









例子
- 简单的一个例子:创建2个大数组,然后相同位置元素相加放入数组2的同一位置;该例子在cpu上执行;
/**/ #include <iostream> #include <math.h> // function to add the elements of two arrays void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } int main(void) { int N = 1<<20; // 1M elements float *x = new float[N]; float *y = new float[N]; // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the CPU add(N, x, y); // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory delete [] x; delete [] y; return 0; } - mac编译:
clang++ add.cpp -o add
- 运行结果:
> ./add
Max error: 0.000000
从cpu到gpu
-
将add函数改写成能在gpu运行的函数,并且可以由cpu调用;改写方法很简单,只要在前面加上
__global__,如下所示 -
改写后的函数称为 kernel
// CUDA Kernel function to add the elements of two arrays on the GPU __global__ void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } -
此外,我们也要把2个数组放到gpu上;这里用到CUDA的unified memory概念,即可以让CUDA分配一块空间,该空间允许cpu、gpu访问;使用该方法改写上面代码如下:
// Allocate Unified Memory -- accessible from CPU or GPU float *x, *y; cudaMallocManaged(&x, N*sizeof(float)); //这里替代了上面的new方法,调用cuda统一内存分配函数 cudaMallocManaged(&y, N*sizeof(float)); ... // 中间部分不变 // Free memory cudaFree(x); // 使用完毕后释放,很简单 cudaFree(y); -
进一步,在原代码中调用add的地方还需要处理一下;因为使用CUDA是要加速的,原代码add部分并没有指定如何加速;所以需要使用cpu调用CUDA kernel的规范来写;如下
add<<<1, 1>>>(N, x, y); // 使用 <<<1,1>>>来表示kernel调用及使用1个gpu线程加速
-
还有点小问题,我们在cpu上调用add这个kernel,此时是由gpu执行add,cpu则继续往下走,那么会造成gpu返回结果前cpu线程就执行完毕。因此需要让cpu等待一下:
add<<<1, 1>>>(N, x, y);
cudaDeviceSynchronize(); # 让cpu等待gpu执行完毕 -
好了,完整的代码如下:
#include <iostream> #include <math.h> // Kernel function to add the elements of two arrays __global__ // 让add变为gpu可执行的kernel void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } int main(void) { int N = 1<<20; float *x, *y; // Allocate Unified Memory – accessible from CPU or GPU cudaMallocManaged(&x, N*sizeof(float)); // 在统一内存上分配空间创建数组 cudaMallocManaged(&y, N*sizeof(float)); // initialize x and y arrays on the host for (int i = 0; i < N; i++) { // cpu上做初始化(cpu、gpu均可访问统一内存) x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the GPU 设置加速并由cpu调用kernel,gpu执行 add<<<1, 1>>>(N, x, y); // Wait for GPU to finish before accessing on host cudaDeviceSynchronize(); // gpu: cpu你等等我 // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory cudaFree(x); // 释放统一内存 cudaFree(y); return 0; } -
执行上述代码
nvcc add.cu -o add_cuda //注意涉及到gpu,因此需要使用nvcc编译
./add_cuda // 执行
Max error: 0.000000 // 没有错误 -
在k80显卡上查看add这个kernel此时的耗费时间:使用CUDA自带的nvprof查看,发现需要463ms
$ nvprof ./add_cuda
3355 NVPROF is profiling process 3355, command: ./add_cuda
Max error: 0
3355 Profiling application: ./add_cuda
3355 Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 463.25ms 1 463.25ms 463.25ms 463.25ms add(int, float*, float*)
…
利用gpu进行加速
-
上面在调用kernel add时,使用了特别的形式:
add<<<1, 1>>>(N, x, y);
-
这里需要提一下CUDA的结构:CUDA有大量的处理单元(下图绿色部分),因此可以开启大量的线程;这就涉及到如何来组织这些线程干活了;CUDA设置了线程块(block)概念、网格(grid)概念、流式多处理器(Streaming Multiprocessor或简称SM)概念来管理线程;
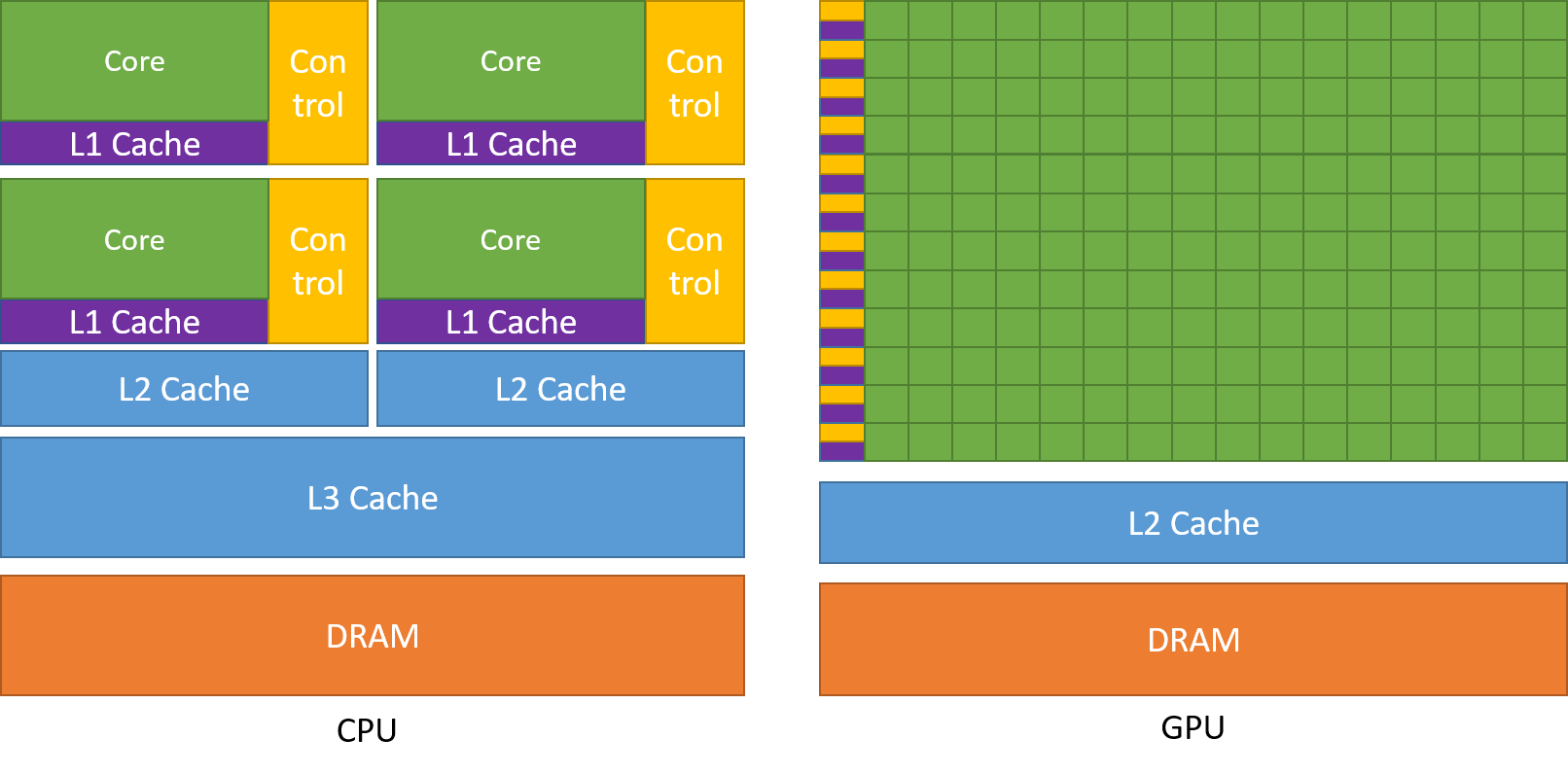
-
每个block可以包含32的倍数个线程组合;多个block构成1个grid(比如4096);1个SM也是多个block组成,类似grid(或者就是grid,我还没完全搞清楚#TODO);见下图
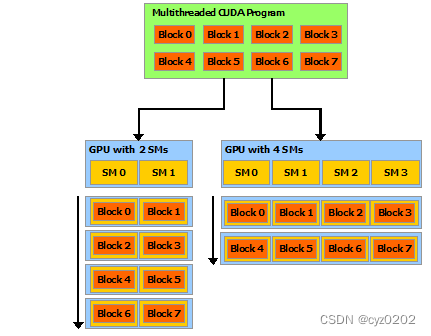
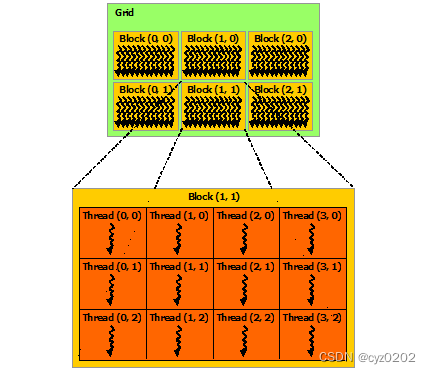
-
CUDA使用格式 <<<a,b>>>来指定并行计算的参数;参数a指定使用多少个block,参数b指定每个block使用多少个线程;
-
我们先来看看b的变动,令a=1,b=256
add<<<1, 256>>>(N, x, y);
-
需要修改一下kernel add,让可使用的线程(256个)分别干自己的活,如下
__global__ void add(int n, float *x, float *y) { // 引入CUDA提供的2个内在变量 int index = threadIdx.x; // threadIdx.x代表当前线程在当前block的index int stride = blockDim.x; // blockDim.x代表当前block的大小,即256 for (int i = index; i < n; i += stride) // 每个线程分配对应的活,如线程1会计算 i=[1, 1+256, 1+2*256,...]位置的元素和,线程2计算 i=[2, 2+256, 2+2*256, ...]位置的元素和 y[i] = x[i] + y[i]; } -
运行结果如下,可以发现耗时从gpu单线程的463ms->2.7ms,加速极多;
Time(%) Time Calls Avg Min Max Name
100.00% 2.7107ms 1 2.7107ms 2.7107ms 2.7107ms add(int, float*, float*) -
进一步,我们来看看不同a的加速情况;我们根据上文定义的数组大小(N)、block大小来计算a的大小;
int blockSize = 256; // b的大小 // 这里使用 (N + blockSize - 1)/blockSize 来进行上取整,如 int((10+6-1)/6)=2; // N=1<<20,则numBlocks=4096 int numBlocks = int((N + blockSize - 1) / blockSize); // a的大小,注意取整 add<<<numBlocks, blockSize>>>(N, x, y); // <<<4096,256>>> -
同样需要修改kernel add来充分利用所有可用线程,如下(需结合下图阅读)
__global__ void add(int n, float *x, float *y) { // blockIdx.x代表block序号,blockDim.x代表block大小,threadIdx.x代表线程序号 // index表示当前线程在所有线程块中的总排序,如第2个block的第3个线程为: // index = 2*256+3 = 515 int index = blockIdx.x * blockDim.x + threadIdx.x; // gridDim.x代表grid内有多少个block;N=1<<20,所以gridDim.x=4096 int stride = blockDim.x * gridDim.x; // grid内所有线程同步执行,N如果超过grid所有线程数,则前面的线程要多干活 for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }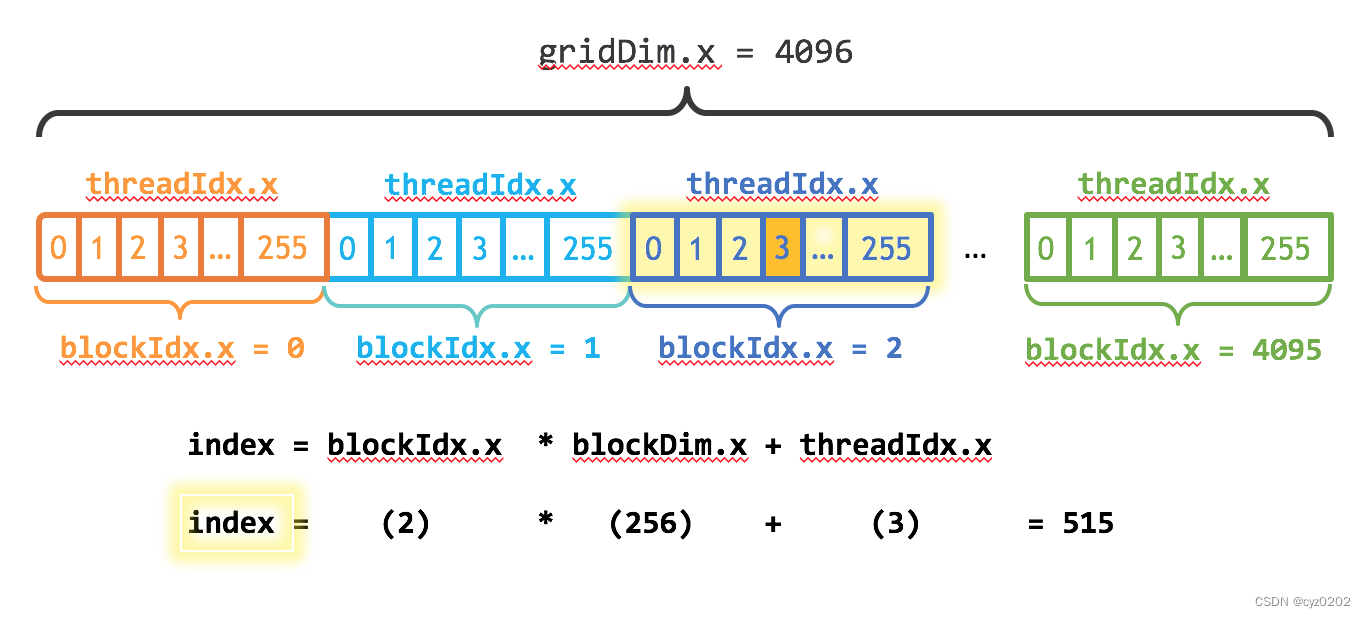
-
执行结果如下,可以看到又有极大的加速(2.7ms->94us)
Time(%) Time Calls Avg Min Max Name
100.00% 94.015us 1 94.015us 94.015us 94.015us add(int, float*, float*)
总结
- 不同设置对应的加速性能(GT750M是作者在其mac上的实验结果)

- 以上展示了如何利用C++ CUDA对代码进行加速;初步介绍了CUDA的结构及调用设置;包括 kernel的写法,统一内存空间分配和回收,多线程的设置和在kernel中的充分利用
更新0601:2维图像上的CUDA线程索引
- 以下内容来自NVIDIA开发者社区课程:何琨-CUDA-python
- 二维情况:grid是6*12,gridDim.x=3,blockDim.x=4,gridDim.y=2,blockDim.y=4;此时如果数据太多,就需要用到grid-stride-loop
 - 使用grid_stride_loop,如下
- 使用grid_stride_loop,如下
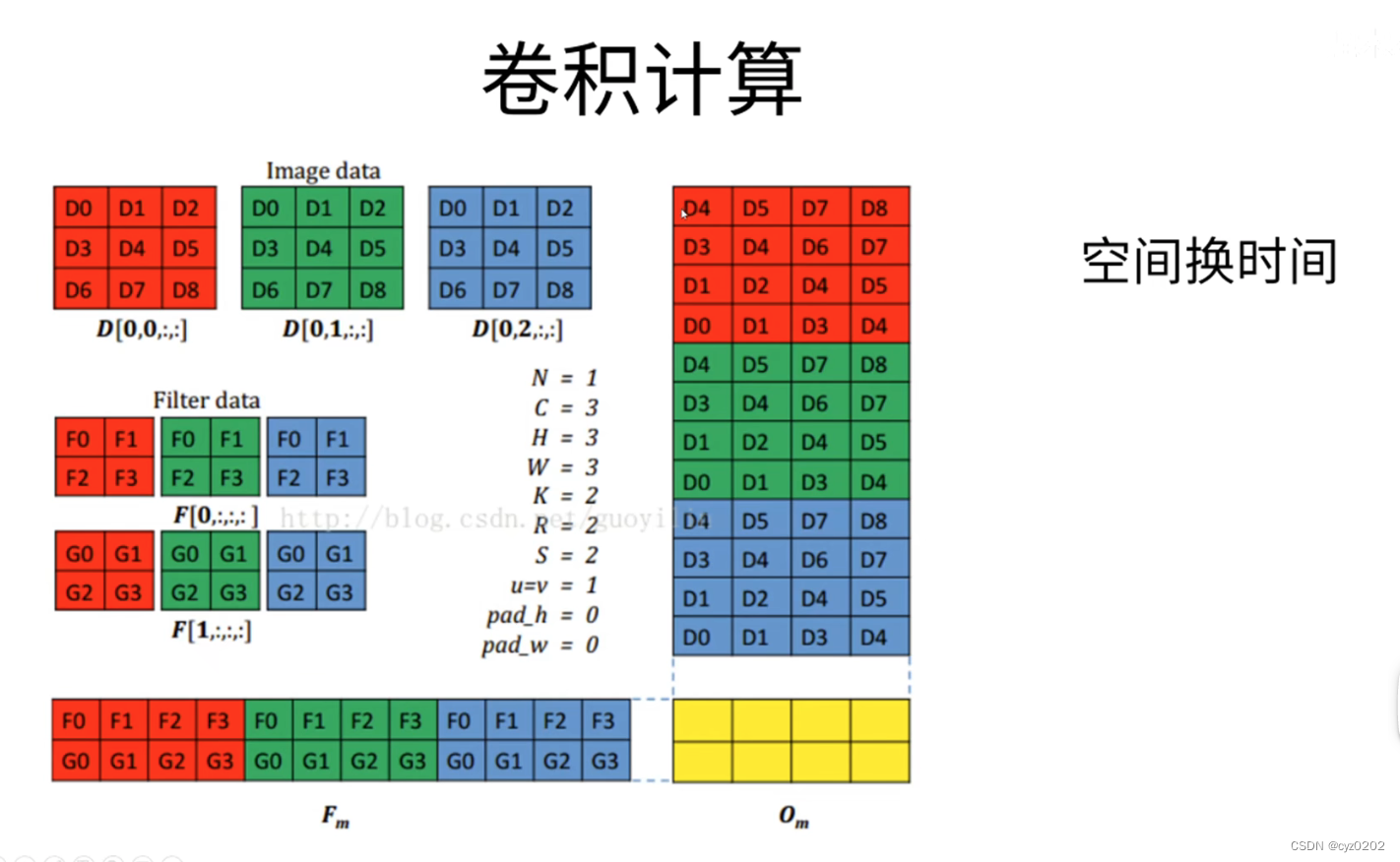
- 卷积计算:下图是3维卷积核在RGB图片上做卷积的过程,实际计算是先将卷积核和图片视为两个特殊的矩阵,再进行矩阵相乘,然后转换成标准的卷积输出;(下图卷积核在计算时做了标准的卷积转置-对角线元素互换)
- CPU实现矩阵乘法:不失一般性,假设M,N均为方阵(行/列大小为width)

- CUDA上的矩阵乘法:使用global memory

- CUDA上的矩阵乘法:使用share memory,能稍快一点


















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









