




 WaterGAN是一种生成对抗网络,用于从空中RGB-D图像生成逼真的水下图像,进而通过两阶段网络实现实时单目水下图像色彩校正。该方法结合了水下图像形成过程,生成高分辨率输出,且在多种条件下表现良好。
WaterGAN是一种生成对抗网络,用于从空中RGB-D图像生成逼真的水下图像,进而通过两阶段网络实现实时单目水下图像色彩校正。该方法结合了水下图像形成过程,生成高分辨率输出,且在多种条件下表现良好。
论文:WaterGAN: Unsupervised Generative Network to Enable Real-Time Color Correction of Monocular Underwater Images
论文:https://arxiv.org/abs/1702.07392
代码: https://github.com/kskin/WaterGAN
作者:Jie Li, Katherine A. Skinner, Ryan M. Eustice, and Matthew Johnson-Roberson
年份:2018
期刊:IEEE ROBOTICS AND AUTOMATION LETTERS
介绍
吸收和散射导致不同波长的光以不同速率衰减(红光最强),使水下图像呈蓝色或绿色。虽然从理论上很好地描述了此物理过程,但该模型取决于水固有的许多参数以及场景的结构。这些因素使得在不简化假设或现场校准的情况下很难恢复这些参数。因此,水下图像的恢复是一个不小的问题。深度学习在建模复杂的非线性系统方面已显示出巨大的成功,但需要大量的训练数据,这些数据很难在深海环境中进行编译。使用WaterGAN,生成一个包含相应深度,空中彩色图像和逼真的水下图像的大型训练数据集。这些数据用作两阶段网络的输入,用于单目水下图像的色彩校正。
光通过散射效应加回到传感器上,产生雾效应,降低有效分辨率的场景。
局限性
局限性:许多深度学习结构需要大量的训练数据,通常与标签或相应的地面真相传感器测量值配对使用。在深海环境中,用深度信息收集大量水下数据是一项挑战。获取自然海底场景的真实色彩的地面事实也是一个未解决的问题。
方法
WaterGAN方法
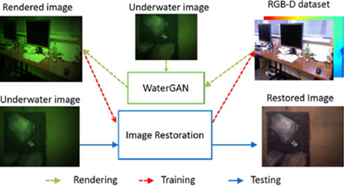
(1)渲染:WaterGAN将空中RGB-D图像和水下图像样本集作为输入,以对抗性地训练生成网络,输出与空中RGB-D对齐的合成水下图像。
(2)训练:颜色校正网络使用合成的水下图像进行训练
(3)测试:输入真实的单目水下图像,输出校正后的图像和相对深度图。
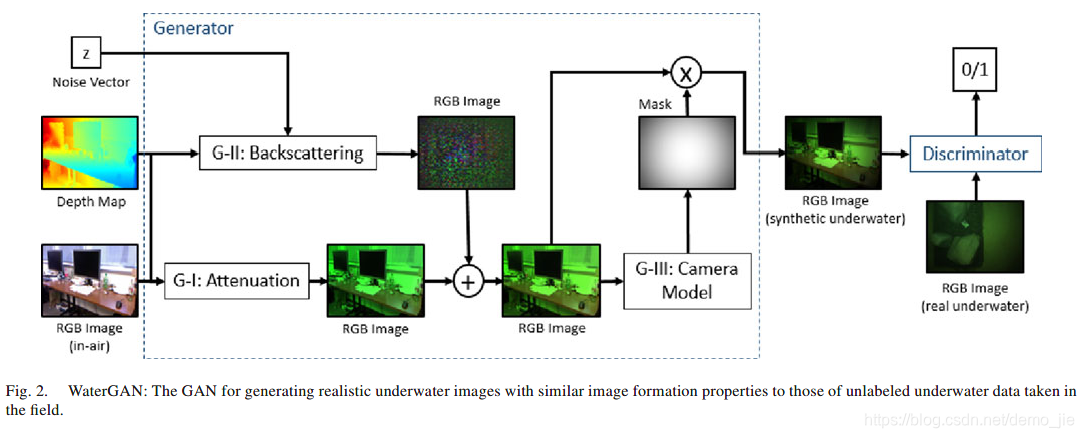
A.生成真实的水下图像
将WaterGAN构建为一个生成对抗网络,该网络同时具有两个训练网络:生成器G和判别器D。在标准GAN中,生成器输入是噪声矢量z,该噪声矢量z投影,整形并通过一系列卷积和反卷积层传播,输出合成图像G(z)。判别器接收合成图像和真实图像x的单独数据集作为输入,并将每个样本分类为真实(1)或合成(0)。 生成器的目标是输出判别器分类为真的合成图像。因此,在优化G时,找最大化

判别器:实现分类的高精度,最小化(1)函数,并针对D的总值函数最大化D(x)。
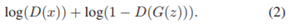
WaterGAN的生成器有三个主要阶段:衰减(G-I),反向散射(G-II)和相机模型(G-III)。此结构的目的是确保生成的图像与RGB-D输入保持一致,这样每个阶段并不改变场景本身的基础结构,只改变其相对的颜色和强度。
(1)G-I衰减:(负责与范围相关的光衰减)衰减模型是Jaffe-McGlamery模型的简化公式:

(Iair是输入的空中图像(传播通过水柱之前的初始辐照度),rc是从摄像机到场景的范围,η是通过网络估计的与波长相关的衰减系数。)我们将波长λ离散为三个颜色通道。G-1的最终辐照度在水柱中会衰减。(衰减系数取决于水的成分和水质,在调查地点间会有所不同)为了确保该阶段仅衰减光而不是增加光,并且确保该系数保持在物理范围内,我们将η约束为大于0。对于训练模型参数,所有输入深度图和图像的尺寸均为48×64,保留了全尺寸图像的长宽比。请注意,我们仍然可以实现全分辨率输出,以生成最终数据,空中训练数据的深度图被标准化为预期的最大水下勘测高度。
(2)G-II散射:(考虑了通过浅卷积网络的散射)会在水下图像中产生独特的雾度效果:
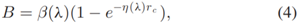
(β是取决于波长的标量参数)。为了捕获范围相关性,输入48×64深度图和100长度的噪声矢量。噪声矢量被投影,整形并连接到深度图,作为单个通道48×64遮罩。为了捕获与波长有关的效应,将输入复制为内核尺寸为5×5的三个独立的卷积层。将此输出批量标准化,并通过泄漏率为0.2的最终泄漏整流线性单元(LReLU)(激活函数)。不同卷积层的三个输出中的每一个都连接在一起,以创建一个48×64×3维的蒙版。 由于后向散射将光添加回图像,并确保成像场景的基础结构不会因RGB-D输入而失真,因此将此蒙版M2添加到G-I的输出中:

(3)G-III相机模型:首先,对渐晕进行建模,由于镜头的影响,渐晕会在图像的边界周围产生阴影图案,渐晕模型:
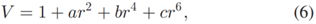
(r:图像中心到每个像素的归一化半径,使r = 0在图像中心,而r = 1在边界处,常数a,b和c是网络估算的模型参数)输出mask具有输入图像的尺寸,渐晕图像G3:

(M3 = 1 /V)
约束:
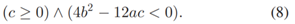
最后,假设一个线性传感器响应函数,它具有单个缩放参数k ,最终输出为

鉴别器:鉴别器输入图像为48×64×3(真实或合成图像)。该图像通过内核大小为5×5的四个卷积层传播,图像尺寸下采样了两倍,并且通道尺寸增加了一倍。每个卷积层后面是LReLU,泄漏率为0.2。最后一层是S型函数,鉴别器返回的分类标签为(0)(合成图像)或(1)(真实图像)。
生成图像样本:训练完成后,使用学习的模型来生成图像样本。为了生成图像,我们以480×640的分辨率输入空中RGB-D数据,并以相同的分辨率输出水下合成图像。为了保持分辨率并保持长宽比,在将暗角遮罩和散射图像应用于图像之前,先对其进行三次三次插值采样。 衰减模型并不特定于分辨率。
B.水下图像恢复网络
为了实现实时的单目图像颜色恢复,我们提出了一种使用两个完全卷积网络的两阶段算法,该网络在空中RGB-D数据和WaterGAN生成的相应渲染水下图像上进行训练。深度估计网络首先根据降采样后的合成水下图像重建一个粗略的相对深度图。 然后,色彩恢复网络根据水下图像及其估计的相对深度图的输入进行还原。
深度估计阶段
我们基于SegNet(最新的全卷积编码器-解码器结构),为像素级密集学习提供了两个网络模块的基本结构。在SegNet中提出了一种新型的非参数上采样层,该层直接使用来自编码器中相应最大池化层的索引信息。与达到类似性能的基准体系结构相比显示出更高的效率。SegNet专为场景分割而设计,因此保留输入图像的高频信息不是必需的属性。但是,在我们的图像恢复应用程序中,重要的是保留用于输出的纹理级别信息,以使校正后的图像仍可在其他应用程序中进行处理或利用。本文在基本的编码器-解码器结构上合并了跳层结构,以补偿通过网络的高频分量的损失。跳过层能够提高网络训练中的收敛速度,并能够改善还原图像的精细比例质量。
色彩恢复阶段
色彩恢复阶段
(1)深度估计阶段使用的基本网络体系结构保留为色彩恢复网的核心成分
(2)将核心成分进行额外的下采样和上采样阶段。使用平均池化层对输入图像进行下采样到分辨率为128×128,并通过核心成分。
(3)在核心成分的最后,用由双线性插值滤波器初始化的反卷积层将输出上采样到512×512。连接两个跳层结构保留高分辨率功能。(使主要的中间计算以较低分辨率进行)
深度估计和色彩校正网络都使用欧几里得损失函数。图像中的像素值在0到1之间归一化。
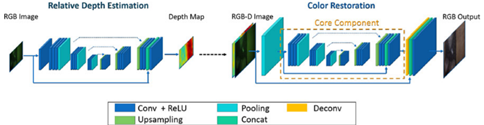
网络以56×56×3的下采样水下图像作为输入,并输出56×56×1的相对深度图。然后将该图上采样为480×480,并作为第二阶段输入的一部分以进行色彩校正。颜色校正网络模块类似于深度估计网络。输入480×480分辨率的RGB-D图像并填充为512×512,避免边缘效应。
结果
直方图均衡化在视觉上看起来很吸引人,但它不知道范围相关的影响,因此从不同的角度观看同一对象的校正后的颜色会显示为不同的颜色。与其他方法相比,我们提出的方法在不同的视图上显示出更一致的颜色,并且减少了渐晕和衰减的影响。
实验
本文使用受控纯净水测试箱中的数据集以及该领域的实际科学调查来评估提出的方法。 作为所有实验的输入空中RGB-D,本文编译了四个室内Kinect数据集(B3DO , UW RGBD Object , NYU Depth and Microsoft 7-scenes),总共15000 RGB-D图像。
A 人工试验台
第一次调查是使用4英尺×7英尺的人造岩石平台进行的,该平台浸没在密歇根大学海洋流体力学实验室(MHL)的纯水试验箱中。 色板连接到平台以供参考(图4)。 此次调查有7000多个水下图像。

B 现场测试
在 Port Royal, Jamaica收集了一个现场数据集,该城市既包含自然结构又包含人造结构。 这些图像是用手持潜水器收集的。 对于本文实验,收集了一次潜水的6500张图像组成的数据集。 离海底的最大深度约为1.5 m。 在澳大利亚蜥蜴岛附近的珊瑚礁系统(coral reef system near Lizard Island)中收集了另一个野外数据集。 数据是使用相同的潜水台收集的,假设距海底的最大深度为2.0 m。 从局部地区的多次潜水调查中收集了总计6083张图像。
C 网络训练
对于每个数据集,我们训练WaterGAN网络以对来自特定调查地点的原始水下图像进行逼真的表示。在训练过程中,将真实样本输入到WaterGAN的判别器网络中,并将相等数量的空中RGB-D配对输入到生成器网络中。在Titan X(Pascal)上训练WaterGAN,批处理大小为64张图像,学习率为0.0002。通过实验,发现10个epochs 足以渲染逼真的图像,以输入到Port Royal and Lizard Island 数据集的色彩校正网络。为MHL数据集训练了25个epochs 。训练模型后,可以生成任意数量的合成数据。本文为每个模型(MHL,Port Royal and Lizard Island)总共生成15000张渲染的水下图像,这与RGB-D数据集的总大小相对应。
然后用生成的图像和相应的空中RGB-D图像训练提出的色彩校正网络。将此集划分为一个包含12000张图像的训练集和一个包含3000张图像的验证集。在Titan X(Pascal)GPU上从头开始为深度估计网络和图像恢复网络训练网络。
(1)对于深度估计网络,训练20个epochs,批量大小为50,基本学习率为1e-6,动量为0.9。
(2)对于色彩校正网络,执行两级训练策略。对于第一级,训练核心组件的输入分辨率为128×128,批处理大小为20,对于20个epochs基本学习速率为1e-6。然后以512×512的全分辨率训练整个网络,并从第一步训练中初始化核心组件中的参数。本文训练了10个epochs的完整分辨率模型,批量大小为15,基本学习率为1e-7。
评估结果
两个用于评估色彩校正性能的定量指标:色彩准确性和色彩一致性。
(1)我们的方法在蓝色,红色和洋红色有最低误差。直方图均衡在青色,黄色和绿色恢复的误差最小,但是我们的方法仍然胜过其他方法的青色。
(2)对于颜色一致性,计算在多个图像上的每个场景点的强度归一化像素颜色的方差。我们提出的方法在每个颜色通道上显示出最低的方差。
我们的深度估算网络可恢复准确的相对深度,而不是绝对深度。这是由于单目深度估计问题所固有的尺度模糊性。
为了评估由于色彩校正网络中跳层结构而导致的图像质量改善,我们以相同分辨率对网络进行了有无跳层结构的训练(跳层结构有助于保留输入图像中的高频信息)。
结论
WaterGAN是一个从空气RGB-D建模水下图像的生成网络。我们展示了一种新颖的生成器网络结构,该结构结合了水下图像形成过程来生成高分辨率输出图像。然后,我们采用了一个密集的像素级模型学习管道,用于训练RGB-D对单目水下图像的颜色校正任务,并生成相应的图像。我们在受控数据和现场数据上评估了我们的方法,以定性和定量地表明我们的输出在各种观点上都是准确且一致的。





















 8167
8167











 到【灌水乐园】发言
到【灌水乐园】发言







