将算子下发任务分为两段,一部分任务放在新增的二级流水上,一、二级流水通过算子队列传递任务,相互并行,通过部分掩盖减少整体的下发耗时,提升端到端性能
- Pytorch和Torch_NPU的热点模块改造以及热点函数优化
5.4 融合算子
从5.3的采样结果看,除了Host Bound现象严重,另外的一个问题就是小算子众多,推理过程中算子下发的整个流程时延消耗高,因此我们通过将多个小算子功能融合,例如用torch_npu.npu_rms_norm算子来替换KTransformers中DeepseekV3RMSNorm的forward逻辑,当然,更多的融合算子我们正在尝试对接。
5.5 Overlapping
DeepSeek的模型结构如下图所示: 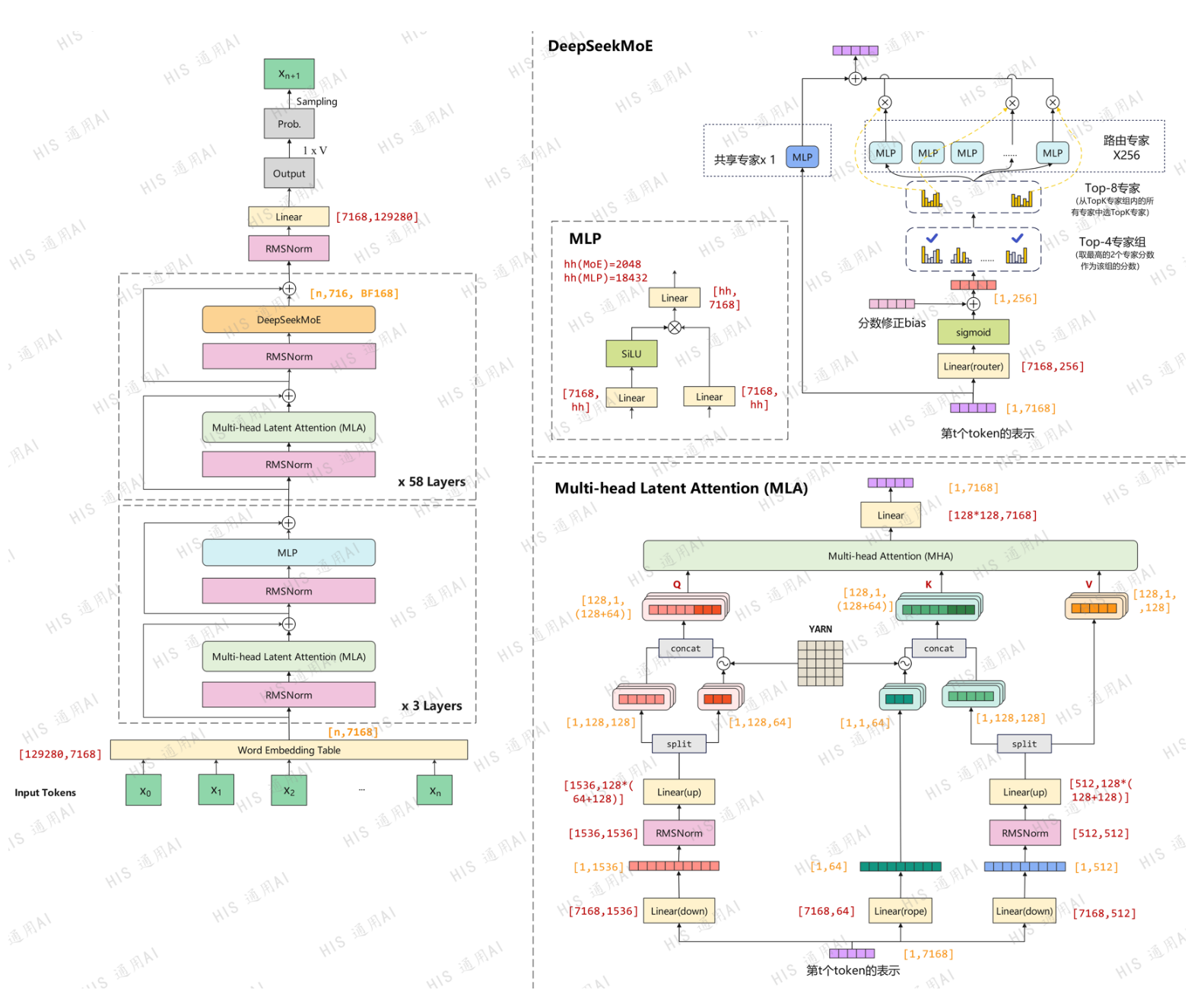
从DeepSeek的模型计算的拓扑流程中可以看出,部分节点相互之间不存在依赖关系,因此可以并发执行来优化推理时延。比如图右上角部分的DeepSeekMoE中,路由专家被卸载到CPU上进行计算,而共享专家MLP是在NPU上进行计算,两者所在的硬件计算资源不同,因此可以通过并行执行来实现计算时延的掩盖,将总体的时延从X+Y降低到Min(X, Y)。
5.6 硬件亲和性优化
鲲鹏的CPU采用NUMA(非统一内存访问)架构,CPU访问不同的内存节点时间差异很大,内存访问时延:跨片 > 跨NUMA节点 > 相同NUMA节点内,因此在业务层面上会表现为明显的性能差异。由于MoE的路由专家我们卸载到了CPU上进行计算,为了充分利用NUMA系统,避免跨NUMA访存带来的时延,我们编译KTransformers时指定USE_NUMA=1启用数据并行, 整个模型权重复制到内存中两次,即分别存入两个NUMA节点,当然这也会带来两倍的内存开销。
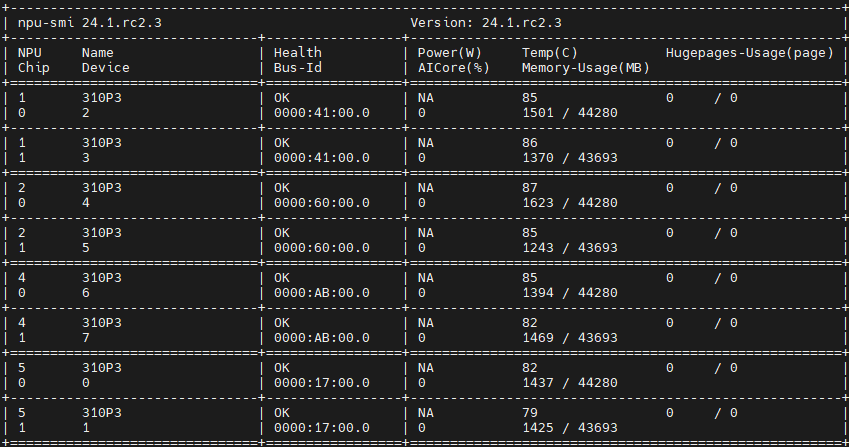
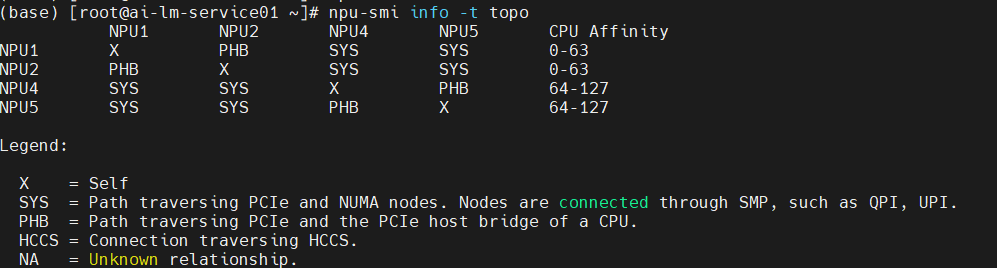
另外,除了CPU的NUMA亲和性外,CPU和NPU之间也存在亲和性关系,例如在我们的服务器上可以通过执行以下命令来查询设备CPU和NPU的亲和性关系、多NPU之间的拓扑结构。
npu-smi info -t topo
查询到的拓扑结构如下图所示,由于CPU卸载的缘故,需要进行Device侧和Host侧的数据拷贝,我们通过绑核操作,将所有任务绑定在NPU对应NUMA的CPU核心上,避免Device侧和Host侧跨NUMA 节点的内存访问,来提升推理性能。
5.7 性能优化结果
通过上述各项推理性能优化手段,在256输入和256输出,单并发的情况下,推理吞吐量优化到14.5 tokens/s,如下图所示:

六、总结和下一步计划
通过对KTransformers的代码在鲲鹏和昇腾硬件上进行适配,我们在300I DUO单机(384G显存+1T内存)上成功部署并运行满血版DeepSeek-R1,并通过一系列的推理性能调优手段,将单路并发的推理吞吐量从最初的0.1 tokens/s提升到14.5 tokens/s,提升了100+倍。KTransformers开源社区最新发布的0.2.4版本已支持多路并发,后续我们将引入多路并发的能力并持续提升推理性能,包括但不限于:
- MLA阶段算子融合或算子优化,降低Device侧计算时延
- ......


















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









