




 雾度会降低图像质量,影响户外场景可见性。本文探索CNN,提出基于感知金字塔深度网络的多尺度图像去雾方法,采用编码器 - 解码器结构,用密集块构造编码器,解码器基于残差和密集块及金字塔池模块。除均方损失外,还用基于VGG - 16的感知损失学习网络权重,训练和推理用多尺度patches。
雾度会降低图像质量,影响户外场景可见性。本文探索CNN,提出基于感知金字塔深度网络的多尺度图像去雾方法,采用编码器 - 解码器结构,用密集块构造编码器,解码器基于残差和密集块及金字塔池模块。除均方损失外,还用基于VGG - 16的感知损失学习网络权重,训练和推理用多尺度patches。
论文:Multi-scale Single Image Dehazing using Perceptual Pyramid Deep Network
作者:He Zhang
年份:2018年
期刊:IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops
代码
摘要
雾度降低了图像的质量,从而影响了其在户外场景中的美学吸引力和可见性。大多数现有的工作,包括最近基于卷积神经网络(CNN)的方法,都依赖于经典的数学公式,其中去雾图像被建模为衰减的场景辐射度和大气光的叠加。本文探索CNN,以直接学习去雾图像和相应的清晰图像之间的非线性函数。本文基于最近流行的密集块和残差块,使用感知金字塔深度网络提出了一种多尺度图像去雾方法。所提出的方法涉及一种编码器-解码器结构,其中使用密集块构造编码器,并且解码器基于一组残差和密集块,然后是金字塔池模块以合并上下文信息。 除了均方损失外,还有基于VGG-16的感知损失用于学习网络权重。 为了进一步提高性能,在训练(training)和推理(inference)过程中使用了多尺度patches。
方法
网络结构
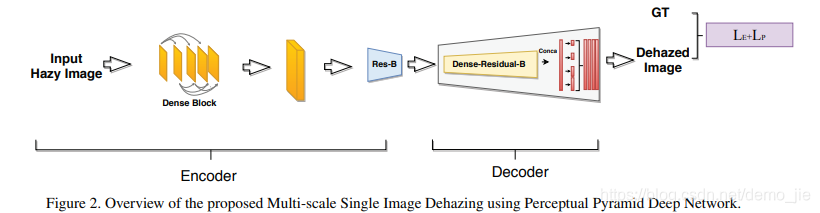
图2说明了所提出的基于CNN的多尺度单图像去雾框架的概述。该编码器接受输入的雾图像并将其映射到潜在空间(中间特征图),解码器将潜在空间映射到相应的清晰无雾图像。
本文的工作与[Densely connected pyramid dehazing network]的工作密切相关,但有一些重要的区别:
(i)另一种方法将传输图估计作为中间步骤,本文直接学习有雾图像与其相应的清晰图像之间的非线性映射 。
(ii)网络体系结构不同。
(iii)本文除了使用标准的L2损失之外,我们还使用感知损失函数来训练网络,从而显着提高了有雾图像的质量。
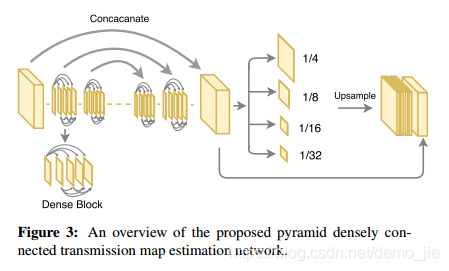
Densely connected pyramid dehazing network网络框架图:
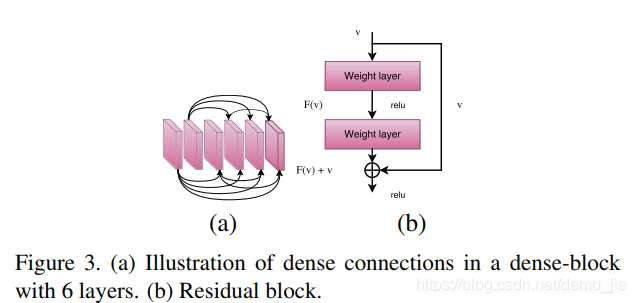
编码器:编码器是使用密集连接卷积网络[Densely connected convolutional networks]的密集块和残差块构造而成的,如图2所示。Huang等人发现,如果CNN靠近输入的层和靠近输出的层之间的连接越短(引入密集连接的网络),则CNN可能会更深并且可以进行有效的训练,其中密集连接的网络会以前馈方式将每一层与其他每一层连接。 与以前的方法相比,所有先前层的特征图都用作特定层的输入。 通过使用这些密集的连接,作者解决梯度消失的问题并了增强特征传播,同时大幅减少网络中的参数数量。 由于这些令人信服的优势,本文使用密集块( dense blocks)构造了编码器。dense-net blocks的结构与Dense-net 网络相似,其中第一个密集块包含12个紧密连接的层,第二个块包含16个紧密连接的层,第三个块包含24个紧密连接的层 。 从预训练的Dense-net 网络初始化每个流的权重。 每个block由一组层组成,其中每个层从所有更早的层接收特征图作为输入,如图3(a)所示。 这种类型的连接可确保在向前和向后传递过程中产生最大的信息流,从而使训练过程更加容易,尤其是在使用更深的网络时。
解码器。 与编码器类似,本文设计具有一组残差和密集块的解码器结构。
残差块主要是受ResNet 中残差学习的启发,ResNet中的残差学习会重新构造网络层,以参考 layer inputs来学习残差功能,代替学习g unreferenced functions。
优点:在网络更深的情况下简化了训练过程
在ResNet中构建残差块,定义为:
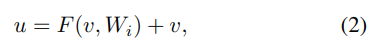
其中v和u是特定层的输入和输出特征,F(x,Wi)是必须学习的残差函数。
本文将所提出的解码器的基本 building block称为dense-residual block,由两层dense block和一个upsampling transition block组成,后面是两个residual blocks。结合这两种类型的块的优势可以实现有雾图像的高质量重建。 注意,dense block与upsampling transition block一起充当refinement功能,以恢复在编码过程中丢失的高级细节,从而获得更好的质量结果。 解码器由一组五个dense-residual blocks和一个 pyramid pooling module。 类似于[ Pyramid scene parsing network],其中融合了图像中各个级别的上下文以进行场景解析,关键idea是包括分层全局优先级,其中包含不同比例和不同子区域的信息。 使用了4个金字塔尺度,分别为1×1、2×2、4×4和8×8。 pooled特征通过1×1卷积沿深度进行降维。 使用双线性插值对这些合并和缩减的特征进行上采样,然后将其与输入特征连接。 最后,使用1×1卷积将这些特征图进行组合,以生成去雾后的输出。
损失函数
已知使用L2误差的传统方法会产生模糊的输出,本文通过最小化LE重建误差和感知损失(LP)函数的组合来学习提出网络的权重:
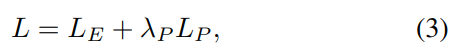
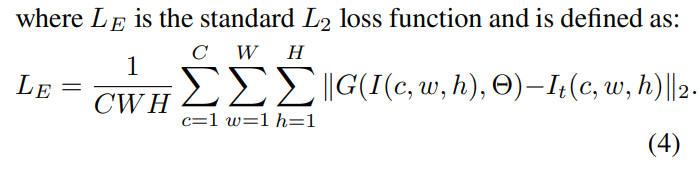

使用从预训练卷积网络提取的高级特征来定义感知损失函数LP。目的是最小化重建图像和地面真实图像之间的感知差异。 本文LP基于VGG-16架构,定义如下:



















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









