






【n8n教程】:用RAG让AI Agent掌握你的知识库
你是否曾想让AI能够理解和引用你的专有文档?RAG(检索增强生成) 技术可以做到这一点。通过RAG,AI不再依赖训练数据中的知识,而是可以实时从你的知识库中检索信息。
什么是RAG?
核心概念
RAG(Retrieval-Augmented Generation) 是一种让AI更聪明的技术:
- 🔍 检索(Retrieval):从你的文档库中找到相关信息
- 📚 增强(Augmented):将找到的信息提供给AI
- ✍️ 生成(Generation):AI基于这些信息生成更准确的答案
RAG解决的问题
| 传统AI的问题 | RAG如何解决 |
|---|---|
| 知识过时(基于旧的训练数据) | 实时从最新文档检索信息 |
| 无法访问专有知识(公司内部信息) | 可以访问你的私有文档库 |
| 容易产生幻觉(编造信息) | 基于真实文档生成,减少幻觉 |
| 无法解释答案来源 | 返回引用的源文档 |
什么是向量存储(Vector Store)?
简单理解
向量存储是一个特殊的数据库,它做三件事:
- 将文本转换为数字(嵌入):每句话都变成一个向量(一列数字)
- 存储这些数字:像档案库一样整理存储
- 快速检索相似内容:根据语义相似性(而非关键词)找到相关信息
工作原理示例
你的文档:
"公司提供健康保险"
"员工享受年假"
向量化后(简化示例):
向量1: [0.12, 0.85, 0.33, ...]
向量2: [0.14, 0.82, 0.35, ...]
用户问题:"假期政策是什么?"
问题向量: [0.15, 0.83, 0.34, ...] ← 与向量2最相似!
↓ 检索出 → "员工享受年假"
为什么向量存储比关键词搜索更聪明
- 🔍 关键词搜索:只能找到包含相同单词的内容
- 🧠 向量搜索:理解语义意思,即使措辞不同也能找到
例子:
- 关键词搜索:“假期” → 无结果(因为文档说"年假")
- 向量搜索:“假期” → 找到"年假"(因为语义相似)
n8n中实现RAG的5个关键步骤
步骤1️⃣:连接数据源
在n8n中,首先需要连接你的知识源:
支持的数据源:
- 📄 本地文件:PDF、TXT、DOCX等
- 🗂️ Google Drive:云端文档
- 💾 数据库:MySQL、PostgreSQL等
- 🌐 API:从任何服务获取数据
n8n节点选择:
文件上传 → Google Drive → 数据库查询 → HTTP请求
步骤2️⃣:分割文本(Text Splitting)
大文档需要分割成小块。n8n提供三种方式:
| 方式 | 特点 | 适用场景 |
|---|---|---|
| 字符分割 | 按固定字符数分割 | 结构简单的纯文本 |
| 递归分割✅ | 按Markdown/代码块/HTML结构分割 | 📌 推荐:适合大多数文档 |
| Token分割 | 按Token数分割 | 精确控制API成本 |
最佳实践:
- 块大小:200-500 tokens(约750-2000字符)
- 块重叠:100 tokens(确保上下文连贯性)
- 推荐组合:递归分割 + 500 tokens + 100重叠
步骤3️⃣:生成嵌入(Embeddings)
将文本转换为计算机能理解的向量。选择合适的模型是关键:
| 模型 | 维度 | 速度 | 成本 | 最适用 |
|---|---|---|---|---|
text-embedding-ada-002 |
1536 | ⚡⚡⚡ 最快 | 💰 最便宜 | 简短文本、原型、成本敏感 |
text-embedding-3-large |
3072 | ⚡ 较慢 | 💰💰 较贵 | 长文档、复杂主题、高精度需求 |
开源模型(如all-MiniLM-L6-v2) |
384 | ⚡⚡⚡ 很快 | 💰 免费 | 本地部署、无成本 |
如何选择:
项目规模 → 文档类型 → 预算
↓ ↓ ↓
小规模 + 短文本 + 有限 → ada-002
大规模 + 长文本 + 充足 → 3-large
本地 + 任何 + 无成本 → 开源模型
步骤4️⃣:存储到向量库
选择合适的向量存储解决方案:
| 存储方案 | 特点 | 成本 | 最适用 |
|---|---|---|---|
| Simple Vector Store | 内存存储,快速原型,n8n内置 | 🆓 免费 | 学习、小规模演示 |
| Pinecone | 托管云服务,完全可扩展,持久化 | 💰 按使用量计费 | 生产环境、企业应用 |
| Qdrant | 开源、功能完整、可自建 | 🆓 开源免费 | 隐私敏感、自主控制 |
| Milvus | 开源向量数据库,高性能 | 🆓 开源免费 | 大规模数据、学术研究 |
步骤5️⃣:查询和生成答案
用户提问时的完整流程:
- 用户输入问题 → “我如何请假?”
- 问题转换为向量 → 生成问题的嵌入
- 向量库相似性搜索 → 找到最相关的5条文档
- 准备上下文 → 将检索结果组织成提示词
- LLM生成答案 → “根据公司政策,年假为…”
- 返回答案 → 可选:附带源文档
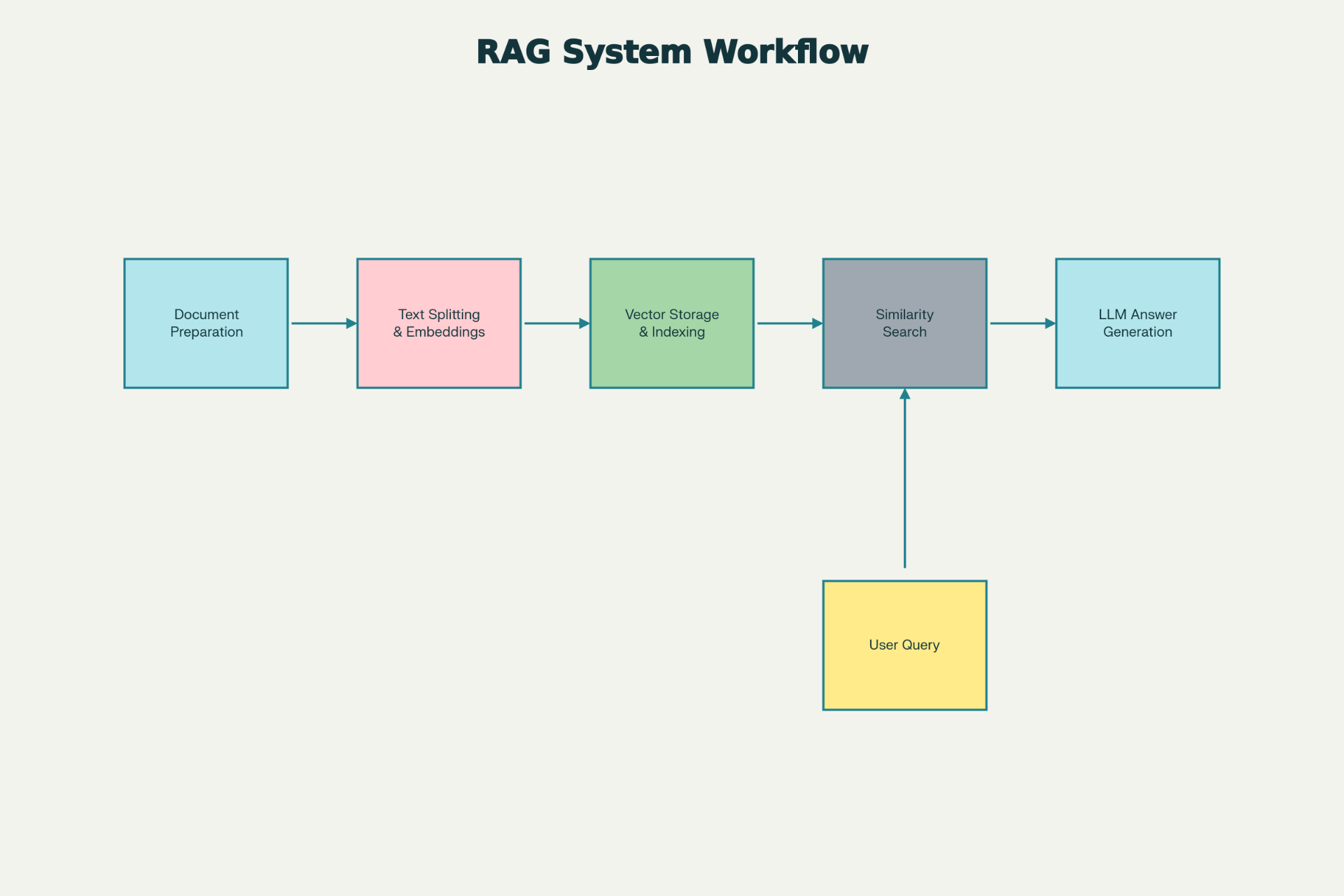
实践案例:构建你的第一个RAG系统
工作流架构概览
┌─────────────┐
│ 文档上传 │
│ (PDF/TXT) │
└──────┬──────┘
↓
┌──────────────────┐
│ 文本分割 │
│(递归分割: 500t) │
└──────┬───────────┘
↓
┌──────────────────┐
│ 生成嵌入 │
│ (OpenAI API) │
└──────┬───────────┘
↓
┌──────────────────┐ 用户问题
│ 向量存储 │ ↓
│(Simple/Pinecone)│ ┌─────────────┐
└──────┬───────────┘ │ 问题向量化 │
│ └─────┬───────┘
└──────→ 搜索 ←────┘
↓
┌──────────────┐
│ 相似性搜索 │
│ (返回Top 5) │
└──────┬───────┘
↓
┌──────────────────┐
│ LLM生成答案 │
│ (基于检索结果) │
└──────┬───────────┘
↓
┌──────────────────┐
│ 返回结果 │
│ (答案+源文档) │
└──────────────────┘
实际操作:5分钟快速开始
第1分钟:新建工作流
- 打开n8n → 点击 + 新建 → 工作流
- 命名为"我的RAG助手"
第2分钟:添加触发器
- 在canvas上搜索 Webhook 节点
- 配置:
- 方法:POST
- 路径:
rag
第3分钟:添加向量存储
- 添加 Simple Ve
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}