



1 背景介绍
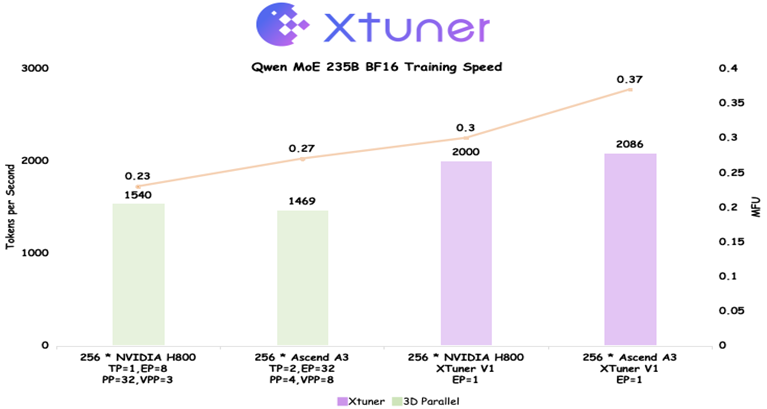
2025年9月8日,上海人工智能实验室开源书生大模型新一代训练引擎XTuner V1。XTuner V1 是伴随上海AI实验室“通专融合”技术路线的持续演进,以及书生大模型研发实践而成长起来的新一代训练引擎。相较于传统的 3D 并行训练引擎,XTuner V1 不仅能应对更加复杂的训练场景,还具备更快的训练速度,尤其在超大规模稀疏混合专家(MoE)模型训练中优势显著。具体信息参考【1】
为了进一步挖掘 XTuner V1 训练方案的上限,实验室研究团队与华为昇腾技术团队在 Ascend A3 超节点上进行联合优化,充分利用超节点硬件特性,FSDP2首次在Qwen 235B MoE上实现了相比传统3D并行更高的 MFU(Model FLOPS Utilization,模型浮点运算利用率)。在理论算力落后 NVIDIA H800 近 20% 的情况下,最终实现训练吞吐超过 H800 近 5%,MFU 反超 20% 以上。
本文第一章节分析Qwen 235B模型,并对比FSDP2与Megatron 3D并行的优势和劣势。第二章介绍FSDP2训练Qwen-235B大模型的性能调优方案。第三章介绍了GroupedMatmul开启NZ的方案设计。第四章对全文的优化点进行了总结。
1.1 Qwen3 MoE模型
Qwen3-235B模型基于GQA,每层128个路由专家,激活Top 8个,不含共享专家。相比deepseek R1、step3、minimax01等其他几百B量级的MoE模型,235B的模型结构层数最多(94层)、专家最小(moe_intermediate_size:1536)。

1.2 训练框架对比
目前训练大参数量MoE模型比较成熟的方案是Megatron的3D并行,通过使能PP、TP、EP并行,将模型的参数量切分到不同的卡上。相比于FSDP2需要每层对完整的模型参数进行allgahter,Megatron 3D并行的方案通信量更小。然而Megatron 3D并行需要对模型代码进行侵入式修改,对算法研究者来说,开发难度较大。且PP、TP、EP等并行超参均需要经过细致地调优才能达到最好的效果。而FSDP2虽然通信量较大,但是开箱即用,同时借助A3超节点的通信优势,FSDP2的通信可以做到绝大部分场景都被计算掩盖。

1.3 FSDP适合场景预测
FSDP 会将参数均匀地切分在每张卡上,在模型的第 i 层计算时,会提前聚合第 i+1 层的参数,当第 i 层计算结束后,会将第 i 层的参数重新切分回每张卡上。这种模式极大地节省了模型参数占用的显存,但也增大了通信量。理想的通算掩盖,需要通信耗时比计算耗时短。

Qwen3 235B每层参数量为2.3G,bf16,则每次通信负载为4.6GB。以16k序列长度为base,每层计算量为6.22Tflops。我们假设通信带宽利用率0.8,昇腾计算MFU 0.4,H800计算MFU0.3,可以得出在不同芯片下的耗时表格预测:

从上表可以看出,对于超大模型MoE训练场景+FSDP2的组合配置下,A3超节点是一个比H800/H200更具有场景普适性的硬件:
- H800的通信受限于RoCE带宽。即使计算序列长度延伸到64k,bf16下也无法完全掩盖通信,需要基于FP8+64k序列长度,才有可能做到较好的通信掩盖比。
- 超节点可以在16k序列长度下完全掩盖通信。在16k及以上场景,可以综合内存、cube和vector比例联合优化。
2 优化方案
2.1 通信性能分析与优化
总结:
-
NPU在通信地址非512对齐场景下,通信会严重劣化。每层Allgather的参数量包含了RMSNorm和gate,一般做不到512对齐。
-
通过使能TORCH_HCCL_ZERO_COPY特性,或者修改fully_shard的策略使切分后的参数量仅包含linear,可以解决这个通信地址512对齐的问题。前者的hccl buffer size可以根据通信量/16配置,235B MoE下配置为512MB,比较节约显存;后者的hccl buffer size需要权衡通信效率和显存大小,一般配置为1024MB。
-
通信时延不符合预期时,排除了通信地址非512对齐情况后,可能大概率是由于计算负载不均衡导致。
2.1.1 开箱情况
开箱通信性能不及预期,在8层32die16K序列长度场景下,发现每个block未被掩盖的通信耗时占比70%。

Allgather一层参数的平均耗时达到127ms左右。
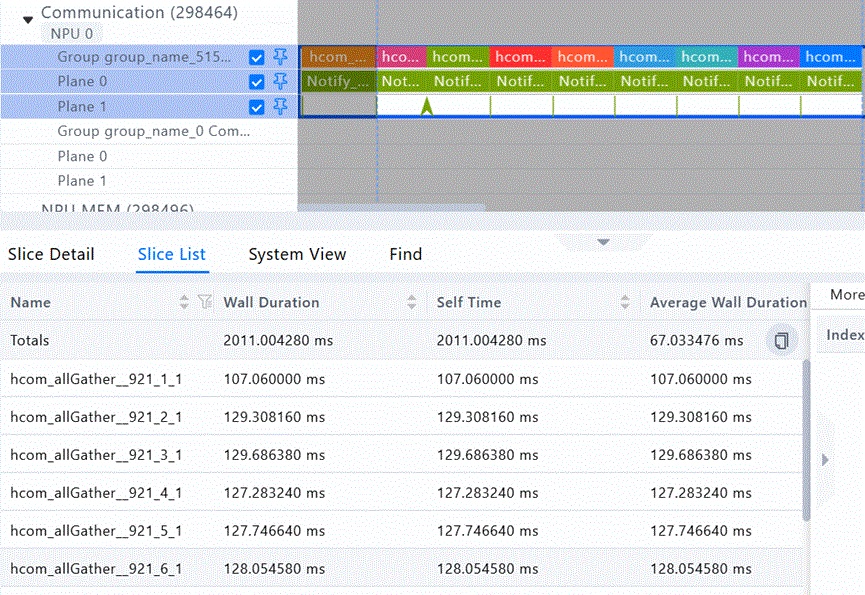
图 开箱时的allgather耗时
A3超节点的allgather理论耗时按1.3节测算,应该是29ms,实测的127ms显然远超了理论耗时,需要定位。
首先怀疑了是否机器是否有硬件问题,通过通信打流工具验证了机器的实际带宽是符合预期的:

2.1.2 通信地址是否512对齐对性能的影响
某企业的使用场景使用fully_shard对一个TransformerLayer进行包装,allgather发送的数据量是一层的参数量/DP,接收的数据量是一层的参数量*(DP-1)/DP,一般按接收数据量评估通信耗时。由于LayerNorm等参数量较小,经大DP切分后导致allgather输入非512对齐。怀疑到通信地址不对齐可能导致通信效率下降后,构造如下脚本进行allgather的单算子验证:
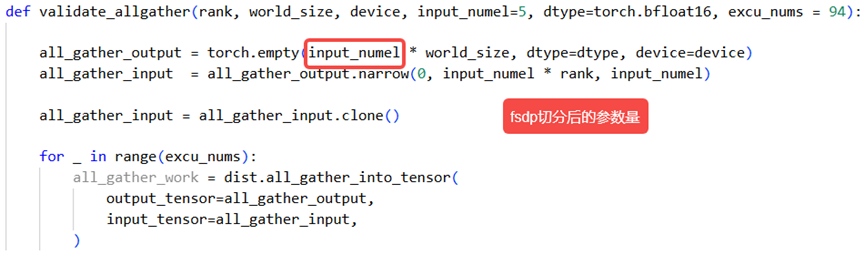
单算子验证结果如下:

可以看到,在通信量相差不大的情况下,allgather输入通信量非512对齐时,性能裂化接近一倍。进一步确认,影响通信效率的直接原因不是通信量不对齐,而是通信首地址不对齐。这里的场景,由于allgather通信量很大,远超默认的HCCL_BUFFER大小(200M),集合通信算子会拆包传输,由于小包的大小可能不对齐,进而导致后序包的内存起始地址不对齐。尝试了两个方案都可以解决这个问题,考虑到内存的约束项目中最终采用方案二。
2.1.3 解决方案1:修改fully_shard切分,仅切分linear
既然切分之后的参数量非512对齐对性能的影响较大,是否可以将参数量裁剪或者补齐成512对齐的?经过分析,Qwen-235B一层的参数量计算如下:

模型中大部分参数按DP(512)切分后仍是512对齐的,仅仅是由于Norm等小参数切分后不对齐,引起了通信效率裂化严重,但内存节省较小,可以考虑不对这部分小参数进行FSDP切分。
将gate_param和norm_param加入layer的FSDPParamGroup中,容易导致该group通信参数量不能被512整除。而linear层因为head_dim=128, hidden_size=4096, 所以切分后能被512整除。Gate和norm的参数量仅占一个layer参数量的0.1%,所以不切分的话也不会造成显存瓶颈。或者可以把所有层的norm和gate都放到一个额外的FSDPParamGroup中。对于大多数的大模型来说,linear层的in_feature和out_feature都是一个对512比较友好的数值,因此该方案在别的模型上也有较好的可行性。
经过修改之后8层32die16k序列场景下,allgather的平均耗时下降至35ms,与理论值比较接近。
2.1.4 解决方案2:HCCL零拷贝技术
单算子模式下算子的输入输出buffer是动态变化的,为了避免每次通信都进行两端进程的内存注册,HCCL在通信域内部构造了一个buffer进行中转完成集合通信,因此会引入额外的内存拷贝开销。每个通信域占用“2*HCCL_BUFFSIZE”大小的内存,分别用于收发内存。针对集合通信算子,当数据量超过HCCL_BUFFSIZE的取值时,可能会出现性能下降的情况,建议HCCL_BUFFSIZE的取值大于数据量。
使能HCCL零拷贝技术后,HCCL可以直接对业务传入的内存进行操作,避免使用中转HCCL buffer,仅跨A3节点的通信使用HCCL_BUFFER。而全域512die的allgather、reducescatter通信是分层实现的,例如Allgather可以先做节点间同号卡的allgather、再做节点内16die的allgather。那么配合HCCL零拷贝技术,我们将HCCL_BUFFER配置为Allgather通信量的1/16(即4.6G/16≈288M)即可以一次性完成通信,同时也避免了通信地址非512对齐带来的通信裂化。该功能可以直接通过以下环境变量开启:
export TORCH_HCCL _ZERO_COPY=1
同时该环境变量依赖虚拟内存管理功能,需要开启以下配置:
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
开启该环境变量后,allgather的耗时可以符合理论带宽预期。
注:该特性630POC、预计930商用。
2.1.5 潜在负载不平衡问题
16k序列长度下性能优化到符合预期后,我们进一步增加序列长度到32k,且扩展256die到512die,又出现了通信性能劣化的问题。实验现象如下:

由于此时已经开启了async activation offload,所以针对是否开启offload、卡数和序列长度都进行了消融实验。在16k序列长度下,耗时没有发生明显的劣化,而序列长度增加到32k后,出现了严重的劣化问题,同时DP域越大,劣化越明显。由于在FSDP训练策略下,每张卡计算的序列长度完全一致,所以在测试了强制专家负载均衡对性能没有显著影响后,一直没有怀疑是计算量不一致导致的快慢卡问题。反而在HBM带宽抢占的探索中走了不少弯路。
最终采集了512die所有的profiling,通过工具排查后,发现是所有的device都在等待rank 132的计算,进一步拆解计算性能后。发现一个block大部分rank的FA前向计算耗时不到5ms,而rank132的FA前向计算耗时达到100多ms。通过拆解客户的数据加载逻辑发现,使用了不同长度的训练语料,pack成16k或者32k的序列长度,FA部分通过TND layout传入不同的actual_seq_len实现。在不同的拼接场景下,会出现有的rank分配到大量短序列,有的rank分配到少量长序列。这两种情况下FA的计算量是完全不同的。示意图如下(填充部分表示计算量):
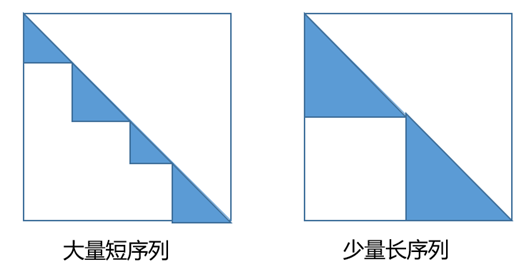
在某企业的代码中,插入每个rank计算量(isi2/2,其中si表示拼接的第i个短句子长度)统计的代码,统计512die场景下,每个rank FA计算量的最大值和最小值,最终统计的结果如下:

存在少量step中,某几个die上FA计算负载特别大的情况。拼接序列越长、DP域越大,FA负载不均衡的现象会越明显。除此之外,我们的FA对shape比较敏感,即使理论计算量相似,actual_seq_len不一样,也会导致计算耗时的偏差,无法做到完全均衡。
根据上述统计,某企业拼接的句子存在负载不均衡,不均衡程度平均值大约在1.3,平均句子长度为80。根据FA计算量反推,相当于负载均衡时平均长度为120的短句子拼接。本文所有系统性能基于此数据分布测试,剔除了个别极不均衡的特例(max/min >100)。
2.2 显存建模与优化
FSDP2下显存优化重要配置:
-
export MULTI_STREAM_MEMORY_REUSE=2 -
async swap activation,offload激活显存
2.2.1 开箱情况
16k序列长度512die开箱后,发现显存频繁触顶,导致出现大量free耗时,端到端耗时达到100s +,且memory active曲线和memory allocated曲线出现分离,说明存在跨流使用的内存没有被及时复用。
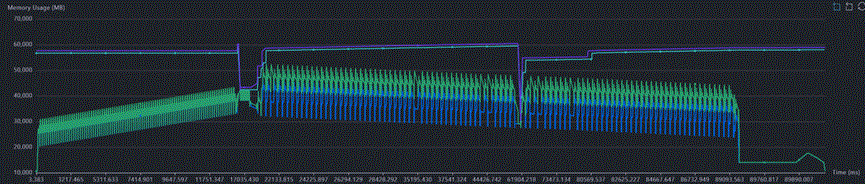
2.2.2 跨流内存未及时释放
FSDP2会对通信进行prefetch,每一层的计算跟下一层权重的通信互相掩盖,产生大量的计算、通信并行,导致Active内存远超Allocated,进而导致训练实际分配的内存远超理论预期,现象如下:
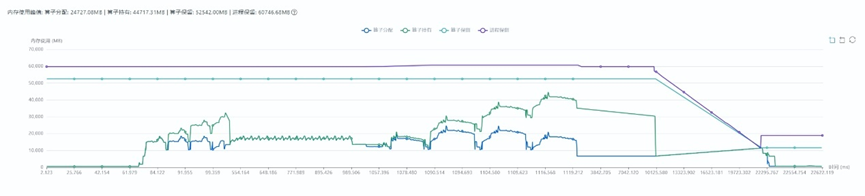
PyTorch跨流内存复用问题可以参考:https://dev-discuss.pytorch.org/t/fsdp-cudacachingallocator-an-outsider-newb-perspective/1486。
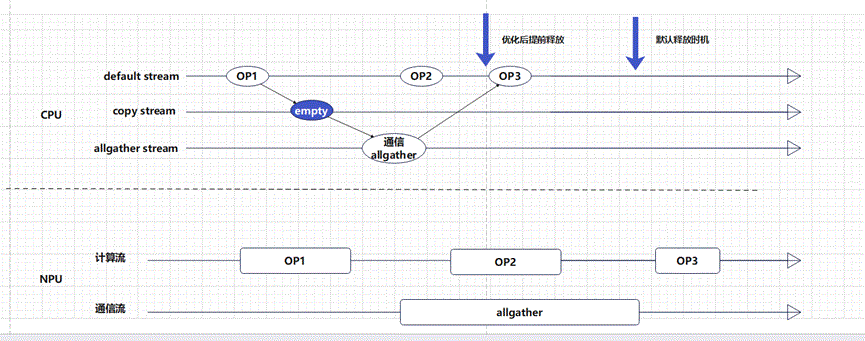
PyTorch允许在多个流上访问同一个Tensor内存,为了保证数据安全性,通过recordStream方法标记内存块被哪些流使用,在Host查询到Event Record任务完成后将内存块还给内存池并允许复用。这意味着内存块允许复用的时机依赖Device的执行速度,但在大模型训练场景,Host执行通常快于Device,这会引起跨流使用的内存无法及时释放,导致active内存显著增加。
针对这种问题,Ascend Extension for PyTorch(PTA)中对异步(async_op=True)的AllGather、ReduceScatter等通信算子、以及dropout genmask等多流计算算子进行了优化,通过在下发wait()时擦除recordStream的标记,解除了这部分内存复用对异步通信算子执行的依赖,提升内存复用效率、降低内存峰值,通过export MULTI_STREAM_MEMORY_REUSE=1使能,当前版本已默认生效。

但eraseStream方案并不能优化FSDP2的场景,FSDP2中减少了recordStream的使用,对参数、梯度的AG、RS均使用同步(async_op=False)的通信算子,而且通过单独的流下发来实现异步。为了优化这种场景的跨流内存复用,PTA中提供了Avoid recordStream的方案,不再实际调用recordStream,通过延长Tensor的生命周期至handle.wait()处保证内存块被使用完成后还给内存池。FSDP2中通过event的record/wait保证该流上无其它内存申请操作与集合通信算子并发,保障了数据准确性,NPU上通过export MULTI_STREAM_MEMORY_REUSE=2使能,在该模型中降低峰值内存7G+。

2.2.3 显存建模
解决了多流复用的问题之后,在16K序列长度94层依然存在显存触顶问题。48层实验中每层未被掩盖通信占比小于1%。为了进一步提高训练的吞吐,希望可以进一步增大序列长度。
通过增大序列长度来增大每个block的计算量,有以下好处
- 每层的通信量是和每层参数量相关,增大计算的序列长度可以减少未被掩盖的通信占比
- FSDP2在allgather了所有的参数之后,会进行一个copy_slice操作,这部分的耗时也只与模型参数量相关,增大序列长度可以减少这部分操作耗时在计算中的占比。
然而单die仅64G显存,想要进一步增大序列长度显存还是十分捉襟见肘。在512die16K序列长度下,显存建模如下面的图表所示。
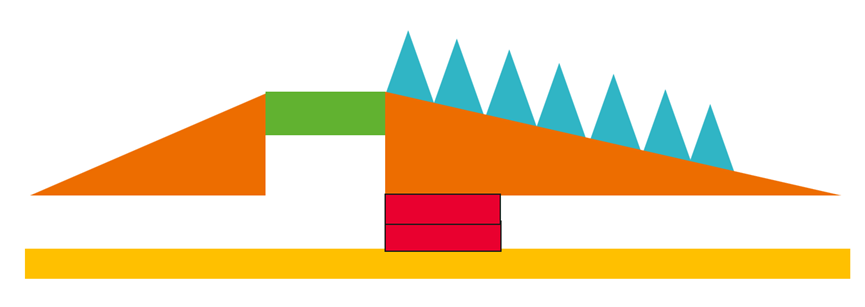
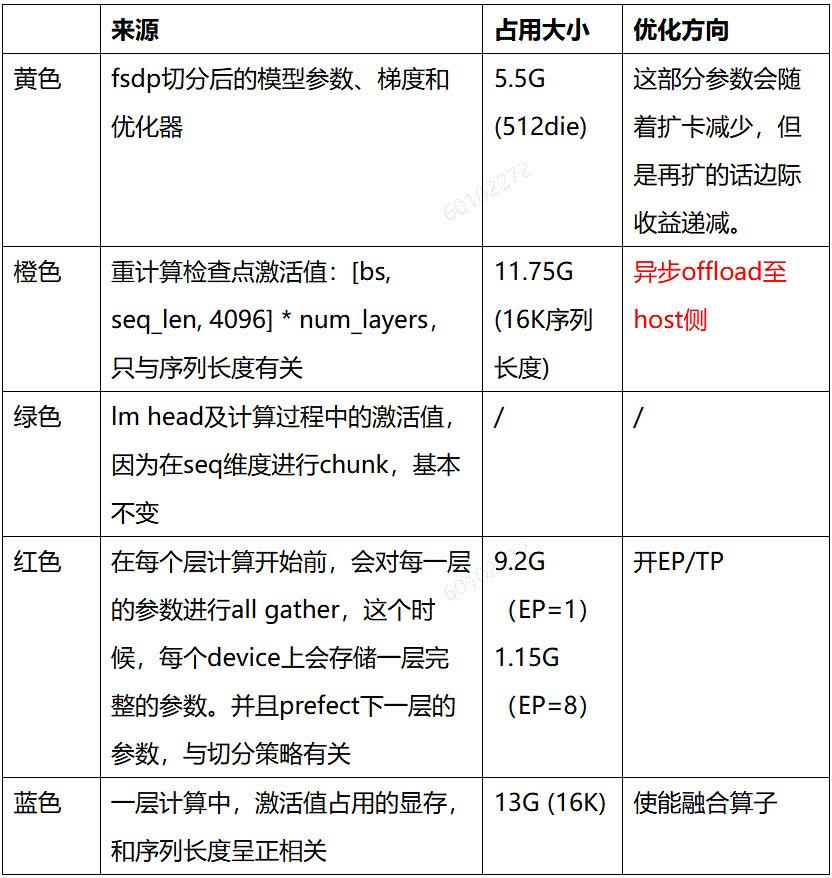
FSDP对模型参数、优化器和梯度进行切分之后,这部分占用的显存已经不多,再进一步扩大切分数量的话,收益并不明显。在Lm_head + 交叉熵损失的计算中,由于词表的维度比hidden_dim要大得多,此处容易造成一个显存尖刺。这里XTuner参考Liger-Kernel 中的做法,开发了一套可以支持多种训练场景和多种硬件的自动 Chunk Loss 机制,激活沿着序列的维度进行切分,每一小块计算完前向后直接计算反向,因此此处的显存占用不随序列长度改变。为了实现通算掩盖,FSDP2在当前层计算时,会prefetch下一层的参数,因此当前时刻会存储两层的模型参数。
综上所述,反向的第一个block计算完成重计算前向时,显存占用达到峰值,此时显存主要包含:fully shard切分后模型、梯度和优化器,94层重计算检查点的激活值,allgather的模型参数和一层完整计算的激活值。占比较高的是94层重计算检查点的激活值和一层完整计算的激活值。
因此,在显存优化部分,主要开发了Async swap activation方案。
2.2.4 Async swap activation方案
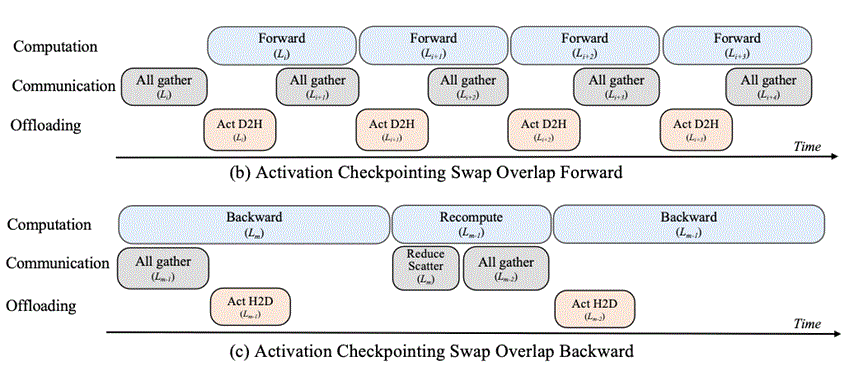
该方案异步将每层重计算的检查点offload到Host侧,在反向计算时,基于前向存储的offload顺序,在当前层计算时,提前将下一层需要的激活值prefetch至device侧。
实验结果
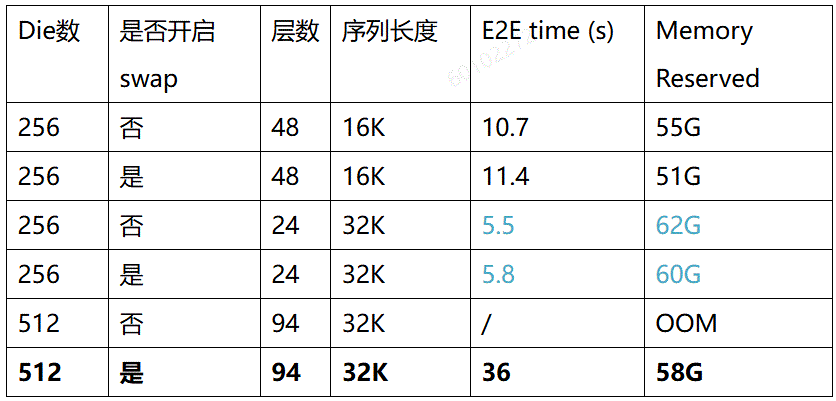
从实验结果可以看出,开启async swap activation后,由于较好的异步策略和较大的H2D D2H带宽,该操作没有对端到端性能产生太大的影响。同时实现了512Die跑下32K序列长度,相比于原来的8K序列长度不开swap,TGS从1100提升到了1820。
Profiling
94层512die 32K序列长度下Memory Profiling

TimeLine如下图所示,红色表示计算,绿色表示swap,蓝色表示通信,可以看出通信和swap activation都完全被计算掩盖


使用方式
这部分方案直接复用了MindSpeed MM中的async offload方案,与模型代码进行了解耦,可以比较方便地复用这套方案。
mindspeed_mm/utils/async_offload.py · Ascend/MindSpeed-MM - 码云 - 开源中国
调用方式如下:
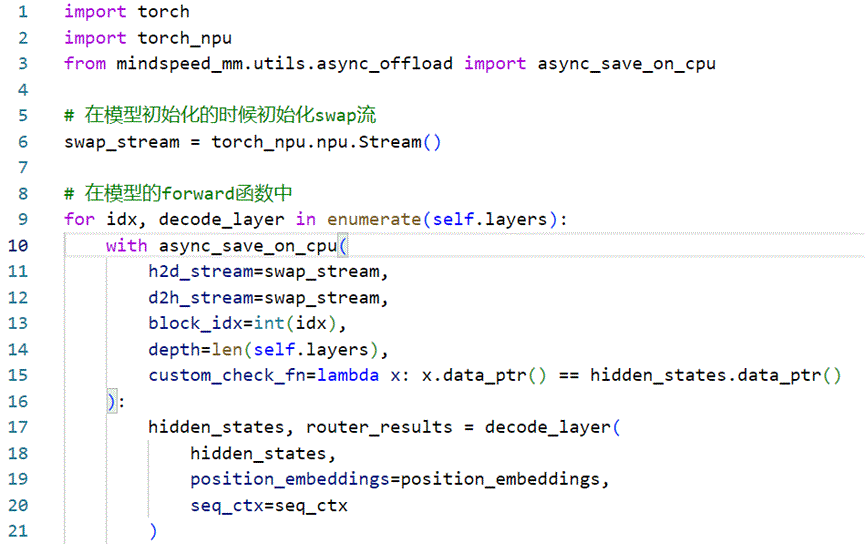
参数说明:
- h2d_stream / d2h_stream: 执行swap操作的stream,一般不用通信和计算的流,单独创建一条流,实现异步操作
- block_idx: 当前layer的编号,前向计算时该函数会在i+1层开始计算的时候触发第i层激活值的H2D。反向计算时,会在第i+1层计算时,触发第i层的D2H。
- depth:模型总层数
- custom_check_fn: 可以自己定义校验函数,满足该校验函数的激活值才会被offload。
2.3 计算优化
以下优化点按增益从大到小排列,每个点增益约从3%到0.5%。
2.3.1 Index select操作换成NPU亲和的API
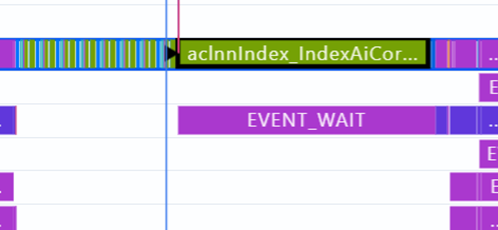
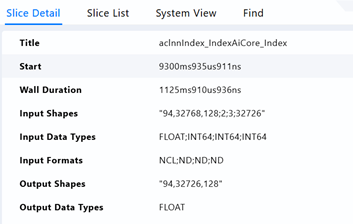
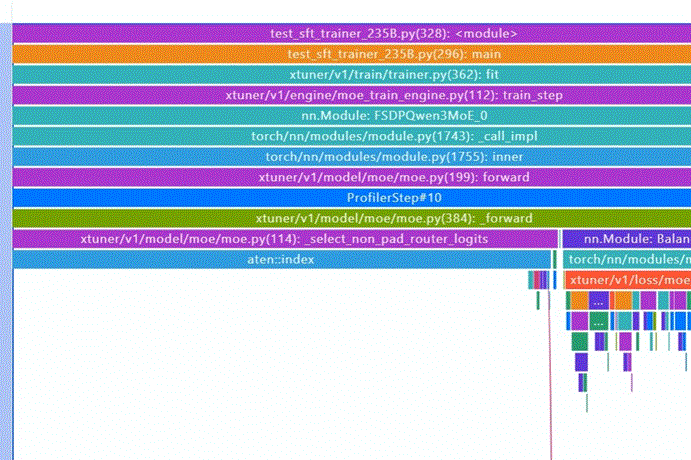
在计算loss的地方,发现一个耗时长达1125ms的indexAiCore算子,查看调用栈找到这个操作的调用位置。由于训练的序列是由多个子序列拼接而成,难免最后会出现需要pad的情况,而在计算专家负载均衡损失的时候,需要删除pad的部分。
源码为:
router_logits = router_logits[:, attn_mask].contiguous().float()
这个使用方式对NPU不友好,可以等效替换为:
indices = torch.nonzero(attn_mask, as_tuple=True)[0]
router_logits = torch.index_select(router_logits, 1, indices).contiguous()
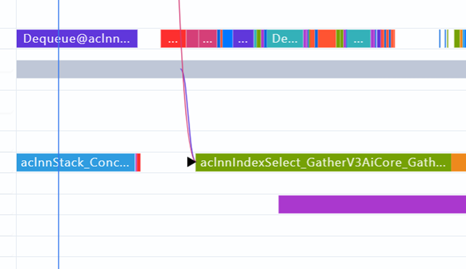
替换完成后,此处执行变成IndexSelect_GatherV3,耗时仅2.5ms。整网收益1000ms。
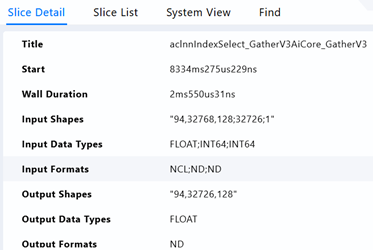
2.3.2 优化器使能foreach
optimizer.step的过程存在大量下发,耗时接近1s,考虑通过使用foreach实现减少下发,优化性能
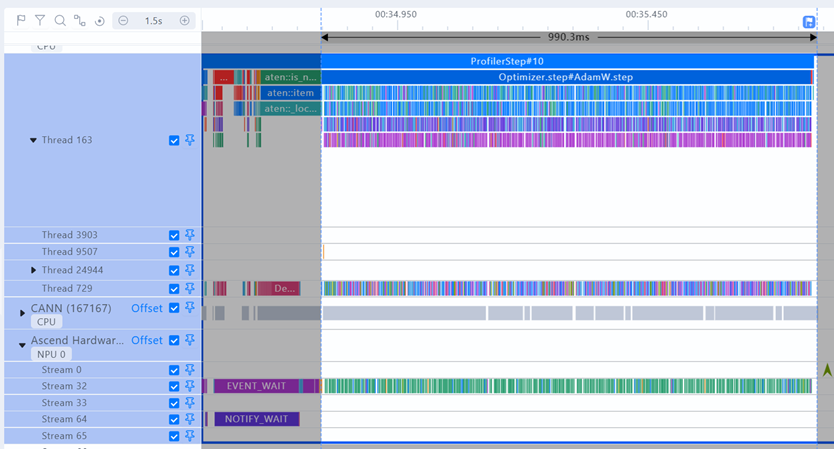
Torch的优化器默认使用For-loop实现,它会遍历每一个参数,对每一个参数单独进行更新。这种方法的效率很低,尤其是在处理大量参数的时候,因为每个参数更新的操作是逐个进行的。而foreach将多个参数的更新操作批量化,从而减少下发的开销和提高访存效率。可以通过下面的方式开启:
Optimizer = torch.optim.AdamW(params, lr=lr, betas=betas, eps=eps, weight_decay=wd, foreach=True)
然而在fsdp2框架中尝试开启foreach后,出现如下报错:
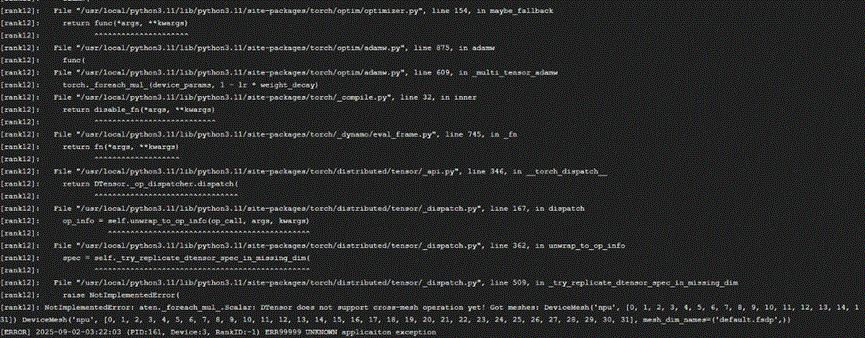
大致的意思是,FSDP2的模型参数和梯度都是DTensor数据结构,但是_multi_tensor_adamw不支持DTensor数据结构。DTensor是torch.Tensor的子类,实际执行计算的,都是DTensor._local_tensor这个变量,由于优化器中不涉及任何并行通信操作,所以考虑将DTensor._local_tensor传到优化器中去。
所以考虑patch优化器的init_group函数,判断param和param.grad的类型是否是DTensor,如果是DTensor,则传入param._local_tensor和grad._local_tensor.
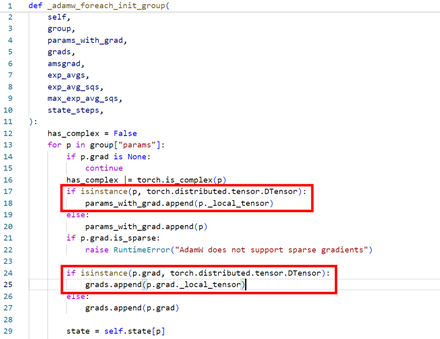
使能foreach之后

optimizer.step处下发大大减少,耗时优化至94ms。
整网端到端耗时优化940ms。
2.3.3 GroupedMatMul算子优化
1)GroupedMatmul基本块大小调整
GroupedMatmul算子内部实现是通过将输入输出矩阵通过切分为一块块小的基本块,再分配到各个物理核上进行计算。在这个过程中,基本块的分块逻辑会直接影响算子执行效率。
A3设备L0C大小为128KB,即应当满足baseM * baseN * sizeof(FLOAT32)< 128KB。GMM中的做法是将baseM设置为128,baseN设置为256。这样右矩阵搬运的时候首地址是512B对齐,搬运效率较高。这部分可以进行动态调整,优化后的策略为:当左矩阵搬运量比右矩阵更大时,可以设置baseM为256,baseN为128从而优化左矩阵搬运效率,实测反向的其中一个shape可以优化5%,每个block可以优化1ms。
2)GroupedMatmul Cache策略细化
通常情况下,算子的输出应当放到L2Cache中,这样后续算子如果需要使用到这部分数据,可以从L2Cache中直接进行获取以提高带宽效率,但是将数据搬运至L2Cache的过程也是有时间损耗的。
通过分析现场GroupedMatmul算子的profiling,发现算子L2Cache的利用率较低(70~80%)。具体分析内部原因,发现输出的矩阵乘结果较大,已经超过了L2Cache的大小,这块影响输入数据的L2Cache利用。而且当输出矩阵较大时,后运算完成的输出矩阵也会将先运算完成的输出矩阵从L2Cache中换出,这样即使后续算子需要使用到这部分数据,也不能正常通过L2Cache获取。
通过SetL2CacheHint接口可以将GlobalTensor使能跳过L2Cache的Cache策略。GMM中当输出矩阵超过L2Cache大小时,我们认为将输出矩阵放入L2Cache中是纯纯的劣化。
现场修改GMM分块及Cache策略之后,GMM算子均有小幅度优化,现场穿刺整网收益350ms左右。
2.3.4 多余的transpose删除

在RotaryEmbeding前后发现各有一次transpose操作。输入在经过proj之后,layout是[b, s, n, d],此处客户的逻辑是转置成[b, n, s, d],然后计算RotaryPositionEmbedding,完成计算后再转置成[b, s, n, d]。而npu融合算子torch_npu.rotary_mul支持[b, s, n, d]输入,因此可以删除这两个转置,整网收益940 ms。
2.3.5 QoS调优
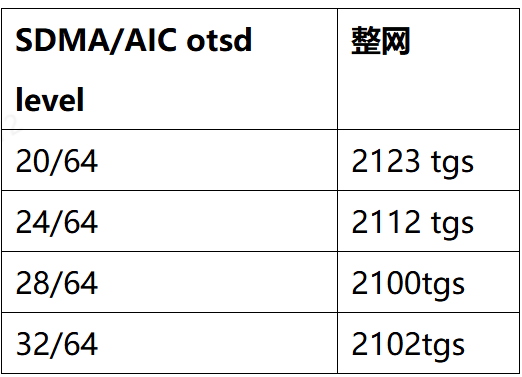
在训练的过程中,计算和通信是并行的,会导致HBM带宽抢占。通过调整otsd可以调整加速器访问HBM的能力,otsd越大访问HBM的带宽突发能力越强。
otsd配置方式(调整otsd参数):
./qos_tool --set=otsd --dev-id=0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 --master=13 --otsd-mode=1 --otsd-level=32
在默认配置下,SDMA otsd level时32,AIC的otsd level是64,在该场景下,希望将计算的优先级调整得高一些,因为通信的耗时已经可以被掩盖,且计算如果有带宽竞争导致的快慢卡,会加剧通信的notify wait。下表为该235B模型allgather reducescatter通信和计算并行场景,调整SDMA的ostd leval的实验记录。
第三、四、五章内容详见:超节点FSDP2训练MoE大模型昇腾联创设计(下)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









