






PaperInfive:五分钟了解一篇前沿论文

全文总结:本文提出了一种基于Transformer的时间序列预测模型的有效设计,通过引入两个关键组件:Patching和通道独立结构。与之前的工作相比,它可以捕获局部语义信息,并受益于更长的回溯窗口。该模型不仅在监督学习方面优于其他基线,而且在自监督表示学习和迁移学习方面证明了其潜能。
题目:A Time Series is Worth 64 Words: Long-Term Forecasting with Transformers
作者:Yuqi Nie
期刊/会议:ICLR
时间:2023
链接:https://arxiv.org/pdf/2211.14730.pdf
源码:https://github.com/yuqinie98/patchtst
问题背景
近年来,基于Transformer的模型在时间序列预测的有效性收到挑战,作者认为Transformer的潜力尚未完全发掘,主要基于以下几个方面的原因:
- 大多数模型使用逐点注意力,实际能提取到的信息非常有限,忽略了Patch的重要性;
- 通道独立在CNN和线性模型中效果很好,但尚未应用于基于transformer的模型。
基于以上两个问题,作者试图通过提出一种通道无关的**patch time series Transformer (PatchTST)**模型来重塑基于Transformer-based Model,主要包括了以下两个模块:
- Patching:通过将时间步长聚合到子序列级Patching中来增强局部性并捕获在点级无法获得的全面语义信息;
- Channel-independence:对于多变量时间序列预测而言,对每一个变量单独预测,多个变量的序列共享Embedding和Transformer参数。
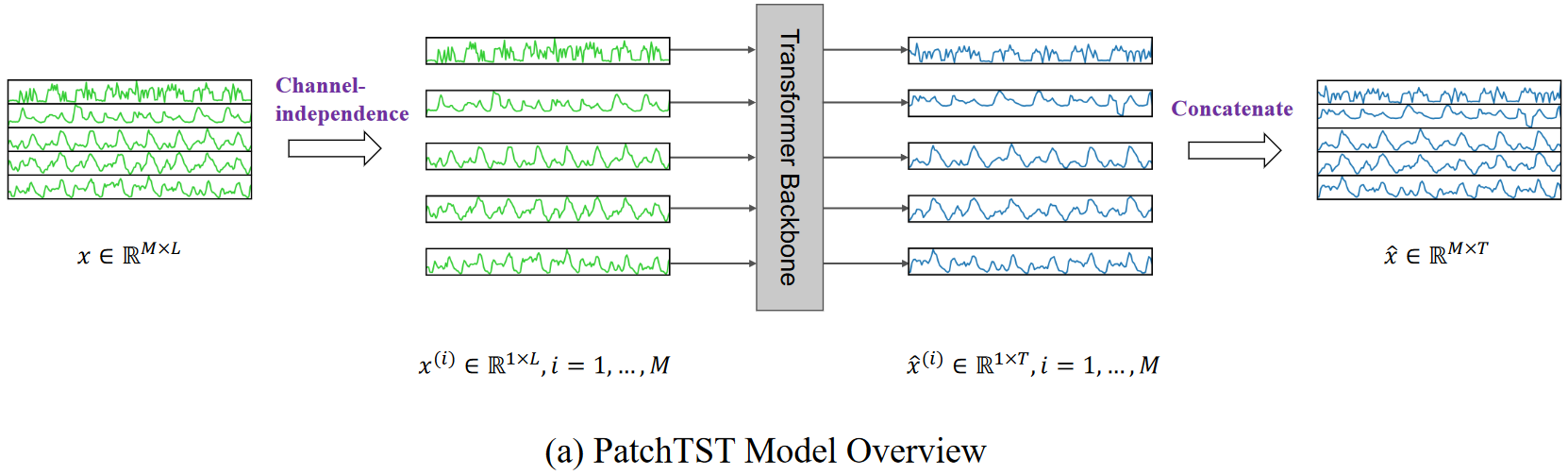
研究方法
1. 有监督学习
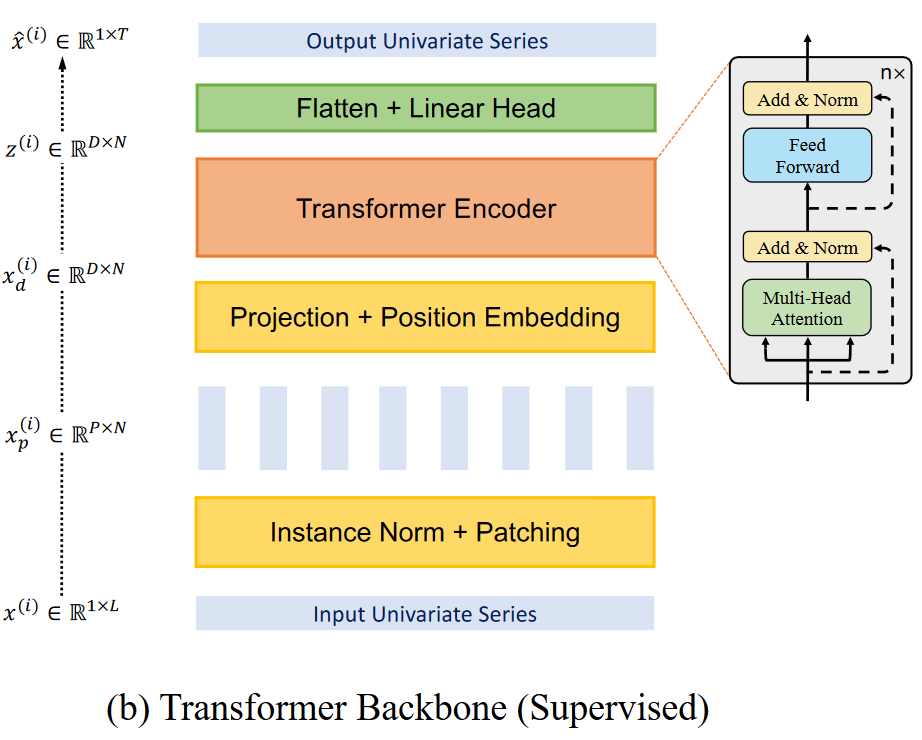
PatchTST的模型结构如上图所示,接下来我们逐模块介绍:
1. Input Univariat Series
首先是输入部分,本文作者采用了Channel Independence,所以模型的输入为多元时间序列中的其中一条序列(Univariat Series) x ( i ) ∈ R 1 × L \boldsymbol{x}^{\left( i \right)}\in \mathbb{R}^{1\times L} x(i)∈R1×L, L L L表示时间序列的长度。
2. Instance Norm + Patching
Instance Norm:以帮助减轻训练数据和测试数据之间的分布偏移效应。它简单地将每个时间序列
x
(
i
)
\boldsymbol{x}^{\left( i \right)}
x(i)以均值为0,标准差为1进行归一化,在输出时将平均值和标准差添加回预测值中。
Patching:将每个输入单变量时间序列
x
(
i
)
\boldsymbol{x}^{\left( i \right)}
x(i)划分为可以重叠或不重叠的patch。假设每一个Patch的长度为
P
P
P,两个连续Patch的初始时刻之间的距离为
S
S
S,那么Patching后的序列维度为
x
p
(
i
)
∈
R
P
×
N
\boldsymbol{x}_{p}^{\left( i \right)}\in \mathbb{R}^{P\times N}
xp(i)∈RP×N,表示一共分为了
N
N
N个Patch,其中每个Patch的长度为
P
P
P,其中
N
=
[
(
L
−
P
)
S
]
+
2
N=\left[ \frac{\left( L-P \right)}{S} \right] +2
N=[S(L−P)]+2。
3. Projection + Position Embedding
Projection:通过线性映射将这些Patches映射到
D
D
D维的Transformer潜在空间,即
x
p
(
i
)
\boldsymbol{x}_{p}^{\left( i \right)}
xp(i)从
P
×
N
P\times N
P×N映射到
D
×
N
D\times N
D×N。
Position Embedding:通过一个可学习的位置编码
W
pos
∈
R
D
×
N
\mathbf{W}_{\text{pos}}\in \mathbb{R}^{D\times N}
Wpos∈RD×N来捕获序列的时间特性,得到最终的输出为
x
d
(
i
)
=
W
p
x
p
(
i
)
+
W
pos
\boldsymbol{x}_{d}^{\left( i \right)}=\mathbf{W}_p\boldsymbol{x}_{p}^{\left( i \right)}+\mathbf{W}_{\text{pos}}
xd(i)=Wpxp(i)+Wpos。
4. Trasnformer Encoder
这里采用的Multi-head Attention与传统的Multi-head Attention完全一致,即对于每一个Patch而言,计算所有Patches对它的注意力权重,并加权求和得到该Patch的输出:
( O h ( i ) ) T = Attention ( Q h ( i ) , K h ( i ) , V h ( i ) ) = Soft max ( Q h ( i ) K h ( i ) d k ) T V h ( i ) \left( \mathbf{O}_{h}^{\left( i \right)} \right) ^T=\text{Attention}\left( Q_{h}^{\left( i \right)},K_{h}^{\left( i \right)},V_{h}^{\left( i \right)} \right) =\text{Soft}\max \left( \frac{Q_{h}^{\left( i \right)}K_{h}^{\left( i \right)}}{\sqrt{d_k}} \right) ^TV_{h}^{\left( i \right)} (Oh(i))T=Attention(Qh(i),Kh(i),Vh(i))=Softmax(dkQh(i)Kh(i))TVh(i), O h ( i ) ∈ R D × N \mathbf{O}_{h}^{\left( i \right)}\in \mathbb{R}^{D\times N} Oh(i)∈RD×N
然后再通过BatchNorm和具有残差连接的前馈网络,得到最终的输出 z h ( i ) ∈ R D × N \boldsymbol{z}_{h}^{\left( i \right)}\in \mathbb{R}^{D\times N} zh(i)∈RD×N。
5. Flattern + Linear Head
最后,将二维特征展平后通过一层线性层,得到最终的预测结果: x ^ ( i ) = ( x ^ L + 1 ( i ) , . . . , x ^ L + T ( i ) ) ∈ R 1 × T \boldsymbol{\hat{x}}^{\left( i \right)}=\left( \hat{x}_{L+1}^{\left( i \right)},...,\hat{x}_{L+T}^{\left( i \right)} \right) \in \mathbb{R}^{1\times T} x^(i)=(x^L+1(i),...,x^L+T(i))∈R1×T。
2. 自监督学习
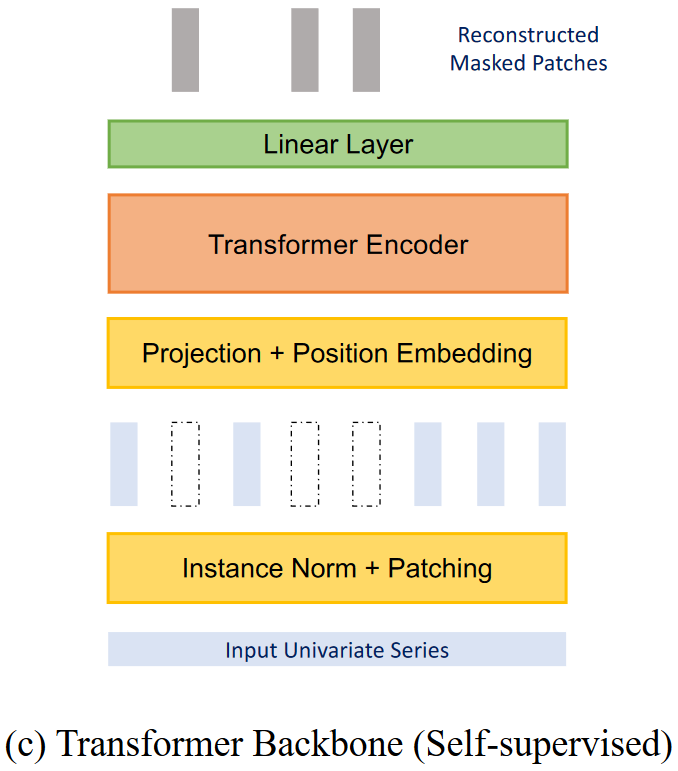
自监督表示学习已成为从未标记数据中提取高层抽象表示的热门方法。在PatchTST中,作者随机掩码若干个Patches,然后对被掩码的Patches进行重建。对于每一个token(Patch),它通过Transformer Encoder后输出维度是 D D D,由于该patch本身的长度是 P P P,因此要重建它的话,再加上一个 D × P D× P D×P的Linear层即可。
注意在自监督学习构造Patches时,Patches之间不应该有重叠区域。
作者提出,如果不进行Patching,直接把时序数据输入进行MASK则会存在两个潜在问题:
- 当前时间步的Mask值可以通过与紧随前后的时间值进行插值轻易推断,而不需要对整个序列有高层次的理解,这与我们学习整个信号的重要抽象表示的目标不符合;
- 已知我们有 L L L个时间步的表示向量, D D D维空间, M M M个变量,每个变量具有预测范围 T T T。则输出需要一个维度为 ( L ⋅ D ) × ( M ⋅ T ) (L⋅D)×(M⋅T) (L⋅D)×(M⋅T)的参数矩阵 。如果这四个值中的任何一个或所有值都很大,那么这个矩阵可能会特别大。当下游训练样本数量稀缺时,这可能导致过拟合问题。
预测效果
作者在以下数据集上进行实验:

1. 时序预测
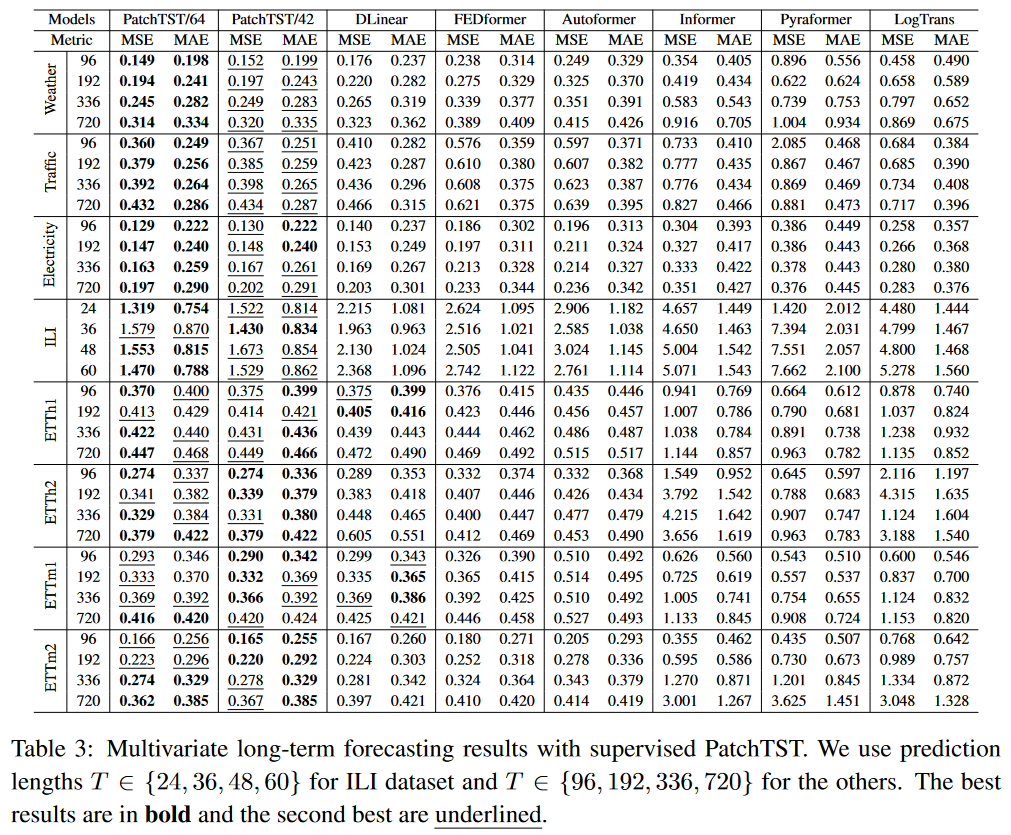
作者根据不同的回望窗口导致Patch数量不同,分为了PatchTST/64和PatchTST/42两个模型,可以看到PatchTST的效果超过了DLinear以及其它的Transformer-based模型。
2. 表征学习
这部分实验验证自监督学习的有效性,其中:
- Fine-tune:表示先通过自监督学习得到预训练模型后,再采用有监督学习进行两阶段微调;
- Lin. Prob.:表示先通过自监督学习得到预训练模型后,只微调Linear Head部分;
- Sup.:表示直接进行有监督学习。
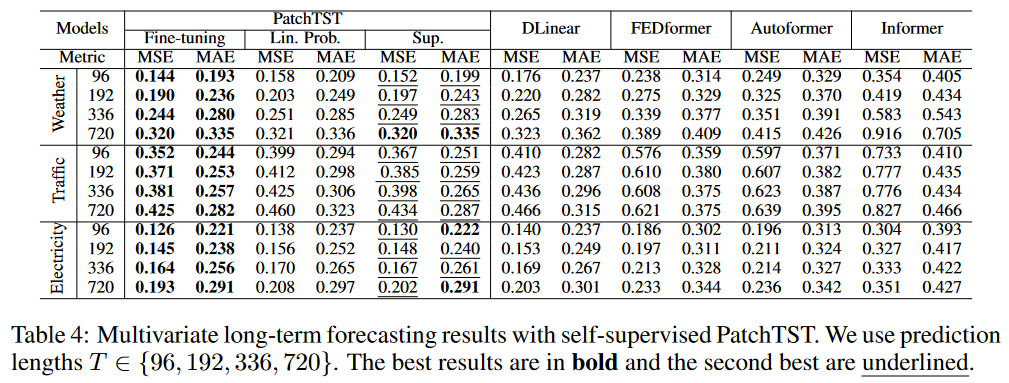
可以看到,仅微调Linear Head的模型已经能达到出色的预测效果,并超过了Dlinear。自监督+全量微调的模型达到了最佳的预测效果。
3. 消融实验
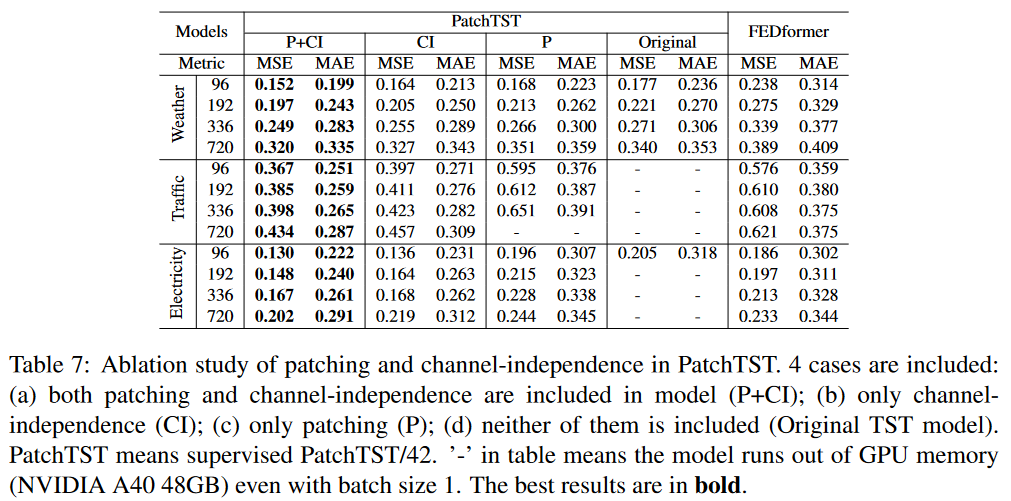
可以看到Patching+Channel Independence的模型达到了最佳的预测性能。
4. 长时预测
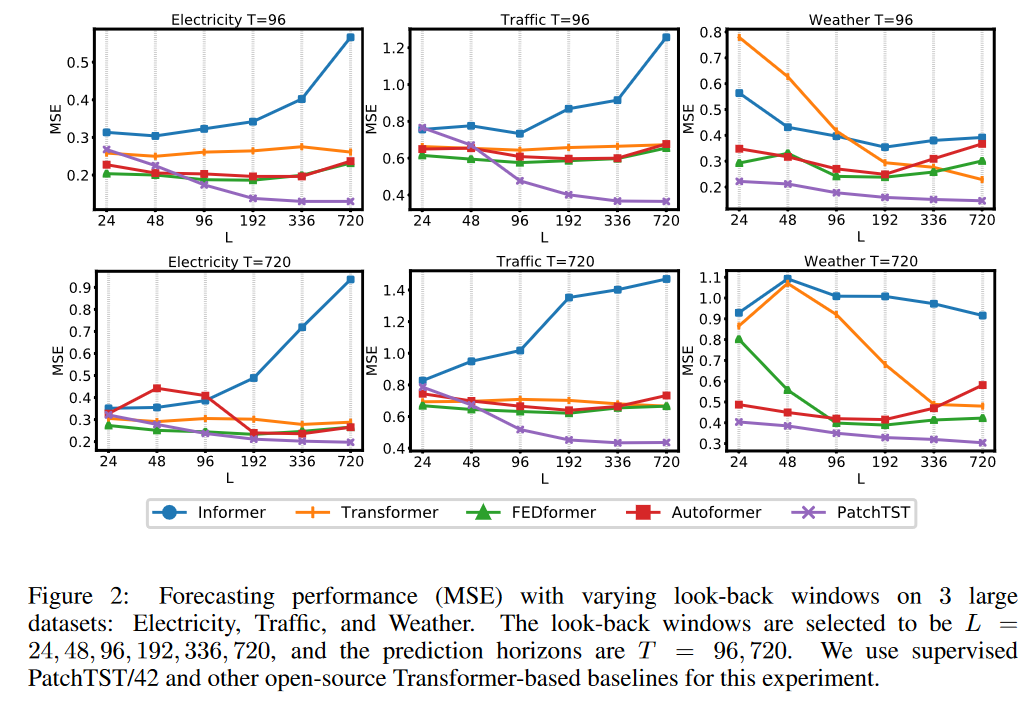
模型随着历史观测长度的增加,呈现明显的预测误差降低趋势。
结论
本文提出一种基于transformer的多变量时间序列预测和自监督表示学习模型的有效设计。它基于两个关键部分:
- 将时间序列分割为子序列级的Patch,这些补丁作为Transformer的输入tokens,来增强局部性并捕获在点级无法获得的全面语义信息;
- 通道独立性,其中每个通道包含一个单一的单变量时间序列,在所有序列中共享相同的嵌入和Transformer权重。
该模型不仅在监督学习方面优于其他基线,而且在自监督表示学习和迁移学习方面均有出色的性能。
思考
这篇文章开启了一个新思路,后续大量的文章都是基于Patch和通道独立优化的,尽管并没有进行大刀阔斧的改造,但是简单的方法就达到了SOTA的效果。

















 1760
1760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









